How to Set the Learning Rate for Large-Scale Pre-training?
Abstract: Optimal configuration of the learning rate (LR) is a fundamental yet formidable challenge in large-scale pre-training. Given the stringent trade-off between training costs and model performance, the pivotal question is whether the optimal LR can be accurately extrapolated from low-cost experiments. In this paper, we formalize this investigation into two distinct research paradigms: Fitting and Transfer. Within the Fitting Paradigm, we innovatively introduce a Scaling Law for search factor, effectively reducing the search complexity from O(n3) to O(n*C_D*C_η) via predictive modeling. Within the Transfer Paradigm, we extend the principles of $μ$Transfer to the Mixture of Experts (MoE) architecture, broadening its applicability to encompass model depth, weight decay, and token horizons. By pushing the boundaries of existing hyperparameter research in terms of scale, we conduct a comprehensive comparison between these two paradigms. Our empirical results challenge the scalability of the widely adopted $μ$ Transfer in large-scale pre-training scenarios. Furthermore, we provide a rigorous analysis through the dual lenses of training stability and feature learning to elucidate the underlying reasons why module-wise parameter tuning underperforms in large-scale settings. This work offers systematic practical guidelines and a fresh theoretical perspective for optimizing industrial-level pre-training.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about choosing the right “learning rate” when training very large AI LLMs. The learning rate is like the step size your model takes while learning. If the step is too big, training can wobble or crash; if it’s too small, learning is slow and wastes time and money. The authors ask: can we figure out the best learning rate for huge models by running cheaper, smaller experiments first?
They compare two ways to do this:
- Fitting: run small experiments, find patterns, and build a formula that predicts the best learning rate at big scale.
- Transfer: use rules called μTransfer to copy good settings from a small “proxy” model to a large “target” model.
Key Questions
The paper focuses on simple versions of these big questions:
- How do we pick a learning rate that works well for very large models and very long training runs?
- Can small, cheap experiments reliably predict the best learning rate for big, expensive training?
- Which approach works better at scale: fitting a formula from data, or transferring settings using μTransfer?
- Do different parts of the model need different learning rates, or is one global learning rate enough?
Methods and Approach
The authors study training under a common schedule called Warmup–Stable–Decay (WSD):
- Warmup: slowly increase the learning rate at the start.
- Stable: keep the learning rate constant for a long time (often weeks).
- Decay: reduce the learning rate at the end to polish the model on higher-quality data.
They test two paradigms:
Fitting Paradigm
Think of this like finding the “Goldilocks zone” of the learning rate by drawing a curve:
- They run small experiments with different learning rates and record the validation loss (how well the model is doing on held-out data).
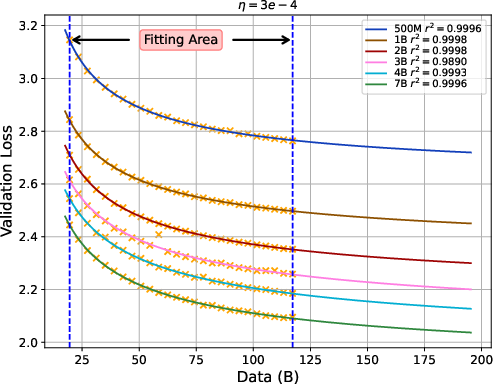
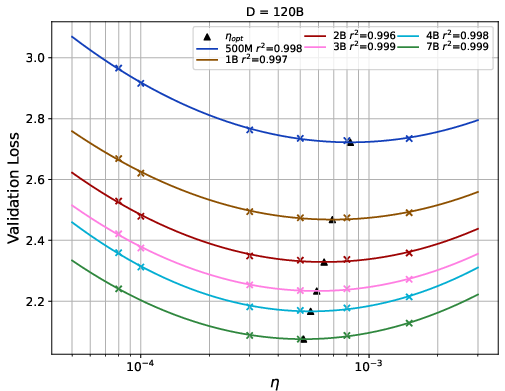
- The loss versus learning rate curve looks like a smooth “U” when plotted in log space, meaning there is a sweet spot. They fit this curve using a simple quadratic (a parabola) to estimate the best learning rate.
- They also use “scaling laws,” which are patterns that show how performance changes with more data. Here, loss decreases roughly as a power of the number of training tokens. This lets them predict results at larger data sizes from fewer experiments.
- With these patterns, they build a rule-of-thumb formula that predicts the best learning rate from model size and data size. In short: as models and datasets get bigger, the best learning rate gets smaller.
An example of the learned rule:
- Lr(N, D) ≈ 38.46 × N-0.22 × D-0.35
- N is the number of model parameters; D is the number of training tokens. The negative exponents mean you should reduce the learning rate when you scale up the model or the data.
This approach reduces the number of experiments needed, saving time and money.
Transfer Paradigm (μTransfer)
μParametrization (μP) and μTransfer are methods designed to keep training stable when scaling model width and depth. The idea:
- Tune hyperparameters (like learning rate) on a small proxy model.
- Transfer those settings to larger models using μTransfer rules, so the bigger model trains with similar behavior.
In this paper:
- They extend μTransfer to Mixture of Experts (MoE) models (a popular large-model architecture where only some “experts” are active for each token).
- They consider width, depth, weight decay (a gentle pull that keeps weights from growing too large), and the total training tokens (the “token horizon”).
- They keep the optimizer and schedule consistent (AdamW, WSD) and compare performance at larger scales.
Main Findings and Why They Matter
Here are the main results, explained clearly:
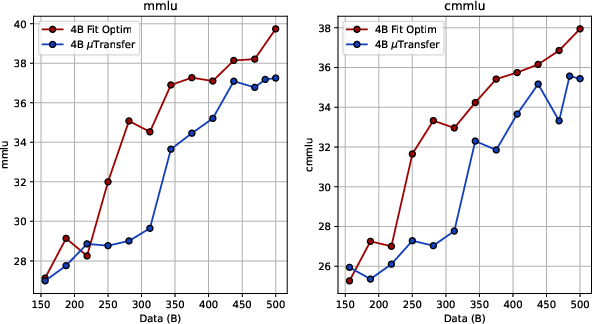
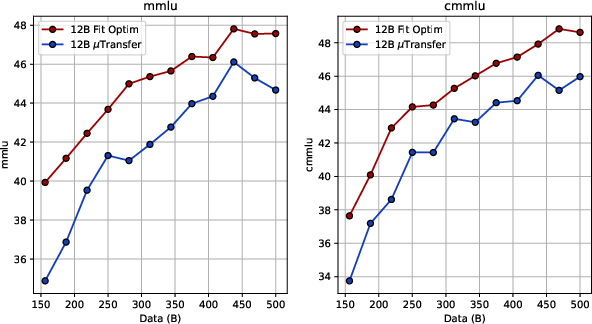
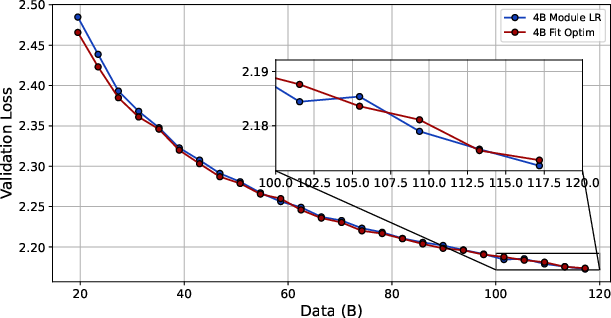
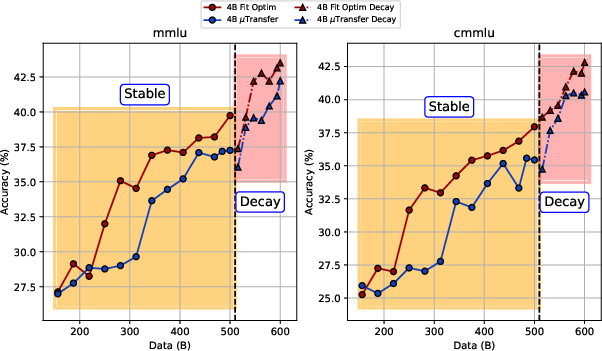
- The fitting approach consistently beats μTransfer at large scale. When they trained bigger MoE models (around 4B and 12B parameters) on very long runs (up to 500B tokens), the learning rate predicted by the fitting law produced better downstream scores (like MMLU and CMMLU) than μTransfer. Even after the decay phase on higher-quality data, fitting stayed ahead, improving accuracy by roughly 1–2 percentage points.
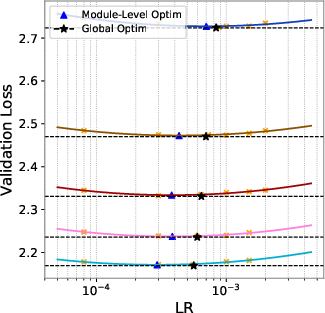
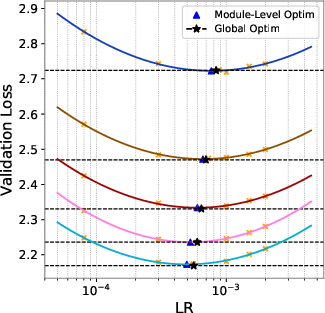
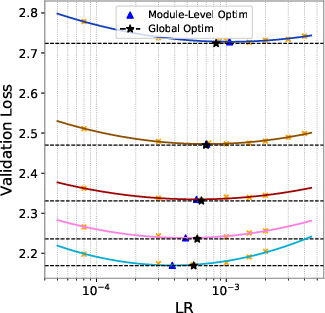
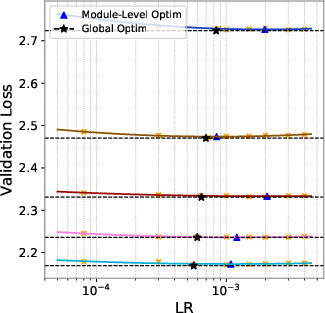
- A single, well-chosen global learning rate works just fine. The authors tried giving different parts of the model (like embeddings, router, hidden layers, and the final “LM head”) their own best learning rates. It didn’t help. The module-specific “best” rates were close to the global best, and performance was essentially the same. That means careful global tuning is enough.
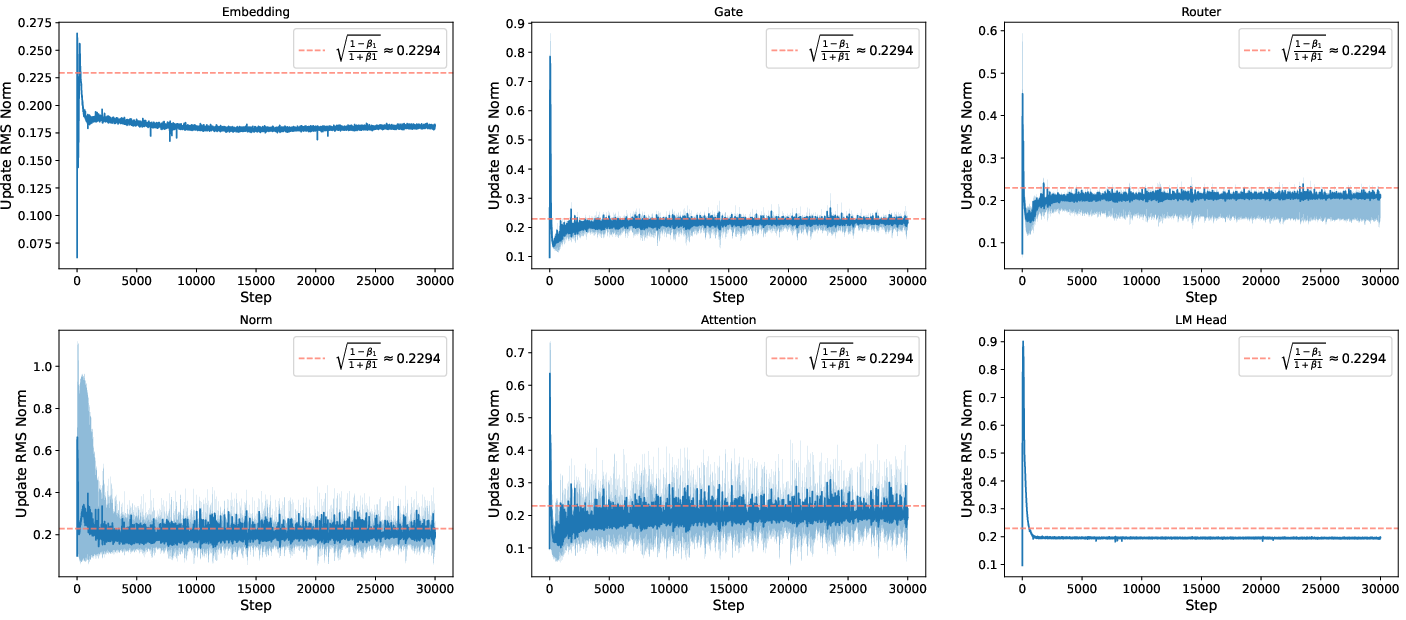
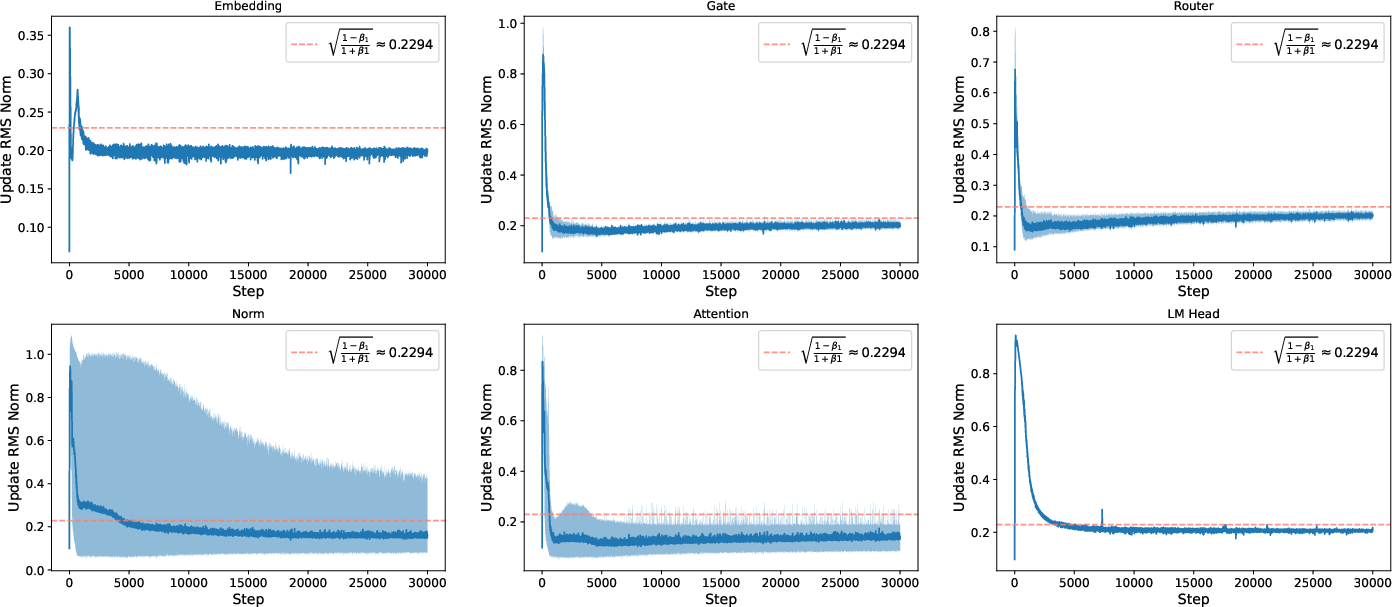
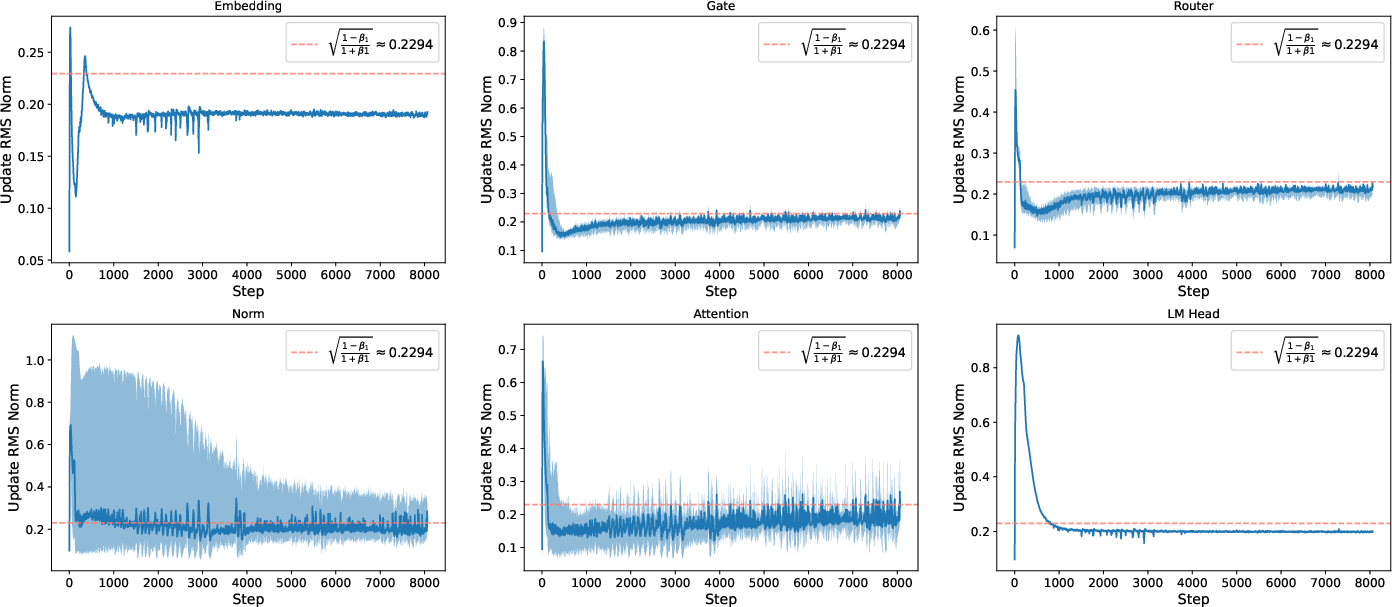
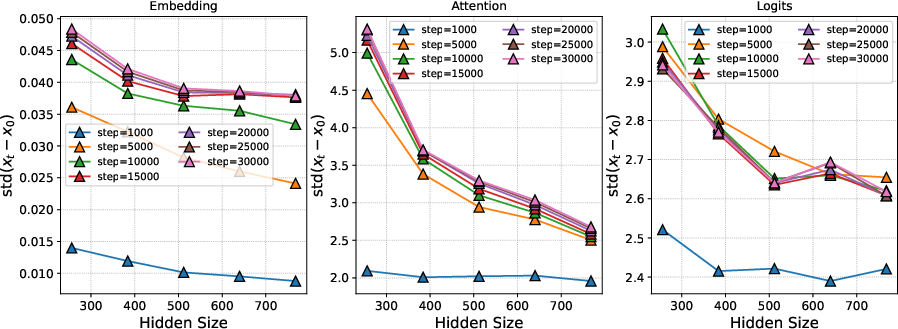
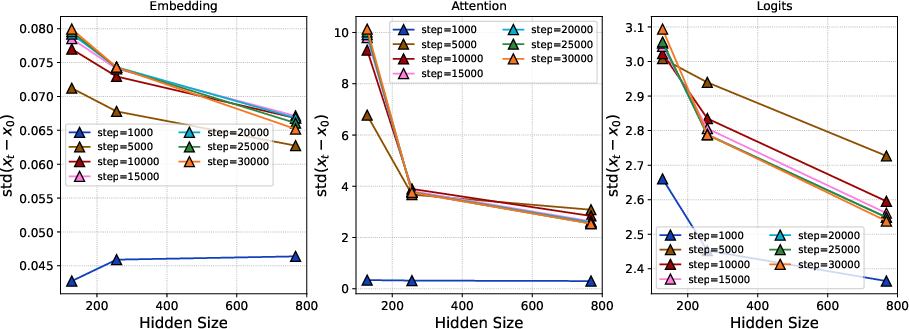
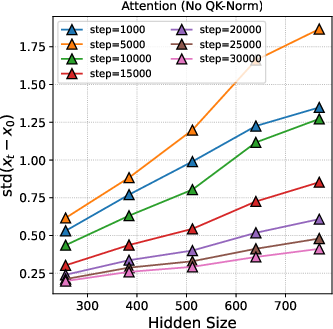
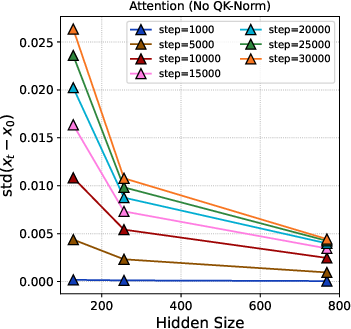
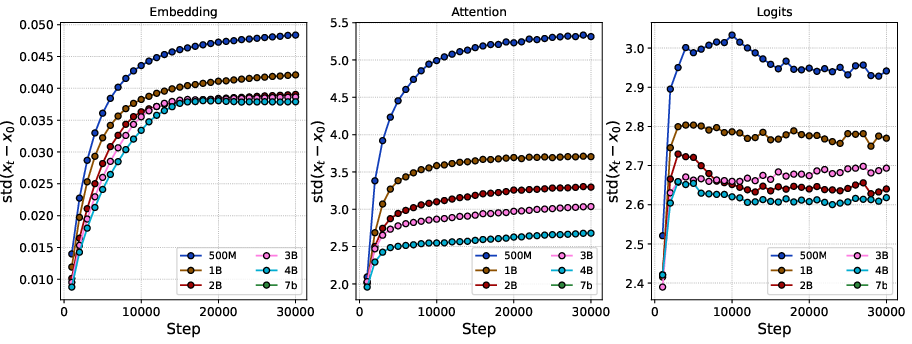
- Training was stable under standard parametrization (SP), especially with modern architectural features. Past work suggested things could blow up as models get wider without μP. But with features like QK-Norm in attention, the authors didn’t see instability. The internal updates stayed steady across layers, and the update magnitudes were fairly uniform for long periods of training.
- Data size affects stability more than model size. As they increased training data, internal states changed more than they did when only increasing model width. This helps explain why the learning rate must drop faster with data than with model size in their formula. In short: when you train on much more data, you should reduce the learning rate more.
- Practical: their fitting-based formula lets teams choose a learning rate with fewer trials. Instead of doing huge grid searches across model size, dataset size, and learning rate, you can fit a simple curve from small experiments and predict the sweet spot for a much bigger training run.
Implications and Impact
What does this mean for building big AI models?
- If you need to train a very large model, use fitting-based scaling laws to set your learning rate. It’s accurate, cheaper, and scales better than μTransfer for MoE models in long WSD training.
- Don’t overcomplicate learning rate per module. A single global learning rate, chosen carefully, is usually enough. Modern architectures already keep layer-wise training balanced.
- When scaling up, pay special attention to data size. As you train on more tokens, reduce the learning rate more aggressively than you would for just increasing model size.
- For the WSD schedule used in industry, picking the right stable-phase learning rate is crucial and the fitting approach gives a reliable way to do that.
- Limits: The study focused on MoE models and WSD. Dense models or other schedules may need separate testing. Also, the “how far can we extrapolate” question still needs more research.
Overall, the paper provides a practical, evidence-backed method to set learning rates for very large pre-training runs, saving time and compute, and it challenges the idea that μTransfer is the best tool at ultra-large scales.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored, framed to be directly actionable for future research.
- Generalization beyond WSD: The study confines analysis to the Warmup-Stable-Decay schedule; it remains unknown whether the proposed LR scaling laws and invex loss–LR shape hold under cosine decay, exponential decay, one-cycle, or adaptive schedules, and how optimal LR should be reparameterized across schedules.
- Optimizer dependence: Results are limited to AdamW with fixed β1/β2/ε; it is unclear how the LR scaling exponents and the update norm invariance (~0.2) change under Adafactor, Lion, RMSProp, SGD, or different β settings, and whether optimizer-specific LR(N, D) laws are needed.
- Batch size effects: Global batch size is fixed (4M tokens); the LR scaling law omits batch size B, gradient accumulation, and micro-batch configuration. Test whether LR(N, D, B) obeys linear, square-root, or GNS-derived scaling and quantify interactions with gradient noise scale.
- Initialization and normalization: The fitting paradigm assumes standard parametrization with a normal init (σ=0.02) and benefits from QK-Norm; assess LR scaling under other inits (Xavier, Kaiming, scaled residual), pre-/post-norm variants (RMSNorm vs LayerNorm), and in the absence of QK-Norm to delineate stability regimes where μP is necessary.
- Architecture coverage: Findings are MoE-centric (Qwen3-MoE style with fixed width–depth aspect ratio). Validate LR(N, D) on dense Transformers and alternative MoE variants (different expert counts, top-k, capacity factor, routing noise, aux loss weights, shared experts) and quantify architectural modifiers to the exponents.
- Width–depth trade-offs: The fitting uses a constant width–depth ratio; extend the scaling law to explicitly model depth L and width W (e.g., LR(W, L, D)) and test whether exponents shift with deeper or wider configurations.
- Data composition sensitivity: The corpus (InternLM2.5) and its mix (text/code/long context) are fixed; quantify how LR scaling exponents vary with data quality, duplication levels, domain mix, long-context distribution, and tokenizer choice, and whether the loss–D power law parameters (A, γ) change materially.
- Sequence length effects: Sequence length is fixed at 4,096; investigate how LR optima scale with context length (L_ctx), especially for long-context curricula, and whether token horizon transfer rules capture sequence-length-induced stability changes.
- Loss–LR curve shape: The invex assumption is fitted with a quadratic in log LR over a limited grid; test for asymmetry, multi-modality, or heteroscedasticity across broader LR ranges, architectures, and optimizers, and compare against nonparametric/Bayesian models to reduce search error.
- Joint LR–weight decay coupling: Weight decay is largely fixed (0.1) in fitting and scaled proportionally in μTransfer; systematically map the LR–λ joint optimum surface across modules and scales to validate or refine the proportionality rule and identify optimizer- or module-specific coupling.
- Module- and layer-wise LR: Module-level search covers Embeddings, LM Head, Router, and “Hidden” collectively; evaluate finer granularity (attention vs FFN vs normalization parameters; shallow vs deep layers) and conditions (e.g., removing QK-Norm) where non-global LR improves learning balance.
- Early-phase dynamics: The focus is the stable phase; characterize LR transferability and optimality in the first tens of billions of tokens, where μTransfer is hypothesized to help, and design adaptive schedules that transition from early-phase stability to late-phase efficiency.
- Decay-phase optimization: Decay used a fixed 10% LR; search the optimal decay factor, onset, and schedule shape across data qualities, and determine if LR(N, D) can predict decay settings or if separate scaling laws are needed for the decay phase.
- Extrapolation limits: The LR(N, D) law is validated up to 12B total parameters and 500B tokens; measure breakdown points and uncertainty bands for N≫12B and D≫500B, and report confidence intervals for exponents (−0.2219, −0.3509) across seeds and replicates.
- Stability drivers and theory: Data scaling affected internal state variation more than model scaling; develop a theory linking the observed exponents to Hessian spectra and gradient noise scale, and test predictions across corpora and architectures to mechanistically explain −0.22 vs −0.35.
- Training mechanics: Report and analyze the impact of gradient clipping (if used), precision (BF16/FP8), sharding/offloading (ZeRO/FSDP), and hardware-induced numerical noise on LR optima to enable robust deployment-aware LR scaling.
- Broader evaluation: Downstream metrics are limited to MMLU and CMMLU; add code, long-context, reasoning, multilingual, and generative tasks to assess how LR choice affects emergent capabilities and whether task-specific LR adjustments are warranted.
- Transfer to fine-tuning: Test whether LR scaling laws from pre-training transfer to instruction tuning, SFT, and RLHF, and whether module-wise LR (rejected in pre-training) becomes beneficial in fine-tuning regimes.
Practical Applications
Immediate Applications
The following bullet points summarize practical, deployable uses of the paper’s findings and methods, grouped by sector and including assumptions/dependencies that affect feasibility.
- Software/MLOps: “AutoLR for WSD MoE pretraining”
- Use the fitted scaling law to set the constant LR in the Warmup–Stable–Decay schedule for large MoE models.
- Workflow: run a few short proxy runs to fit the quadratic loss–LR curve at fixed , fit the power-law on limited points, then extrapolate to the target scale and generate training configs.
- Tools/products: LR recommender plugin for DeepSpeed/Megatron-LM/ColossalAI; CLI/SDK that consumes model size and token budget to emit LR and decay settings.
- Assumptions/dependencies: AdamW (β1=0.9, β2=0.95), WSD schedule with a long constant phase, MoE architecture similar to Qwen3, QK-Norm present, proxy data distribution representative of target, normal init ~0.02.
- Software/MLOps: Reduced hyperparameter search cost
- Apply the paper’s “scaling law for search factor” to compress LR search from
O(n^3)toO(n * C_D * C_η)by fitting the loss–LR relationship and the loss–data-size scaling. - Workflow: replace broad grid searches with a small design-of-experiments; cache fitted curves and reuse across adjacent model sizes or corpora.
- Assumptions/dependencies: Invex loss–LR profile holds under constant LR phase; proxy runs are stable and reproducible.
- Apply the paper’s “scaling law for search factor” to compress LR search from
- Software/MLOps: Stability-aware LR planning when scaling data
- Adjust LR more aggressively when increasing data size than when increasing model size, reflecting the observed higher sensitivity to .
- Workflow: for token budget expansions (e.g., 200B → 500B), recompute LR using the scaling law; stage training with cautious LR ramps for data spikes.
- Assumptions/dependencies: Same optimizer and schedule; consistent corpus quality and mixing; monitoring in place to detect instability.
- Software/Engineering: Simplify training configs—avoid module-wise LR tuning
- Adopt a single global LR under modern SP + QK-Norm architectures; per-module LR tuning showed no measurable gains in this regime.
- Workflow: remove layer-/module-specific LR overrides; standardize configs to global LR plus decay phase.
- Assumptions/dependencies: Presence of QK-Norm or equivalent stabilizing components; AdamW; SP initialization; MoE architectures akin to Qwen3.
- Software/MLOps: Decay-phase recipe for WSD
- Anneal LR to ~10% of stable-phase LR and switch to higher-quality data for an additional ~100B tokens to improve downstream accuracy (MMLU, CMMLU gains reported).
- Workflow: segment corpus; automate LR decay trigger; integrate quality-weighted data curriculum.
- Assumptions/dependencies: WSD scheduler; availability of curated “high-quality” data; validated decay triggers.
- Software/MLOps: Health monitoring via update RMS norms
- Track per-layer update RMS norms (target ~0.2) as a health signal to detect training drift or instability.
- Tools/products: dashboards and alerting (e.g., Prometheus/Grafana hooks), training telemetry APIs.
- Assumptions/dependencies: AdamW optimizer; consistent norm computation; sufficient logging granularity.
- Industry/Finance/Energy: Compute and budget planning
- Use the LR scaling law to forecast training stability and reduce trial-and-error runs, cutting wasted GPU-hours and energy.
- Workflow: pre-run efficiency audits; scenario planning that ties LR and data budgets to expected performance; optimize cloud reservations.
- Assumptions/dependencies: Reliable proxy fit; comparable hardware and kernels; minimal domain shift.
- Academia: Replicable hyperparameter methodology for large-scale pretraining
- Adopt the fitting paradigm to systematically study LR vs. size/data across MoE architectures; publish reusable fit curves and code.
- Workflow: small-scale experiments; share fitted parameters and RMSE; enable cross-lab comparability.
- Assumptions/dependencies: Access to mid-scale compute; consistent evaluation (e.g., OpenCompass + LMDeploy).
- Industry/Academia: Practical use of extended μTransfer at small/medium scales
- Apply depth-aware residual scaling and couple weight decay with LR (δλ ∝ δlr) for proxy-to-target transfers when models are not ultra-large.
- Workflow: run μP proxy searches; transfer LR/init with depth and width scaling; validate early training quality.
- Assumptions/dependencies: Benefit diminishes at ultra-large scales per paper; strict adherence to μP rules; MoE-specific initialization.
- Policy/Sustainability: Efficiency-first training guidelines
- Encourage projects to use predictive LR fitting before large runs to cut energy and costs; report expected savings and measured outcomes.
- Workflow: governance checklists; funder or internal reviews that require efficiency plans; sustainability KPIs.
- Assumptions/dependencies: Organizational buy-in; standardized reporting; alignment with sustainability goals.
Long-Term Applications
These applications require further research, scaling, or productization before broad deployment.
- Software/MLOps: Generalize LR scaling laws beyond WSD and MoE
- Extend the fitting paradigm to dense transformers, alternative schedulers (cosine, one-cycle), and different optimizers (Adam, Adafactor, Lion).
- Tools/products: “AutoLR” libraries that select LR per architecture/schedule; integrated hyperparameter backends in training frameworks.
- Dependencies: New empirical campaigns; robust fitting across diverse model families; evaluation breadth.
- Software/MLOps: Multi-hyperparameter scaling laws and joint optimization
- Fit joint scaling relationships for LR, weight decay, batch size, gradient clipping, and init σ; automate end-to-end config synthesis.
- Tools/products: Hyperparameter compilers; “profile → recommend → deploy” pipelines.
- Dependencies: Joint identifiability; interactions across hyperparameters; larger design spaces.
- Software/MLOps: Adaptive, online LR controllers guided by fitted profiles
- Adjust LR dynamically across the stable phase using real-time loss/feature-learning signals to maintain stability as data distributions shift.
- Tools/products: Closed-loop controllers in training stacks; safety thresholds; RL-based schedulers.
- Dependencies: Robust online metrics; controller stability; guardrails against oscillations.
- Academia: Stability theory emphasizing data scaling
- Formalize why internal states vary more with data growth than width; propose architecture-level mitigations (e.g., normalization strategies).
- Outcomes: new theory; improved designs that reduce sensitivity to ; guidance for curriculum and mixing strategies.
- Dependencies: Analytical advances; controlled experiments across corpora and token budgets.
- Architecture/Optimizer R&D: Make μTransfer effective at ultra-large scales
- Explore new initialization schemes, layer-wise scalings, or optimizer variants to recover transfer efficacy when scaling >10×.
- Outcomes: revised μP/μTransfer protocols; better early-to-late-stage transfer.
- Dependencies: Large-scale experiments; interplay with decay phase and weight decay; MoE routing behaviors.
- Cluster/HPC: Energy-aware schedulers using LR forecasts
- Integrate predicted LR and training curves into job schedulers to minimize idle cycles and energy spikes.
- Tools/products: LR-informed scheduling; workload capping; “green” training modes.
- Dependencies: Accurate performance–energy models; scheduler integration; operator policies.
- Cross-domain ML: Apply LR fitting paradigm to CV, speech, RL, and robotics foundation models
- Use reduced search complexity for large-scale pretraining beyond language; accelerate development of multimodal and policy models.
- Tools/products: domain-specific AutoLR extensions; cross-modality benchmarks.
- Dependencies: Domain-specific loss–LR invex behavior; different data scaling dynamics; varied optimizers.
- Education/Workforce: Curriculum and certs for efficient large-scale training
- Train ML engineers on the fitting paradigm, stability diagnostics (e.g., update RMS norm), and WSD best practices.
- Outcomes: standardized training modules; industry certifications.
- Dependencies: Teaching materials; collaboration with industry consortia; updates as practices evolve.
- Policy/Standards: Best-practice benchmarks for efficient pretraining
- Establish community standards that include predictive LR fitting, stability monitoring, and transparent reporting of compute and energy.
- Outcomes: reproducibility and sustainability baselines; procurement guidelines.
- Dependencies: Standards bodies; multi-stakeholder participation; enforcement and incentives.
Glossary
- AdamW optimizer: An adaptive optimization algorithm with decoupled weight decay commonly used for training deep neural networks. "we utilize the AdamW optimizer \cite{adamw} with , , and ."
- Attention logits: The pre-softmax compatibility scores computed in the attention mechanism that determine how much each token attends to others. "we conducted an ablation where the QK-Norm modules were removed during the computation of attention logits (Figure \ref{fig:logits_attn})."
- CMMLU: A comprehensive Chinese multiple-choice benchmark used to evaluate LLM proficiency across diverse domains. "we evaluate our models on MMLU \cite{mmlu} and CMMLU \cite{li-etal-2024-cmmlu} benchmarks."
- Complete-μP: An extension of μParametrization providing rules to scale depth and improve transferability across model sizes. "we draw upon the methodologies of Depth-up \cite{depthmup} and Complete-P \cite{dey2025dontlazycompletepenables,complete-d-p}."
- Cosine annealing schedule: A learning rate schedule that decreases the learning rate following a cosine curve over training steps. "the cosine annealing schedule \cite{cosineschedule} served as the predominant standard."
- Depth-up: A methodology to scale model depth under μParametrization while preserving stable training dynamics. "we draw upon the methodologies of Depth-up \cite{depthmup} and Complete-P \cite{dey2025dontlazycompletepenables,complete-d-p}."
- Invex profile: A functional shape where a generalized convexity-like property ensures a unique global minimum, used to justify quadratic fitting of loss vs. learning rate. "we observe that for fixed and , the relationship between the validation loss and the learning rate approximates an invex profile."
- LM Head: The final linear projection layer that maps hidden states to vocabulary logits for token prediction. "Embeddings, LM Head, Router, and Hidden parameters."
- Maximal Update Parametrization (μP): A parametrization scheme ensuring stable, maximal feature learning as model width grows, enabling hyperparameter transfer. "Maximal Update Parametrization (Parametrization or P, \citet{mup}) is a widely investigated framework for hyperparameter configuration."
- Mixture of Experts (MoE): An architecture that routes inputs to a subset of expert networks to improve capacity and efficiency. "As the Mixture-of-Experts (MoE) architecture increasingly serves as the foundational backbone for large-scale pre-training \cite{deepseekai2024deepseekv2strongeconomicalefficient,deepseekv3,deepseekai2025deepseekr1incentivizingreasoningcapability,deepseekai2025deepseekv32pushingfrontieropen,yang2024qwen2technicalreport,qwen2025qwen25technicalreport,yang2025qwen3technicalreport,interns1}, we adopt the MoE architecture as our proxy model for P."
- MMLU: A broad English multiple-choice benchmark covering many academic subjects to assess model general knowledge. "we evaluate our models on MMLU \cite{mmlu} and CMMLU \cite{li-etal-2024-cmmlu} benchmarks."
- μTransfer: A method for transferring optimal hyperparameters (e.g., learning rate) from a small proxy model to a target model under μP. "In this study, we adopt the fundamental principles of Transfer~\cite{mup}."
- Power-law: A mathematical relationship of the form y = a·xb used to model scaling behaviors like loss vs. data size. "and \citet{steplaw} empirically derived power-law formulations correlating the learning rate with model size and training data size ."
- QK-Norm: A normalization technique applied to query-key pairs in attention to stabilize training and prevent blow-up. "we conducted an ablation where the QK-Norm modules were removed during the computation of attention logits (Figure \ref{fig:logits_attn})."
- Residual branch: The skip-connection pathway added to layer outputs in residual architectures, often scaled when adjusting depth. "The central mechanism involves applying a depth-dependent scaling factor to the residual branch:"
- Root Mean Squared Error (RMSE): A standard error metric computed as the square root of the mean of squared differences between predicted and observed values. "and denotes the metric function, which is Root Mean Squared Error (RMSE) in our work."
- Router: The gating component in MoE that selects which experts process each token. "Embeddings, LM Head, Router, and Hidden parameters."
- Scaling Law for search factor: A formal relation used to reduce hyperparameter search complexity via performance prediction. "we innovatively introduce a Scaling Law for search factor, effectively reducing the search complexity from to via predictive modeling."
- Standard Parametrization (SP): Conventional initialization and scaling settings for model parameters during training. "A fundamental motivation behind P is the hypothesis that under Standard Parametrization (SP) and a uniform global learning rate, specific modules may suffer from insufficient training, thereby failing to satisfy the regime of maximal feature learning."
- Token horizon: The training or transfer scale in terms of the number of tokens processed, affecting optimization dynamics. "Regarding transfer along the token horizon dimension, we adopt the configuration from \citet{complete-d-p}."
- Warmup-Stable-Decay (WSD): A learning rate schedule with an initial warmup, a long constant phase, and a final decay phase. "Consequently, the Warmup-Stable-Decay (WSD) schedule \cite{minicpm} has emerged."
- Weight decay: A regularization technique that penalizes large parameter values, typically implemented via the optimizer. "\citet{wang2025setadamwsweightdecay} and \citet{fan2025robustlayerwisescalingrules} have identified weight decay as a critical determinant of Transfer efficacy."
Collections
Sign up for free to add this paper to one or more collections.

