Agent0: Unleashing Self-Evolving Agents from Zero Data via Tool-Integrated Reasoning
Abstract: LLM Agents, often trained with Reinforcement Learning (RL), are constrained by a dependency on human-curated data, limiting scalability and tethering AI to human knowledge. Existing self-evolution frameworks offer an alternative but are typically restricted by the model's inherent capabilities and single-round interactions, hindering the development of complex curricula involving tool use or dynamic reasoning. We introduce Agent0, a fully autonomous framework that evolves high-performing agents without external data through multi-step co-evolution and seamless tool integration. Agent0 establishes a symbiotic competition between two agents initialized from the same base LLM: a curriculum agent that proposes increasingly challenging frontier tasks, and an executor agent that learns to solve them. We integrate external tools to enhance the executor's problem-solving capacity; this improvement, in turn, pressures the curriculum agent to construct more complex, tool-aware tasks. Through this iterative process, Agent0 establishes a self-reinforcing cycle that continuously produces high-quality curricula. Empirically, Agent0 substantially boosts reasoning capabilities, improving the Qwen3-8B-Base model by 18% on mathematical reasoning and 24% on general reasoning benchmarks. Code is available at https://github.com/aiming-lab/Agent0.
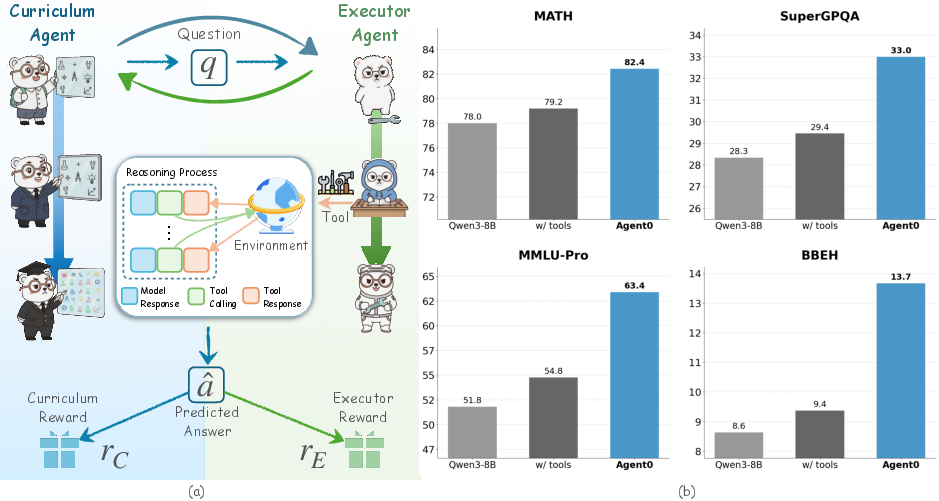

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Agent0: A simple explanation for teens
1) What is this paper about?
This paper introduces Agent0, a way to help AI learn to think better without using any human-made training data. It does this by letting two AIs “grow” together: one AI invents new, harder problems, and the other AI tries to solve them. The solver can also use a tool (like a built‑in calculator that runs code) to help. As the solver improves, the problem-maker creates tougher, tool-heavy problems. This creates a loop where both keep getting better.
2) What were the authors trying to figure out?
In simple terms, they asked:
- Can an AI teach itself to become smarter without people giving it examples or answers?
- Can we make this work for multi-step thinking and problems where using tools (like a code interpreter) helps?
- Will this self-improving setup beat other popular “learn by yourself” methods?
3) How does Agent0 work?
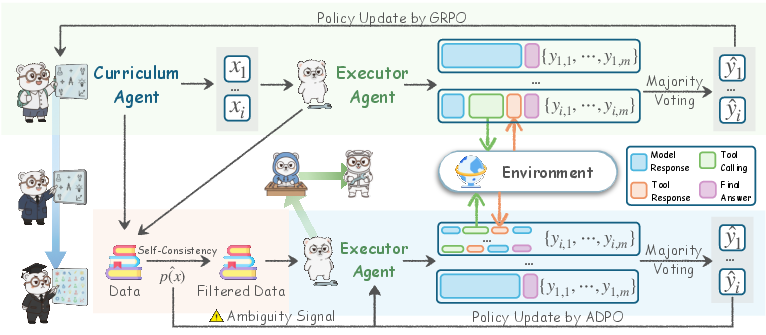
Think of two teammates who start with the same basic knowledge:
- The “Curriculum Agent” is the puzzle-maker. Its job is to create problems that are just hard enough to challenge the solver.
- The “Executor Agent” is the puzzle-solver. Its job is to solve those problems, using step-by-step reasoning and a tool (a safe code runner) when useful.
They train in rounds, like levels in a game. After each round, both get better.
Here are the main ideas, explained with everyday language:
- Reinforcement Learning (RL): Like training a pet with treats. If the AI does something good (e.g., makes a useful problem or solves one), it gets a reward and learns to do more of that.
- Friendly rivalry (co-evolution): The puzzle-maker tries to stump the solver (but not too much), and the solver tries to catch up. This back-and-forth pushes both to improve.
- Tool use: The solver can write and run short bits of code (like using a powerful calculator) to handle tough math or checks. The puzzle-maker is rewarded when it creates problems that make the solver actually use the tool.
- Smart rewards for the puzzle-maker:
- Uncertainty reward: If the solver gives mixed answers (about half right, half wrong), that means the problem is the right difficulty—so the puzzle-maker is rewarded.
- Tool-use reward: If the problem makes the solver use its coding tool, extra reward.
- Repetition penalty: If the puzzle-maker keeps making similar problems, it loses points. This forces variety.
- Learning from itself (no human answers):
- The solver answers each problem multiple times.
- It uses the most common answer (majority vote) as a temporary “label” to train on.
- Because these self-made labels can be noisy, the authors add a safety step called ADPO:
- Be cautious when the AI is very unsure (downweight learning from those).
- Let the AI explore more (take bigger steps) on uncertain problems, so it can discover new reasoning paths.
- Multi-turn reasoning: Instead of one-shot answers, the solver can think step by step, call the tool, see the result, and continue—like having a conversation with itself while working out the solution.
4) What did they find, and why does it matter?
The authors tested Agent0 on many math and general reasoning benchmarks. Key results:
- On math tests, performance improved by about 18%.
- On general reasoning tests (outside pure math), performance improved by about 24%.
- Agent0 beat several strong “self-improving” baselines, including ones that don’t use tools and some that do.
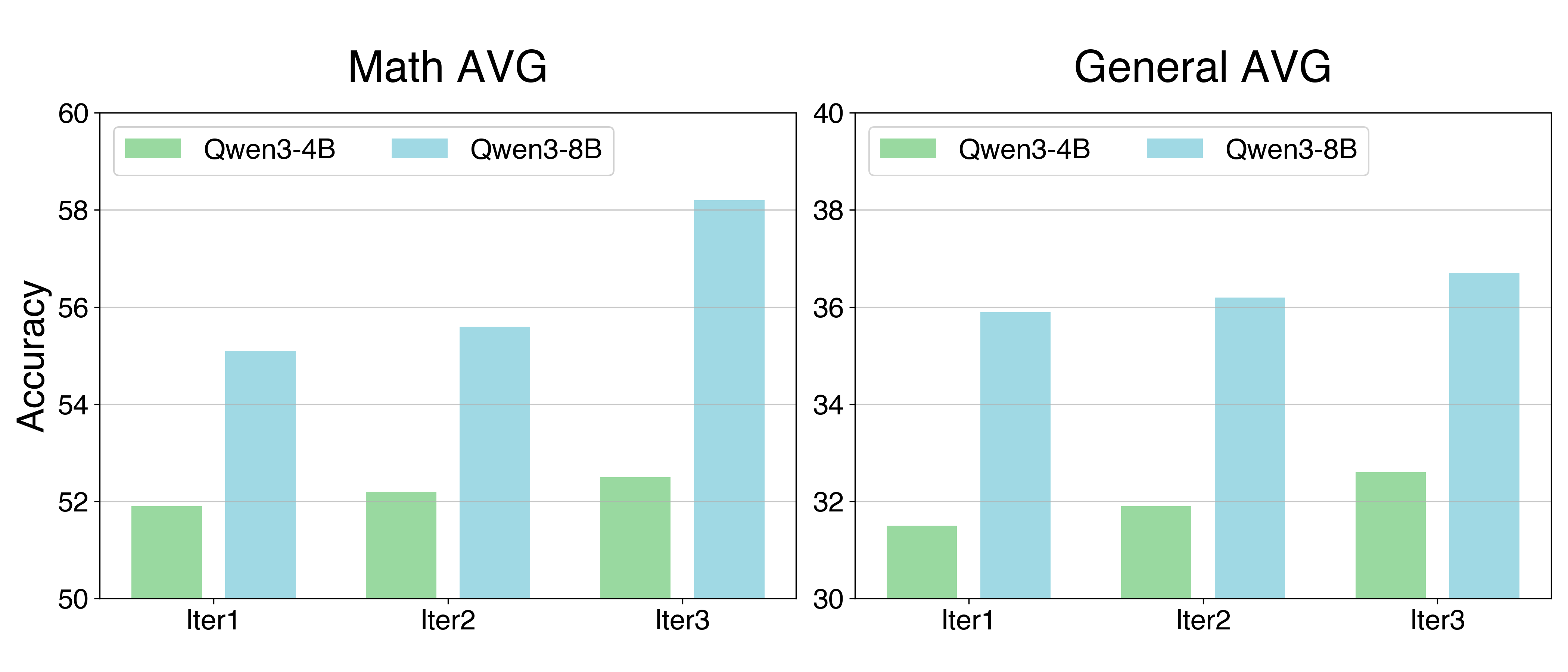
- Across rounds of training, both the difficulty of generated problems and the solver’s skill rose steadily.
- The solver used the tool more often on later, harder tasks—showing the system learned when tools are helpful.
Why this matters:
- It shows an AI can meaningfully improve itself without needing giant human-made datasets.
- It learns not just to “write answers,” but to plan, think in steps, and use tools—skills that matter for real-world tasks.
5) What’s the bigger impact?
Agent0 points to a future where:
- AIs can teach themselves at scale, saving time and cost and going beyond the limits of human-curated data.
- Tool-aware reasoning becomes standard, helping AIs solve complex, multi-step problems more reliably (like math, coding, research, or data analysis).
- The “puzzle-maker + solver” setup could be adapted to many areas, creating custom learning paths that stay at the edge of an AI’s abilities.
In short, Agent0 is like two smart partners—one inventing ever better practice, the other mastering it with the help of a tool—working together to climb a never-ending staircase of harder challenges, all without needing humans to label the steps.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list summarizes the paper’s unresolved gaps, limitations, and open questions that future work could concretely address.
- Ambiguous specification of
R_format: The format check used to gate task rewards is not defined (criteria, enforcement, failure modes), leaving task validity and solvability checks under-specified. - Uncertainty proxy calibration: The self-consistency measure is assumed to correlate with task difficulty, but no calibration study validates this relationship across domains or temperatures; assess when stems from ill-posed tasks versus genuinely challenging ones.
- Majority-vote pseudo-label noise: Training the executor to match the majority answer risks reinforcing errors; quantify error rates of majority votes and compare against verifiable signals (e.g., numeric correctness via the interpreter).
- ADPO functional forms and theory: The paper does not specify concrete forms for the advantage scaling function or the dynamic clipping bound , nor provide theoretical guarantees; analyze stability, convergence, and sensitivity to these choices.
- Reward hacking via tool calls:
R_toolrewards the count of tool invocations rather than utility; investigate detection and penalization of spurious or ineffectual tool use (e.g., no-ops, repeated prints, irrelevant code). - Tool-use quality metrics: Replace or augment raw tool-call counts with outcome-aware metrics (e.g., code execution success rate, correctness of computed values, error recovery) to tie rewards to effective tool use.
- Repetition penalty using BLEU: BLEU-based clustering incentivizes surface-level diversity; evaluate embedding-based semantic similarity, task structure metrics, or functional equivalence to enforce meaningful diversity at scale.
- Task validity and solvability: Without external labels, generated tasks may be unsolvable or ambiguous; introduce automated checks (constraint satisfiability, numeric verifiers, unit tests, solution consistency) and report rejection rates.
- Long-horizon and multi-turn rigor: The multi-turn setting is described, but there is no quantitative analysis of horizon length, error recovery strategies, or interaction budgets; evaluate performance beyond short math workflows (e.g., >10 turns).
- Single-tool scope: The framework relies on one code interpreter; assess generalization to multiple heterogeneous tools (web search, calculators, databases, APIs), tool selection policies, and orchestration strategies.
- Stability of co-evolution: Reported gains cover three iterations; study longer runs for mode collapse, cyclic curricula, or diminishing returns, and propose stagnation detectors and adaptive schedules.
- Catastrophic forgetting: Measure retention of earlier competencies across iterations and introduce replay or regularization strategies to prevent forgetting of previously mastered skills.
- Sample-efficiency and compute: Training requires samples per task and multi-turn generation; quantify compute budgets, training times, and carbon costs, and analyze trade-offs versus performance.
- Sensitivity to key hyperparameters: No systematic analysis of , , , , , , KL penalty, or clipping bounds; conduct robust sensitivity and ablation studies.
- Error handling in the sandbox: Execution errors are fed back as
output, but failure-handling policies are not analyzed (retry strategies, timeouts, resource limits); quantify error distributions and their impact on learning. - Structured tool-calling vs code fences: Reliance on
pythonandoutputtags is brittle; evaluate structured function-calling interfaces with schema validation to reduce false positives/negatives in tool detection. - Task difficulty measurement: The “pass rate decrease” proxy is used to infer difficulty climbs; develop independent difficulty estimators (solver-independent metrics, solution length/complexity, formal hardness) to avoid confounds.
- Generalization beyond math: The curriculum mainly produces code-amenable math tasks; test whether Agent0 can autonomously generate high-quality curricula for non-math domains (e.g., law, biology, commonsense) and evaluate domain transfer mechanisms.
- Fairness and statistical rigor: Report confidence intervals, multiple seeds, and significance tests; ensure comparable compute budgets and tool access across baselines to support claims of superiority.
- Base model diversity: Results are shown for Qwen3-4B/8B; examine portability across model families (e.g., Llama, Mistral, Phi) and sizes to assess generality and scaling laws.
- Safety, alignment, and misuse: Self-evolving curricula could produce harmful or deceptive tasks; define guardrails, policy filters, and alignment monitors, and measure adverse behaviors over iterations.
- Data contamination checks: Verify that evaluation datasets are not leaked into the training loop via the base model or generated tasks; provide contamination analyses and mitigation.
- Intermediate credit assignment: The executor receives terminal rewards only; investigate step-level rewards (e.g., correct intermediate computations, successful subgoals) to improve learning signal in multi-step trajectories.
- Distribution coverage and novelty: Beyond repetition penalties, quantify coverage of topic space, novelty relative to pretraining, and avoidance of trivial perturbations; design explicit novelty rewards or exploration objectives.
- Multi-agent heterogeneity: Both agents are initialized from the same base LLM; study effects of heterogeneous initializations (different models or seeds), asymmetric capacities, and cross-play to improve curriculum/executor diversity.
- Robustness to task formatting and parsing: Define and evaluate resilience to malformed prompts, adversarial formatting, or non-standard tool tags, and enhance parsing reliability.
- Overreliance on tools: Evaluate whether gains persist without tool access, and whether the executor’s reasoning degrades when tools are unavailable; introduce balanced training to maintain tool-free competence.
- Practical deployment considerations: Detail how Agent0 integrates with real-world environments (permissions, data privacy, sandbox security), and quantify risks from executing generated code (e.g., resource abuse, vulnerabilities).
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can be implemented now using the paper’s methods, tools, and training loop (Agent0 with code interpreter, GRPO/ADPO, uncertainty- and tool-aware curriculum rewards).
- Auto-curriculum generation for math and logic training (Education; AI/ML R&D)
- Use the Curriculum Agent to generate frontier problems and the Executor Agent to improve reasoning without human-authored datasets.
- Tools/products/workflows: “Self-Evolve Tutor” for math Olympiad practice; auto-item generation for adaptive testing; fine-tuning pipelines for campus or ed-tech LLMs.
- Dependencies/assumptions: Requires safe Python sandbox; base LLM must have minimal reasoning competence; compute budget for multi-sample self-consistency (k≈10).
- Synthetic data generation for code/interpreter tasks (Software; ML Engineering)
- Co-evolve tasks that require code execution (unit tests, small scripts), then train the Executor with ADPO to use tools effectively.
- Tools/products/workflows: CI “auto-test generator”; “bug reproducer” that proposes failing cases; “agentic coding” bootstrapping sans human labels.
- Dependencies/assumptions: Deterministic, resource-limited sandbox; guardrails against harmful or long-running code; integration with unit-test frameworks.
- Tool-use policy optimization for existing assistants (Software; Analytics; Enterprise IT)
- Apply ADPO to existing text+tool assistants (Python, SQL, spreadsheets) to improve when-to-call and how-to-call tools using uncertainty-aware curricula.
- Tools/products/workflows: “Tool proficiency trainer” for internal enterprise copilots; SQL agent trainer that auto-generates frontier queries.
- Dependencies/assumptions: Stable tool APIs and observability of tool calls; telemetry for tool-call frequency; adherence to access controls.
- Dynamic evaluation and red-teaming via uncertainty targeting (Policy; AI Safety; MLOps)
- Use the Curriculum Agent’s uncertainty reward to auto-generate “hard cases” that the model is maximally unsure about for continuous evaluation and stress tests.
- Tools/products/workflows: “Uncertainty-targeted test suite” in model evaluation; red-team harness that escalates difficulty as defenses improve.
- Dependencies/assumptions: Clear reward shaping for diversity (repetition penalty) to avoid mode collapse; governance to prevent unsafe content generation.
- Adaptive tutoring with multi-turn tool-integrated reasoning (Education; Consumer Apps)
- Deliver stepwise, code-assisted explanations; escalate task complexity as learner succeeds; provide instant verification via code execution.
- Tools/products/workflows: Jupyter-like tutoring chat; curriculum that increases tool reliance over time; teacher dashboards of skill frontier.
- Dependencies/assumptions: On-device or private sandboxing in classrooms; content safety filters; alignment with curricular standards.
- Internal upskilling and interview prep (HR; Corporate L&D)
- Generate escalating scenario questions and evaluate reasoning with majority voting; align to job competencies (analytics, logic, quant).
- Tools/products/workflows: “Frontier interview question generator”; automated skill gap analysis via self-consistency signals.
- Dependencies/assumptions: Role-specific toolchains (e.g., Excel, SQL) must be callable; HR privacy and fairness constraints.
- Finance scenario/stress-test generation (Finance; Risk; Audit)
- Curriculum Agent crafts edge-case financial scenarios (e.g., cash flow puzzles, sensitivity analyses) that push tool-using analysts.
- Tools/products/workflows: Spreadsheet- or Python-driven scenario simulators; risk “frontier task generator” for internal model validation.
- Dependencies/assumptions: Regulatory-compliant data handling; tool APIs (spreadsheets, market-data simulators); strict sandboxing and logging.
- Knowledge-base QA hardening (Enterprise Support; Search)
- Generate difficult, multi-turn KB queries that require tool use (retrieval, summarization, code snippets for calculators) to improve agent robustness.
- Tools/products/workflows: “KB frontier query generator”; ambiguity-aware RL finetuning pipeline to reduce hallucinations on hard queries.
- Dependencies/assumptions: KB connectors; retrieval tool instrumentation; guardrails for sensitive content and privacy.
- Continuous benchmark generation for research (Academia; ML Evaluation)
- Produce evolving, diverse benchmarks using repetition penalty and uncertainty targeting; track capability growth across iterations.
- Tools/products/workflows: Auto-benchmark composer; longitudinal model scoreboards; multi-turn math and general-reasoning suites.
- Dependencies/assumptions: Validation harnesses to detect degenerate or trivialized tasks; public release policies and licensing.
- Cost reduction in RLHF-like pipelines (AI/ML Ops)
- Replace parts of human-curated datasets with self-generated curricula and pseudo-label majority voting to cut data collection costs.
- Tools/products/workflows: “Agent0 pretrain→self-evolve→supervised touch-up” pipelines; ADPO as a drop-in optimizer for ambiguous samples.
- Dependencies/assumptions: Human-in-the-loop checkpoints for safety and calibration; compute budget; reproducibility controls.
Long-Term Applications
These require further research, stronger safety controls, more robust tools, domain validation, or regulatory clearance.
- Clinical reasoning agents with tool-connected calculators and EHR simulators (Healthcare)
- Co-evolve complex, multi-turn clinical cases; use calculators (risk scores, dosing) to train tool-aware decision-making.
- Tools/products/workflows: “Clinical frontier case generator”; simulator-connected training; audited reasoning traces.
- Dependencies/assumptions: Regulatory approval (e.g., FDA); rigorous external validation; privacy-preserving sandboxes; domain-aligned reward shaping.
- Robotics task planning with simulator tools (Robotics; Manufacturing)
- Curriculum Agent uses uncertainty and tool rewards in physics simulators to co-evolve tasks and motion plans for long-horizon control.
- Tools/products/workflows: Gazebo/Isaac sim connectors; “frontier manipulation task generator”; plan-and-act ADPO trainer.
- Dependencies/assumptions: High-fidelity simulators; sim-to-real transfer; safe exploration; latency-tolerant training infra.
- Scientific discovery assistants (Science; R&D)
- Co-evolve hypotheses and verification scripts (numerical experiments) to improve reasoning about models, proofs, or data analysis.
- Tools/products/workflows: “Auto-hypothesis and test generator”; lab notebook agents with code execution and data loaders.
- Dependencies/assumptions: Verified evaluation signals beyond majority vote; reproducible computational environments; access to curated datasets.
- Grid and energy operations scenario generation (Energy; Utilities)
- Stress-test planning and dispatch strategies with tool-integrated power flow solvers; co-evolve challenging contingencies.
- Tools/products/workflows: Power-system simulator agents; “frontier outage scenario generator” for operator training.
- Dependencies/assumptions: Accurate simulators; safety and critical-infrastructure constraints; human oversight in loop.
- Cybersecurity red-teamers and blue-team trainers (Security; Policy)
- Generate adversarial, tool-reliant challenges to probe and harden systems; co-evolve attacks and defenses.
- Tools/products/workflows: Sandbox-integrated exploit simulators; “uncertainty-targeted adversary” and defense curriculum.
- Dependencies/assumptions: Strong containment and legal compliance; rigorous access control; misuse prevention and auditing.
- Negotiation and multi-agent governance simulations (Public Policy; Economics)
- Extend co-evolution to multi-agent, multi-round settings for policy design, auctions, and mechanism testing.
- Tools/products/workflows: Multi-agent simulators; market/game-theory toolkits; institutional “policy sandbox.”
- Dependencies/assumptions: Validated modeling assumptions; fairness/ethics oversight; interpretability of learned strategies.
- Domain-specific engineering copilots with specialized toolchains (Semiconductors, CAD/EDA, Bioengineering)
- Co-evolve tasks tied to CAD/EDA or bioinformatics tools; train agents to orchestrate complex tool pipelines.
- Tools/products/workflows: EDA workflow agents (synthesis, PnR, verification); bioinformatics analysis trainers.
- Dependencies/assumptions: Proprietary tool licensing; deterministic, audit-friendly tool outputs; domain expert validation.
- Lifelong self-improving enterprise agents (AgentOps; Continual Learning)
- Always-on co-evolution in production: agents log uncertainty, spawn frontier tasks, retrain with ADPO, and redeploy.
- Tools/products/workflows: “Self-Improving AgentOps” platform; rollout–evaluate–evolve loops; change management gates.
- Dependencies/assumptions: Strong governance, rollback, and drift detection; data and privacy compliance; cost controls.
- Standards for dynamic, self-generated evaluations (Policy; AI Governance)
- Establish norms and audits for curricula generated without human labels, including safety thresholds and alignment checks.
- Tools/products/workflows: Certification suites for self-evolving agents; standardized uncertainty and repetition metrics.
- Dependencies/assumptions: Community consensus; benchmarking bodies; third-party auditing infrastructure.
- Personalized lifelong learning tutors (Education at scale)
- Full-stack agents that continuously co-evolve a student’s curriculum across subjects, tools, and modalities over years.
- Tools/products/workflows: Cross-subject “frontier learning map”; tool-integrated multi-turn tutoring with verified assessments.
- Dependencies/assumptions: Robust student modeling; equity and bias safeguards; parental/educator oversight; privacy-by-design.
Notes on feasibility across applications:
- Safety and alignment: Autonomous, zero-data self-evolution can drift; require guardrails, human checkpoints, and monitoring to prevent “alignment tipping.”
- Tooling reliability: The approach hinges on trustworthy, sandboxed tools with clear I/O contracts and resilient error handling.
- Compute and engineering: Iterative, multi-sample RL (GRPO/ADPO, k-sampling, multi-turn) needs meaningful compute and careful hyperparameter tuning.
- Evaluation signals: Majority-vote pseudo-labels suffice for bootstrap but may require external verification or domain oracles for high-stakes domains.
Glossary
- ADPO: An RL optimization variant that scales advantages and relaxes clipping based on task ambiguity. "Ambiguity-Dynamic Policy Optimization (ADPO)"
- AIME24: A benchmark from the American Invitational Mathematics Examination 2024 used to evaluate mathematical reasoning. "AIME25, and AIME24."
- AIME25: A benchmark from the American Invitational Mathematics Examination 2025 used to evaluate mathematical reasoning. "AIME25, and AIME24."
- AMC: The American Mathematics Competitions benchmark for math problem solving. "including AMC, Minerva~\cite{lewkowycz2022solving}, MATH~\cite{hendrycks2021measuring}, GSM8K~\cite{cobbe2021training}, Olympiad-Bench~\cite{he2024olympiadbench}, AIME25, and AIME24."
- Ambiguity-Aware Advantage Scaling: A technique to down-weight learning signals for low-consistency (ambiguous) samples. "Ambiguity-Aware Advantage Scaling."
- Ambiguity-Modulated Trust Regions: A method that adjusts PPO clipping bounds based on task ambiguity to encourage exploration. "Ambiguity-Modulated Trust Regions."
- BBEH: A general-domain reasoning benchmark used for evaluating agent performance. "BBEH~\cite{kazemi2025big}."
- BLEU score: A text similarity metric used to penalize repeated or similar tasks. "such as BLEU score~\cite{papineni2002bleu}: ."
- Capability frontier: The boundary where tasks are neither too easy nor too hard for the current model. "filter for tasks that lie at the capability frontier."
- Code interpreter: An external tool that executes code during multi-turn reasoning to aid problem solving. "a sandboxed code interpreter~\cite{cheng2025fullstack}"
- Composite reward: A combined scoring function (e.g., uncertainty, tool use, repetition penalty) to evaluate generated tasks. "The composite reward consists of two key components:"
- Curriculum Agent: The agent trained to generate challenging tasks that target the executor’s weaknesses. "The Curriculum Agent is trained via RL to generate tasks"
- Curriculum Evolution: The training phase where the curriculum agent is optimized via RL to produce frontier tasks. "Curriculum Evolution."
- Executor Agent: The agent trained to solve increasingly complex tasks created by the curriculum agent. "The Executor Agent is then trained on via ADPO"
- GRPO: Group Relative Policy Optimization, an RL method that uses intra-group relative rewards instead of a critic. "Group Relative Policy Optimization (GRPO)."
- GSM8K: A benchmark of grade-school math word problems for evaluating reasoning. "GSM8K~\cite{cobbe2021training}"
- Importance sampling ratio: The ratio of current to reference policy probabilities used in PPO-style updates. "is the importance sampling ratio"
- KL-divergence: An information-theoretic measure used as a regularization term in RL training. "The KL-divergence term acts as a regularization penalty to stabilize training."
- Majority-vote pseudo-labels: Labels inferred by selecting the most common answer among multiple samples. "using majority-vote pseudo-labels ."
- MATH: A benchmark dataset of challenging math problems for LLM evaluation. "MATH~\cite{hendrycks2021measuring}"
- Mean@32: An evaluation metric averaging performance over 32 sampled attempts. "except AMC and AIME benchmarks (mean@32)."
- Minerva: A quantitative reasoning benchmark from Google for evaluating math abilities. "Minerva~\cite{lewkowycz2022solving}"
- MMLU-Pro: An advanced version of Massive Multitask Language Understanding used for robust evaluation. "MMLU-Pro~\cite{wang2024mmlu}"
- Multi-Turn Rollout: A generation procedure where reasoning and tool calls interleave across multiple steps. "Multi-Turn Rollout."
- Olympiad-Bench: A dataset of math olympiad-style problems for testing complex reasoning. "Olympiad-Bench~\cite{he2024olympiadbench}"
- Pass@1: The accuracy of the model’s first attempt at solving a task. "We report the accuracy (pass@1) based on greedy decoding"
- PPO: Proximal Policy Optimization, an RL algorithm with clipped objectives to stabilize updates. "PPO-style clipped loss function~\cite{schulman2017proximal}"
- Repetition Penalty: A penalty that discourages generating highly similar tasks within a batch. "Repetition Penalty."
- RLHF: Reinforcement Learning from Human Feedback, an RL paradigm using human-provided signals. "Reinforcement Learning from Human Feedback (RLHF)"
- RLVR: Reinforcement Learning from Verifiable Rewards, using automatically verifiable signals instead of human labels. "Reinforcement Learning from Verifiable Rewards (RLVR)"
- Self-consistency: The fraction of sampled responses agreeing on the majority answer, used as a proxy for uncertainty. "We use the Executor's self-consistency as a proxy for uncertainty."
- Self-evolution: A training paradigm where models autonomously generate and learn from their own data. "self-evolution frameworks have emerged as a promising alternative"
- Self-play: A method where an agent improves by playing against versions of itself or generating its own challenges. "existing self-play or self-challenging approaches"
- Symbiotic competition: A co-evolution dynamic where two agents push each other to improve. "These agents co-evolve through a symbiotic competition"
- Tool-Integrated Reasoning (TIR): Reasoning that leverages external tools (e.g., code execution) inside the LLM loop. "Tool-Integrated Reasoning (TIR)."
- Tool Use Reward: A reward component incentivizing tasks that require leveraging external tools. "Tool Use Reward."
- Trust region: The bounded region of parameter updates enforced by clipping in PPO-style methods. "ADPO dynamically modulates the trust region."
- Uncertainty Reward: A reward encouraging generation of tasks with mid-level consensus (most uncertain for the executor). "Uncertainty Reward."
- Upper clipping bound: The upper limit in PPO’s clipping function, adjusted dynamically in ADPO. "We define the upper clipping bound $\epsilon_{\text{high}(x)$"
- VeRL: A reinforcement learning framework used as the implementation base for Agent0. "Agent0, is implemented based on the VeRL~\cite{sheng2025hybridflow}."
- VeRL-Tool: A tool integration module enabling code execution within the RL framework. "based on VeRL-Tool~\cite{jiang2025verltool}"
- z-score: A normalization method used to compute standardized advantages in GRPO. "using a z-score"
Collections
Sign up for free to add this paper to one or more collections.

