- The paper introduces an autoregressive diffusion framework that unifies video and action tokens in a shared latent space for enhanced robot control.
- It employs a dual-stream Mixture-of-Transformers architecture with teacher forcing and noisy history augmentation to ensure closed-loop reasoning and rapid convergence.
- Experimental evaluations in simulation and real-world tasks demonstrate significant improvements in success rates and sample efficiency over state-of-the-art methods.
Causal World Modeling for Robot Control
Introduction
The paper "Causal World Modeling for Robot Control" (2601.21998) explores a novel approach to robotic manipulation through world modeling, focusing on vision-language pre-training to create robust and adaptable robotic policies. This framework leverages autoregressive diffusion for simultaneous video frame prediction and policy execution. The model employs a Mixture-of-Transformers (MoT) architecture, combining video and action tokens in a shared latent space. This integration facilitates effective closed-loop reasoning and supports long-term temporal memory, which is crucial for executing long-horizon tasks. This approach is thoroughly evaluated against existing state-of-the-art methods in both simulated environments and real-world applications.
Methodology
The core of the methodology involves an autoregressive diffusion framework that predicts video and actions in a unified sequence. This is achieved through flow matching in latent space, allowing for continuous integration of action tokens with visual predictions. At each autoregressive step, the model interleaves video and action tokens to decode corresponding actions, conditioned on the predicted visual transitions.

Figure 1: Framework overview: is conditioned by autoregressive diffusion for unified video-action world modeling.
The use of a dual-stream architecture allows video and action modalities to interact without interference, maintaining separate feature spaces while enabling mutual influence via attention mechanisms. Initialization of the action network with scaled video network weights ensures stable dynamics during training and quick convergence. The training scheme includes teacher forcing with noisy history augmentation to simulate real-world observations, enhancing inference efficiency and maintaining high-frequency control.
Real-time Deployment
The asynchronous inference framework addresses the computational demands of video generation, allowing parallel action prediction and execution. This strategy mitigates latency and maintains real-time control, crucial for practical applications.

Figure 2: Asynchronous pipeline design overview: highlights how parallel computation enhances real-time control.
The asynchronous pipeline overlaps computation and execution, using cached key-value pairs to avoid redundant calculations, which is pivotal for maintaining task performance without compromising efficiency.
Experimental Results
The proposed model shows competitive performance across diverse scenarios including simulation benchmarks such as RoboTwin 2.0 and LIBERO, as well as real-world tasks. In these evaluations, the method substantially outperforms other existing state-of-the-art models like π0.5, achieving significant improvements in success rates and sample efficiency.
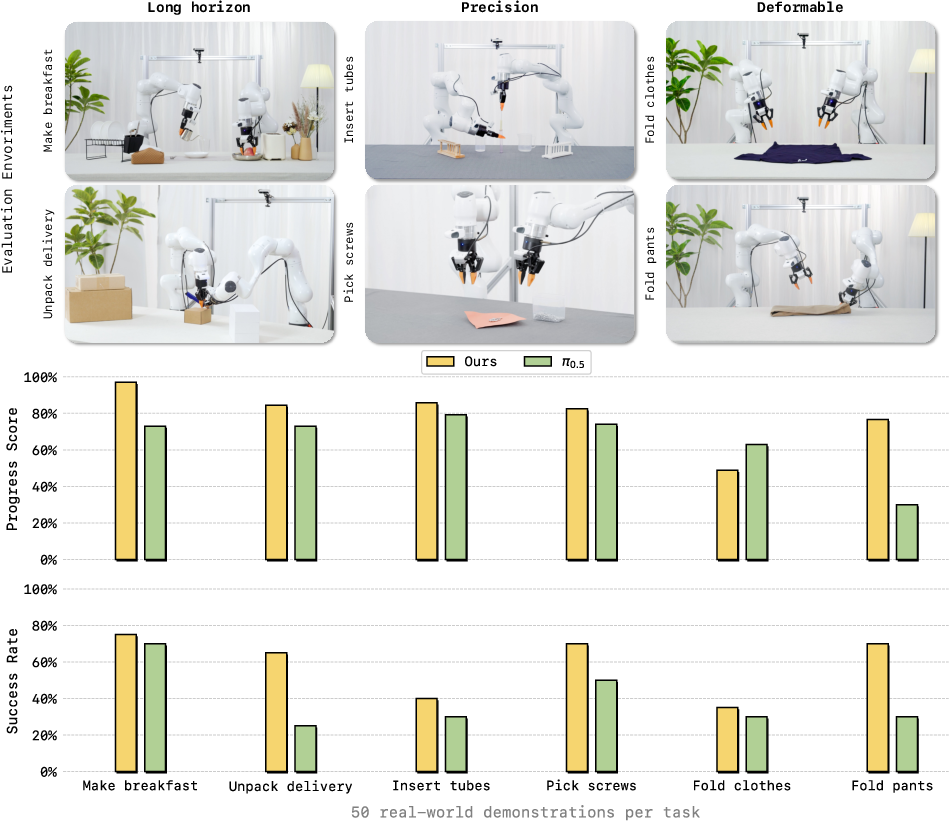
Figure 3: Real-world deployment results on various manipulation tasks with state-of-the-art performance.
The strong results highlight the model's capabilities in maintaining temporal consistency and precision in manipulation tasks, ultimately confirming the benefits of integrating video prediction with causal inference for robust robot control.
Conclusion
The paper introduces an effective world modeling approach for robotic manipulation that combines video dynamics prediction with inverse dynamics action inference. The causal modeling framework demonstrates superior performance, especially in tasks requiring long-term planning and real-time adjustments. Future developments might include enhancing video tokenization for lower computational overhead and expanding sensory inputs to accommodate more complex physical interactions. This advancement in causal world modeling emphasizes the importance of temporal coherence and adaptability in robotic control systems, setting a new benchmark in the field.
By addressing key issues in existing frameworks, such as representation entanglement and sample inefficiency, this approach presents a promising path forward for developing adaptable, general-purpose robotic systems that can seamlessly operate in diverse environments and tasks.
