Dual-Stream Diffusion for World-Model Augmented Vision-Language-Action Model
Abstract: Recently, augmenting Vision-Language-Action models (VLAs) with world modeling has shown promise in improving robotic policy learning. However, it remains challenging to jointly predict next-state observations and action sequences because of the inherent difference between the two modalities. To address this, we propose DUal-STream diffusion (DUST), a world-model augmented VLA framework that handles the modality conflict and enhances the performance of VLAs across diverse tasks. Specifically, we propose a multimodal diffusion transformer architecture that explicitly maintains separate modality streams while still enabling cross-modal knowledge sharing. In addition, we introduce independent noise perturbations for each modality and a decoupled flow-matching loss. This design enables the model to learn the joint distribution in a bidirectional manner while avoiding the need for a unified latent space. Based on the decoupling of modalities during training, we also introduce a joint sampling method that supports test-time scaling, where action and vision tokens evolve asynchronously at different rates. Through experiments on simulated benchmarks such as RoboCasa and GR-1, DUST achieves up to 6% gains over baseline methods, while our test-time scaling approach provides an additional 2-5% boost. On real-world tasks with the Franka Research 3, DUST improves success rates by 13%, confirming its effectiveness beyond simulation. Furthermore, pre-training on action-free videos from BridgeV2 yields significant transfer gains on RoboCasa, underscoring DUST's potential for large-scale VLA pretraining.















Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching robots to act more wisely by helping them imagine the future. The authors build a system called DUST (Dual-Stream Diffusion) that lets a robot learn two things at the same time:
- What actions to take (like moving its arm).
- What the world will look like after those actions (like where an object will be).
By learning both together, the robot can plan better and avoid silly mistakes, like reaching for a cup but missing the rim.
What questions are they trying to answer?
In simple terms, the paper tackles three questions:
- How can a robot learn actions and predict future visuals at the same time, even though these two things are very different?
- Can we let information flow both ways (actions informing vision and vision informing actions) without mixing them into one confusing blob?
- Can we make the robot’s thinking more accurate at test time (when it’s acting) without retraining it or making it slow?
How does their method work?
Think of the robot’s brain as two parallel lanes that occasionally whisper to each other:
- Lane 1: Action lane (low-dimensional, smooth, like the steps of a dance).
- Lane 2: Vision lane (high-dimensional, detailed, like understanding a scene).
Here’s the core idea:
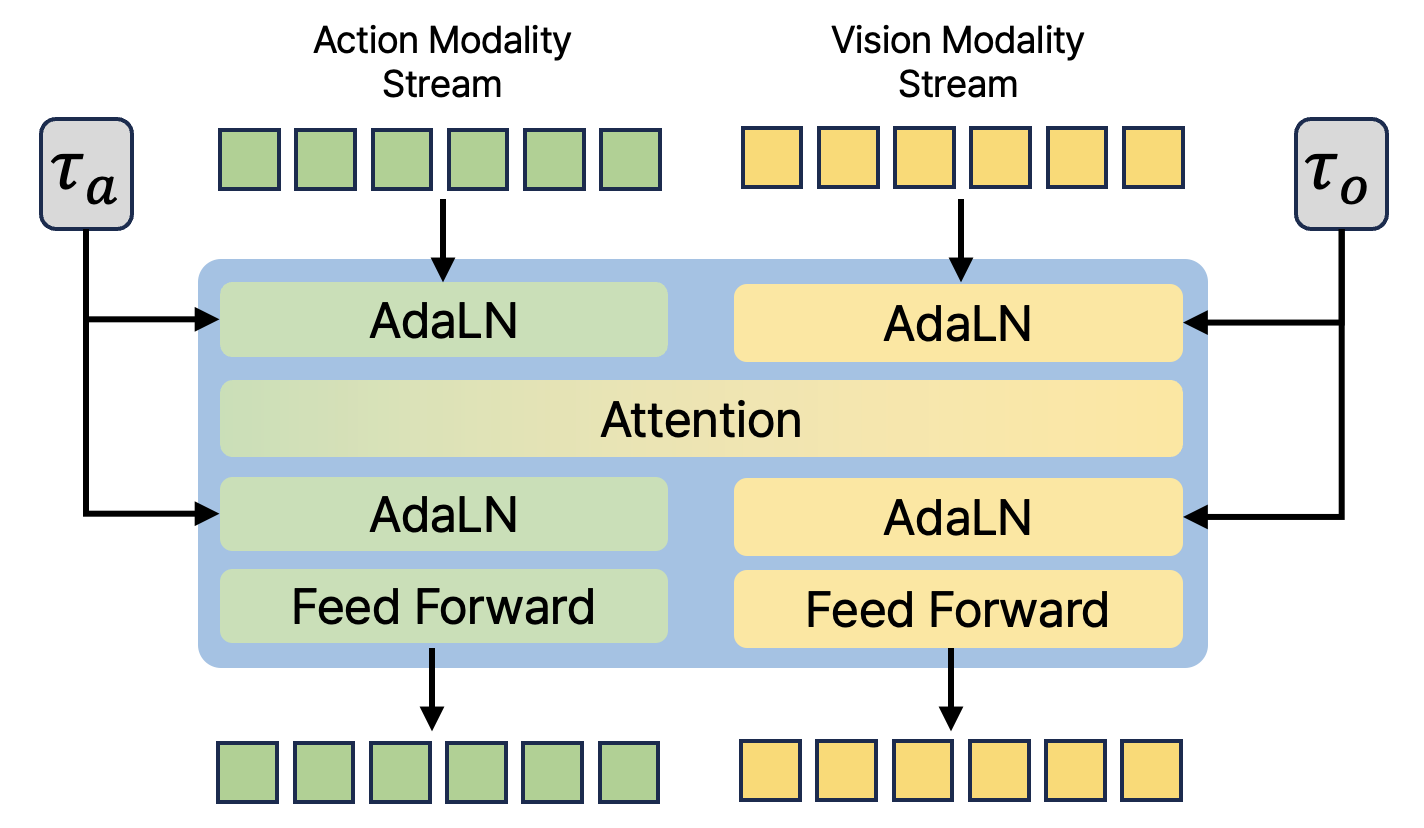
- Dual streams: DUST keeps actions and future-vision predictions in separate “streams” so each can be handled in the best way for its type. They don’t get mashed together, which avoids confusion.
- Smart communication: The two streams still share information through special attention layers (like bridges), so actions can help predict the future, and predicted futures can shape better actions.
- Diffusion learning: The model learns using a “diffusion” process. You can imagine starting with noisy, blurry versions of actions and images, then step-by-step un-blurring them. The model learns how to un-blur correctly.
Two training tricks make this work well:
- Independent noise per stream: They add different amounts of “blur” (noise) to actions and to vision—separately. For example, the model might see a clear future image but a noisy action and learn to guess the action that could cause that future, and vice versa. This teaches both “what action leads to what future?” and “what future matches this action?”
- Decoupled loss (flow matching): The model learns how to “move” from noisy to clean for each stream in a way that fits that stream’s structure (simple for actions, complex for vision). “Flow matching” is just a way of telling the model the direction to go from noise to the real thing.
A practical sampling trick at test time:
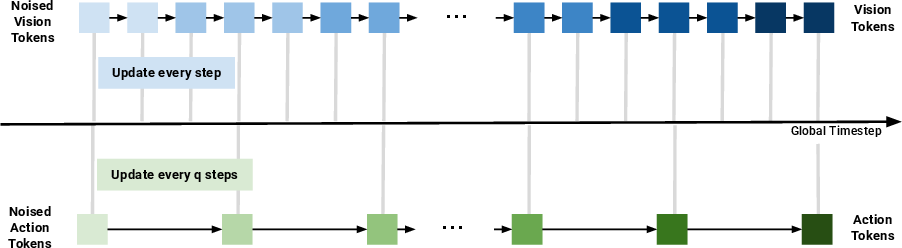
- Asynchronous denoising: Vision is complex and benefits from more un-blurring steps; actions are simpler and can settle faster. So, during action generation, they update the vision stream more frequently than the action stream. This gives the robot a sharper “mental picture” of what will happen without overcomplicating the action steps.
Analogy: It’s like rehearsing a play. The stage crew (vision) needs many small tweaks to get the set perfect, while the actors’ movements (actions) only need a few clear cues. Let the stage crew work more often while the actors hold their positions until needed.
What did they find, and why is it important?
Across both simulations and real robots, DUST beat strong baselines.
- Simulated kitchens (RoboCasa): DUST improved success rates by up to about 6% compared to a standard robot model and other “world-model” methods. With their smarter test-time sampling, they got an extra 2–5% boost.
- Humanoid tasks (GR-1): Similar gains—better performance on both simple pick-and-place and tasks with doors/drawers.
- Real robot (Franka arm): About 13% higher success on real pick-and-place tasks compared to baselines. It aligned the gripper better and grasped more reliably.
- Learning from action-free videos: Pretraining on large video datasets (with no action labels) made later robot learning stronger. When they fine-tuned on real robot data, performance jumped significantly. This matters because robot demos are expensive, but videos are cheap.
Why this matters: Robots that can imagine the future make smarter choices. Keeping actions and vision separate but connected helps the robot learn both better. And the test-time trick gives you a handy dial: more steps for vision if you want more accuracy, fewer if you need speed.
What’s the bigger impact?
- Safer, more reliable robots: By predicting what the world will look like after acting, robots can avoid slips and mis-grasps.
- Data efficiency: You can pretrain on mountains of ordinary videos (no robot labels), then fine-tune for real tasks. That lowers cost and speeds up development.
- Better generalization: The robot understands cause-and-effect between actions and outcomes, helping it adapt to new objects and scenes.
- Practical control: The “asynchronous” test-time method gives you a simple way to trade speed for accuracy depending on the situation.
In short, DUST is a practical step toward robots that don’t just react—they plan ahead, using a clearer split-brain setup where actions and future vision learn in their own lanes but still collaborate.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list captures what remains missing, uncertain, or unexplored in the paper, framed as concrete items future researchers can act on:
- Long-horizon prediction and control: The model predicts only a single future embedding at t+k; it does not study multi-step rollouts, compounding errors, or use of the world model for planning (e.g., MPC, multi-chunk lookahead). Evaluate performance when predicting and conditioning on longer horizons and sequences of future observations.
- World-model fidelity metrics: Success rate is the primary metric; there is no quantitative assessment of prediction quality for future observation embeddings (e.g., embedding reconstruction error, semantic consistency, calibration, or correlation with downstream control success). Establish metrics and benchmarks to evaluate and improve the accuracy and usefulness of predicted future embeddings.
- Causality validation: The paper claims bidirectional causal relationships are learned via decoupled noise schedules but provides no causal tests (e.g., interventions, counterfactuals, conditional mutual information). Design experiments that explicitly validate whether actions cause predicted states and vice versa, and quantify causal strength.
- Decoupled training theory: The decomposition of the joint objective into unimodal flow matching losses is asserted (with citation) but not proven for this architecture. Provide theoretical analysis or empirical stress tests showing when independent per-modality noise still yields a correct joint distribution and where it may fail.
- Asynchronous sampling policy: The choice of action/vision step ratio (q) is fixed or grid-searched; there is no adaptive or task-conditioned policy. Investigate adaptive scheduling (e.g., error-based or uncertainty-based step allocation), per-task optimal q, and convergence/latency trade-offs.
- Runtime and real-time feasibility: Inference-time scaling increases denoising steps but runtime is not quantified (latency per control cycle, throughput on robot hardware, memory usage). Report compute budgets and latency to assess real-time applicability and limits on control frequency.
- Failure mode analysis: No systematic analysis of when DUST fails (e.g., occlusions, fast dynamics, slippery or deformable objects, clutter, multi-object interactions). Curate and report failure cases, diagnose error sources (action vs. vision stream), and propose mitigations.
- Embedding choice and robustness: Future observations are SIGLIP-2 embeddings pooled to 64 tokens; the impact of the encoder choice, pooling strategy, token count, and embedding invariances on control and prediction remains untested. Compare different vision encoders, pooling schemes, and token budgets; evaluate robustness to camera/viewpoint changes and lighting.
- Pixel-level vs. embedding-level modeling: The paper adopts embedding prediction to avoid pixel-level details but does not explore hybrid approaches (e.g., low-res pixels, depth, segmentation maps) or the effect of richer visual targets on manipulation tasks. Test whether adding structured visual targets improves dynamics fidelity and control.
- Cross-modal attention design: The shared attention mechanism is fixed; no ablation of attention depth/placement, gating, or constraints to prevent harmful leakage or collapse. Study alternative cross-modal integration designs, regularization (e.g., orthogonality, sparsity), and their impact on stability and performance.
- Modality-specific normalization and timestep embeddings: AdaLN/timestep embedding choices per modality are reported but not compared against alternatives (e.g., FiLM, conditional batch norm, different noise schedules). Ablate conditioning mechanisms and noise schedules to identify robust configurations.
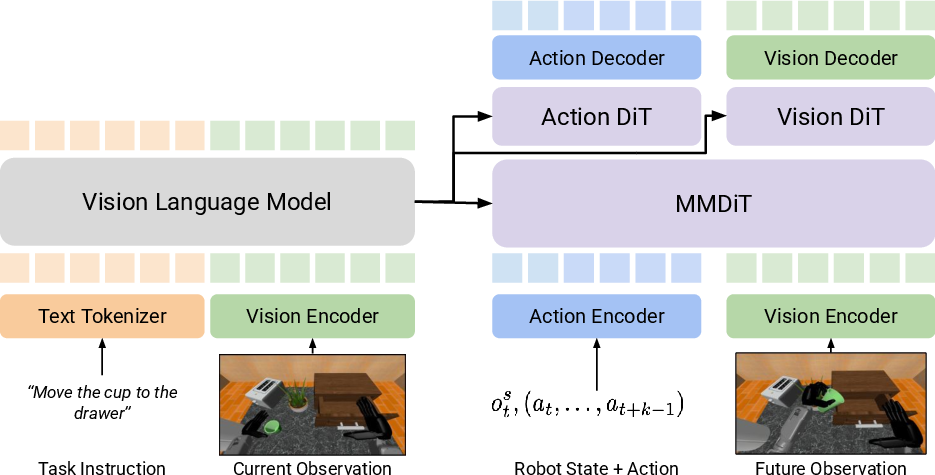
- VLM backbone dependence and tuning: The VLM (Eagle-2) is frozen; the effect of fine-tuning, adapter layers, or alternative VLMs on both action and world-model performance is unknown. Evaluate different backbones, partial fine-tuning strategies, and instruction grounding quality.
- Action representation constraints: Actions are joint positions plus binary gripper in chunks; the method is not evaluated on 6-DoF end-effector actions, torque/force control, compliance, or variable-length action segments. Test diverse action spaces and chunk lengths, and measure their effect on stability and success.
- Generalization across embodiments: Results are limited to a 7-DoF arm and humanoid simulation; cross-embodiment transfer (legged, mobile manipulators) and sim-to-real gaps are unexplored. Assess transferability across robots and the role of world-model pretraining for embodiment-agnostic policies.
- Task diversity and complexity: Real-world evaluation covers only four pick-and-place tasks with modest object variation; articulated, deformable, contact-rich, and long-horizon tasks are underrepresented. Expand real-world benchmarks to stress dynamics modeling and policy robustness.
- Data efficiency and scaling laws: While demo counts vary, there is no systematic scaling-law analysis relating demos, model size, world-model loss weighting, and performance. Derive empirical scaling laws to guide data collection and model sizing.
- Loss weighting strategy: The world-model/action loss weight λWM is tuned via small ablations; there is no principled or adaptive balancing (e.g., uncertainty weighting, gradient norm balancing). Develop and evaluate automated loss balancing strategies.
- BridgeV2 pretraining details and limits: Pretraining uses action-free video, but the data volume, domain match, and role of language supervision (if any) are unclear. Analyze how pretraining scale, domain similarity, and caption/instruction availability affect transfer; study negative transfer cases.
- Alignment between predicted embeddings and true images: The paper assumes that matching future embeddings is sufficient for control; the mapping from embeddings back to actionable visual features is not validated. Audit embedding semantics (e.g., via retrieval or decoders) and verify that predicted embeddings correspond to physically plausible states.
- Robustness to distribution shift: No evaluation under shifts in camera placement, lighting, backgrounds, or object sets beyond the training distribution. Design out-of-distribution tests and domain randomization protocols to measure and improve robustness.
- Safety and recovery: The approach does not address safety constraints, collision avoidance, or recovery from erroneous predictions/actions. Integrate safety-aware planning or constraint handling and report safety metrics.
- Comparative baselines and fairness: FLARE is reimplemented and other joint-latent or causal baselines (e.g., UVA, PAD variants) are not included; fairness of comparisons is uncertain. Add stronger baselines, unified backbones, and controlled training budgets to isolate architectural gains.
- Ensemble and uncertainty: The method is single-model; predictive uncertainty and its use in control (e.g., risk-aware action selection, active exploration) are not explored. Quantify uncertainty (e.g., via ensembles or stochastic sampling) and evaluate its utility for robust decision-making.
- Training stability and optimization: The paper does not report training instabilities, failure to converge, or sensitivity to hyperparameters (noise schedules, step counts, learning rates). Provide stability diagnostics and guidelines to help practitioners reproduce and scale DUST.
- Integration with planning: Joint sampling is used at inference, but integration with planners (e.g., trajectory optimization or tree search using predicted futures) is not evaluated. Test hybrid model-based/model-free pipelines leveraging DUST’s world model for planning.
Glossary
- AdaLN: Adaptive LayerNorm that conditions normalization on additional inputs (e.g., timestep), commonly used in diffusion transformers. "adaptive layernorm (AdaLN)"
- Action expert: A specialized module that generates robot action sequences conditioned on observations and instructions. "action experts (e.g., diffusion policy~\citep{chi2023diffusion})"
- Asynchronous denoising: A sampling procedure where different modalities are denoised at different rates to reflect their dimensionality and dynamics. "we introduce asynchronous denoising, where we take diffusion steps on the high-dimensional vision tokens more frequently than the low-dimensional action tokens."
- Asynchronous forward Euler sampling: An integration scheme that applies forward Euler updates with modality-specific step sizes during joint diffusion sampling. "we introduce a test-time scaling strategy based on asynchronous forward Euler sampling."
- Beta distribution: A continuous distribution used to sample diffusion timesteps over [0,1] with tunable shape parameters. "we sample timestep from a beta distribution as "
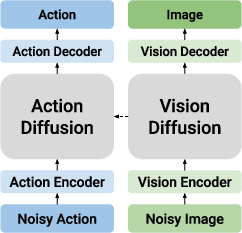
- Causal Diffusion Model: An architecture with separate models for each modality and one-way conditioning, limiting information flow to a single direction. "Causal Diffusion Model"
- Cross-attention: An attention mechanism that lets the action generator attend to conditioning signals from a VLM. "through cross-attention layers in a diffusion transformer (DiT;~\citealt{Peebles2022DiT})"
- Cross-embodiment latent action spaces: Shared action representations designed to generalize across different robot bodies. "cross-embodiment latent action spaces \citep{ye2024lapa, bu2025univla}"
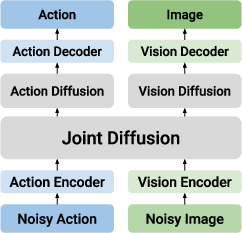
- Cross-modal attention: Attention layers that enable information exchange between action and vision token streams. "shared cross-modal attention layers"
- Decoupled diffusion training algorithm: A training approach that applies independent noise schedules to each modality to learn joint dynamics without a unified latent space. "we introduce a decoupled diffusion training algorithm"
- Decoupled noise scheduling: Injecting independent noise levels into each modality during training to capture causal relationships. "Decoupled noise scheduling."
- Denoising steps: The number of iterative integration steps used to transform noise into data samples. "over denoising steps"
- Diffusion forcing: A training method that uses independent noise levels (often per token) to encourage learning of causal dependencies. "inspired by diffusion forcing \citep{chen2025diff_forcing}"
- Diffusion transformer (DiT): A transformer backbone used for diffusion models to predict velocities over tokens. "diffusion transformer (DiT;~\citealt{Peebles2022DiT})"
- Dual-Stream Diffusion (DUST): The proposed framework that maintains separate action and vision streams with shared attention for joint world-modeling and action prediction. "dual-stream diffusion (DUST)"
- Euler's method: A simple numerical integration method used to integrate the learned velocity field during sampling. "using Euler's method"
- Flow matching: A generative modeling technique that trains a velocity field to transport noise to data along a continuous time parameter. "flow matching objective"
- Flow matching loss: The squared-error objective used to train the velocity network in flow matching. "flow matching loss"
- Future image embedding: A semantic representation of the next visual observation predicted instead of raw pixels. "future image embedding"
- Independent noising schedules: Modality-specific noise schedules applied during training to avoid collapsing into a shared latent space. "independent noising schedules to each modality"
- Multimodal Diffusion Transformer (MMDiT): A transformer that processes action and vision token streams separately while enabling interaction via shared attention. "multimodal diffusion transformer (MMDiT)"
- Proprioceptive state: The robot’s internal state (e.g., joint positions) used as part of the conditioning for action generation. "robot proprioceptive state"
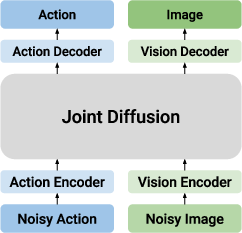
- Shared latent space: A single latent representation assumed to encode multiple modalities; often problematic due to modality mismatch. "shared latent space"
- Test-time scaling: Increasing inference computation (e.g., more vision denoising steps) to trade speed for accuracy. "test-time scaling"
- Timestep embedding: An embedding of the diffusion time parameter fed into the network to condition denoising. "timestep embedding"
- Unified Joint Diffusion Model: An architecture that concatenates modalities and models them with a single diffusion network. "Unified Joint Diffusion Model"
- Uni-directional conditioning: Conditioning that allows information flow in only one direction between modalities. "uni-directional conditioning"
- Velocity field: The vector field predicted by the diffusion model that points from noise toward data. "velocity field"
- Vision-language-action model (VLA): A model that uses visual and textual inputs to generate robot actions. "Vision-language-action models (VLAs)"
- Vision-LLM (VLM): A model pretrained on large-scale image–text data that provides joint semantic representations. "vision-LLMs (VLMs)"
- World-modeling: Learning to predict future states or observations to capture physical dynamics and guide policy learning. "world-modeling objectives"
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s findings and methods, particularly the DUST architecture (dual-stream diffusion with decoupled training and asynchronous joint sampling), embedding-based world modeling, and action-free video pretraining.
Robotics and Industrial Automation
- Robotic pick-and-place with higher robustness (factory, warehouse, lab)
- Sector: Robotics, Manufacturing, Logistics
- What: Replace or fine-tune existing VLA/diffusion policy stacks to jointly predict actions and future-state embeddings, improving grasp alignment and success rates for bin picking, kitting, packaging, palletizing, and lab sample handling.
- Tools/Products/Workflows:
- A DUST-based “Action+Prediction Policy” module integrated as a ROS2 node; plugin for Franka/UR/ABB controllers.
- Isaac Sim/Unreal simulation training with DUST’s decoupled losses; evaluation on RoboCasa-like task suites.
- Inference-time scaling “q-knob” for critical steps (e.g., contact phases): boost vision denoising steps without slowing the entire cycle.
- Assumptions/Dependencies:
- Access to a strong frozen VLM (e.g., Eagle-2/SIGLIP-2) and compatible licensing.
- Sufficient GPU for real-time inference at chosen N_A, N_o; acceptable latency budget.
- Fixed or well-calibrated camera viewpoints to stabilize embeddings.
- Retail shelf restocking and store logistics
- Sector: Retail Robotics, Logistics
- What: Robust object relocation where world-model prediction reduces collision and misplacement by anticipating state changes (doors/drawers/faucets, object orientation).
- Tools/Products/Workflows:
- Shelf restocking workflow with DUST-based policy; monitoring predicted future embeddings for pre-emptive recovery.
- Assumptions/Dependencies:
- Domain-relevant demonstrations or video pretraining; consistent store layouts.
- Teleoperation assist with predictive overlays
- Sector: Teleoperation, Remote Robotics
- What: Use DUST’s predicted future embedding to visualize likely end-effector pose/scene alignment, guiding operators during grasp/insert phases.
- Tools/Products/Workflows:
- A UI overlay in teleop dashboards that renders “future-embedding-aligned” cues (e.g., highlighting expected contact points).
- Assumptions/Dependencies:
- Stable latency; reliable mapping from embeddings to visual cues.
- Vision-conditioned quality assurance and recovery
- Sector: Manufacturing QA, Robotics
- What: Compare predicted future embeddings to actual post-action embeddings to detect mis-execution; trigger re-grasp or corrective actions.
- Tools/Products/Workflows:
- Anomaly detector operating on embedding-space residuals; recovery policy library.
- Assumptions/Dependencies:
- Good coverage of task variance during training; calibrated thresholds for residuals.
Warehouse, Fulfillment, and Logistics
- Mixed-shape item handling with test-time scaling
- Sector: Logistics, E-commerce
- What: Dynamically increase vision denoising steps (N_o) for challenging SKUs, improving pick success without globally increasing latency.
- Tools/Products/Workflows:
- Policy server with per-item “difficulty profiles” mapping to q (N_o = q × N_A).
- Assumptions/Dependencies:
- SKU classification upstream; compute headroom for on-demand scaling.
Healthcare and Elder Care (Non-critical Tasks)
- Hospital supply runs and room tidying by mobile manipulators
- Sector: Healthcare Operations, Service Robotics
- What: Safer, more reliable fetch-and-place in semi-structured wards by predicting near-future states as actions are planned.
- Tools/Products/Workflows:
- DUST-infused mobile manipulator policies; simulation pretraining on action-free hospital workflows (privacy-safe videos).
- Assumptions/Dependencies:
- Non-surgical, non-critical tasks; strong safety wrappers; compliance with privacy and data standards.
Education and Academic Research
- Low-data robotics courses and labs
- Sector: Education, Academia
- What: Use action-free video pretraining (e.g., BridgeV2) to reduce demonstration collection; teach causal, bidirectional learning via decoupled noising.
- Tools/Products/Workflows:
- Starter kits: DUST training scripts, MMDiT blocks, demo-to-policy pipelines, RoboCasa/GR-1 eval harnesses.
- Assumptions/Dependencies:
- GPU availability; access to public video datasets; clear lab safety protocols.
Software and Agentics
- GUI automation and tool-use agents that predict UI state transitions
- Sector: Software Automation, Enterprise IT
- What: Apply dual-stream formulation to “action tokens” (clicks, keystrokes) and “future-UI embeddings” (screen representations) to reduce cascading errors in multi-step UI tasks.
- Tools/Products/Workflows:
- Screen-embedding adapters (e.g., CLIP-like) and DUST-style decoupled training; asynchronous sampling for high-res UI states.
- Assumptions/Dependencies:
- Stable UI embedding extractor; dataset of action-free screen recordings + few action-labeled demos.
Long-Term Applications
The following require further research, larger-scale validation, safety cases, or infrastructure.
Generalist Home and Service Robots
- Open-world household assistance (cooking prep, laundry, tidying)
- Sector: Consumer Robotics, Smart Home
- What: A single DUST-like policy that generalizes across diverse homes, objects, and long-horizon tasks by combining world modeling, language goals, and planning.
- Tools/Products/Workflows:
- Massive action-free video pretraining (household videos), followed by targeted teleop demos; hierarchical planning layers over DUST.
- Assumptions/Dependencies:
- Scalable data curation; robust sim2real; safety certification and user trust frameworks.
- Assistive care and rehabilitation robotics
- Sector: Healthcare, Assistive Tech
- What: Physical assistance (meal support, fetching, dressing aids) with reliable prediction of contact outcomes and safety-aware action generation.
- Tools/Products/Workflows:
- Safety-constrained DUST with uncertainty estimation; compliance control integration; fine-grained failure detection.
- Assumptions/Dependencies:
- Regulatory approval; rigorous clinical trials; guarantees around out-of-distribution behavior.
Advanced Industrial Autonomy
- Contact-rich assembly and deformable object manipulation
- Sector: Manufacturing, Electronics, Food Processing
- What: Joint prediction of action and complex future states (deformables, fine tolerances) via richer world-model targets beyond static embeddings.
- Tools/Products/Workflows:
- Multi-sensor fusion (force/torque, tactile) as additional streams; learned uncertainty-aware asynchronous sampling.
- Assumptions/Dependencies:
- New encoders for non-visual modalities; high-fidelity data; real-time control constraints.
- Autonomous mobile manipulation in dynamic environments
- Sector: Warehousing, Construction, Field Robotics
- What: Couple locomotion actions and future-scene embeddings in crowded, changing environments.
- Tools/Products/Workflows:
- Extensions to multimodal planning (3D occupancy embeddings, scene graph evolution); integration with SLAM.
- Assumptions/Dependencies:
- Robust multi-view perception; on-robot compute scaling; resilient safety layers.
Autonomous Driving and Embodied AI
- Joint plan-and-predict policies for autonomous driving
- Sector: Transportation, Automotive
- What: Treat control trajectories as actions and future scene embeddings as visual outcomes; decoupled-noise training to learn causal bidirectionality between plans and predicted traffic evolution.
- Tools/Products/Workflows:
- HD map and sensor fusion encoders; regulator-ready validation harnesses; asynchronous sampling for high-dimensional sensor embeddings.
- Assumptions/Dependencies:
- Safety-critical certification; real-time latency guarantees; dataset scale and coverage.
- Multi-agent collaboration with shared world models
- Sector: Robotics, Logistics, Defense
- What: Agents exchange predicted future embeddings to coordinate without tight hand-crafted communication protocols.
- Tools/Products/Workflows:
- Communication-efficient embedding sharing; consensus over predicted futures; conflict resolution policies.
- Assumptions/Dependencies:
- Network reliability; privacy/security of shared embeddings; scalable training curricula.
Foundation-Model-Scale Training and Tooling
- Video-first pretraining pipelines that minimize teleop data
- Sector: AI Infrastructure, MLOps
- What: Cloud-scale “action-free pretraining as a service,” producing transferable world models for many robot form factors.
- Tools/Products/Workflows:
- Data governance stacks (privacy, IP filtering); automated domain adaptation; standardized evaluation suites (RoboCasa/GR-1++/real-world).
- Assumptions/Dependencies:
- Access to massive, diverse, rights-cleared video; cost-effective GPUs; reproducibility and auditing.
- Uncertainty-aware, safety-certified VLA stacks
- Sector: Safety, Regulation, Insurance
- What: Wrap DUST with calibrated uncertainty and counterfactual checks on predicted futures to meet safety standards (ISO/IEC).
- Tools/Products/Workflows:
- Conformal prediction on embedding trajectories; certifiable controllers with fallback policies; scenario-based testing.
- Assumptions/Dependencies:
- Agreed industry metrics; policy frameworks for acceptable risk; third-party certification ecosystems.
Software, UX, and Human-in-the-Loop Systems
- Predict-then-act UX for collaborative robots (cobots)
- Sector: HRI, Manufacturing
- What: Interfaces that preview the predicted scene outcome before committing actions, enabling human override or refinement.
- Tools/Products/Workflows:
- “Preview UI” integrated into teach pendants; slider for test-time scaling to increase prediction fidelity on-demand.
- Assumptions/Dependencies:
- Natural UIs for embedding visualizations; operator training; latency vs. throughput trade-offs.
- General multimodal planning where actions and outcomes live in different spaces
- Sector: Software Agents, Creative Tools
- What: Apply dual-stream diffusion to domains like CAD/CAM, AR/VR authoring, where low-dim actions yield high-dim outcomes (layouts, scenes).
- Tools/Products/Workflows:
- Domain-specific outcome encoders; DUST-style decoupled losses; asynchronous sampling for complex outputs.
- Assumptions/Dependencies:
- High-quality embedding spaces; task-specific datasets; tight integration with design tools.
Notes on feasibility and cross-cutting dependencies
- Compute and latency: MMDiT + DiT stacks with even 4–64 denoising steps demand edge GPUs or low-latency networking for cloud offload; the q parameter offers a practical knob.
- Data and transfer: Performance hinges on domain-relevant demos and/or large-scale action-free video; sim2real mitigation is still necessary.
- Safety and reliability: Embedding-level prediction may hide pixel-level hazards; uncertainty estimation and verification loops are recommended in safety-critical contexts.
- Generalization: Results were shown on manipulator tasks (RoboCasa, GR-1, Franka); nonstationary sensors, deformables, and tight-tolerance assembly will require additional research and sensing.
- Licensing and governance: VLM backbones (Eagle-2/SIGLIP-2) and datasets (BridgeV2) must be used under appropriate licenses; privacy vetting for video pretraining data is critical.
Collections
Sign up for free to add this paper to one or more collections.

