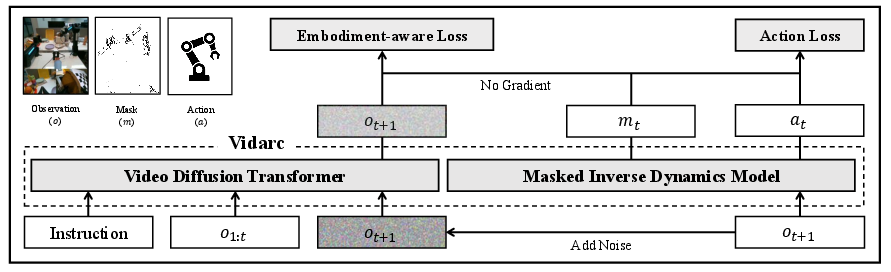
- The paper demonstrates that integrating an autoregressive video diffusion model with a masked inverse dynamics mechanism achieves real-time closed-loop robotic manipulation.
- The method leverages cross-embodiment pretraining and environmental re-prefilling to bridge simulation and real-world performance, significantly improving task success rates.
- Empirical results reveal up to 17% higher success rates and a 91% reduction in inference latency compared to baselines, underscoring its robustness and efficiency.
Vidarc: Embodied Video Diffusion Model for Closed-loop Robotic Control
Overview and Motivation
Vidarc proposes a novel framework for robotic arm manipulation in environments with limited data, focusing on closed-loop control utilizing an embodied video diffusion model augmented by a masked inverse dynamics mechanism (2512.17661). The main motivation lies in overcoming the limitations of previous video-based systems, which typically provide open-loop predictions and are not optimized for rapid real-time feedback integration or embodiment-specific grounding. Vidarc targets robust, generalizable, and adaptive manipulation by leveraging large-scale video data and specialized mechanisms for fast sensory-action cycles.
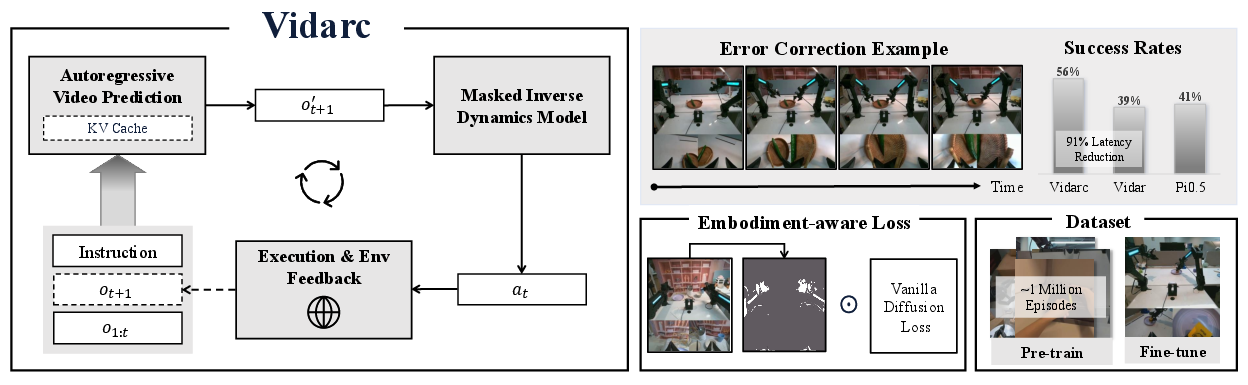
Figure 1: Vidarc architecture integrates an autoregressive video diffusion model and a masked inverse dynamics component to enable closed-loop control and efficient error correction after cross-embodiment pre-training and task-specific calibration.
Technical Contributions
Vidarc advances the state-of-the-art through several key components:
Empirical Results
Vidarc is pre-trained on over one million episodes spanning diverse embodiments and subsequently fine-tuned on unseen robotic platforms. Empirical evaluations demonstrate substantial improvements over prior baselines (Vidar, Pi0.5):

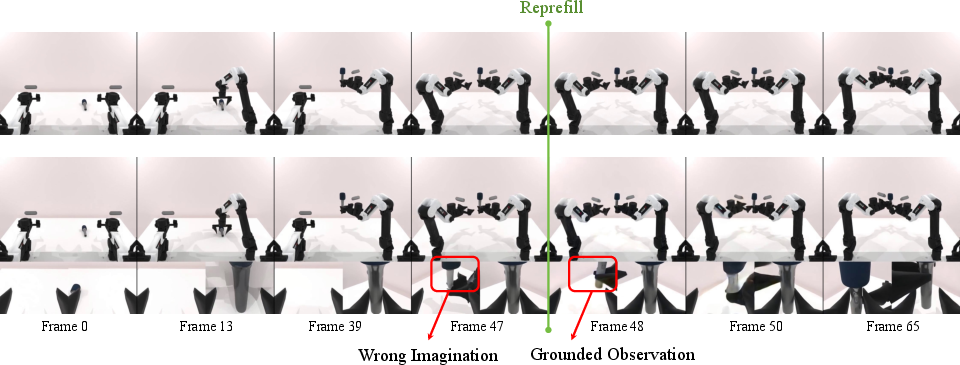
Figure 4: Closed-loop grounding at frame 47 corrects cumulative generative errors, ensuring successful manipulation even with drifted prediction histories.
Analysis of Robustness and Ablations
Ablation studies confirm the contributions of both the embodiment-aware loss and closed-loop feedback. Removing either reduces success rates by 6–14% across benchmarks. Sensitivity analysis on the loss reweighting parameter η shows Vidarc maintains high performance across a broad range of values, indicating stable behavior under hyperparameter variation.

Figure 5: Persistent artifacts near robot arm in naive video generation models can degrade final task performance; Vidarc’s masking mechanism mitigates such artifacts.
Implications and Future Directions
Vidarc’s design has several notable theoretical and practical ramifications:
Conclusion
Vidarc delivers a marked advancement in embodied video-based robotic control by achieving superior generalization, rapid closed-loop responsiveness, and robust error correction in both simulated and real domains. Its methodological contributions—causal autoregressive diffusion, action-relevant masking, and re-prefill-based closed-loop feedback—together address core challenges facing the deployment of foundation models for robot manipulation. These innovations suggest promising future research trajectories in scalable transfer, safety-aware feedback integration, and foundational model adaptation for dynamic environments.
Speculation on Future AI Developments
Looking forward, integration of communication between multiple visual world models, increasing multimodal grounding, and further acceleration of diffusion-based inference will be central. There is substantial headroom for architectural optimization (including hybrid autoregressive/non-autoregressive regimes), distillation for hardware efficiency, and leveraging foundation models to expand zero-shot/one-shot learning not just in manipulation but also in mobile, multi-agent, and dexterous domains.

Figure 7: The Aloha robot platform and its hardware specifications demonstrate Vidarc’s deployment context, featuring high-DOF manipulators and multi-view sensing for complex bimanual operations.