Published 13 Jan 2026 in cs.LG and cs.AI | (2601.08393v1)
Abstract: Scaling large models requires optimization strategies that ensure rapid convergence grounded in stability. Maximal Update Parametrization ($\boldsymbolμ$P) provides a theoretical safeguard for width-invariant $Θ(1)$ activation control, whereas emerging optimizers like Muon are only ``half-aligned'' with these constraints: they control updates but allow weights to drift. To address this limitation, we introduce the \textbf{Spectral Sphere Optimizer (SSO)}, which enforces strict module-wise spectral constraints on both weights and their updates. By deriving the steepest descent direction on the spectral sphere, SSO realizes a fully $\boldsymbolμ$P-aligned optimization process. To enable large-scale training, we implement SSO as an efficient parallel algorithm within Megatron. Through extensive pretraining on diverse architectures, including Dense 1.7B, MoE 8B-A1B, and 200-layer DeepNet models, SSO consistently outperforms AdamW and Muon. Furthermore, we observe significant practical stability benefits, including improved MoE router load balancing, suppressed outliers, and strictly bounded activations.
The paper introduces the Spectral Sphere Optimizer (SSO) to enforce maximal update parametrization and spectral constraints, ensuring controlled activations during LLM training.
It employs a constrained steepest descent on a spectral sphere using a Lagrange multiplier strategy to balance rapid convergence with strict stability.
Empirical results demonstrate that SSO outperforms traditional methods by achieving up to 19% fewer training steps and robust performance across varied architectures.
Spectral Sphere Optimization: Controlled LLM Training on Spectral Manifolds
Introduction
This work presents the Spectral Sphere Optimizer (SSO), a method targeting both rapid convergence and strict stability for LLM pretraining by constraining both weights and updates to a spectral sphere manifold. SSO directly addresses the fundamental problem in LLM scaling: ensuring that model activations remain tightly controlled across optimization, which conventional approaches and even recent spectral optimizers like Muon fail to guarantee. The core innovation is to derive steepest descent on the spectral sphere, systematically enforcing Maximal Update Parametrization (μP) constraints at all times. This yields strong stability in training dynamics, improved scaling laws, and superior empirical performance.
Background: Maximal Update Parametrization and Spectral Constraints
μP scaling theory dictates that to preserve scale-invariant activations, the spectral norms of both weights and updates in deep models should scale as Θ(dout/din). Empirical instability in LLM pretraining is typically rooted in violations of this law. Approaches like weight decay or custom initializations provide only soft, transient regularization, allowing weights to drift and amplifying the risk of activation explosions or degraded feature learning.
The state-of-the-art Muon optimizer interprets weight updates as steepest descent under the spectral norm, resulting in highly isotropic, spectrum-aligned updates. However, Muon constrains only the update direction—not the forward weights. As confirmed in deep training runs, this leaves open the possibility of instabilities, such as attention outlier explosions or drifted hidden state norms, which then necessitate aggressive normalization or other architectural patches.
Spectral Sphere Optimizer: Methodology
SSO seeks a unique intersection: it enforces both the μP spectral scaling law and the steepest descent update, within the geometry of the spectral sphere. At each optimizer step, the task is to find a direction on the tangential space of the spectral sphere tailored to both maximize descent (for convergence) and strictly maintain the radius (for stability).
This is accomplished by formulating a constrained maximization problem:
Tangent Constraint: Updates must be orthogonal to the top singular direction of the weight matrix, ensuring preserved spectral norm radius to first order.
Constrained Descent: The update direction is the unique solution (found via a Lagrange multiplier) that maximizes descent while staying within the sphere's tangent space.
Retraction: Any higher-order drift in the spectral norm is corrected via retraction—projecting the weights back onto the spectral manifold. This makes weight decay redundant for hidden 2D weight matrices, strictly enforcing norm control.
A bracketing and bisection root-finding algorithm is used to solve for the correct λ multiplier at each step, capitalizing on the monotonicity and boundedness of the duality constraint function (see Appendix A for proofs).
Figure 1: The spectral sphere geometry constrains weights and updates to an invariant-radii manifold, with the tangent space defining the feasible update region at each optimization step.
Algorithm Implementation and System Design
Integrating SSO efficiently for distributed, large-scale training poses nontrivial engineering challenges, mainly due to iterative solvers for the Lagrange multiplier and the need for matrix-wise (not element-wise) updates:
Atomic Module Sharding: Parameters are sharded as atomic modules (e.g. per-head Q/K/V, FFN gate/up) to allow independent, communication-free local updates.
Workload Balancing: A "ping-pong" strategy sorts and distributes modules by size for effective load balancing in distributed setups.
Kernel Adaptation and Parallelism: The implementation dispatches matrix operations to either custom or general kernels based on matrix size; multiple CUDA streams are used to minimize latency, with BFloat16 and cached singular vectors used for precision and speed.
Sharp reductions in training latency were obtained through these system optimizations.
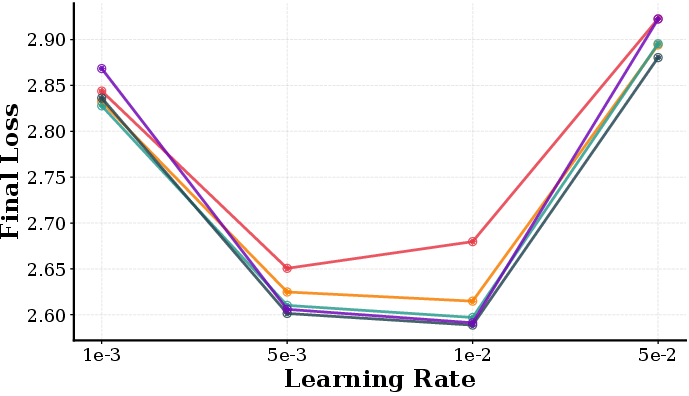
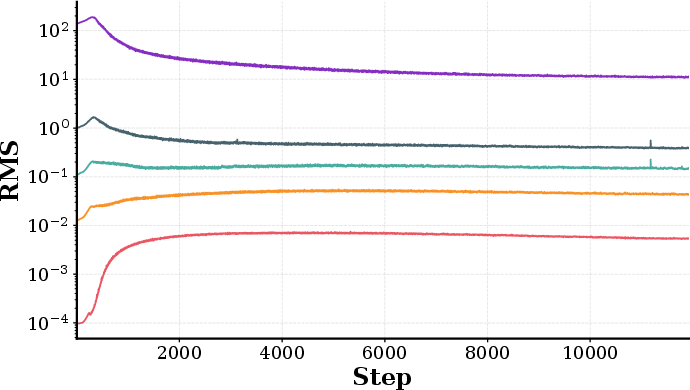
Choice of the spectral radius scale (constant c in R=cdout/din) directly tunes the energy transfer in residual pathways and is essential for stable and performant scaling. Ablation on radius scale shows that moderate settings yield lowest validation loss, with clear scaling effects on activation RMS and maximum values.
Figure 2: Ablation of radius scale—final loss, FFN activation AbsMax, and RMS as a function of the spectral radius constant.
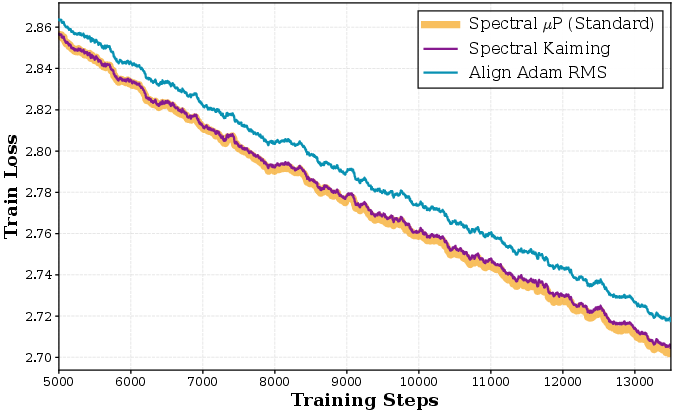
Learning rate scaling is critical for safe and efficient transfer across widths and depths in LLMs. The spectral μP scaler outperformed both heuristics (Align-Adam-RMS, Spectral Kaiming) in both theory and grid search ablation studies.
Figure 3: Validation loss curves for alternative learning rate scalers, showing SSO's advantage.
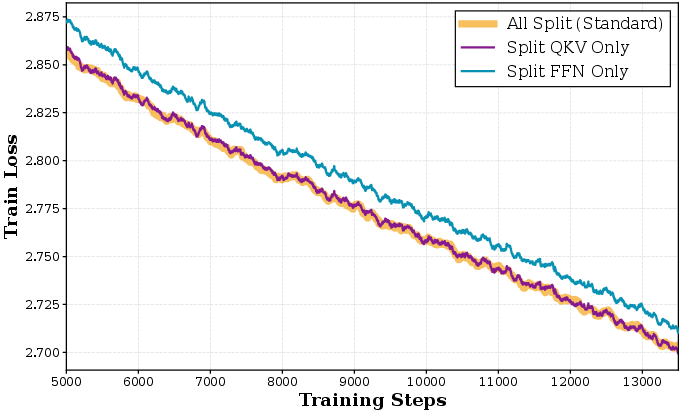
Granular application of spectral constraints—splitting QKV per head and separating FFN matrices—yields tangible gains over monolithic fused tensors, in line with the distinct functional roles of submodules.
Figure 4: Module-splitting ablation demonstrates that per-head (QKV) spectral normalization is critical for optimal performance.
Empirical Results: Stability and Generalization
SSO's empirical performance was validated on multiple architectures, including dense 1.7B parameter LLMs, 8B-A1B MoE, and 200-layer DeepNets.
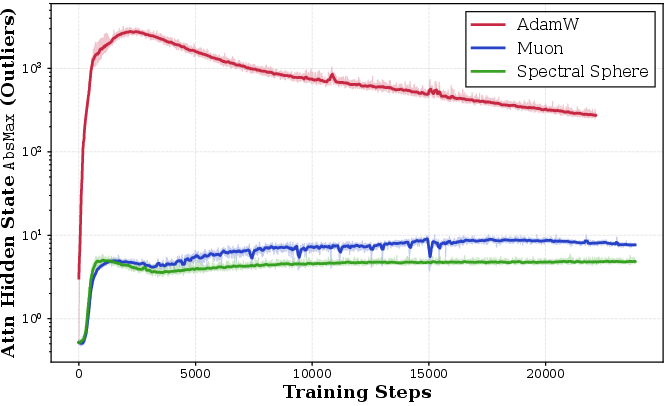
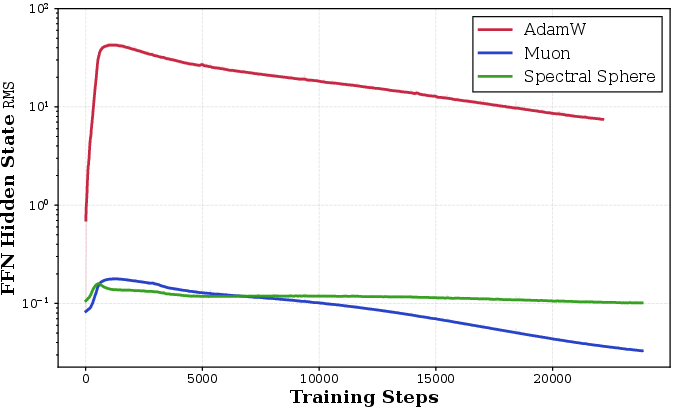
Activation Dynamics and Outlier Suppression: SSO uniquely maintains strictly bounded, stable activations throughout training, outperforming Muon (which shows mild drift) and AdamW (which suffers order-of-magnitude scale blowups).
Figure 5: Attention activation AbsMax outliers are effectively suppressed by Spectral Sphere across training steps.
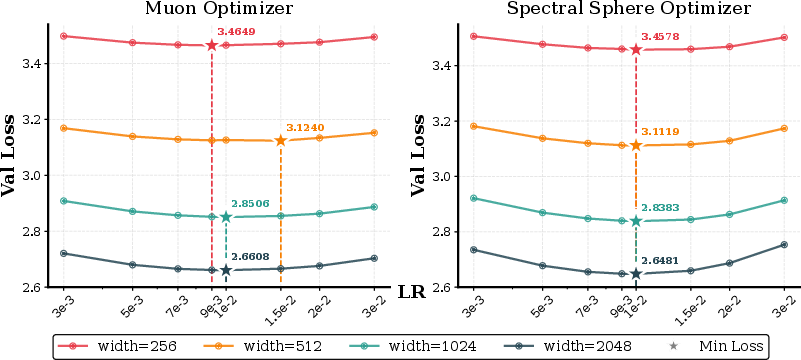
Scaling Laws and LR Transfer: SSO sustains width-invariant loss and optimal learning rate transfer across 25× model size scaling, whereas both Muon and AdamW drift from the theoretical μP scaling, with higher validation loss at scale.
Figure 6: Learning rate scaling and corresponding losses over a model size sweep confirm μP alignment and superior transfer.
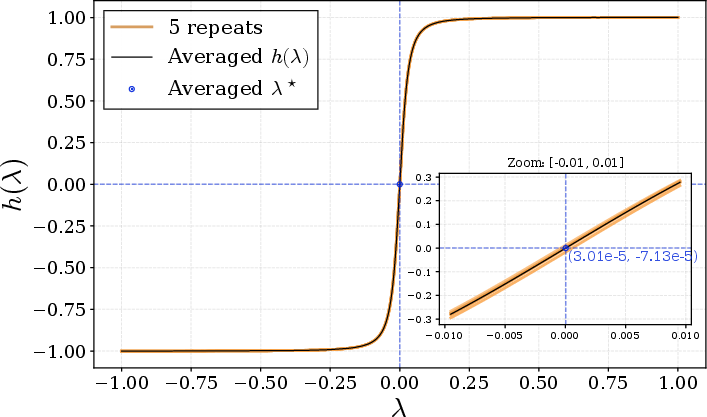
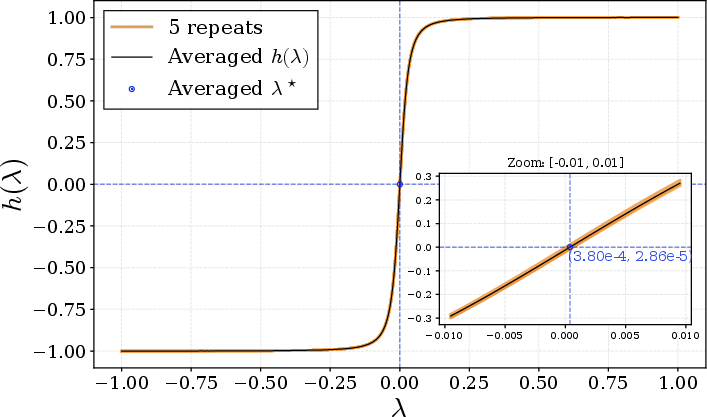
Matrix Root Solver Behavior: Empirical validation of the Lagrange multiplier root-finding shows rapid convergence across practical matrix shapes, ensuring that SSO remains tractable as width grows.
Figure 7: h(λ) is monotonic in λ for a 1024×3072 matrix; the root is easily bracketed and found.
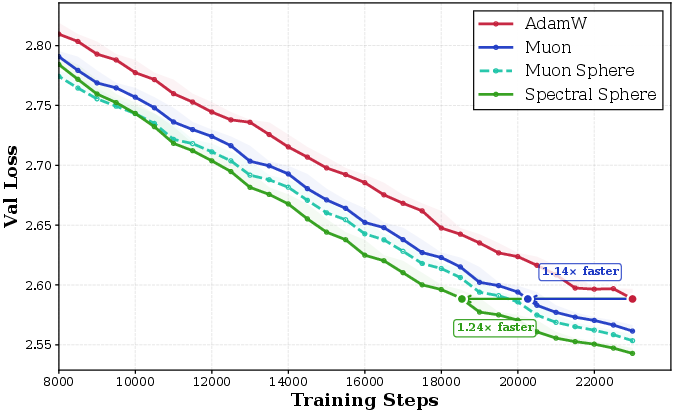
Training Loss and Final Performance: On dense 1.7B, SSO consistently outperforms baselines—empirically requiring 19% fewer steps to reach AdamW-equivalent validation loss, and achieving higher downstream task accuracy.
Figure 8: Validation loss trajectory for the dense 1.7B transformer, highlighting spectral-based optimizers’ efficiency.
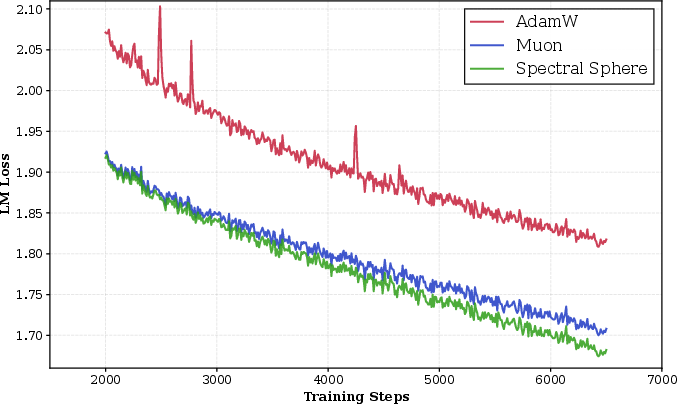
Extreme Depth Stability Stress Test: In 200-layer DeepNets, SSO remains robust, whereas AdamW exhibits frequent spikes and degraded convergence.
Figure 9: Training loss for 200-layer DeepNet shows SSO’s high stability and efficiency.
MoE Routing and Load Balance: SSO significantly improves load balancing in MoE architectures, reducing MaxVio spikes and improving expert utilization.
Theoretical and Practical Implications
Spectral sphere optimization not only formalizes but strictly enforces the spectral μP conditions that, if neglected, cause most training instabilities and scaling law deviations in large models. While Stiefel manifold optimization is even more restrictive (all singular values = 1), SSO’s focus on the leading singular value achieves a balance between stability and spectrum flexibility, avoiding unnecessary constraints on expressivity.
Practically, the SSO methodology removes the need for brittle ad-hoc stabilization techniques, introduces a hyperparameter-free solution for scale, and delivers reliable activation control—paving the way for robust low-precision or fully manifold-constrained architectures. Future directions include optimizing the Lagrange solver for GPU-native execution and extending spectral manifold constraints to other critical structures (e.g. residual streams).
Conclusion
The Spectral Sphere Optimizer presents a comprehensive, theoretically justified, and empirically validated solution to the critical challenge of stable, efficient LLM scaling. Its manifold-constrained update scheme unifies the goals of fast convergence and activation control, outperforming dominant baselines across depth, scale, and architecture variants. This work establishes both a new optimization primitive for deep learning and a robust engineering framework, setting the stage for the broader adoption of manifold-constrained optimization in large model pretraining and deployment.
References:
"Controlled LLM Training on Spectral Sphere" (2601.08393)