Dr. Zero: Self-Evolving Search Agents without Training Data
Abstract: As high-quality data becomes increasingly difficult to obtain, data-free self-evolution has emerged as a promising paradigm. This approach allows LLMs to autonomously generate and solve complex problems, thereby improving their reasoning capabilities. However, multi-turn search agents struggle in data-free self-evolution due to the limited question diversity and the substantial compute required for multi-step reasoning and tool using. In this work, we introduce Dr. Zero, a framework enabling search agents to effectively self-evolve without any training data. In particular, we design a self-evolution feedback loop where a proposer generates diverse questions to train a solver initialized from the same base model. As the solver evolves, it incentivizes the proposer to produce increasingly difficult yet solvable tasks, thus establishing an automated curriculum to refine both agents. To enhance training efficiency, we also introduce hop-grouped relative policy optimization (HRPO). This method clusters structurally similar questions to construct group-level baselines, effectively minimizing the sampling overhead in evaluating each query's individual difficulty and solvability. Consequently, HRPO significantly reduces the compute requirements for solver training without compromising performance or stability. Extensive experiment results demonstrate that the data-free Dr. Zero matches or surpasses fully supervised search agents, proving that complex reasoning and search capabilities can emerge solely through self-evolution.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Dr. Zero, an AI system that teaches itself to become a better “search agent” without using any human-made training data. A search agent is an AI that can look things up on the web and reason through several steps to answer tricky questions. Dr. Zero does this by creating its own practice questions, solving them, and learning from the results—like a student who writes their own test and then studies from their mistakes.
Key Questions the Paper Tries to Answer
- Can an AI improve its web-search and reasoning skills without any human-written questions or answer labels?
- How can we make the AI’s self-made questions diverse, challenging, and still solvable, so learning stays meaningful?
- How do we make this self-training efficient, so it doesn’t require huge amounts of computer power?
How Dr. Zero Works (In Simple Terms)
Think of Dr. Zero as a two-player team that levels up together:
- The proposer is like a puzzle maker. It creates questions for the AI to answer. Over time, it tries to make questions that are not too easy and not impossible—just the right challenge.
- The solver is like a puzzle solver. It uses a search engine to find information and reasons step-by-step to answer the questions.
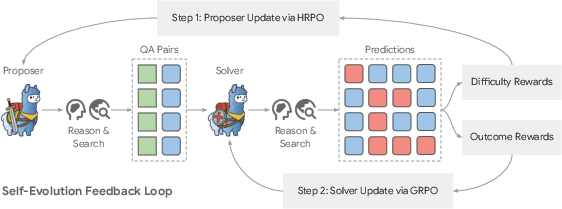
Here’s the loop they repeat:
- The proposer makes new questions (some require one step to answer, others need multiple “hops” across different web pages—like following clues in a scavenger hunt).
- The solver tries to answer them by searching and reasoning.
- The proposer gets a “score” based on how well the solver did:
- If all answers are correct, the question was too easy.
- If none are correct, the question was too hard.
- The best score comes when the question is challenging but still solvable.
- Both models update themselves to do better next round: the proposer makes better questions, and the solver gets better at solving them.
To make this efficient, the authors created a training method called HRPO (hop-grouped relative policy optimization). In everyday terms:
- “Multi-hop” means a question needs several steps to solve (like reading multiple pages and connecting facts).
- HRPO groups questions by how many hops they need (1 step, 2 steps, 3 steps, etc.).
- By comparing questions within the same group, the system can judge difficulty more fairly and learn faster, without needing to generate tons of extra samples. This avoids wasting a lot of computer time.
They also train the solver with a simpler method (GRPO) that focuses on whether the final answers are correct.
What They Found and Why It Matters
The researchers tested Dr. Zero on well-known question-answering challenges that require web search and multi-step reasoning (for example, Natural Questions, TriviaQA, HotpotQA, and others). Important takeaways:
- Dr. Zero matched or even beat strong systems that were trained with lots of human-made data. On some complex benchmarks, it surpassed supervised methods by up to 14.1%.
- It especially improved on multi-hop questions that need careful, multi-step thinking.
- The system worked on small and larger AI models, with bigger models gaining more from tougher, multi-step practice questions.
- Thanks to HRPO, training was much more efficient than older self-training methods that needed many repeated tries for each question.
In short: Dr. Zero shows an AI can teach itself to search and reason better without any labeled training data, just by using the web and a smart feedback loop.
Why This Is Important
- Reduces dependence on human-made datasets: Making and labeling training data is slow and expensive. Dr. Zero shows a path to strong performance without it.
- Builds better study habits for AI: The “make a puzzle → solve it → adjust difficulty” loop creates an automatic curriculum, helping the AI steadily level up.
- More practical search agents: A system that can reliably look up facts and reason through multiple steps can help with research, learning, and answering complex real-world questions.
Final Thoughts and Future Impact
Dr. Zero is a promising step toward AI systems that improve themselves using the open web, without manual supervision. This could make advanced, reasoning-heavy assistants more accessible, especially when high-quality training data is hard to find.
The authors also point out future challenges:
- Keeping training stable over many rounds so performance doesn’t plateau.
- Preventing “reward hacking” (the AI gaming its own scoring system).
- Avoiding bias and ensuring reliability when there’s no human in the loop.
If these challenges are addressed, self-evolving search agents like Dr. Zero could become powerful tools for learning, research, and problem-solving in many fields.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, phrased to guide actionable follow-up work:
- External search dependency and scope: Generalization beyond a local English Wikipedia index (E5-base, top-3) to open-web search, other corpora (domain-specific, noisy, or adversarial), and multilingual settings is untested.
- Verifiability and truthfulness: The framework lacks an explicit evidence-grounded verifier (e.g., citation checking or claim verification); correctness is judged by exact match and solver agreement, leaving risks of incorrect or unsupported synthesized labels unaddressed.
- Reward hacking and ambiguity: The proposer reward peaks when exactly one of n solver attempts is correct, potentially incentivizing ambiguous or borderline questions; the paper does not quantify reward gaming or ambiguity and offers no safeguards beyond future work.
- Sensitivity to n in pass-rate reward: The number of solver attempts (n) used to compute proposer difficulty is unspecified; its impact on compute, variance, and reward reliability is not analyzed.
- “Hop” measurement and grouping validity: How hop counts are computed, validated, and robustly distinguished is unclear; the effect of hop misclassification on HRPO stability and performance is not studied.
- Grouping features beyond hop count: HRPO groups by hops only; alternative or complementary grouping criteria (topic, answer type, retrieval difficulty, lexical overlap, evidence count) are not explored.
- Efficiency claims unquantified: Wall-clock time, GPU hours/FLOPs, token throughput, and energy/cost comparisons vs GRPO, PPO, and nested sampling are not reported, leaving HRPO’s efficiency gains largely qualitative.
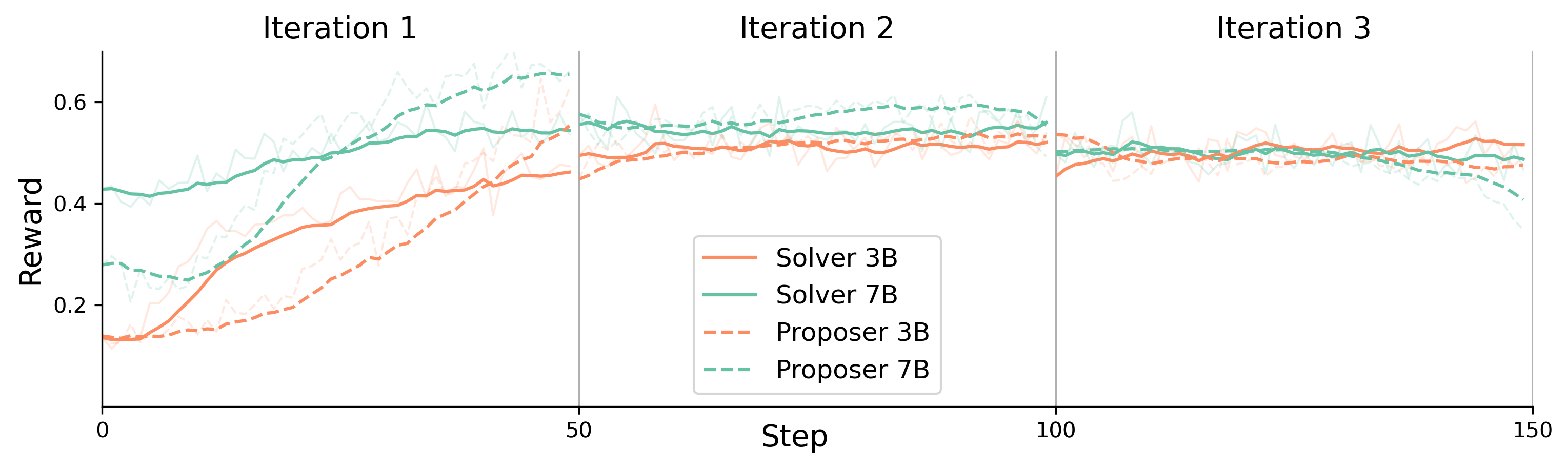
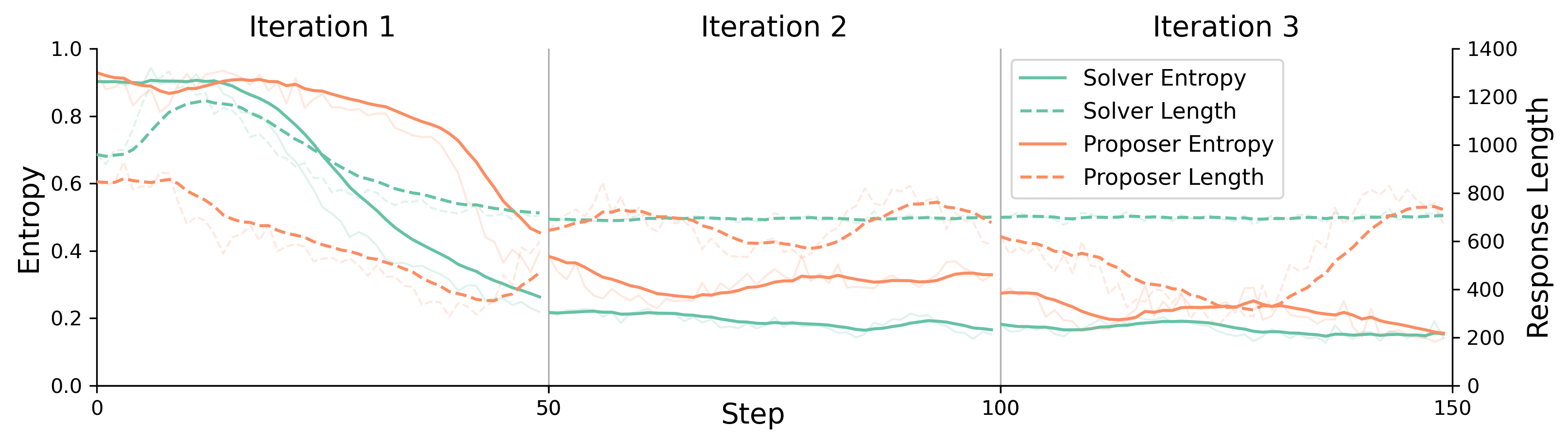
- Stability and plateau: Self-evolution plateaus after 2–3 iterations (worse at 7B); mechanisms to sustain continual improvement (adaptive curriculum, diversity constraints, restarts, entropy regularization) are not investigated.
- Implementation fragility: Training failures due to “inconsistent token IDs” in multi-turn rollouts suggest tooling brittleness; the frequency, impact on results, and mitigation strategies are not systematically analyzed.
- Safety and bias: No bias, toxicity, or safety audits are conducted; the method could amplify biases or generate unsafe content through search-augmented self-play.
- Robustness to retrieval noise/attacks: The agent’s behavior under irrelevant, misleading, adversarial, or poisoned documents, as well as retrieval outages and latency, is untested.
- Evaluation limited to exact match: No assessments of paraphrase tolerance, partial credit, calibration, hallucination rate, confidence reliability, or human judgments are provided.
- Evidence grounding quality: The system does not measure citation coverage, evidence sufficiency, or attribution quality for generated answers or synthesized QA pairs.
- Topic and difficulty diversity: There is no quantitative analysis of proposer-generated topic coverage, knowledge breadth, or difficulty profiles; mechanisms to enforce or diagnose diversity are missing.
- Co-adaptation/collusion risk: Using the same base LLM for proposer and solver could induce co-adaptation to idiosyncratic patterns; cross-play tests (swapping solvers, evaluating on external solvers/users) are absent.
- Generality beyond QA: Applicability to other tool-use tasks (coding, planning, data analysis), multi-modal settings, or interactive research tasks is not evaluated.
- Retrieval component learning: The retriever is fixed (E5-base, ANN top-3); joint learning or RL-based query reformulation and retriever adaptation are not explored.
- Curriculum control is manual: Fixed hop ratios (4:3:2:1) are hand-set; an adaptive curriculum policy tied to solver competence and uncertainty is not proposed or evaluated.
- Algorithmic baselines and theory: Comparisons to PPO with learned critics, off-policy methods, advantage normalization variants, or preference-based RL (DPO/RLAIF) are limited; HRPO’s theoretical properties (variance bounds, convergence) are not provided.
- Hyperparameter omissions and reproducibility: Key settings (e.g., HRPO/GRPO group sizes, max turns per rollout) are unspecified in the text; sensitivity analyses and reproducibility checklists are missing.
- Scaling laws: Results are reported for Qwen2.5 3B/7B only; scaling trends to larger models, compute scaling vs performance, and plateau behaviors under scale are unexplored.
- Temporal and domain drift: Training and evaluation use a static Wikipedia snapshot; robustness to evolving knowledge, time-sensitive queries, and cross-domain drift is not assessed.
- Dependence on initial document seeding: Ablations show large drops without an initial document; sensitivity to initial retrieval quality and fallback strategies when retrieval fails are not studied.
- Failure-case taxonomy: There is limited qualitative or systematic error analysis (e.g., retrieval misses vs reasoning mistakes vs formatting/tool-use errors), hindering targeted improvements.
- Ethical/legal considerations: Potential plagiarism of retrieved text in synthesized QA pairs, copyright concerns, and data governance for self-generated corpora are not addressed.
Glossary
- Actor-critic methods: RL algorithms that pair a policy (actor) with a value estimator (critic) to reduce gradient variance. "For example, actor-critic methods such as PPO employ a learned critic to estimate a value baseline (Mnih et al., 2016; Schulman et al., 2017)."
- Advantage estimation: Computing the relative benefit of an action or trajectory versus a baseline to guide policy updates. "We introduce hop-grouped relative policy optimization (HRPO), a novel optimization method that clusters structurally similar questions to provide a robust group-level baseline for advantage estimation."
- Approximate nearest neighbor (ANN) search: An efficient retrieval technique that finds items close to a query in embedding space using approximate indexing. "During inference, we perform an approximate nearest neighbor (ANN) search to retrieve the top-3 documents."
- Automated curriculum: An automatically generated sequence of tasks that increase in difficulty to improve learning. "As the solver evolves, it incentivizes the proposer to produce increasingly difficult yet solvable tasks, thus establishing an automated curriculum to refine both agents."
- Data-free self-evolution: A training paradigm where models improve by generating and learning from synthetic data without human-curated datasets. "As high-quality data becomes increasingly difficult to obtain, data-free self-evolution has emerged as a promising paradigm."
- Direct Preference Optimization (DPO): An offline method that trains LLMs directly on pairwise preference data. "A simpler offline alternative is direct preference optimization (DPO) (Rafailov et al., 2023), which directly optimizes LLMs on pairwise preference data."
- Exact match: An evaluation metric that marks a prediction correct only if it exactly matches the target answer string. "All models are evaluated using exact match with identical search engine (E5 base) and corpus settings (English Wikipedia dump)."
- Group Relative Policy Optimization (GRPO): A group-based policy optimization method that uses statistics across multiple responses to form low-variance baselines. "For solver training, we sample data pairs (x, y) from the proposer Te and optimize To via group relative policy optimization (GRPO) (Shao et al., 2024)."
- Hop-grouped Relative Policy Optimization (HRPO): An optimization algorithm that clusters questions by hop complexity to compute group-level baselines efficiently. "To enhance training efficiency, we also introduce hop-grouped relative policy optimization (HRPO)."
- IRCoT: A technique that interleaves retrieval with chain-of-thought reasoning to improve accuracy on knowledge-intensive tasks. "A notable example is IRCoT, where Trivedi et al. (2023) exploit multi-step retrieval to optimize answer accuracy on knowledge-intensive tasks."
- KL regularizer: A regularization term that penalizes divergence between the current policy and a reference to stabilize updates. "where N denotes the size of the sampled batch, and 3 is the hyperparameter controlling the KL regularizer."
- Multi-hop queries: Questions requiring reasoning across multiple pieces of evidence or steps. "such approaches yields moderate performance gains on trivial one-hop tasks but struggles to match supervised baselines on complex multi-hop queries (see Section 4)."
- Multi-turn tool-use rollout pipeline: A training procedure involving repeated tool interactions across turns during rollouts. "we introduce a multi-turn tool-use rollout pipeline that enables the trained proposer to significantly improve question generation quality and produce complex, multi-hop questions."
- Nested sampling: A multi-level sampling approach (e.g., sampling many questions and many responses per question) that increases compute cost. "the standard group relative policy optimization (GRPO) significantly increases training compute in self-evolution as it requires nested sampling: generating multiple queries and subsequently producing multiple responses for each question."
- On-policy framework: An RL setup where updates are computed using data sampled from the current policy. "For optimal proposer performance and training efficiency, we adopt a strictly on-policy framework and omit ratio clipping."
- Outcome-based reward: A reward signal that depends solely on the correctness of the final answer. "The optimization is driven by an outcome-based reward that solely evaluates the correctness of final predictions against the synthesized ground truth y."
- Policy gradient algorithms: RL methods that directly optimize a policy’s parameters via gradients of expected reward. "In the context of LLMs, RL is frequently implemented using policy gradient algorithms (Sutton et al., 1999; Ouyang et al., 2022)."
- Proposer-solver co-evolution: A training scheme where a question generator (proposer) and solver improve together by challenging each other. "Huang et al. (2025a) design a proposer-solver co-evolution framework to iteratively bootstrap questions and rationales, thereby achieving meaningful performance gains without access to any curated datasets."
- Proximal Policy Optimization (PPO): A widely used actor-critic RL algorithm that stabilizes updates via clipping and KL constraints. "For example, actor-critic methods such as PPO employ a learned critic to estimate a value baseline (Mnih et al., 2016; Schulman et al., 2017)."
- Ratio clipping: Limiting the change in the policy probability ratio during updates to improve stability. "we adopt a strictly on-policy framework and omit ratio clipping."
- REINFORCE++: A single-response RL optimization approach proposed for efficient alignment that reduces sampling costs. "While single-response methods like REINFORCE++ reduce sampling costs, we find that a global baseline becomes unstable when processing diverse query structures."
- Retrieval-Augmented Generation (RAG): Augmenting generation with retrieved documents to inject external knowledge. "Few-shot baselines include standard prompting, IRCoT (Trivedi et al., 2023), Search-o1 (Li et al., 2025) and retrieval augmented generation (RAG) (Lewis et al., 2020)."
- Reward hacking: Exploiting the reward function to achieve high scores without solving the intended task. "Furthermore, we plan to safeguard the self-evolution process against reward hacking and bias amplification, aiming to develop robust learning frameworks..."
- Reward standardization: Normalizing rewards within a group to compute advantages with lower variance. "where the advantages are computed via reward standardization (i.e., Ai = std({(y=ûi)}-1)+8"
- Search-o1: A search-enhanced reasoning baseline used for comparison in experiments. "Few-shot baselines include standard prompting, IRCoT (Trivedi et al., 2023), Search-o1 (Li et al., 2025) and retrieval augmented generation (RAG) (Lewis et al., 2020)."
- Search-R1: An RL-trained search agent baseline that leverages external search with reinforcement learning. "Supervised baselines consist of supervised fine-tuning (SFT), RL-based fine-tuning without search (R1) (Guo et al., 2025) and the RL-based search agent Search-R1 (Jin et al., 2025)."
- Self-play: A training mechanism where a model generates tasks and evaluates itself to improve without human labels. "Early approaches utilize self-play mechanisms where the model acts as both the generator and the evaluator to refine its policy without human annotations (OpenAI et al., 2021; Chen et al., 2024; Wu et al., 2024)."
- Self-questioning LLMs (SQLM): Models that generate their own questions to train themselves in a data-free manner. "We further compare Dr. Zero against existing data-free methods, specifically self-questioning LLMs (SQLM) and self-evolving reasoning LLMs (R-Zero) (Chen et al., 2025; Huang et al., 2025a)."
- Supervised fine-tuning (SFT): Training a model on labeled datasets to improve performance on target tasks. "Supervised baselines consist of supervised fine-tuning (SFT), RL-based fine-tuning without search (R1) (Guo et al., 2025) and the RL-based search agent Search-R1 (Jin et al., 2025)."
- Value baseline: An estimate of expected return used to reduce variance in policy gradient updates. "For example, actor-critic methods such as PPO employ a learned critic to estimate a value baseline (Mnih et al., 2016; Schulman et al., 2017)."
Practical Applications
Overview
Below are practical, real-world applications derived from the paper’s findings and innovations—primarily the Dr. Zero data-free proposer–solver framework, hop-grouped relative policy optimization (HRPO), difficulty-guided rewards, and multi-turn search/tool-use. Applications are grouped by deployment horizon and annotated with sectors, emerging tools/products/workflows, and key assumptions or dependencies affecting feasibility.
Immediate Applications
These can be deployed now with standard LLMs that support tool-use, a searchable corpus (internal or web), and modest RL training infrastructure.
- Self-evolving enterprise knowledge assistant (software, enterprise knowledge management)
- Deploy a Q&A/search agent that self-improves without annotated data by indexing internal wikis, policy manuals, and tickets; swap Wikipedia for an enterprise corpus in the search tool while keeping Dr. Zero’s proposer–solver loop and HRPO.
- Tools/workflows: E5-style embedding + ANN index; multi-turn tool-use; 4:3:2:1 hop curriculum; HRPO training to reduce compute; <question>/<answer> formatting for verifiability; EM or domain-specific exact-match evaluation.
- Assumptions/dependencies: High-quality internal index; base LLM supports reliable tool-calls; data governance (privacy, access control); modest RL compute; guardrails to prevent reward hacking and biased exploration.
- Customer support copilot and FAQ refinement (industry: customer service)
- Use the proposer to synthesize diverse, verifiable issues and the solver to learn troubleshooting flows over product documentation and known issues—reducing manual prompt/dataset curation.
- Tools/workflows: Connect to Zendesk/ServiceNow knowledge bases; difficulty-guided rewards to avoid trivial tickets; HRPO to keep training costs low; human-in-the-loop validation for edge cases.
- Assumptions/dependencies: Accurate retrieval from rapidly changing support content; escalation rules; latency budgets for multi-turn reasoning.
- Analyst research copilot with citations (finance, marketing, competitive intelligence)
- Self-evolving web-search agent producing multi-hop, source-backed answers for market, company, and technology analysis without hand-labeled datasets.
- Tools/workflows: Browser extension or research workspace; public search APIs; automatic citation capture from retrieved passages; iteration-limited training (50–150 steps) for quick wins.
- Assumptions/dependencies: API rate limits; uneven web content quality; need for provenance logging and bias controls.
- Educational content generation and adaptive tutoring (education)
- Generate verifiable multi-hop questions and answers aligned to topics; employ hop ratios and difficulty-guided rewards to control challenge level; provide sources for each item.
- Tools/workflows: LMS integration; item bank builder using <question>/<answer> tags; entropy/length monitoring to ensure diversity and reduce collapse; knob for hop distribution (Table 4 insights).
- Assumptions/dependencies: Curriculum alignment; content safety; psychometric validation for formal assessments; human review for high-stakes exams.
- Fact-checking and claim verification assistant (media, policy)
- Multi-hop search agent that self-evolves to find corroborating sources, highlighting exact matches and contradictions for statements in articles, posts, or briefs.
- Tools/workflows: News feed ingestion; cross-source retrieval; structured outputs with citations; outcome-based rewards tuned for verifiable claims.
- Assumptions/dependencies: Robustness to noisy/irrelevant context; need evaluation beyond EM; safeguards against bias amplification and cherry-picking.
- Developer documentation and API Q&A (software)
- Index code docs, API references, and issue trackers; the agent self-trains to answer developer questions across repos without curated instruction sets.
- Tools/workflows: Doc search adapters; IDE/chat integrations; HRPO to cluster by “hop” (single source vs cross-repo/API) complexity; format rewards to keep outputs structured.
- Assumptions/dependencies: Good indexing of technical docs; reliable tool-calling; version-awareness for evolving APIs.
- Legal and compliance Q&A over regulations (legal, policy, compliance)
- Retrieve across statutes, guidance, and memos; the agent self-evolves to handle cross-references and multi-hop statutory reasoning while surfacing sources.
- Tools/workflows: Regulatory corpus ingestion; answer justification with citations; audit trail logging; constrained iteration training for stability.
- Assumptions/dependencies: High accuracy requirements; human-in-the-loop review; jurisdictional filtering; periodic re-indexing as regulations change.
- Knowledge-base bootstrapper from unlabeled corpora (industry, academia)
- Proposer synthesizes Q&A pairs from a corpus; solver validates via search, creating a seed KB for downstream systems while reducing curation cost.
- Tools/workflows: Synthetic dataset pipeline; deduplication; verifiability checks; curriculum tuning via hop ratios; structured export to KB systems.
- Assumptions/dependencies: Corpus quality; dedup and leakage controls; risk of reinforcing corpus biases; governance for what becomes “canonical” knowledge.
- RL training efficiency upgrade for proposer-like tasks (ML engineering)
- Adopt HRPO to cut nested sampling and stabilize optimization for any structured generation tasks with measurable difficulty (e.g., math/coding benchmarks, query generation).
- Tools/workflows: HRPO library; grouping by task complexity features (hops, tool calls, steps); lighter compute footprint vs GRPO.
- Assumptions/dependencies: Clear complexity signals for grouping; adequate batch sizes for stable baselines.
- Lightweight benchmark synthesis for open-domain QA (academia)
- Use Dr. Zero to create multi-hop, source-verifiable datasets for research, minimizing human annotation.
- Tools/workflows: Dataset generation and filtering; source provenance; split uniqueness checks; public release workflows.
- Assumptions/dependencies: Dataset bias management; dedup against existing benchmarks; alignment to community evaluation norms.
- Personal research and planning assistant (daily life)
- A self-training assistant for travel plans, product comparisons, and how-to tasks that leverages multi-hop web search to improve over time without manual datasets.
- Tools/workflows: Browser/mobile integration; citation and checklist outputs; iteration-capped training for responsiveness.
- Assumptions/dependencies: Web search reliability; preference customization; guardrails for misleading content.
Long-Term Applications
These will benefit from further research on stability, domain governance, safety, and scaling (as noted in the paper’s future-work and limitations).
- Domain-specific clinical search and guideline navigator (healthcare)
- Self-evolving assistant over PubMed, clinical guidelines, and formularies providing verifiable multi-hop answers; prospective CME item generation and literature synthesis.
- Tools/workflows: Medical-grade indexing; clinical safety layers; rigorous evaluation beyond EM; institutional approval pipelines.
- Assumptions/dependencies: Regulatory compliance (HIPAA, MDR); strong guardrails against hallucinations; adjudication by clinicians; reward hacking prevention.
- Autonomous literature-review and hypothesis exploration (“robot scientist”) (academia)
- Agents generate questions, retrieve evidence, and iteratively refine hypotheses using self-evolving curricula; potentially integrate with experimental planning tools.
- Tools/workflows: Scholarly corpus integration; multi-agent proposer–solver extensions; provenance graphs; long-context reasoning scaling.
- Assumptions/dependencies: Reliability of scientific retrieval; bias control; mechanism to avoid spurious multi-hop chains; ethical oversight.
- Continuous-learning search engines and browser-integrated agents (software, consumer tech)
- Embed Dr. Zero to automatically improve search result synthesis and reasoning over time with verifiable answers and dynamic curricula.
- Tools/workflows: At-scale HRPO training; real-time telemetry; reward integrity monitoring; A/B testing; multi-lingual indexing.
- Assumptions/dependencies: Massive compute and logging; strict safeguards against bias and reward gaming; privacy and consent.
- Adaptive testing and curriculum design systems (education)
- Use difficulty-guided rewards and hop ratios to generate balanced assessments and personalized curricula; psychometric properties tuned via RL signals.
- Tools/workflows: Item response theory (IRT) integration; validity and reliability audits; explainable item provenance.
- Assumptions/dependencies: Formal validation; fairness auditing; strong content review cycles.
- Generalization of HRPO to multi-tool, multi-agent systems (robotics, software automation)
- Cluster tasks by structural complexity (not only “hops”) to stabilize RL for agents that interleave tools beyond search (planning, simulation, APIs).
- Tools/workflows: Complexity feature engineering; multi-tool orchestrators; group-level baselines across task families.
- Assumptions/dependencies: Well-defined complexity metrics; robust logging of tool-call sequences; variance control across heterogeneous tasks.
- Enterprise autonomous knowledge maintenance (software, enterprise)
- Agents continuously ingest new documents, synthesize Q&A, and update KBs with verifiable links while self-evolving to handle novel multi-hop relationships.
- Tools/workflows: Incremental indexing; change-detection; provenance-preserving updates; audit dashboards.
- Assumptions/dependencies: Governance on authoritative sources; rollback mechanisms; drift detection; human oversight.
- Financial and regulatory surveillance copilot (finance, policy)
- Multi-hop monitoring across filings, rules, and news to surface compliance risks and cross-reference impacts; self-evolving to keep pace with regulatory changes.
- Tools/workflows: Regulatory ontology mapping; alerting pipelines; justification trails; risk scoring.
- Assumptions/dependencies: High-stakes accuracy; legal review; stable retrieval across jurisdictions.
- Legal due diligence autopilot (legal)
- Cross-source retrieval across case law, contracts, and memos with multi-hop reasoning and verifiable citations; continuous self-evolution for new precedents.
- Tools/workflows: Legal corpora ingestion; cross-referencing; explanation generators; review queues.
- Assumptions/dependencies: Domain validation; liability frameworks; bias mitigation.
- Multilingual, cross-domain data-free agents (global deployment)
- Extend Dr. Zero to non-English corpora and mixed-domain retrieval, using HRPO-like grouping stratified by language and domain complexity.
- Tools/workflows: Multilingual embeddings; corpus-specific hop metrics; locale-aware evaluation.
- Assumptions/dependencies: Quality of non-English indices; culturally aware content controls; cross-lingual alignment challenges.
- Reward integrity, bias auditing, and governance tooling (policy, AI safety)
- Build infrastructure to detect reward hacking, entropy collapse, and bias amplification in self-evolution loops; enforce robust feedback integrity without human labels.
- Tools/workflows: Reward audit services; anomaly detection on training dynamics; fairness dashboards; intervention APIs.
- Assumptions/dependencies: Access to training telemetry; agreed-upon safety metrics; organizational policies for interventions.
Collections
Sign up for free to add this paper to one or more collections.