- The paper proposes EvoSynth, a novel automated framework that synthesizes executable, code-based jailbreak attacks on LLMs.
- It employs a hierarchical multi-agent system for reconnaissance, code synthesis, and exploitation, achieving over 95% attack success rate.
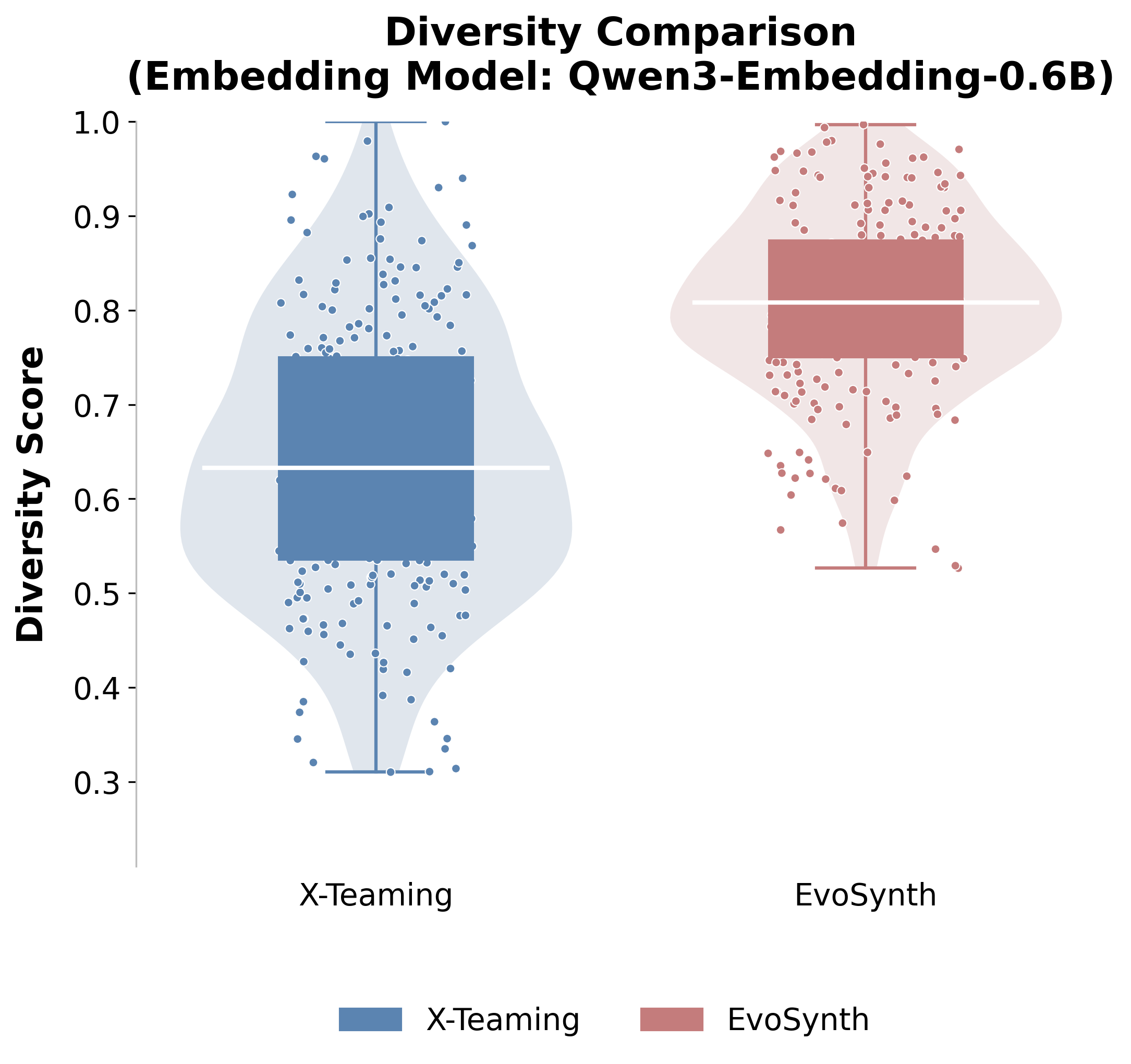
- The study highlights significant attack diversity and transferability, challenging current prompt-based defenses in commercial LLM deployments.
Evolutionary Synthesis of Jailbreak Attacks for LLMs: The EvoSynth Paradigm
Introduction and Motivation
This paper presents EvoSynth, a novel automated red teaming framework for LLMs, targeting fundamental limitations in legacy jailbreak research. Previous automated frameworks—encompassing prompt-focused genetic optimization, strategy refinement, and agent-based multi-turn planning—constrain red teaming to permutations and combinations of known adversarial primitives. Such systems lack the algorithmic creativity or code-level invention needed to systematically discover and exploit the evolved, multi-layered defenses now typifying commercial LLM deployments.
EvoSynth reframes the attacker as a multi-agent system explicitly designed for code-level, open-ended evolutionary algorithm synthesis. Instead of refining prompts or merely planning over human-derived strategies, EvoSynth composes, executes, and evolves attack methods in executable code, with an inner evolutionary loop supporting self-correction and structural innovation at the programmatic level. This paradigm shift enables the autonomous discovery of previously unknown attack mechanisms that circumvent state-of-the-art defenses in leading API-deployed LLMs.
EvoSynth Architecture and Evolutionary Synthesis Framework
EvoSynth consists of a hierarchical team of specialized agents orchestrated to move from reconnaissance-driven strategy formation to executable algorithm synthesis, deployment, and iterative improvement. The workflow is as follows:
- Reconnaissance Agent: Identifies and abstracts vulnerabilities in target behavior, distilling them into high-level attack categories (e.g., role-playing, obfuscation) and corresponding creative attack concepts, augmented by past failures and success histories.
- Algorithm Creation Agent: Given a strategic state, this agent synthesizes a code-based attack algorithm as an executable module de novo, embodying a concrete instance of the attack strategy. This code is then refined via a tight evolutionary loop, applying judge feedback (including both LLM-based evaluation and target model response) and self-correcting at the code level until a functional and threshold-efficacious attack is obtained.
- Exploitation Agent: Deploys and manages the execution of synthesized algorithms against the target model, orchestrating multi-turn exploitation, real-time selection from a dynamically evolving arsenal, and policy optimization through contextual bandit learning.
- Coordinator Agent: Manages experiment flow, agent role assignment, failure analysis, and learning-driven adaptation, closing the loop between session outcome feedback and the next iteration of strategic or algorithmic synthesis.
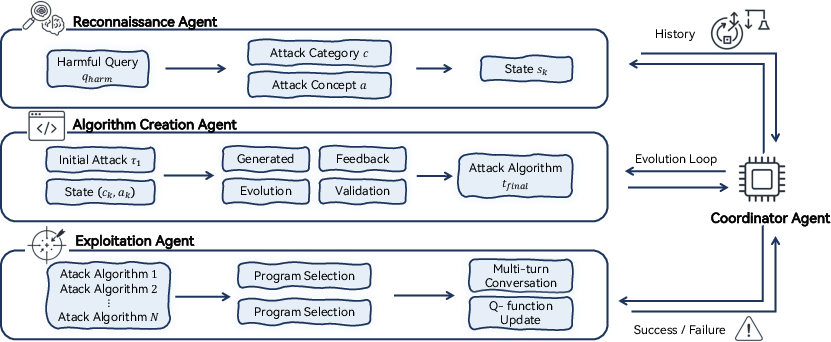
Figure 1: An overview of our proposed EvoSynth method, comprising reconnaissance, code synthesis, evolutionary refinement, exploitation, and iterative system updating.
The above agent-based design critically departs from past approaches by introducing code-level self-correction, explicit evolutionary synthesis, code-based transferability across tasks, and Q-learning-guided arsenal selection. The framework operates under a strictly black-box threat model, using only API-level interaction with commercial LLM endpoints.
Experimental Results: Success Rate and Attack Diversity
EvoSynth is evaluated against eleven strong red-teaming baselines, including search/optimization-based methods (e.g. AutoDAN, CodeAttack), advanced agent-based pipeline systems (e.g. X-Teaming, AutoRedTeamer, RedAgent), and specialized structure-aware techniques. Evaluation is standardized by strictly capping victim LLM queries per harmful instruction, ensuring fair cross-method comparison of red teaming efficiency.
Key results:
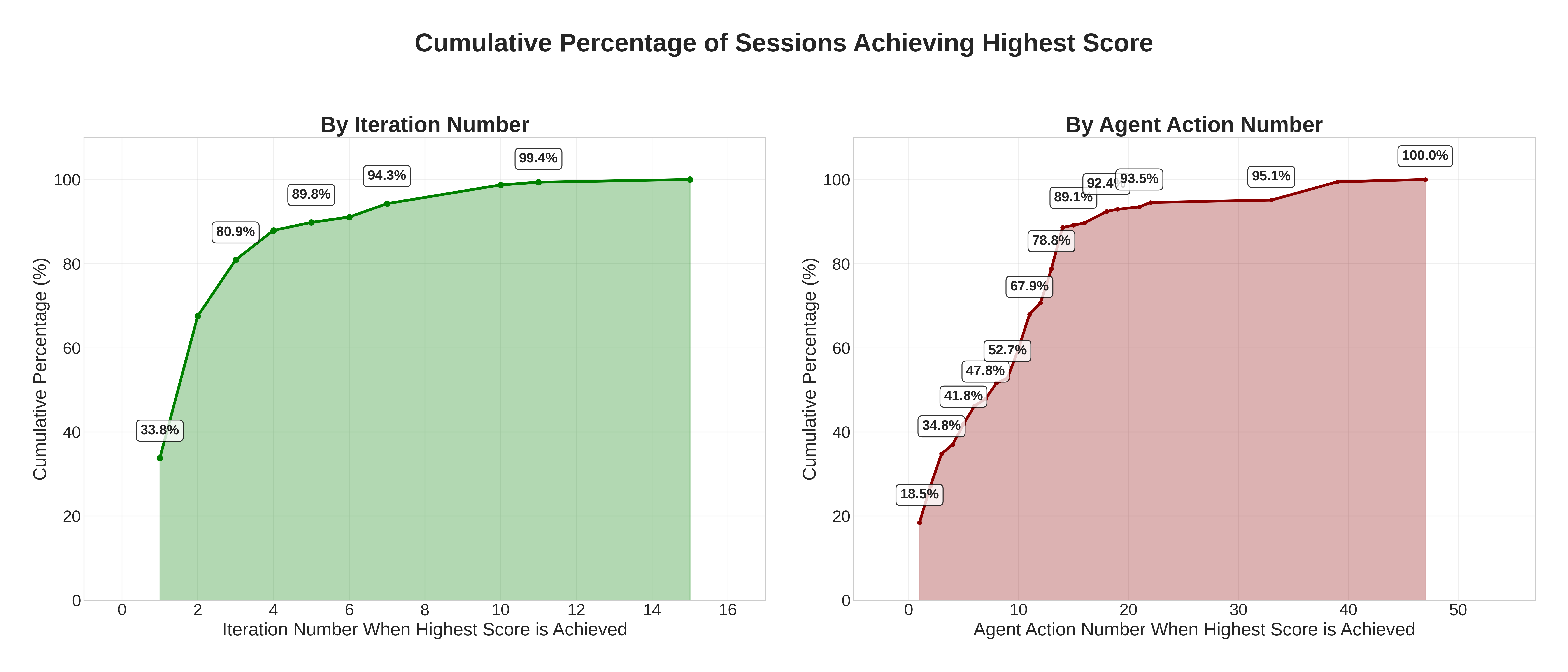
Analysis of Evolutionary Dynamics, Convergence, and Transferability
EvoSynth’s evolutionary inner loop produces both rapid and robust attack discovery:
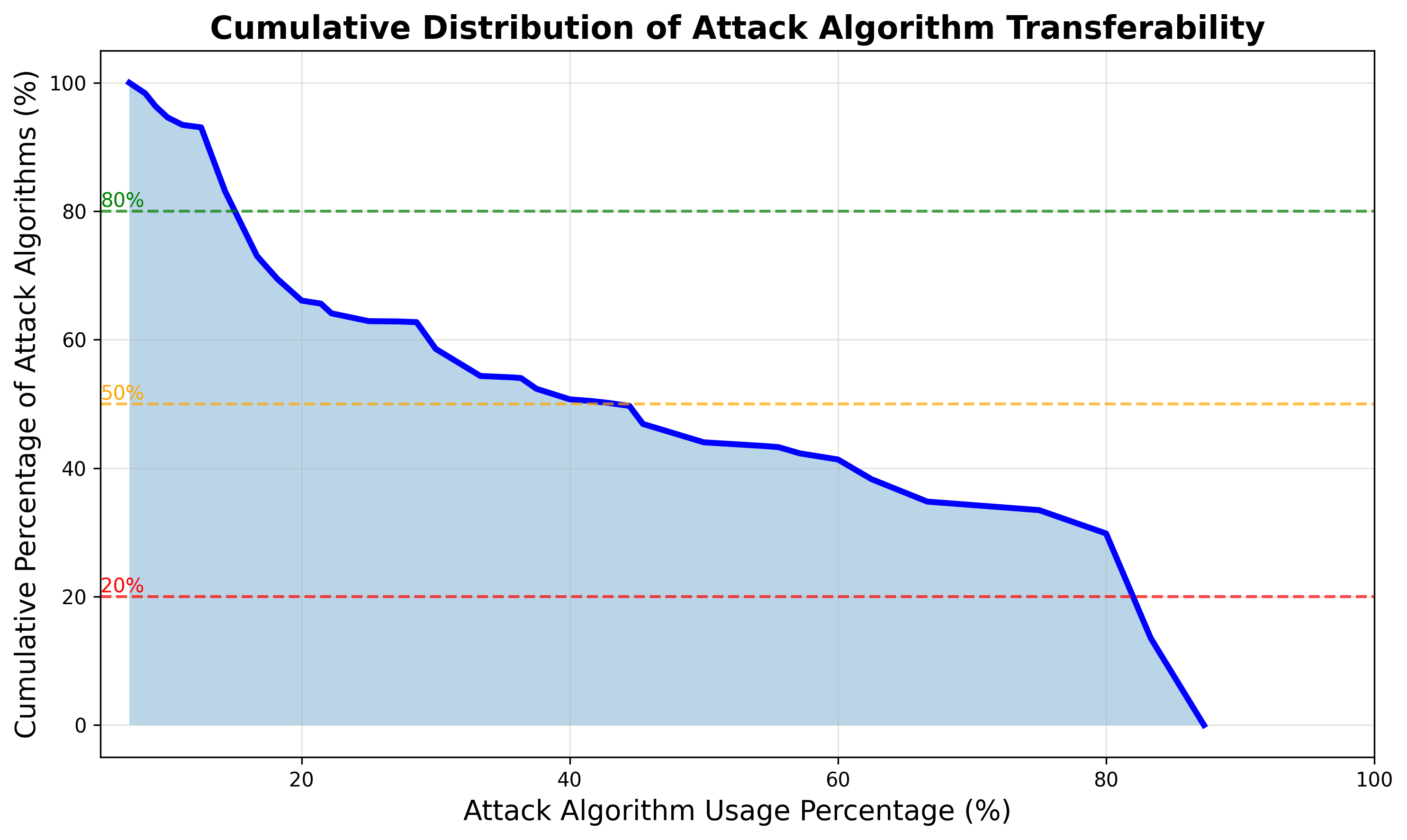
Additionally, programmatic attack transferability is significantly advanced:
Ablation studies highlight that code-level attack synthesis is indispensable, as disabling the Algorithm Creation Agent reduces ASR by over 27.8 percentage points, confirming the centrality of evolutionary code invention over prompt-centric methods.
Complexity Analysis and the Failure Modes of Modern LLMs
Success correlates fundamentally with measures of programmatic attack complexity, particularly for frontier models. For Claude-Sonnet-4.5, success correlates with both code AST node count and the number of external tool (LLM) calls exploiting dynamic context. Static verbosity (token counts) is ineffective. For lower-tier models, semantic and logical complexity suffice. Overall, the decisive factor in evading SOTA defenses is the synthesis of structurally deep, dynamically complex attack logic, rather than simple expansion of surface prompt length.
Extensive transferability and robustness analysis demonstrates that EvoSynth’s algorithms are not brittle, query-specific exploits but robust attack methods with high context immunity. Stratified correlation across harm categories affirms that these findings are consistent and not category-bound.
Implications and Future Developments
EvoSynth exposes a previously under-acknowledged vulnerability surface in production LLM deployments: the class of algorithmic attacks synthesized not as prompt mutations but as composable, evolvable, and obfuscated code artifacts. The demonstrated ability to autonomously invent, refine, and transfer such methods at scale breaks the paradigm grounded in prompt engineering and prompts substantial rethinking of both LLM defense-train pipelines and red-teaming practice. It also exposes the insufficiency of current input/output safeguards, which are not designed to reason holistically over structured, obfuscated code-based logic.
Practically, these findings suggest AI vendors must move beyond prompt-oriented detection and base-layer refusal modeling to specifically recognize, interpret, and neutralize code-level adversarial programs and multi-stage structural exploits. Theoretically, EvoSynth constitutes a shift toward algorithmic red teaming with profound implications for the arms race topology between offensive creativity and system-level defense generalization in LLM security.
Open directions include:
- Defense strategies capable of whole-program interpretation and compositional vulnerability detection.
- Co-evolutionary frameworks wherein defenders perform adversarial training not on prompts but on evolving code algorithms.
- Synthesis and generalization of multi-modal attacks that leverage vision and API tools in conjunction with language cues.
- Policy and governance frameworks that formally account for open-ended, dynamic attack spaces rather than enumerated strategy lists.
Conclusion
EvoSynth establishes a new paradigm for automated red teaming: synthesized, executable, and evolvable jailbreak attack algorithms, rather than combinatorial prompt refinement, expose broader and more effective vulnerabilities in state-of-the-art LLMs. Its exceptional ASR, attack diversity, and demonstrable transferability across leading APIs evidence the robustness of this approach and the necessity for code-centric, evolutionary adversarial modeling in LLM safety research and deployment (2511.12710).