- The paper presents a self-supervised method for creating general-purpose visual features using a scalable data processing pipeline and large curated datasets.
- It employs Vision Transformers with image and patch-level objectives and introduces KoLeo regularization to ensure diverse and stable feature representations.
- Performance evaluations demonstrate competitive results in semantic segmentation, instance recognition, and monocular depth estimation without fine-tuning.
DINOv2: Learning Robust Visual Features without Supervision
This paper, titled "DINOv2: Learning Robust Visual Features without Supervision" (2304.07193), presents an exploration into generating foundational models for computer vision, analogous to recent advancements in Natural Language Processing. The authors aim to produce general-purpose visual features that can operate across various tasks and distributions without the necessity of fine-tuning by revisiting existing pretraining techniques, particularly self-supervised methods.
Introduction and Motivation
In the field of NLP, task-agnostic pretrained representations have significantly enhanced performance across various downstream tasks. The paper anticipates similar developments for computer vision, where foundation models would generate visual features suitable for image-level and pixel-level tasks. This has primarily been pursued through text-guided pretraining, leveraging large corpora of paired textual information. However, this approach often lacks the ability to captures complex pixel-level information due to the approximate nature of textual descriptions.
Self-supervised learning offers a promising alternative, wherein visual features are derived solely from the image data without reliance on accompanying textual information. Despite their potential, existing self-supervised methodologies have largely been constrained to smaller, curated datasets like ImageNet-1k, resulting in limited scalability and applicability across diverse image domains.
Data Processing Pipeline
The paper introduces a sophisticated data processing pipeline designed to curate a robust dataset essential for effective self-supervised learning. The pipeline comprises various stages, including embedding mapping, deduplication, and retrieval from both curated and uncurated sources.

Figure 1: Overview of our data processing pipeline. Images from curated and uncurated data sources are mapped to embeddings, deduplicated, and matched to curated images, enhancing the initial dataset via a self-supervised retrieval system.
This automated pipeline, inspired by NLP techniques, utilizes similarities between data rather than external metadata, resulting in a curated dataset of 142 million high-quality images. This curated dataset, termed LVD-142M, attempts to balance concepts and prevent mode collapse, ensuring quality and diversity among the training data.
Methodology
The study employs Vision Transformers (ViT) with significant model and data scaling, incorporating strategies to stabilize and accelerate learning. The authors distill a billion-parameter ViT model into smaller models while retaining superior performance.
The paper evaluates DINOv2 across numerous image understanding tasks, demonstrating substantial improvements over existing self-supervised methods and competitive performance with weakly-supervised models.
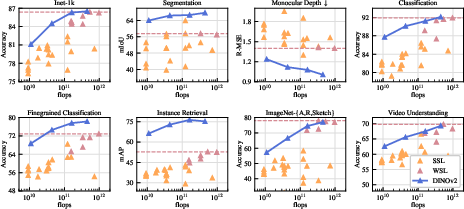
Figure 3: Evolution of performance when scaling in parameters, demonstrating robust performances across vision tasks.
Indeed, the DINOv2 models exhibit capabilities in semantic segmentation, instance recognition, and monocular depth estimation, illustrating high efficacy as general-purpose visual feature extractors.
Future Prospects and Conclusion
DINOv2 heralds promising developments in self-supervised visual representations, yet also opens avenues for further scaling in model and data size. As foundational models in vision analogous to NLP continue to mature, such enhancements will likely yield broader applicability and task-free operation across diverse visual domains.
In conclusion, the research underscores the potential gradual shift towards self-supervised foundations in computer vision, encouraging future exploration into larger scales and refined methodologies, potentially integrating multimodal capabilities that could redefine visual AI systems.
