Cross-lingual transfer of multilingual models on low resource African Languages
Abstract: Large multilingual models have significantly advanced NLP research. However, their high resource demands and potential biases from diverse data sources have raised concerns about their effectiveness across low-resource languages. In contrast, monolingual models, trained on a single language, may better capture the nuances of the target language, potentially providing more accurate results. This study benchmarks the cross-lingual transfer capabilities from a high-resource language to a low-resource language for both, monolingual and multilingual models, focusing on Kinyarwanda and Kirundi, two Bantu languages. We evaluate the performance of transformer based architectures like Multilingual BERT (mBERT), AfriBERT, and BantuBERTa against neural-based architectures such as BiGRU, CNN, and char-CNN. The models were trained on Kinyarwanda and tested on Kirundi, with fine-tuning applied to assess the extent of performance improvement and catastrophic forgetting. AfriBERT achieved the highest cross-lingual accuracy of 88.3% after fine-tuning, while BiGRU emerged as the best-performing neural model with 83.3% accuracy. We also analyze the degree of forgetting in the original language post-fine-tuning. While monolingual models remain competitive, this study highlights that multilingual models offer strong cross-lingual transfer capabilities in resource limited settings.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at how computer programs that understand language can learn from one African language and then do well in another, closely related African language. The two languages are Kinyarwanda (spoken in Rwanda) and Kirundi (spoken in Burundi). The authors compare two kinds of LLMs:
- Multilingual models (trained on many languages)
- Monolingual models (trained on just one language)
They want to see which kind is better at “transferring” what it learned from Kinyarwanda to Kirundi, especially when there isn’t much data.
What questions did the researchers ask?
The paper explores simple, practical questions:
- If we train a model on Kinyarwanda, how well can it handle Kirundi without extra help?
- If we fine-tune (adjust) the model using Kirundi data afterward, how much better does it get?
- Do multilingual models transfer better than monolingual models in this setting?
- After fine-tuning on Kirundi, does the model “forget” what it learned about Kinyarwanda?
How did they do it? (Methods explained simply)
Think of LLMs like students learning patterns in text. The researchers used two kinds of “students”:
- Multilingual transformer models (advanced, pre-trained models):
- mBERT: trained on 104 different languages
- AfriBERTa (“AfriBERT” in the paper): trained mostly on African languages
- BantuBERTa: focused on the Bantu language family (which includes Kinyarwanda and Kirundi), but trained on a smaller dataset
- Simpler neural models (more basic learners):
- CNN and Char-CNN: scan text like a “pattern finder,” either at the word level (CNN) or the character level (Char-CNN)
- BiGRU: reads text forward and backward to understand context, like reading a sentence both ways to catch more meaning
Here’s their approach, step by step:
- They used news articles in Kinyarwanda (about 21,000 articles) and Kirundi (about 4,600 articles), each labeled into 14 topics (like categories).
- First, they trained each model on Kinyarwanda to classify the news into the right topic.
- Then, they tested the trained model directly on Kirundi to see how much it transferred without any help (this is “direct transfer”).
- Next, they fine-tuned the model on Kirundi to improve its performance in the target language.
- Finally, they checked the model again on Kinyarwanda to see if it forgot what it learned before (“catastrophic forgetting” — like studying a new subject and forgetting the old one).
They measured success using:
- Accuracy: how often the model got the topic right
- F1 score: a balanced measure of correctness that looks at both precision and recall
- Forgetting: how much the model’s performance dropped on Kinyarwanda after fine-tuning on Kirundi
What did they find, and why does it matter?
Here are the main results in simple terms:
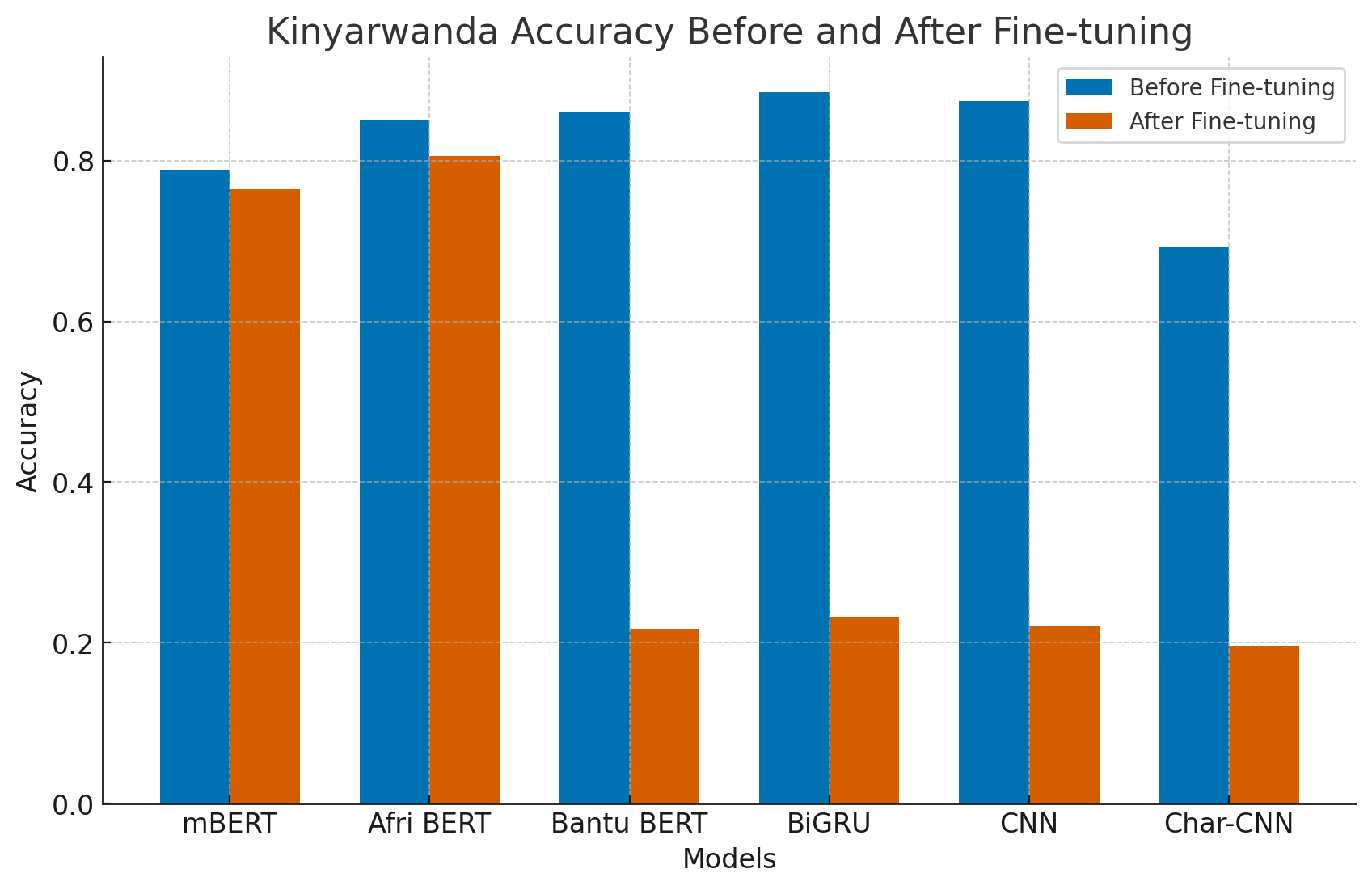
- Multilingual models transferred better than monolingual models overall.
- After fine-tuning on Kirundi, AfriBERTa did the best, reaching about 88% accuracy. mBERT and BantuBERTa also did well (around 85–86%).
- Among the simpler neural models, BiGRU was the strongest after fine-tuning (about 83% accuracy). CNN and Char-CNN did worse.
- AfriBERTa and mBERT forgot only a little of Kinyarwanda after fine-tuning on Kirundi (roughly 3–5% drop).
- BantuBERTa and the simpler neural models suffered “catastrophic forgetting,” losing most of their Kinyarwanda performance after fine-tuning.
Why is this important?
- It shows that multilingual models (especially those focused on African languages) can be very helpful when data is scarce.
- It supports the idea that training on related languages can boost performance, which is valuable for many underrepresented languages worldwide.
- It highlights a risk: some models forget old knowledge when learning new tasks, so we need strategies to reduce forgetting.
What does this mean for the future?
This research suggests:
- If you’re working with low-resource African languages, multilingual models like AfriBERTa are a strong choice for cross-language transfer.
- Fine-tuning on the target language can significantly improve results.
- We must design better training strategies (like “continual learning”) to prevent forgetting when models learn multiple languages or tasks.
- Building and sharing more high-quality datasets for African languages will make these tools even better and fairer.
In short, this paper shows that smart, multilingual language tools can help bridge gaps for underrepresented languages, making technology more inclusive for people who speak them.
Glossary
- Adapter-based architecture: A modular approach that adds small trainable adapters to large models to enable efficient task or language transfer. "UniBridge , an adapter based architecture incorporating embedding initialization and multi-source transfer."
- AfriBERT: A multilingual transformer model covering African languages, designed to better capture their linguistic characteristics. "AfriBERT achieved the highest cross-lingual accuracy of 88.3% after fine-tuning"
- ARBERT: A transformer-based LLM tailored for Arabic, focusing on Modern Standard Arabic and dialects. "introduce ARBERT and MARBERT, two deep bidirectional transformer-based models designed for Arabic language processing"
- AWD-LSTM: ASGD Weight-Dropped LSTM; a regularized LSTM variant that improves language modeling performance. "AWD-LSTM and QRNN consistently outperform other models"
- Back-translation: A technique that translates monolingual target-language text back into the source language to create synthetic parallel data. "effectively back-translating monolingual LRL data to create an enhanced corpus"
- BantuBERTa: A multilingual transformer pretrained primarily on Bantu languages to leverage family similarities for transfer. "BantuBERTa leverages these commonalities to enhance performance in Natural Language Processing within the language family"
- BiDRL (Bilingual Document Representation Learning): A model that jointly learns document embeddings across two languages to capture semantic and sentiment correlations. "present the Bilingual Document Representation Learning model (BiDRL) learning document representations using a joint learning algorithm"
- BiGRU (Bidirectional Gated Recurrent Unit): A recurrent neural network processing sequences in both directions to capture context. "BiGRU emerged as the best-performing neural model with 83.3% accuracy"
- Bits-per-character: A LLM evaluation metric measuring the average number of bits needed to encode characters; lower is better. "achieving better bits-per-character metrics"
- BLEU score: An automatic metric for machine translation quality based on n-gram overlap with reference translations. "In terms of averaged BLEU score, the multilingual approach shows the largest gains"
- Byte-pair encoding (BPE): A subword tokenization method that handles rich morphology by segmenting words into frequently occurring units. "using byte-pair encoding to handle the rich morphology of these languages"
- Catastrophic forgetting: The loss of previously learned knowledge when a model is fine-tuned on new data/tasks. "with fine-tuning applied to assess the extent of performance improvement and catastrophic forgetting"
- Char-CNN (Character-Level CNN): A convolutional network that processes text at the character level to capture morphological and orthographic patterns. "Character-Level Convolutional Neural Networks (char-CNN)"
- Code-switched languages: Texts mixing two or more languages within or across sentences, common in social media and conversational data. "for sentiment analysis in Dravidian code-switched languages"
- CommonCrawl: A large public web crawl dataset used to pretrain multilingual LLMs. "using two terabytes of CommonCrawl data"
- Cross-lingual transfer learning: Transferring knowledge learned in one language to perform tasks in another language. "Cross-lingual transfer learning, where knowledge from a resource-rich language is transferred to a lexically similar low-resource language"
- CUDA: NVIDIA’s parallel computing platform enabling GPU-accelerated training and inference. "Given the computation on a Mac environment, MPS was opted due the unavailability of CUDA"
- Data augmentation: Techniques to increase training data variety and quantity to improve model robustness. "Data augmentation for LRL are explored by [13]"
- Downstream task: A specific application (e.g., classification) on which a pretrained model is fine-tuned and evaluated. "Fine-tune on tokenized for the downstream task"
- Embedding initialization: Setting initial values of word/subword embedding vectors to facilitate better learning or transfer. "incorporating embedding initialization"
- Fine-tuning: Adapting a pretrained model to a target task or language by further training on task-specific data. "with fine-tuning applied to assess the extent of performance improvement and catastrophic forgetting"
- GLUE benchmark: A suite of NLP tasks for evaluating language understanding models. "fine tuned using the GLUE benchmark"
- Hierarchical Softmax: An efficient approximation of softmax that speeds training over large vocabularies using a tree structure. "adopting a skip-gram model and hierarchical Softmax to obtain word embeddings"
- IndicSBERT: A sentence embedding model for Indian languages used for multilingual and cross-lingual tasks. "IndicSBERT generally outperforms LaBSE"
- Joint pre-training: Training a single model simultaneously on multiple languages to learn shared representations. "without requiring shared subword vocabularies or joint pre-training"
- KINNEWS: A Kinyarwanda news dataset curated for cross-lingual text classification. "Two new datasets, KINNEWS and KIRNEWS, were introduced"
- KIRNEWS: A Kirundi news dataset for benchmarking cross-lingual classification. "Two new datasets, KINNEWS and KIRNEWS, were introduced"
- LaBSE: Language-agnostic BERT Sentence Embeddings; a multilingual model for sentence-level representations. "IndicSBERT generally outperforms LaBSE"
- Language discriminator: A module that encourages language-invariant features by distinguishing between languages in adversarial training. "employing unsupervised machine translation and language discriminator to align latent space between languages"
- Latent space: The internal representation space where models encode features; alignment can facilitate cross-lingual transfer. "align latent space between languages"
- Masked LLM (MLM): A pretraining objective where random tokens are masked and the model predicts them from context. "we first train a transformer-based masked LLM on one language"
- MARBERT: A transformer-based LLM specialized for Arabic, especially dialectal and social media text. "introduce ARBERT and MARBERT, two deep bidirectional transformer-based models designed for Arabic language processing"
- mBERT (Multilingual BERT): A BERT variant pretrained on 100+ languages, enabling zero-shot cross-lingual capabilities. "The multilingual architectures like multilingual BERT (mBERT) are trained on a variety of languages"
- Modern Standard Arabic (MSA): The standardized variety of Arabic used in formal contexts and media. "focusing on Modern Standard Arabic (MSA) and various dialects"
- MPS (Metal Performance Shaders): Apple’s GPU acceleration framework used on macOS for training when CUDA is unavailable. "Given the computation on a Mac environment, MPS was opted due the unavailability of CUDA"
- Multi-source transfer: Leveraging multiple source languages or datasets to improve transfer learning to a target language. "incorporating embedding initialization and multi-source transfer"
- Multilingual embeddings: Representation spaces learned across multiple languages to enable shared semantics. "sentence level alignment and multilingual embeddings"
- MVEC (Multi-View Encoder-Classifier): A model that aligns multiple views (e.g., translated and original text) for cross-lingual classification. "evaluate the Multi-View Encoder-Classifier (MVEC) model"
- Mutual intelligibility: The degree to which speakers of different languages can understand each other, facilitating transfer. "leveraging the mutual intelligibility of the languages"
- Neural Machine Translation (NMT): End-to-end neural approaches for translating text between languages. "multilingual neural machine translation (NMT) strategies for African languages"
- NLTK tokenizer: A tokenization tool from the Natural Language Toolkit used to split text into tokens. "The Natural Language Toolkit (NLTK) tokenizer was applied to the text corpus"
- Partial lexicalization: Using limited lexicon mappings to support transfer when full lexical resources are unavailable. "using partial lexicalization and LSTM architecture"
- QRNN (Quasi-Recurrent Neural Network): A faster RNN variant combining convolutional layers with recurrent pooling. "AWD-LSTM and QRNN consistently outperform other models"
- Skip-gram: A Word2Vec training objective predicting context words from a center word. "adopting a skip-gram model and hierarchical Softmax"
- Stop word lists: Lists of common function words filtered out during preprocessing. "stop word lists for both languages"
- Subword vocabulary: A set of subword units used for tokenization in models to handle rare or morphologically rich words. "without requiring shared subword vocabularies"
- Tokenization: Splitting text into tokens (words or subwords) for model input. "Tokenize "
- Transfer learning: Reusing knowledge from one task or domain to improve performance in another. "review past and future techniques such as transfer learning, data augmentation"
- Transliteration: Converting text from one script to another based on phonetic or orthographic rules. "using transliteration"
- UniBridge: A unified approach for cross-lingual transfer focusing on embedding initialization and vocabulary size optimization. "we introduce UniBridge (Cross-Lingual Transfer Learning with Optimized Embeddings and Vocabulary)"
- Warmup steps: Initial training steps with gradually increasing learning rate to stabilize optimization. "500 warmup steps were employed to stabilize training"
- Weight decay: A regularization technique adding a penalty on large weights to prevent overfitting. "a weight decay of 0.01 was applied to prevent overfitting"
- Word2Vec: An algorithm that learns word embeddings through predictive tasks like skip-gram or CBOW. "a Word2Vec model was trained adopting a skip-gram model and hierarchical Softmax"
- XLM: A cross-lingual LLM enabling multilingual understanding and transfer. "against various models like multilingual BERT (mBERT) and XLM"
- XLM-R: A large multilingual transformer pretrained on massive web data across 100 languages. "XLM-R, a large-scale multilingual LLM trained on 100 languages using two terabytes of CommonCrawl data"
- XQuAD: A cross-lingual question answering dataset derived from SQuAD translated into multiple languages. "along with the introduction of the XQuaD dataset"
- Zero-shot: Evaluating or transferring to a task/language without any labeled training data for that target. "outperforms cross-lingual transfer in both zero-shot and supervised settings"
Collections
Sign up for free to add this paper to one or more collections.