- The paper demonstrates that unsupervised DINOv3 features yield robust in-context segmentation without training, achieving an average gain of +7.5% mIoU using 3× fewer parameters.
- It introduces a novel debiasing strategy that projects out positional signals to ensure reliable cross-image semantic matching and improved segmentation performance.
- Empirical results confirm INSID3’s superior generalization across semantic, part, and personalized segmentation tasks on diverse datasets.
INSID3: Training-Free In-Context Segmentation with DINOv3
Motivation and Context
The paper introduces INSID3, a minimalist and training-free framework for in-context segmentation using DINOv3, a dense vision foundation model designed for self-supervised representation learning. In-context segmentation (ICS) is aimed at segmenting arbitrary concepts (objects, parts, personalized instances) given visual examples without supervised mask or category-level training. Prior methods rely either on fine-tuning vision foundation models (VFMs), which causes domain over-fitting, or on multi-component pipelines combining frozen pre-trained models (e.g., DINOv2 with SAM), which yield architectural complexity and fixed mask granularity.
The central research question is whether emergent segmentation and robust correspondence can arise solely from a single, frozen self-supervised backbone, without requiring additional decoders, supervision, or model composition.
Dense Self-Supervised Representations and Region-Level Grouping
The DINOv3 model exhibits strong spatial structure and semantic correspondence due to its Gram-anchoring objective and dense high-resolution post-training. This enables unsupervised region-level grouping (Figure 1), where agglomerative clustering applied to DINOv3 features delineates coherent object and part-level regions.

Figure 1: Region-level grouping from DINOv3 features, illustrating unsupervised decomposition into object and part-level clusters.
INSID3 Pipeline and Debiasing of Positional Signals
The INSID3 methodology leverages three key stages: (1) fine-grained agglomerative clustering on the target image, (2) seed-cluster selection via cross-image semantic matching in a debiased feature space, and (3) spatial mask aggregation guided by intra-image self-similarity. Crucially, cross-image matching in DINOv3 reveals a systematic positional bias—features at corresponding spatial coordinates spuriously match across unrelated images—stemming from absolute positional encodings interacting with semantic signals. This is visualized and contrasted with DINOv2 in Figure 2.

Figure 2: Positional bias in DINOv2 vs DINOv3, demonstrating coordinate-aligned artifacts in DINOv3's feature space and their suppression via debiasing.
Debiasing is achieved by projecting both reference and target features onto the orthogonal complement of a positional subspace extracted via SVD from a noise image, suppressing absolute positional components during cross-image matching while retaining original features for intra-image clustering.
Algorithmic Stages and Structured Aggregation
INSID3 operates as follows (Figure 3):
- Clustering: Agglomerative clustering segments the target image into coherent regions using original DINOv3 features.
- Seed-Cluster Selection: Candidate clusters matching the reference are identified by backward correspondence in the debiased space; the most semantically similar cluster serves as the segmentation seed.
- Aggregation: Final mask is formed by combining cross-image similarity (semantic alignment) with self-similarity (affinity to the seed), aggregating clusters to recover the spatial extent of the prompted concept.
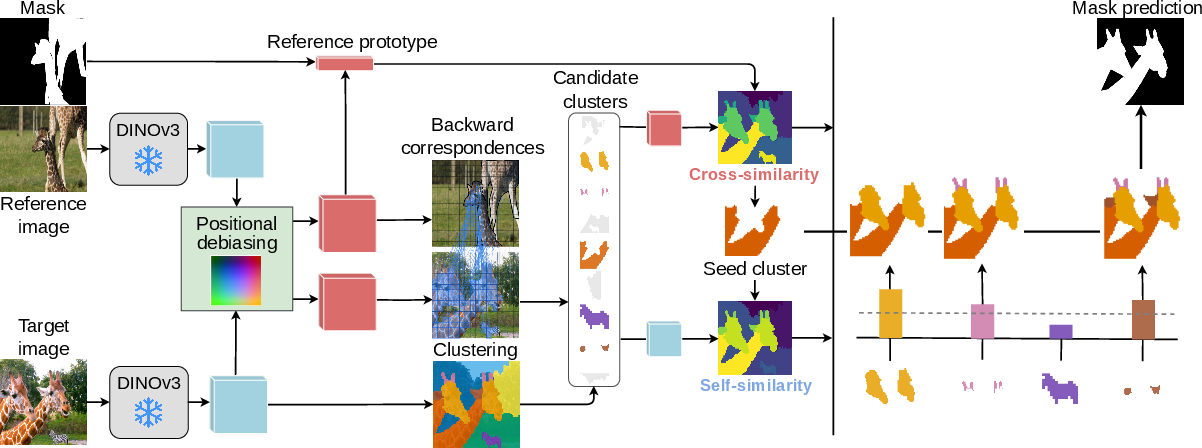
Figure 3: Overview of INSID3’s pipeline, including clustering, seed selection based on cross-image debiased matching, and semantic/spatial aggregation.
Empirical Results and Comparative Analysis
INSID3 achieves superior generalization and segmentation accuracy across one-shot semantic, part, and personalized segmentation benchmarks—yielding an average gain of +7.5% mIoU over previous approaches and using 3× fewer parameters, all without category or mask-level supervision.
The method outperforms competitive training-free pipelines (e.g., GF-SAM and Matcher, which depend on mask-supervised SAM and DINOv2 features) and task-specific fine-tuned models (SegIC, DiffewS, SINE) on both standard and out-of-domain datasets, maintaining robustness across granularity levels and domains. Figure 4 provides a qualitative comparison.

Figure 4: INSID3 versus GF-SAM on benchmark datasets, highlighting improved mask accuracy, generalization, and flexible region granularity.
INSID3 also demonstrates stable improvement when scaling to multiple reference examples (5-shot segmentation), with no need for task-specific parameter tuning. Furthermore, the proposed debiasing strategy improves semantic correspondence on SPair-71k by up to +6.6% PCK, indicating its generality across cross-image matching tasks.
Qualitative and Limitations
INSID3 produces coherent, accurate masks for objects, parts, and personalized instances, even under appearance changes and distractors. Figure 5 exemplifies broad generalization across domains, including medical, remote sensing, and everyday imagery.
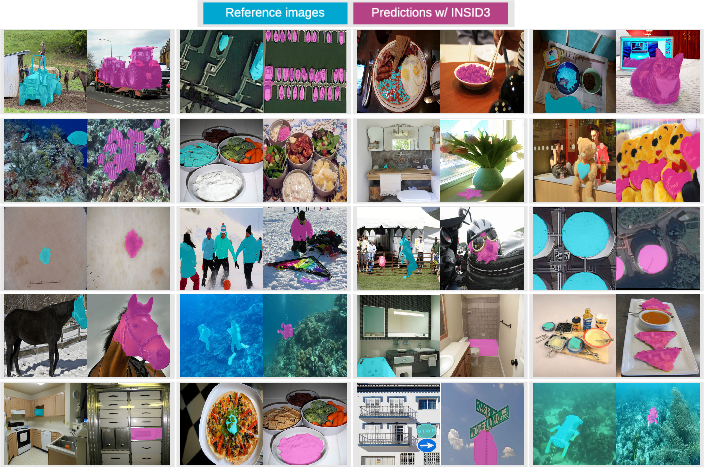
Figure 5: Qualitative segmentation results with INSID3; reference mask (light blue), predicted target mask (purple), demonstrating semantic and spatial flexibility.
Limitations include inability to segment multiple concepts in a single pass, reliance on mask prompts (vs points/boxes), and dependence on the expressivity of the underlying backbone for instance-level reasoning.
Practical and Theoretical Implications
INSID3 establishes that dense, self-supervised representations provide sufficient semantic and spatial structure for training-free segmentation, negating the necessity for supervision or model composition. Practical implications include:
- Reduced inference complexity (single backbone, no decoders or auxiliary models).
- Competitive computational efficiency, outperforming multi-stage pipelines in runtime.
- Robust transferability across domains and segmentation granularity.
- Applicability to broader tasks requiring semantic cross-image alignment.
Theoretically, this supports the emergence of object/part segmentation via unsupervised spatial grouping and semantic matching. Future developments may extend toward joint multi-concept prompting, interactive annotation modalities, and further leveraging backbone properties for instance-level decomposition.
Conclusion
INSID3 demonstrates that in-context segmentation can arise directly from self-supervised DINOv3 features, delivering robust domain and granularity generalization with minimal architecture and without supervision (2603.28480). The debiasing of positional signals is essential for reliable cross-image matching and is broadly beneficial for semantic correspondence tasks. These findings suggest that unsupervised dense representations are sufficient for general-purpose visual segmentation and affirm a scalable paradigm for vision understanding free from task-specific training and multi-stage orchestration.

