- The paper establishes that curvature-aware optimizers (e.g., KFAC) achieve statistically optimal feature learning, surpassing classical first-order methods.
- It presents modular norm design that reframes optimizer construction, enabling layerwise hyperparameter transfer and robust scaling in large-scale training.
- Empirical experiments confirm that advanced preconditioning and tailored learning rate schedules lead to faster convergence and improved generalization.
Guided Descent: Algorithmic Principles and Practical Innovations for Neural Network Optimization
Introduction
This work provides a comprehensive analysis of the algorithmic evolution, foundational principles, and practical integration strategies for optimization algorithms in large-scale neural network training. It dissects the empirical success of canonical algorithms like SGD and Adam, exposing their limitations through the lens of geometry and statistical feature learning. The study establishes a throughline from classical first-order and second-order methods to recent advances in curvature-aware optimization, modular norm-based design, and large-scale engineering practices.
Classical Optimization Methods: Foundations and Limitations
The initial investigation deconstructs the empirical success and theoretical shortcomings of first-order optimizers.
Pure SGD and its momentum-based variants (Polyak, Nesterov) are documented to be limited by their axis-aligned update schemes, struggling in highly anisotropic or ill-conditioned loss landscapes and failing in effective feature learning when input data exhibits strong covariance structure (Figure 1).
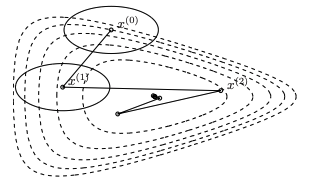
Figure 1: Visualization of steepest descent under a quadratic norm, highlighting slow convergence in ill-conditioned valleys.
Second-order methods (Newton’s, quasi-Newton, L-BFGS) provide affine-invariant convergence and rapid minimization in convex landscapes. However, their computational infeasibility for billion-parameter models, sensitivity to stochastic gradients, and lack of out-of-sample generalization robustness restrict practical adoption. The problem is further highlighted by empirical evidence that, in nonconvex high-dimensional settings, second-order trajectories often converge to suboptimal sharp minima, impacting generalization.
Curvature-Aware Preconditioning: From Gauss-Newton to Structured Approximations
The paper thoroughly reviews curvature matrix-based preconditioners, particularly the Fisher Information Matrix (FIM) and Generalized Gauss-Newton (GGN), and discusses the computational impracticalities of direct usage.
KFAC is meticulously developed as the canonical structured approximation, exploiting layerwise Kronecker factorization to achieve efficient storage and inversion:



Figure 2: Iterative comparison of KFAC, natural gradient descent, and first-order methods on a linear feature learning task, indicating that KFAC surpasses even full-matrix second-order methods.
The analysis connects KFAC’s structure with the statistical necessity for feature whitening and quantifies exactly when SGD/Adam become suboptimal under realistic (anisotropic) data distributions. Empirical experiments confirm that KFAC’s layerwise preconditioning yields statistically optimal convergence rates for feature learning, robust to poor input conditioning.
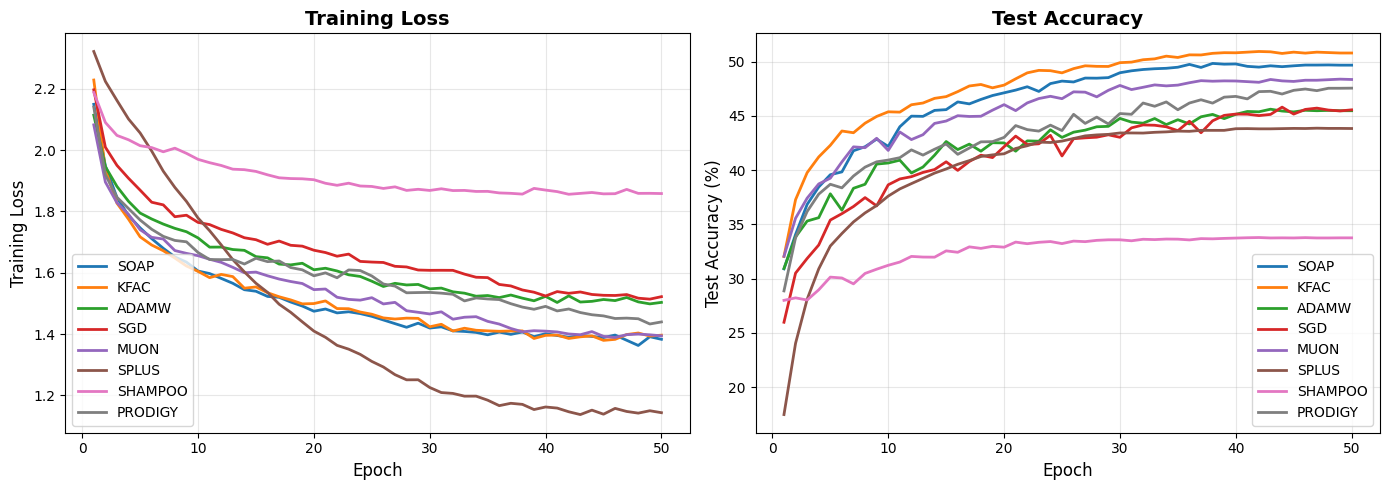
Recent methodological branches (EKFAC, Shampoo, SOAP, SPlus, Muon) derive from the inefficiencies or instability of canonical KFAC. These variants introduce eigenbasis updates, matrix power roots, instantaneous normalization, and efficient orthogonalization, thereby enabling high performance in large-batch, high-dimensional regimes with practical wall-clock efficiency.
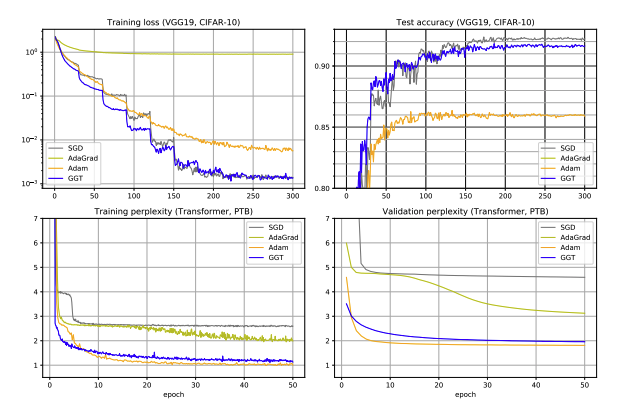
Figure 3: GGT adaptive method and its AdaGrad counterpart display instability; KFAC-type methods yield significantly more reliable convergence.
Modular Norms and Duality Maps: Reframing Optimizer Design
A unifying theoretical framework is established via the modular norm approach, reframing optimizer design as the problem of choosing geometry- and layer-aware update norms and their corresponding duality maps.
- The analysis demonstrates that standard optimizers are recoverable as steepest descent under norm-induced dual maps: Adam as max-of-max norm, Shampoo as spectral norm, Prodigy as norm-adaptive sign descent.
- The choice of norm (spectral, operator, block-based) is shown to govern not only convergence rates but also the expressivity and reachable solution class during training, as demonstrated in weight “erasure” experiments.
- The theory is tied to practical toolkits (modula library) enabling layerwise mixing of dualized optimizers, and it establishes the invariance or schedule insensitivity property of appropriately modularized optimizers, which ensures that learning rate transfer is highly robust under scaling.
Interaction with Large-Scale Training Practices
The work considers modern large-scale training “tooling,” including:
- Maximal Update Parameterization (μP), which ensures width-invariant hyperparameter transfer by aligning initialization, learning rates, layer-wise dampening, and optimizer assignment.
- Learning Rate Schedules: It formally justifies the empirical popularity of linear decay, constant+cooldown, and WSD schedules, showing that they are nearly optimal under realistic objectives and critically impact final generalization via bias-variance tradeoffs in the cooldown phase (Figure 4).
- Exponential Moving Averages: The role of EMA in biasing and stabilizing both parameter and optimizer trajectories is deconstructed, highlighting innovations like BEMA that eliminate the instability of early-iteration bias correction (Figure 5).
- Weight Decay: The study uncovers the mechanism of rotational equilibrium for normalized layers, explaining how decoupled and scheduled weight decay coordinate layerwise angular updates, correct schedule-induced pathologies, and improve optimizer compatibility.
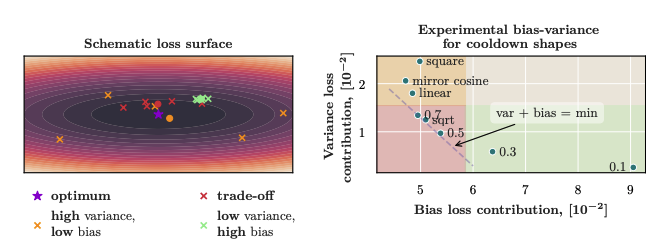
Figure 4: Cooldown bias-variance decomposition showing that square-root decay achieves superior tradeoff near the minimum bias-plus-variance region.
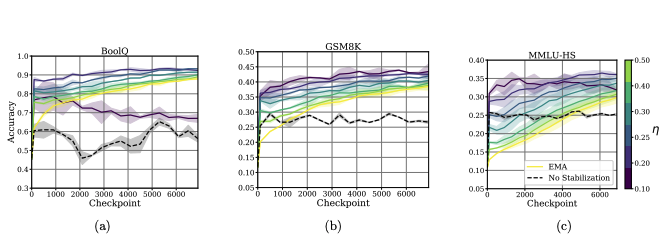
Figure 5: Effects of BEMA bias power η in stabilizing early training for fine-tuning LLMs; excessive correction leads to instability.
Empirical Validation
Experiments ground the theoretical exposition through controlled MLP/CIFAR experiments, head-to-head optimizer comparisons, learning rate schedule ablations, and demonstrations of modula library capabilities. Key findings include:
Implications and Future Research
This analysis exposes critical practical and theoretical frontiers:
- Curvature-aware optimizers (especially Muon and KFAC) are not crude approximations but statistically optimal feature learners—often exceeding the performance of even their full-matrix antecedents.
- Modular norm design codifies optimizer/architecture alignment, facilitating both hyperparameter transfer and robust scaling, and reorients optimizer choice from monolithic to layerwise.
- For cutting edge foundation model pretraining, these methods provide substantial compute advantages and are likely already deployed in industrial labs.
- Open issues remain in formalizing the interaction of EMA, learning rate schedules, and modular norm updates, especially for modern architectures (Transformers) and components with non-Euclidean parameter geometries.
- Progress in hardware-aware implementations (e.g., SVD acceleration, dynamic sketching) will further reduce the FLOP overhead of duality map computation.
Conclusion
The reviewed research demonstrates that principled optimizer design—rooted in problem geometry, statistical feature learning, and modular dual map selection—yields methods that are computation-efficient, scale-robust, and offer explainable improvement beyond classical approaches. The future of neural network training will be governed by the seamless integration of curvature-aware algorithms, norm-induced modular adaptation, principled scheduling tactics, and scalable engineering, closing the gap between theory and empirical efficacy in deep learning optimization (2512.18373).