Digital Red Queen: Adversarial Program Evolution in Core War with LLMs
Abstract: LLMs are increasingly being used to evolve solutions to problems in many domains, in a process inspired by biological evolution. However, unlike biological evolution, most LLM-evolution frameworks are formulated as static optimization problems, overlooking the open-ended adversarial dynamics that characterize real-world evolutionary processes. Here, we study Digital Red Queen (DRQ), a simple self-play algorithm that embraces these so-called "Red Queen" dynamics via continual adaptation to a changing objective. DRQ uses an LLM to evolve assembly-like programs, called warriors, which compete against each other for control of a virtual machine in the game of Core War, a Turing-complete environment studied in artificial life and connected to cybersecurity. In each round of DRQ, the model evolves a new warrior to defeat all previous ones, producing a sequence of adapted warriors. Over many rounds, we observe that warriors become increasingly general (relative to a set of held-out human warriors). Interestingly, warriors also become less behaviorally diverse across independent runs, indicating a convergence pressure toward a general-purpose behavioral strategy, much like convergent evolution in nature. This result highlights a potential value of shifting from static objectives to dynamic Red Queen objectives. Our work positions Core War as a rich, controllable sandbox for studying adversarial adaptation in artificial systems and for evaluating LLM-based evolution methods. More broadly, the simplicity and effectiveness of DRQ suggest that similarly minimal self-play approaches could prove useful in other more practical multi-agent adversarial domains, like real-world cybersecurity or combating drug resistance.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What This Paper Is About
This paper explores a simple way to make AI programs get better by constantly challenging them with tougher opponents, much like an endless game of rock–paper–scissors. The authors use a safe, virtual game called Core War, where tiny programs (called “warriors”) try to outsmart each other inside a simulated computer. Their method, called Digital Red Queen (DRQ), uses a LLM—a kind of AI that can write and edit code—to repeatedly create better warriors that can defeat all the earlier ones.
The Big Questions the Paper Asks
- Can we make AI systems improve in a more “real-life” way by always training them against changing opponents, instead of a fixed test?
- Will this constant arms race produce warriors that are not just good at one thing (specialists) but good against many different opponents (generalists)?
- Over time, will different runs of this process “converge” on similar winning behaviors, even if the code looks different?
- Can we predict how strong a warrior is just by looking at its code, without running expensive simulations?
How They Did It (In Simple Terms)
Think of a sports team that always practices against recordings of its past games. After each practice, the team studies what worked, then plans new strategies to beat all previous versions of itself. That’s DRQ.
Here are the main pieces, explained with everyday ideas:
- Core War: This is a safe virtual arena where small programs fight for control of a shared memory (think of a digital playing field). Programs can copy themselves, search for opponents, and try to “crash” the other program. It’s like two tiny robots trying to disable each other in a fenced-off ring.
- LLM: This is an AI that can read and write code. The LLM proposes new warrior programs or edits old ones, like a coach drafting new plays.
- Self-play and the “Red Queen” idea: In nature, species must keep adapting just to avoid falling behind—like running in place on a treadmill. DRQ captures this by evolving a new warrior each round that must beat all previous champions. The goal keeps moving, so strategies must keep improving.
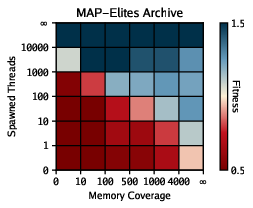
- MAP-Elites (diversity-preserving search): Instead of searching for just one “best” strategy, DRQ keeps a collection of different styles (like a grid of top plays across different playing styles). This prevents everyone from copying the same idea and getting stuck. You can imagine a trophy cabinet with one top example per style of play.
- Avoiding cycles: Only playing the latest opponent can cause loops (A beats B, B beats C, C beats A). DRQ reduces this by making each new warrior train against a growing history of past warriors.
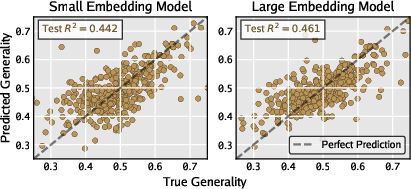
- Predicting strength without playing: The authors also tried to see if they could “guess” a warrior’s overall strength just by looking at its code (using a code embedding and a simple predictor), to save time on long simulations.
What They Found and Why It Matters
Here are the main findings, written for clarity:
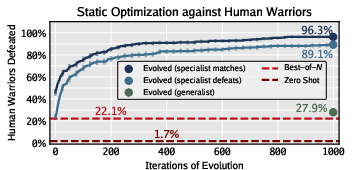
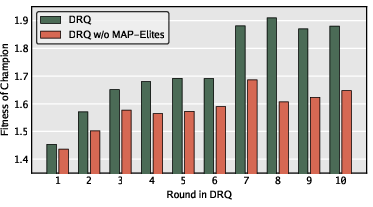
- Specialists vs. generalists: Training against just one target makes warriors that can beat that one target very well—but they’re brittle against others. On average, a single specialist only beat about 28% of human-designed warriors. In contrast, DRQ’s constant self-play produced warriors that handled many different opponents better—more like all-rounders. Some DRQ warriors defeated around 80% of human designs.
- Growing generality: Across many rounds, warriors became more general (better at beating unseen human opponents). This means the shifting challenge of self-play nudges AI toward robust strategies.
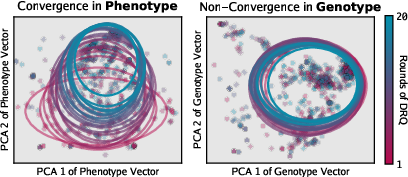
- Convergent behavior, different code: Over time, the behavior of warriors from different runs became more similar (they won and lost against the same kinds of opponents in similar ways). But their code did not become the same. In other words, different “recipes” (code) can lead to very similar “flavors” (behavior). This mirrors nature, where different species evolve similar traits (like wings or eyes) in different ways.
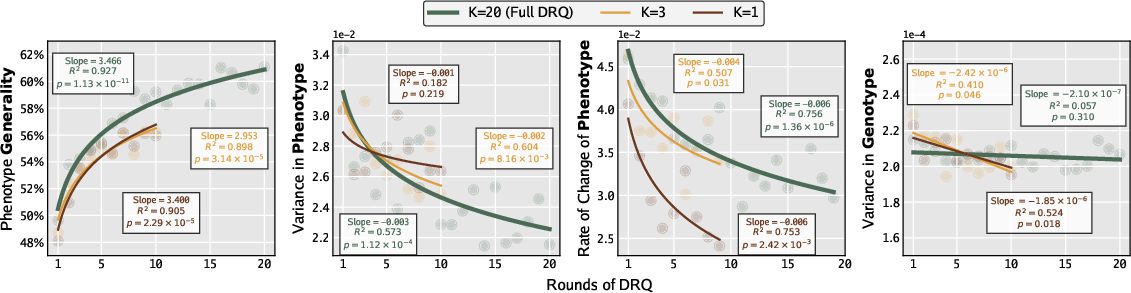
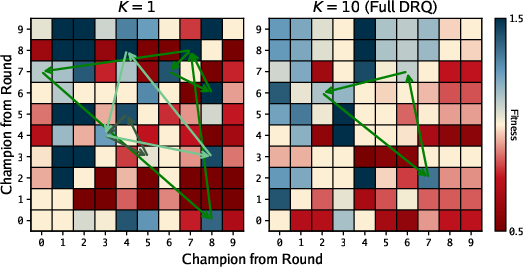
- Fewer rock–paper–scissors loops: Including more history (playing against many past opponents, not just the last one) reduced cyclic “I beat you, you beat them, they beat me” patterns.
- Diversity helps search: Keeping a variety of strategy styles (with MAP-Elites) led to better results than narrowing down to just one style. Without diversity, progress slowed.
- Predicting strength from code is possible (to a point): A simple predictor that looked at code embeddings could moderately guess how general a warrior would be, without running the full set of simulations. It wasn’t perfect, but it’s promising and could save time or help interpret what makes code strong.
Why This Research Matters
This work shows a simple, practical way to push AI systems to become more robust: don’t train them on a fixed test—make the test evolve. That makes them learn strategies that work in many situations, not just one. Studying this in a safe, contained game like Core War helps us understand “arms race” dynamics that also show up in the real world, like cybersecurity (attackers and defenders) or medicine (drugs and resistant bacteria).
The method is simple enough to try in other competitive settings. It could help us:
- Build stronger defenses by automatically “red-teaming” systems before they face real threats.
- Explore safer ways to study adversarial evolution without real-world risks (Core War is a sandbox).
- Design AI training setups that grow general skills, not just one-off tricks.
In short, by making AI “run to stay in place” against a constantly improving set of opponents, we can encourage it to discover sturdy, flexible strategies—much like living things do in nature.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list captures what remains missing, uncertain, or unexplored in the paper and suggests concrete directions for future research:
- Fitness formulation clarity and sensitivity: The printed fitness formula appears malformed; formally specify the fitness computation and ablate alternative reward shapings (e.g., survival-only, kill-weighted, multi-agent non-zero-sum variants) to quantify sensitivity of DRQ outcomes.
- 1v1-centric generality metric: Generality is measured only in 1-on-1 battles; evaluate robustness in multi-warrior battles (varying N, spawn order, and placement randomness) to reflect the actual training context and multi-agent dynamics.
- Dataset bias and representativeness of human warriors: Characterize the strategy distribution of the 294/317 human warriors (e.g., bomber/scanner/replicator proportions, era, difficulty) and test generalization to newly curated, stronger, and adversarially designed human warriors to reduce evaluation bias.
- Missing baseline against purely non-LLM evolution: Quantify search efficiency and final performance against random mutation, genetic programming, and evolutionary baselines without LLMs to isolate the contribution of LLM-guided mutations.
- Limited comparison to alternative self-play frameworks: Compare DRQ against PSRO/FSP variants (e.g., explicit meta-game solving or opponent mixtures) to test whether convergence and generality gains are method-specific or general across self-play paradigms.
- Scaling and compute costs with growing opponent history: Measure how optimization time and variance scale with history length K and number of rounds T; explore opponent sub-sampling, reservoir strategies, or meta-mixture opponents to maintain tractable cost at large T.
- Theoretical analysis of convergence: Provide a game-theoretic or dynamical systems analysis of the observed phenotypic convergence, including conditions for a universal attractor, convergence rates, and whether Core War admits approximate Nash equilibria under DRQ.
- Cycle detection beyond triads: Extend cyclicity analysis beyond 3-cycles using graph-theoretic methods (e.g., longer cycles, strongly connected components) and quantify how cycles impact optimization and generality.
- Behavioral descriptor choice in MAP-Elites: Only two descriptors (threads, memory coverage) are used; systematically ablate/add descriptors (e.g., instruction mix, self-modification rate, spatial dispersion, kill/scan frequency, temporal burstiness) and test automatic descriptor discovery to improve QD performance.
- QD algorithm alternatives: Compare MAP-Elites to other quality-diversity algorithms (CVT-MAP-Elites, NSLC, ME-ES, Novelty Search + local competition) to see if diversity preservation and optimization speed can be improved.
- Mutation operator design: The LLM is used with simple prompts; evaluate diff-based edits, syntax/semantics-aware transformations, program repair via compile-and-run feedback, and tool-augmented prompting (e.g., Reflexion-like loops) to reduce invalid/brittle code and increase search efficiency.
- Invalid-code rate and repair strategies: Report the rate of invalid or non-functional Redcode produced by the LLM and assess automated repair pipelines’ effectiveness; measure the impact on search throughput.
- LLM model choice and training: Only GPT-4.1 mini is used; evaluate code-specialized and open-weight models, domain fine-tuning on Redcode, instruction-following variants, and temperature/decoding strategies to identify which capabilities matter for adversarial program synthesis.
- Surrogate modeling beyond linear probes: The R2≈0.46 predictor is linear and text-embedding-based; explore richer surrogates (AST/graph-based representations, code transformers trained on Redcode, hybrid models using short simulation traces) and integrate them into DRQ for pre-filtering or simulation bypass.
- Genotype representation inadequacy: Text embeddings may miss program structure/semantics; test AST-level distances, control-flow/data-flow graphs, opcode-level histograms, and semantics-preserving metrics to better capture genotypic similarity and its relation to phenotypic convergence.
- Exploitability and equilibrium analysis: Measure exploitability of DRQ champions (e.g., via best-response training) and compute meta-game equilibria to quantify how close DRQ populations are to Nash or coarse correlated equilibria.
- Initialization effects: Quantify sensitivity to the choice of initial warrior w0 and initial archive composition; test diverse initial populations and meta-initialization strategies to reduce path dependence.
- Parameter sweeps and robustness: Systematically vary archive size, iteration count, mutation rate, LLM temperature, evaluation seeds, core size, and timestep budget to map the stability/performance landscape and provide reproducible heuristics.
- Strategy taxonomy and interpretability: Automatically classify evolved warriors by strategy (bomber, replicator, scanner, hybrid), track their prevalence across rounds, and link the convergent phenotype to known strategic motifs to mechanistically explain generality.
- Bridging 1v1 phenotype to multi-agent training context: Analyze the relationship and potential mismatch between 1v1 phenotype vectors and training in multi-agent environments; introduce multi-agent phenotype measures and test their predictive power.
- Opponent selection policies: Instead of “all past champions,” evaluate prioritized sampling (e.g., high-exploitability, diverse-behavior, or hardest-opponent selection) to reduce cycles and accelerate generality gains.
- Long-run open-endedness: Assess whether DRQ saturates (e.g., diminishing returns in generality) and test mechanisms to sustain innovation (environmental shifts, randomized core rules, resource constraints, or co-evolving environment parameters).
- Multi-population coevolution: Move beyond a linear lineage to co-evolving populations with reproduction and selection, measuring ecosystem-level diversity, mutualism/antagonism, and emergent niches.
- Robustness to simulator stochasticity: Quantify variance across randomized placements/seeds and report confidence intervals; use ensemble evaluations to ensure reliable fitness estimates and fair comparisons.
- Reproducibility and benchmarking: Standardize and release the exact human warrior sets, seeds, simulator configs, and evaluation scripts; propose a shared Core War benchmark (tasks, metrics, splits) for Red Queen studies.
- Transfer to practical domains and safety: Empirically test DRQ in other adversarial sandboxes (e.g., micro-CTFs, sandboxed exploit/defense games, synthetic biological simulators) and analyze dual-use/safety implications before transitioning beyond Core War.
Practical Applications
Immediate Applications
Below are practical, deployable applications that leverage the paper’s findings, methods, and tooling today.
- Sector: Software Security (Cybersecurity)
- Application: Adversarial self-play red-teaming in a sandbox
- What to deploy: A DRQ-like self-play pipeline that continuously evolves attack “warriors” (scripts or agents) against instrumented microservices or protocol emulations inside a contained VM/simulator, with a growing archive of historical opponents to reduce cycles and overfitting.
- Potential tools/products/workflows: “Red-Queen CI/CD” stage that spins up adversaries per commit; MAP-Elites for diversity across attack behaviors (e.g., payload coverage, thread/process spawning); automatic generality scoring; historical-opponent replay archive.
- Assumptions/dependencies: High-fidelity simulators of target services; compute budget for iterative rounds; careful guardrails to prevent real-system targeting; organizational buy-in for offensive testing; legal/ethical approvals.
- Sector: AI Evaluation and Benchmarking
- Application: Core War as a benchmark to assess LLM self-play and adversarial adaptation
- What to deploy: A standardized “Core War Red Queen Benchmark” to measure model-driven evolution under shifting opponent sets, generality against held-out strategies, and phenotypic convergence.
- Potential tools/products/workflows: Leaderboards for generality; variance-of-phenotype metrics; reproducible DRQ runs with public seeds; integration with FSP/PSRO baselines for comparison.
- Assumptions/dependencies: Shared datasets of human-designed warriors; consistent simulator configs; standardized metrics and reporting.
- Sector: Software Testing and QA
- Application: Diversity-preserving test generation (MAP-Elites + LLM mutations)
- What to deploy: Use LLMs as mutation operators to evolve diverse test inputs or harnesses while MAP-Elites tracks behavioral descriptors (e.g., code coverage, concurrency, memory footprint), reducing brittleness in tests.
- Potential tools/products/workflows: “Quality-Diversity Fuzzer” that evolves payload families rather than single best cases; descriptor grids tied to coverage and resource use; integration with existing fuzzing frameworks.
- Assumptions/dependencies: Meaningful behavior descriptors must correlate with bugs/coverage; instrumentation to measure descriptors; domain-specific mutation prompts.
- Sector: AI/ML Engineering (MLOps)
- Application: Historical self-play archives for robust agent training
- What to deploy: Maintain an opponent/history buffer of previous agents in multi-agent training (similar to DRQ’s K-round history) to reduce cycles and promote generalist strategies.
- Potential tools/products/workflows: Opponent sampling policies; systematic ablation of history length (K) to balance compute and robustness; phenotype trend monitoring dashboards.
- Assumptions/dependencies: Stable training environment; ability to serialize opponents; careful mixture policies to avoid catastrophic forgetting.
- Sector: Model-Assisted Development
- Application: Surrogate pre-filtering of evolved code with embeddings
- What to deploy: A lightweight embedding-based scorer to triage candidate code edits before full simulation, using a linear probe over code embeddings to predict generality/performance.
- Potential tools/products/workflows: “Surrogate Fitness Gate” that discards low-promise candidates; periodic recalibration as data grows; uncertainty thresholds to avoid false negatives.
- Assumptions/dependencies: Moderate predictive power (R²≈0.44–0.46 in paper); domain shift sensitivity; safe handling of noisy labels; retraining with fresh data as strategies evolve.
- Sector: Education (CS/AI curricula)
- Application: Teach adversarial dynamics and self-modifying code safely
- What to deploy: Course modules or hackathons using Core War for hands-on learning about arms races, self-play, quality-diversity, and assembly-like programming within a safe, Turing-complete sandbox.
- Potential tools/products/workflows: Classroom DRQ labs; leaderboard challenges; structured assignments analyzing phenotypic convergence and cyclic dynamics.
- Assumptions/dependencies: Instructor familiarity; accessible tooling; clear safety rules; sandbox constraints enforced.
- Sector: Research (Artificial Life, Multi-Agent Systems)
- Application: Study convergent evolution and Red Queen dynamics in silico
- What to deploy: Replicate DRQ experiments to analyze genotype vs. phenotype convergence, cycles, and generalist emergence under different descriptors and opponent histories.
- Potential tools/products/workflows: Shared archives; standardized descriptors; cross-lab replication; comparative studies with non-LLM mutations.
- Assumptions/dependencies: Compute for multi-round runs; open-source simulator parity; consistent evaluation suites.
- Sector: Governance and AI Policy
- Application: Safe pre-deployment adversarial testing protocols
- What to deploy: Policy guidance recommending sandboxed Red Queen testing (e.g., Core War-like environments) for dual-use risk assessment of autonomous LLM agents before real-world interaction.
- Potential tools/products/workflows: “Adversarial Readiness Levels” that incorporate generality and cycle-resilience metrics; mandated simulation-based stress tests for critical systems.
- Assumptions/dependencies: Regulatory acceptance; standardized benchmarks; oversight to ensure tests stay within sandbox boundaries.
Long-Term Applications
Below are applications that are feasible with further research, scaling, domain adaptation, or productization.
- Sector: Cybersecurity (Enterprise/ICS/OT)
- Application: Continuous coevolution of exploits and defenses in realistic system simulators
- What could emerge: “Digital Immune Systems” where DRQ-style agents generate evolving attacks while defensive agents adapt (patches, rule updates), measured by generality against diverse threat repertoires.
- Assumptions/dependencies: High-fidelity system digital twins; secure containment; rapid patch synthesis; robust evaluation preventing overfitting to simulator quirks; strict governance to avoid dual-use misuse.
- Sector: Biosecurity and Drug Discovery
- Application: Adversarial coevolution of pathogens and therapeutics in computational models
- What could emerge: Co-designed drug candidates robust to resistance (“Red-Queen Pharma”), with MAP-Elites maintaining diversity in molecular scaffolds; generality metrics measuring efficacy across variant panels.
- Assumptions/dependencies: Validated biophysical simulators; multi-objective fitness (efficacy, toxicity, manufacturability); translational pipelines; strong ethical/regulatory frameworks.
- Sector: Robotics and Autonomous Systems
- Application: Multi-agent adversarial self-play for robust behaviors (pursuit-evasion, swarm defense)
- What could emerge: Training regimes where agents learn general-purpose strategies against evolving adversaries; convergence analyses guiding architecture choices.
- Assumptions/dependencies: Sim-to-real transfer; safe adversarial curricula; descriptor design capturing salient behavior (e.g., coverage, collisions, energy usage); reliable sensor/actuator models.
- Sector: Finance
- Application: Coevolutionary training of trading agents under adversarial market scenarios
- What could emerge: Stress-tested strategies resilient to evolving opponent tactics, with MAP-Elites preserving diverse niches (risk profiles, instruments, latencies).
- Assumptions/dependencies: Realistic market simulators; guardrails against manipulation; regulatory compliance; careful fitness shaping to avoid emergent pathological behaviors.
- Sector: Software Engineering (Program Synthesis/Optimization)
- Application: Red-Queen evolution of performance-robust algorithms (compilers, schedulers, kernels)
- What could emerge: Auto-generated code techniques that remain performant across changing workloads/hardware; generality assessed against diverse benchmarks; LLM mutation plus QD to explore non-obvious designs.
- Assumptions/dependencies: Accurate performance simulators; descriptor choices aligned with resource/latency metrics; integration with autotuners; IP/licensing concerns.
- Sector: Cloud/DevSecOps
- Application: Live “Red-Queen” hardening services (Red-Queen-as-a-Service)
- What could emerge: Managed pipelines that continuously evolve adversarial tests against customer stacks, generating actionable defense updates and generality reports.
- Assumptions/dependencies: Customer data isolation; multi-tenant safety; standardized reporting and SLAs; on-demand compute elasticity.
- Sector: AI Systems Safety
- Application: Regulatory standards for adversarial coevolution testing of agentic LLMs
- What could emerge: Certification schemes requiring demonstration of robustness under Red Queen benchmarks; phenotype variance thresholds; cycle-resilience criteria.
- Assumptions/dependencies: Broad stakeholder consensus; measurement reproducibility; alignment with existing safety frameworks.
- Sector: Applied Methodology (Surrogate Modeling)
- Application: Advanced surrogate predictors replacing parts of expensive simulations
- What could emerge: Learned fitness models that enable rapid inner-loop search, active learning to select informative simulations, and interpretable embeddings linking code features to performance.
- Assumptions/dependencies: Higher predictive accuracy than current linear probes; uncertainty-aware selection; domain-specific feature engineering; continual recalibration.
- Sector: Game AI and Esports
- Application: Open-ended coevolution of strategies and maps/rules (POET-like + DRQ)
- What could emerge: Ever-evolving meta where agents remain robust to new content and opponent sets; tools for tournament balance testing.
- Assumptions/dependencies: Content generation pipelines; community acceptance; anti-cheat integration; compute scaling.
- Sector: Scientific Discovery (Complex Systems)
- Application: Mechanistic insights into convergent evolution and arms races
- What could emerge: Cross-domain theories linking phenotypic convergence without genotypic collapse; experimental platforms for testing hypotheses about selection pressures, diversity maintenance, and curriculum shaping.
- Assumptions/dependencies: Interdisciplinary collaboration; consistent experimental protocols; dedicated funding for long-run studies.
In all long-term cases, feasibility hinges on several common dependencies: high-fidelity simulators tailored to the domain; robust guardrails to prevent dual-use harm; scalable compute for multi-round coevolution; standardized descriptors and metrics (generality, phenotype variance, cycle counts); and organizational/regulatory alignment to adopt adversarial testing as a core practice.
Glossary
- Adversarial dynamics: Competitive interactions where agents continually co-adapt against one another. "overlooking the open-ended adversarial dynamics that characterize real-world evolutionary processes."
- Behavior descriptor: A compact feature tuple summarizing behavior, used to place solutions into MAP-Elites cells. "We define the behavior descriptor function as the discretized tuple (total spawned processes, total memory coverage)"
- Convergent evolution: Independent evolution toward similar functional strategies under similar selection pressures. "much like convergent evolution in nature."
- Core War: A programming game where assembly-like programs (“warriors”) battle for control of a shared virtual machine. "Core War is a classic programming game, studied in both artificial life and cybersecurity"
- Cyclic dynamics: Recurring dominance loops among strategies (e.g., rock–paper–scissors). "Cyclic dynamics are a well-known phenomenon in self-play and coevolutionary systems"
- DAT instruction: A Redcode instruction that causes a process to crash when executed. "A program can inject a DAT instruction in front of an opponent's process, terminating it when that process attempts to execute it."
- Fictitious Self-Play (FSP): A self-play method that learns best responses to the empirical average of opponents’ past policies. "Within self-play, our DRQ algorithm is closely related to Fictitious Self-Play (FSP)"
- Fitness landscape: The mapping from solutions to performance; static landscapes have fixed objectives and do not change during search. "do not operate as optimization on a static fitness landscape"
- Foundation Model Self-Play (FMSP): A framework where foundation models generate competing agents trained via self-play. "\citet{dharna2025foundation} was the first to propose Foundation Model Self-Play (FMSP)"
- Generality: The breadth of performance against diverse, unseen opponents. "Generality is defined as the fraction of unseen human warriors defeated or tied"
- Genotype: The underlying representation of an agent (here, a code embedding) that gives rise to behavior. "A warriorâs genotype is defined as a text embedding of its source code"
- LLM-guided evolution: Using LLMs to propose mutations or generate candidates in evolutionary search. "These works demonstrate that LLM-guided evolution can act as engines of discovery in many domains."
- Linear probe: A simple linear model trained on embeddings to predict a target property. "train a linear probe to predict the warrior's final generality score."
- MAP-Elites: A quality-diversity evolutionary algorithm that fills an archive with high-performing, behaviorally diverse elites. "DRQ uses MAP-Elites, a quality-diversity algorithm, to optimize warriors within each round"
- Meta-game: A game defined over strategy populations used to compute mixture distributions and equilibria. "solve a meta-game to compute Nash equilibrium distributions over the strategy population."
- Nash equilibrium: A strategy (or distribution) where no player can improve by unilaterally changing their strategy. "compute Nash equilibrium distributions over the strategy population."
- Open-ended evolution: An evolutionary process without a fixed target, continually generating new challenges and adaptations. "recent studies have begun to study open-ended evolution with LLMs"
- Phenotype: The observable performance profile of an agent across tasks or opponents. "A warriorâs phenotype is defined as a vector of fitness values against each unseen human warrior."
- Policy Space Response Oracles (PSRO): An algorithm that iteratively adds approximate best-response policies and solves a meta-game over them. "PSRO iteratively expands a population of policies by training approximate best responses to mixtures of existing strategies and solving a meta-game to compute Nash equilibrium distributions over the strategy population."
- Quality-diversity algorithm: An approach that seeks many diverse high-quality solutions rather than a single optimum. "MAP-Elites, a quality-diversity algorithm"
- Red Queen dynamics: Continuous co-adaptive pressure where agents must evolve just to maintain relative fitness. "embraces these so-called ``Red Queen'' dynamics via continual adaptation to a changing objective."
- Red Queen hypothesis: A biological theory stating organisms must continuously evolve to maintain their fitness relative to others. "this continual pressure to adapt is known as the Red Queen hypothesis"
- Redcode: The assembly-like language used to program Core War warriors. "Warriors are written in the Redcode assembly language"
- Rock–paper–scissors dynamic: A cyclical dominance relation where each strategy defeats one and loses to another. "have a rock-paper-scissors dynamic."
- Self-modifying code: Code that alters its own instructions during execution. "self-modifying code is commonplace."
- Self-play: Training by playing against oneself or historical versions of oneself to drive improvement. "Reinforcement learning has also taken inspiration from Red Queen dynamics in the form of self-play."
- Surrogate model: A predictive model used to approximate expensive simulation-based evaluations. "either as surrogate models to bypass simulation"
- Zero-shot: Performance on new tasks without task-specific training. "measuring a warriorâs ability to adapt to novel threats in a zero-shot setting."
Collections
Sign up for free to add this paper to one or more collections.