- The paper introduces ICL-APT, a novel methodology combining in-context learning with kNN retrieval to efficiently augment training data for German process industry applications.
- The paper demonstrates that the method improves key information retrieval metrics by an average of 3.5 while reducing computational time by approximately four times.
- The paper highlights that optimized, domain-adaptive pretraining can effectively handle the unique terminology and data sparsity challenges in the process industry.
Efficient Domain-adaptive Continual Pretraining for the Process Industry in the German Language
Introduction
The paper "Efficient Domain-adaptive Continual Pretraining for the Process Industry in the German Language" (2504.19856) presents an innovative approach to domain-adaptive continual pretraining (DAPT) specifically tailored for the German language within the process industry. DAPT, a leading method for further training LMs, typically requires extensive domain-related corpus, posing challenges for specific domains and non-English languages like German. This research introduces the In-context Learning Augmented Pretraining (ICL-APT) methodology, leveraging in-context learning (ICL) and k-nearest neighbors (kNN) to efficiently augment training data with domain-specific texts, reducing computational effort while sustaining robust model performance.
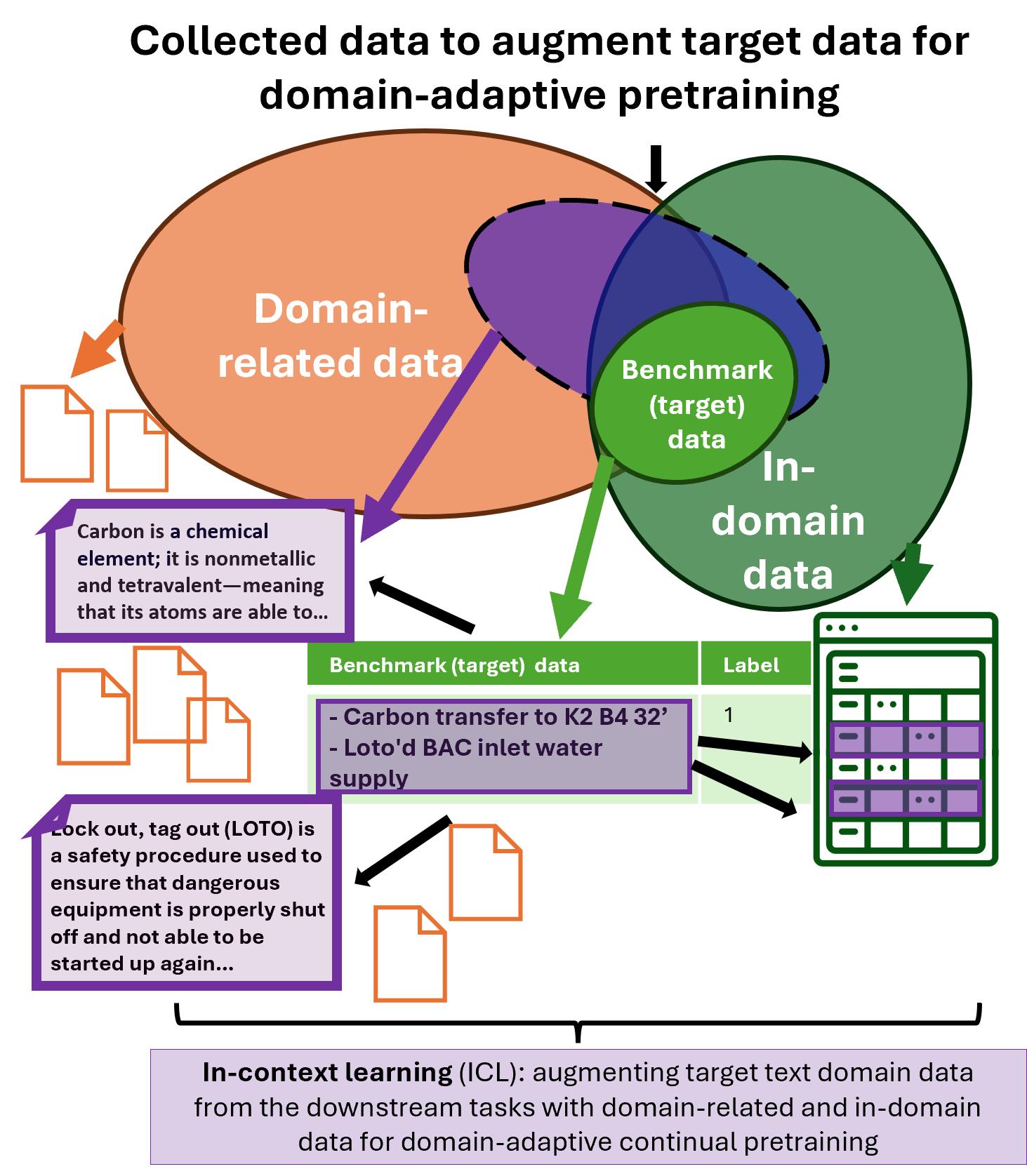
Figure 1: The proposed methodology, called in-context learning for domain-adaptive pretraining (ICL-APT), focuses on selecting data for continual pretraining. Using target data sampled from task-specific text-only datasets (light green), ICL-APT retrieves semantically similar documents from domain-related (orange) and in-domain (dark green) datasets to create augmented target data for pretraining.
Methodology: ICL-APT
The ICL-APT methodology combines in-context learning with kNN retrieval to intelligently augment training datasets. By selecting semantically similar documents from domain-related and in-domain corpora, it constructs a richer training dataset that enhances the learning of domain-specific vocabulary. This approach addresses the limitations of DAPT, which typically requires vast amounts of domain-specific data, by emphasizing semantic similarity and contextual relevance rather than data volume, thus optimizing computational efficiency.
Domain Challenges in the Process Industry
The process industry encompasses sectors such as chemical and pharmaceutical production, characterized by unique terminology, acronyms, and numerical data. German domain-specific LLMs currently face limitations due to sparse large datasets. The industry's text data—often recorded in shift logs—contains specialized jargon demanding advanced semantic understanding for effective NLP applications.
An example of a shift log is depicted, illustrating the intricate language used within these documents.
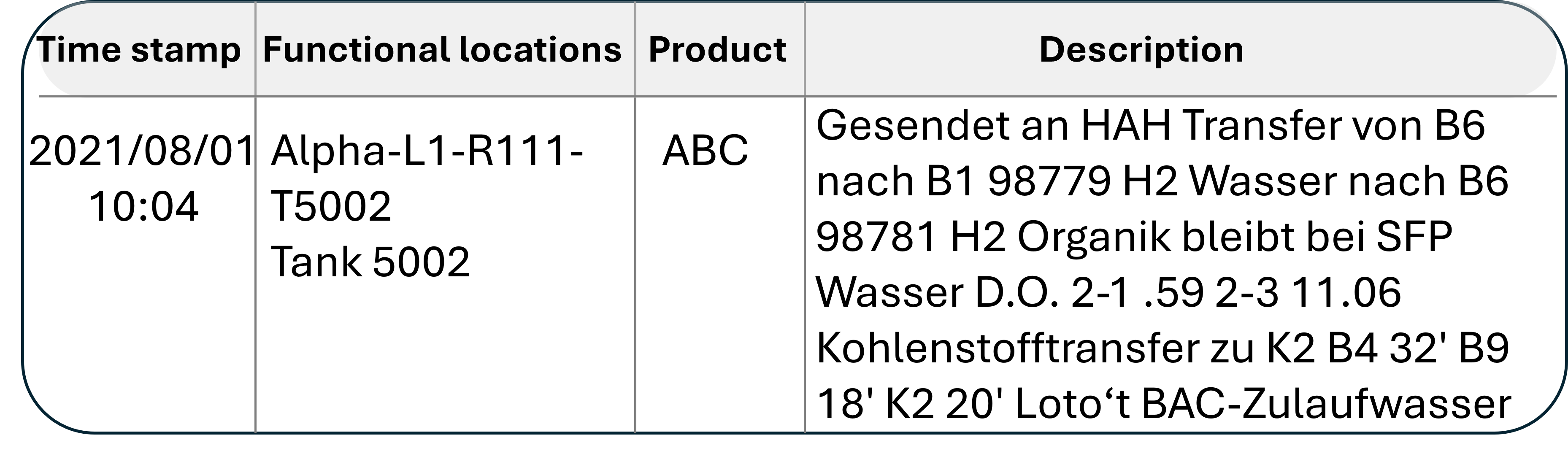
Figure 2: An example of a simulated text log from a shift book in German. These logs contain domain-specific terminology that demands specialized knowledge of the field and a thorough understanding of the production process.
Evaluation and Results
ICL-APT demonstrated strong performance improvements over traditional DAPT methodologies, boasting a 3.5 average increase in information retrieval (IR) metrics, such as mAP, MRR, and nDCG, while demanding approximately four times less computational time. This model's effectiveness was tested across semantic search tasks, using a custom domain benchmark that evaluates the retrieval of relevant documents based on semantic similarities. The substantial reduction in GPU hours required for training further underscores the method's efficiency and suitability for organizations with constrained computational resources.
The research also analyzed the distribution of cosine distances among seed, in-domain, and domain-related documents, revealing lower distances for in-domain data—indicative of better alignment with the target data's distribution.
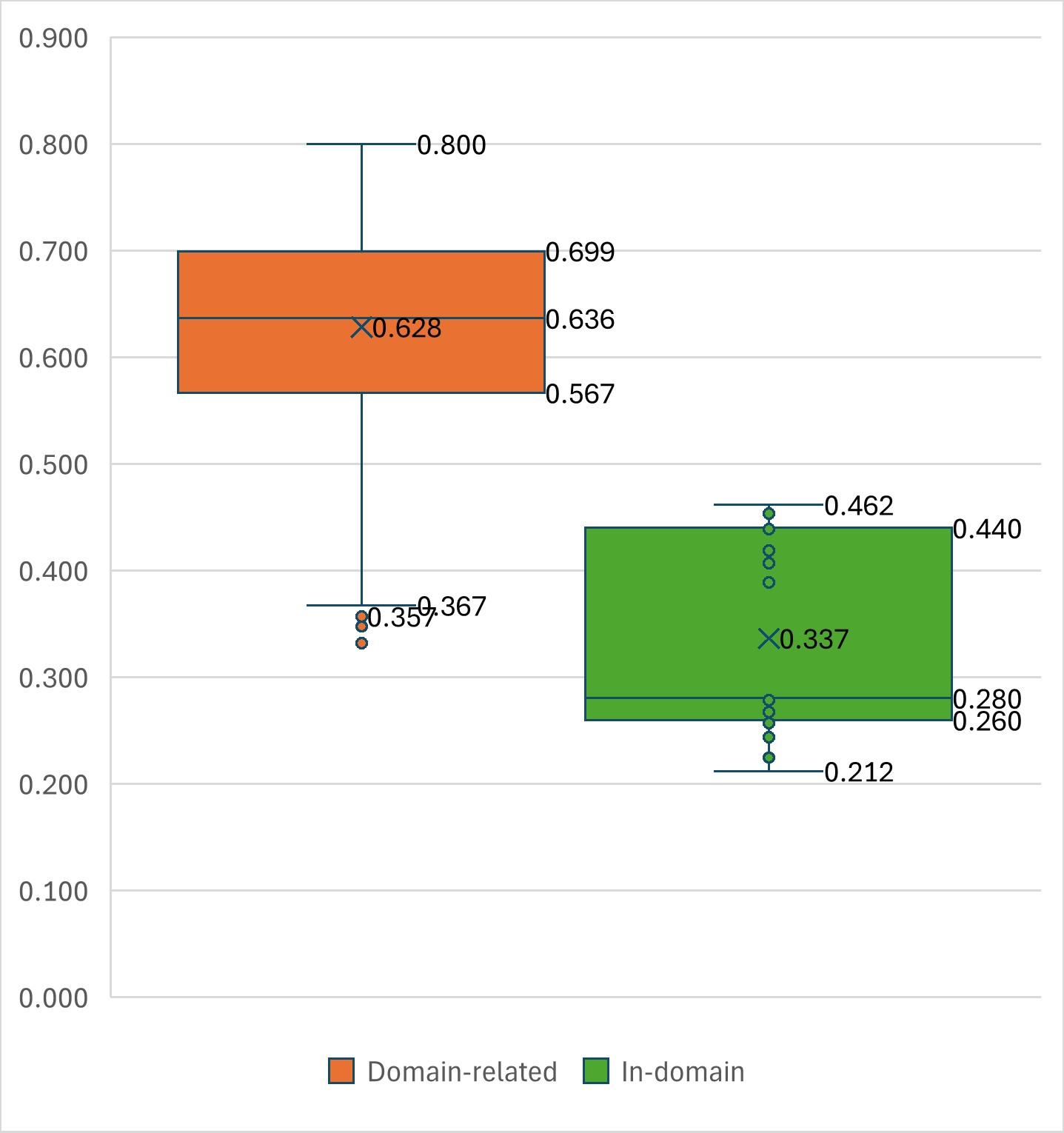
Figure 3: The distribution of cosine distances between seed documents and their relevant in-domain and domain-related documents is analyzed under identical constraints: a distance threshold of 0.8 and 70 NNs. Because the seed documents share the same data distribution as the in-domain documents, their distances to in-domain documents are significantly lower than those for domain-related documents.
Implications and Future Work
The introduction of ICL-APT presents significant implications for the deployment and development of NLP systems within low-resource domains. By optimizing training efficiency without compromising performance, this methodology enhances access to advanced LLMs across various industries with limited computational capacities. The findings advocate for broader applicability of similar approaches in other resource-constrained domains.
Future research is suggested to extend the testing of ICL-APT in diverse domains and languages, examining whether vocabulary expansion and contrastive learning for domain-specific terms could further enhance the adaptation process.
Conclusion
"Efficient Domain-adaptive Continual Pretraining for the Process Industry in the German Language" (2504.19856) presents a compelling methodology that reshapes the landscape of domain adaptation in LLMs. By pioneering a cost-effective, efficient strategy, the research equips industries with an adept tool to advance NLP applications, ensuring relevance and efficiency amidst domain-specific challenges.