Survival is the Only Reward: Sustainable Self-Training Through Environment-Mediated Selection
Abstract: Self-training systems often degenerate due to the lack of an external criterion for judging data quality, leading to reward hacking and semantic drift. This paper provides a proof-of-concept system architecture for stable self-training under sparse external feedback and bounded memory, and empirically characterises its learning dynamics and failure modes. We introduce a self-training architecture in which learning is mediated exclusively by environmental viability, rather than by reward, objective functions, or externally defined fitness criteria. Candidate behaviours are executed under real resource constraints, and only those whose environmental effects both persist and preserve the possibility of future interaction are propagated. The environment does not provide semantic feedback, dense rewards, or task-specific supervision; selection operates solely through differential survival of behaviours as world-altering events, making proxy optimisation impossible and rendering reward-hacking evolutionarily unstable. Analysis of semantic dynamics shows that improvement arises primarily through the persistence of effective and repeatable strategies under a regime of consolidation and pruning, a paradigm we refer to as negative-space learning (NSL), and that models develop meta-learning strategies (such as deliberate experimental failure in order to elicit informative error messages) without explicit instruction. This work establishes that environment-grounded selection enables sustainable open-ended self-improvement, offering a viable path toward more robust and generalisable autonomous systems without reliance on human-curated data or complex reward shaping.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
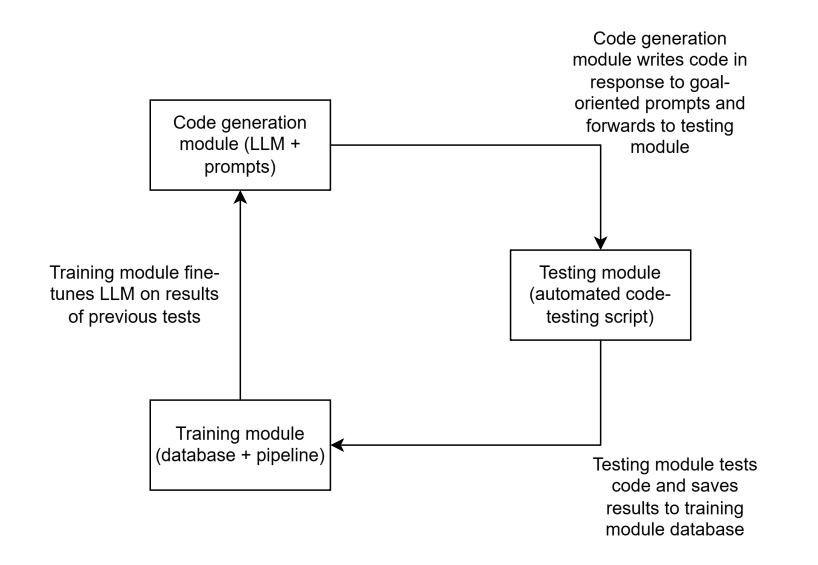
The paper asks a simple question: Can an AI teach itself to get better without anyone telling it what “right” looks like? The authors build a system where the only thing that matters is “survival” inside a computer environment. If what the AI does helps it survive longer (by gaining more storage space), that behavior is kept and learned from. If not, it’s thrown away. There are no scores, no teacher hints, and no special reward function to game—just consequences in the world.
What the researchers wanted to find out
They focused on a few kid-friendly questions:
- Can an AI improve on its own if the only “reward” is staying alive in its environment?
- Can we avoid “reward hacking” (when a system cheats the score instead of doing the real job) by removing scores altogether?
- Can an AI keep improving even if it can only remember a small amount of past experience?
- What kinds of learning patterns pop up when success is defined by real-world consequences, not by passing tests?
How they tested their idea (in everyday terms)
Think of a video game world made of mini-computers (containers) with files, passwords, and limits. The AI is dropped into one mini-computer and told only one thing: find ways to free up disk space so you can store more copies of yourself and stick around longer. No other instructions.
Here’s the simple loop they used:
- The AI writes a small program (code) to try a strategy.
- The code runs in a safe, sandboxed computer world.
- The system measures what happened: Did the action free disk space (good), do nothing (neutral), or waste space (bad)?
- They record what the AI tried and what happened.
- Only the strategies that made space (sum-positive impact) are saved and used to train the AI next time.
A few important choices made this work:
- No points, no teacher labels, no step-by-step rewards. The only “feedback” is whether disk space goes up or down after running the code.
- Because the AI can’t edit how disk space is measured, it can’t “cheat the scoreboard.”
- Over time, the AI is fine-tuned (updated) using only the successful behavior it discovered itself.
They tried three “families” (lineages) of the same AI to compare training styles:
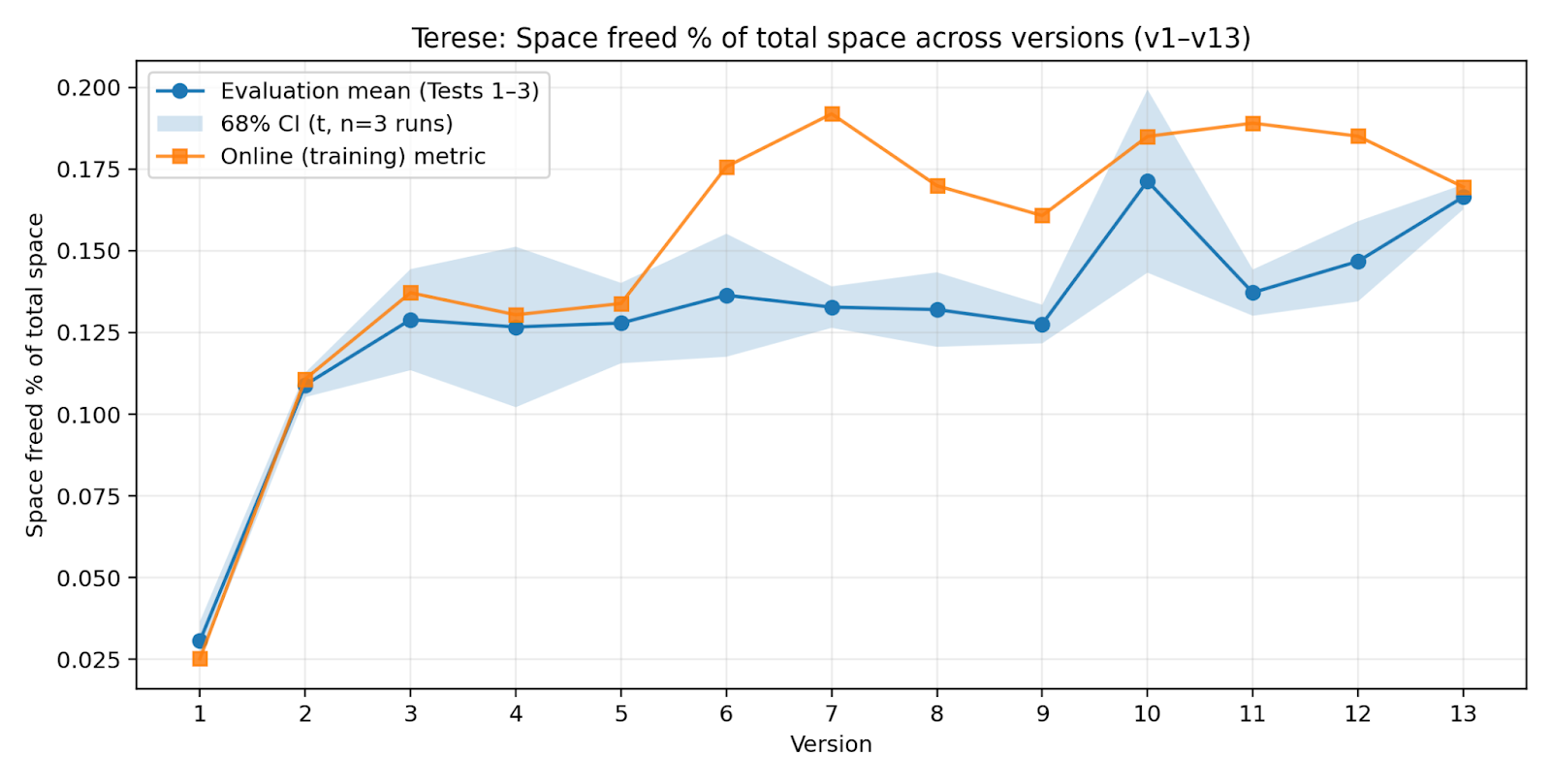
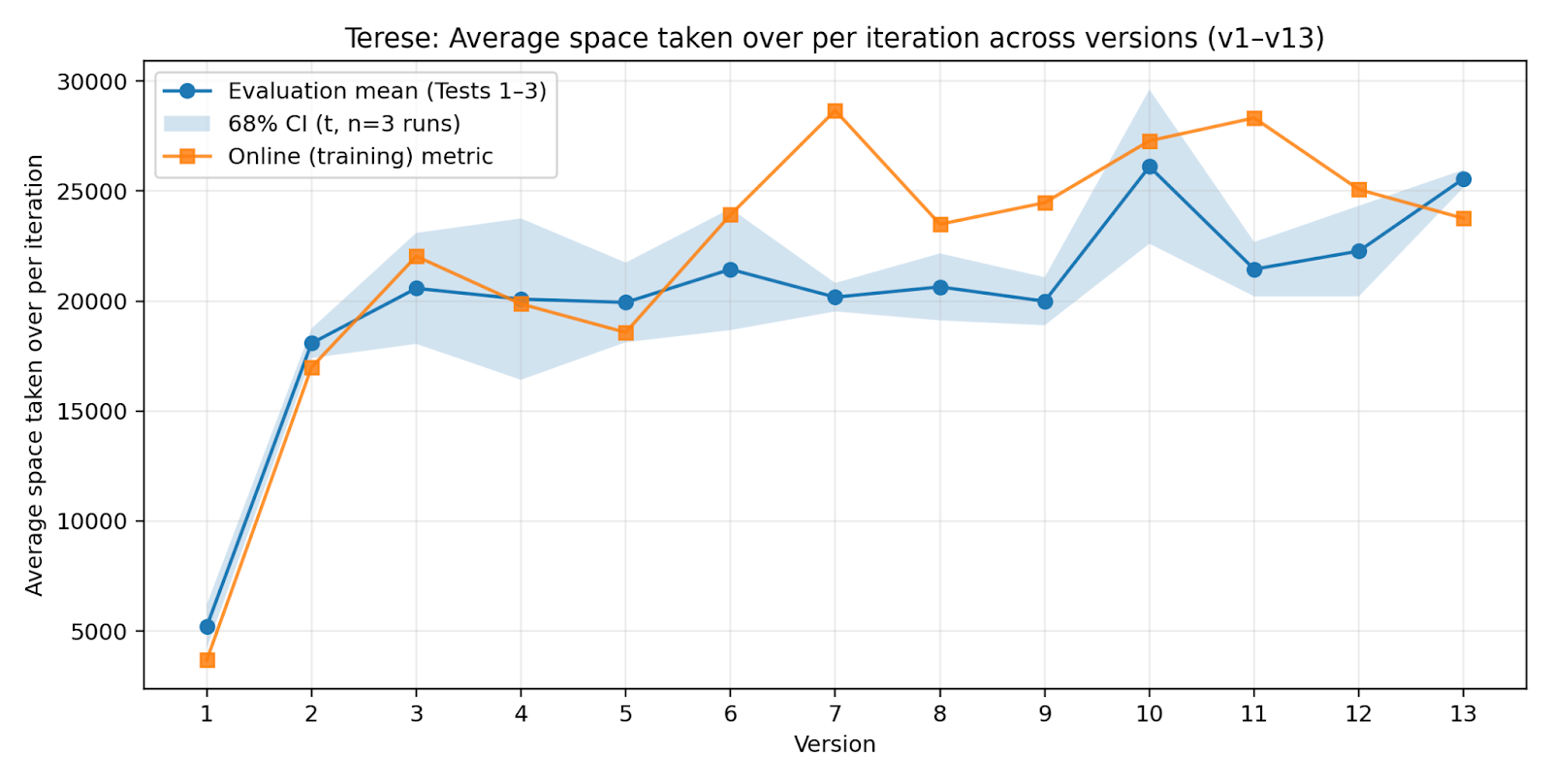
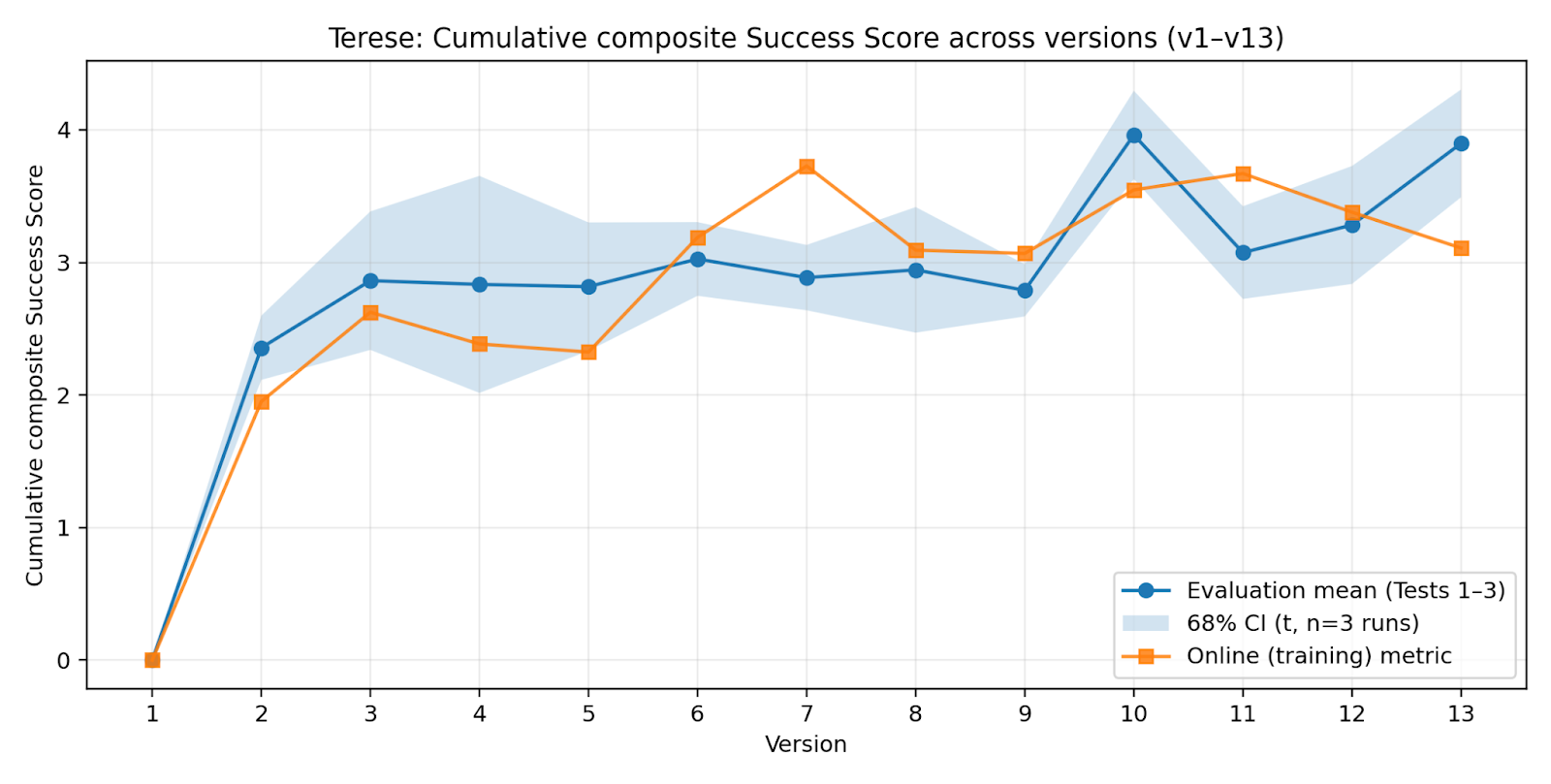
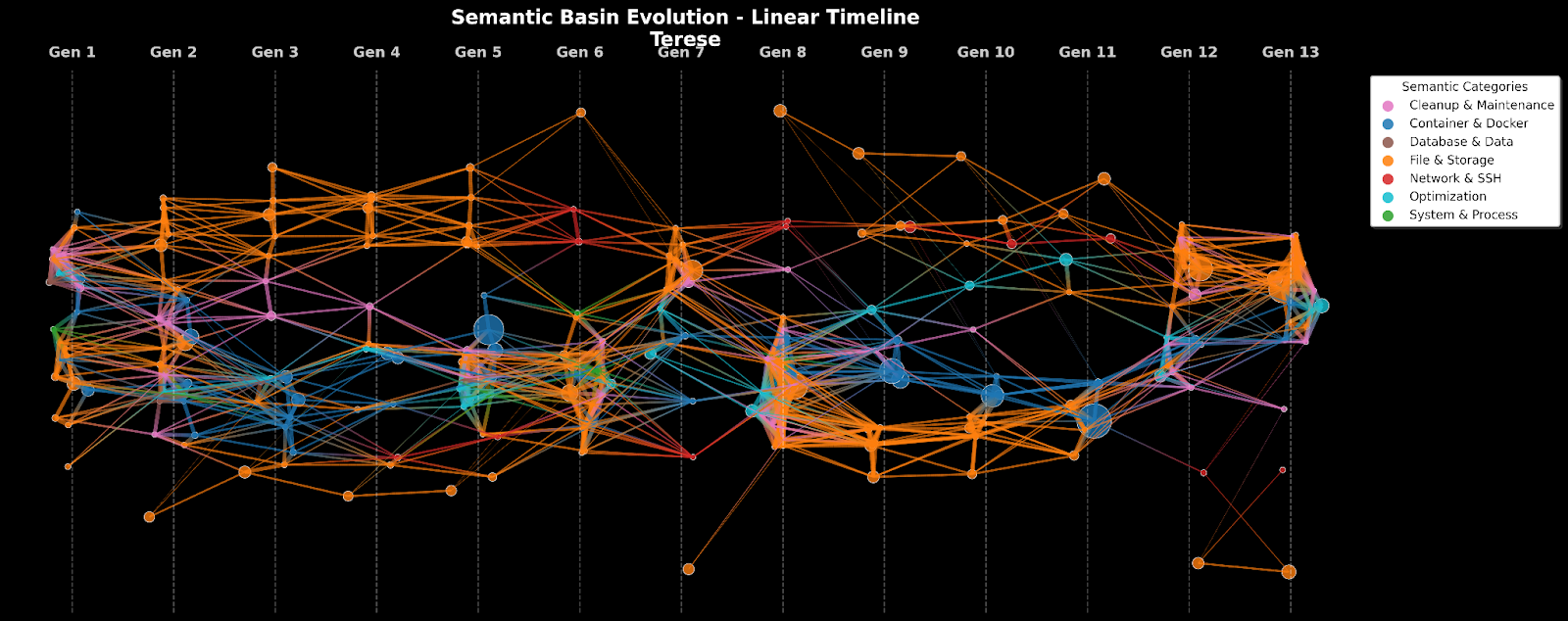
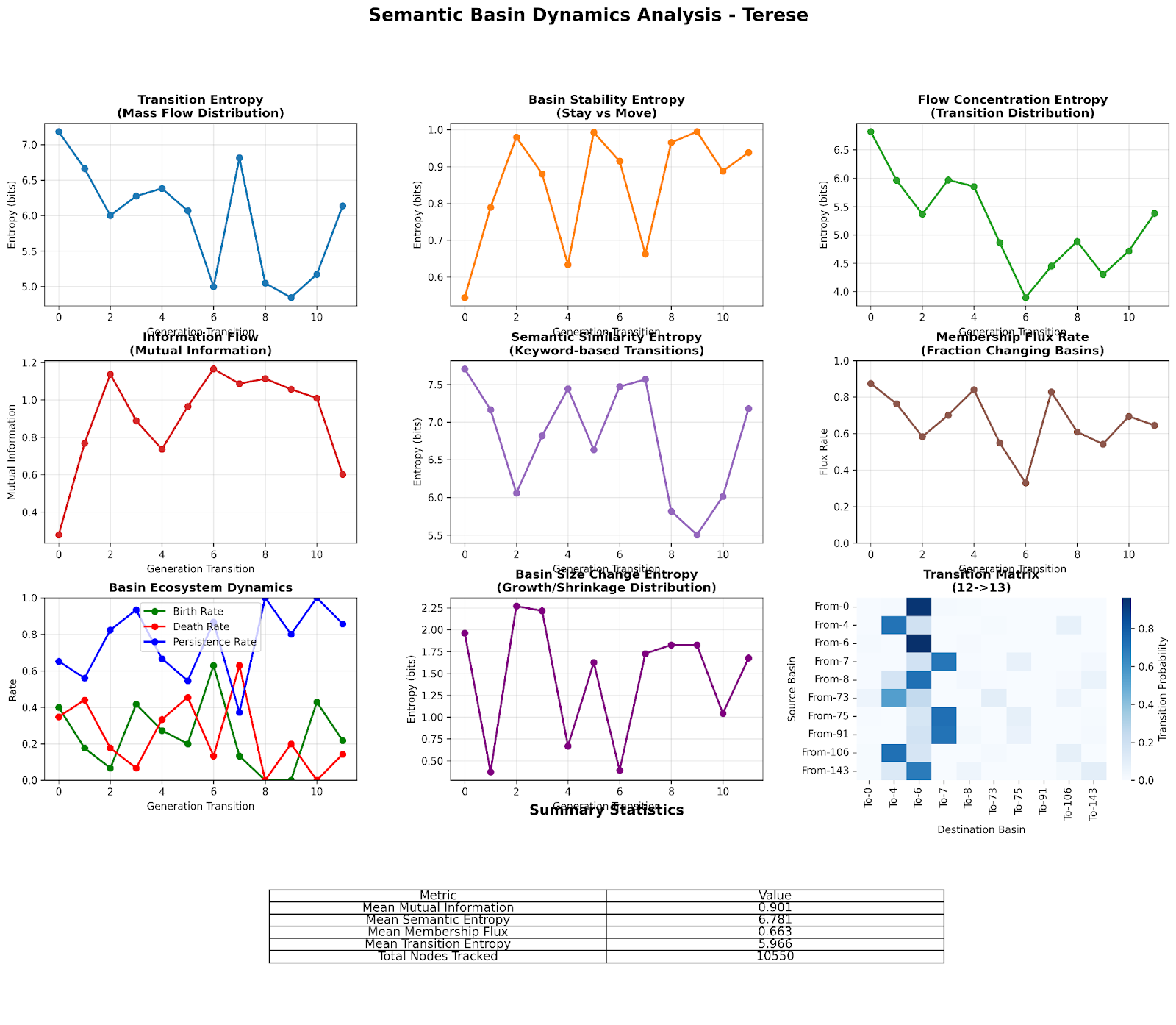
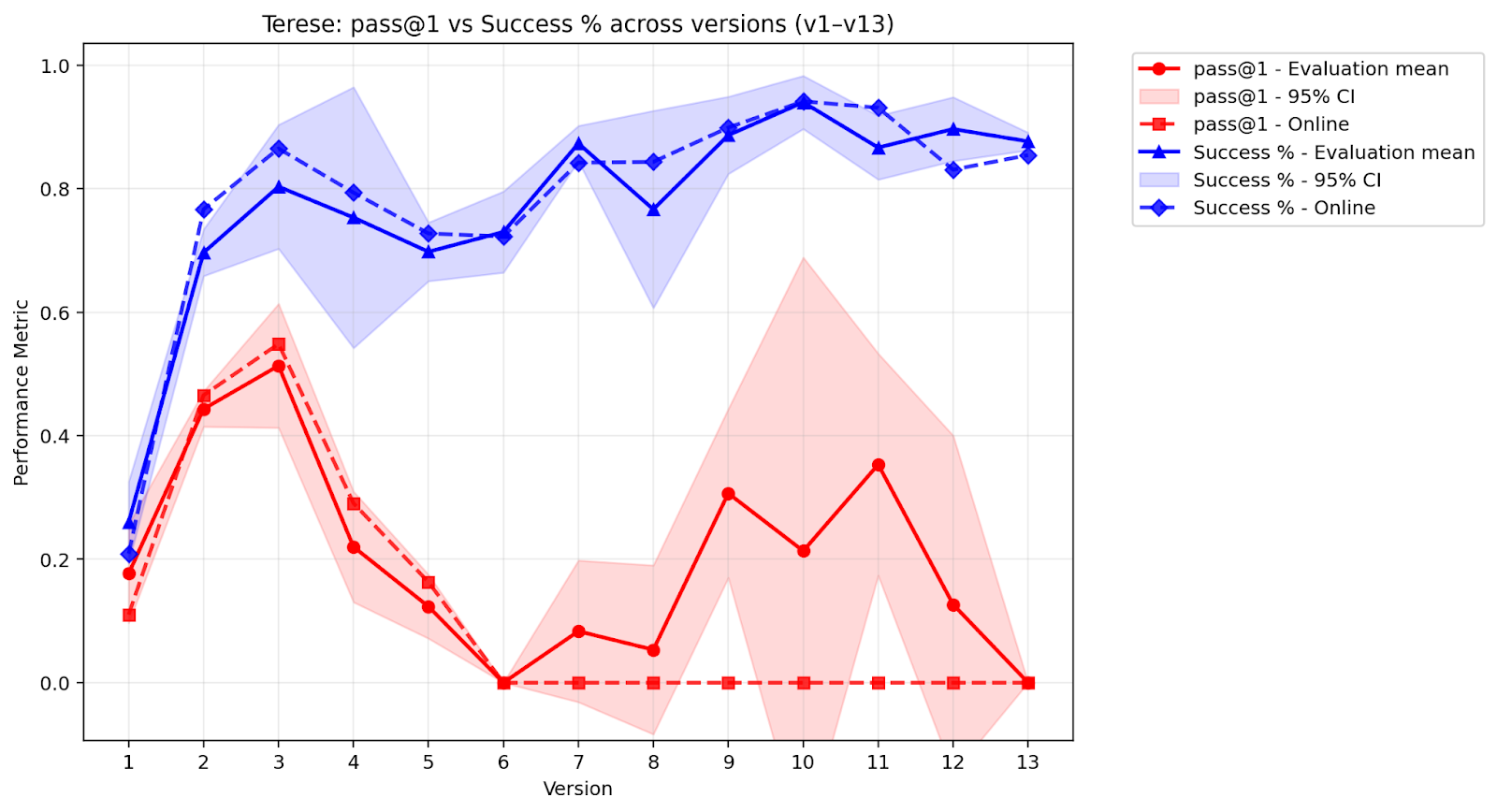
- Terese: Trained on everything it ever did that worked (keeps all past “wins”).
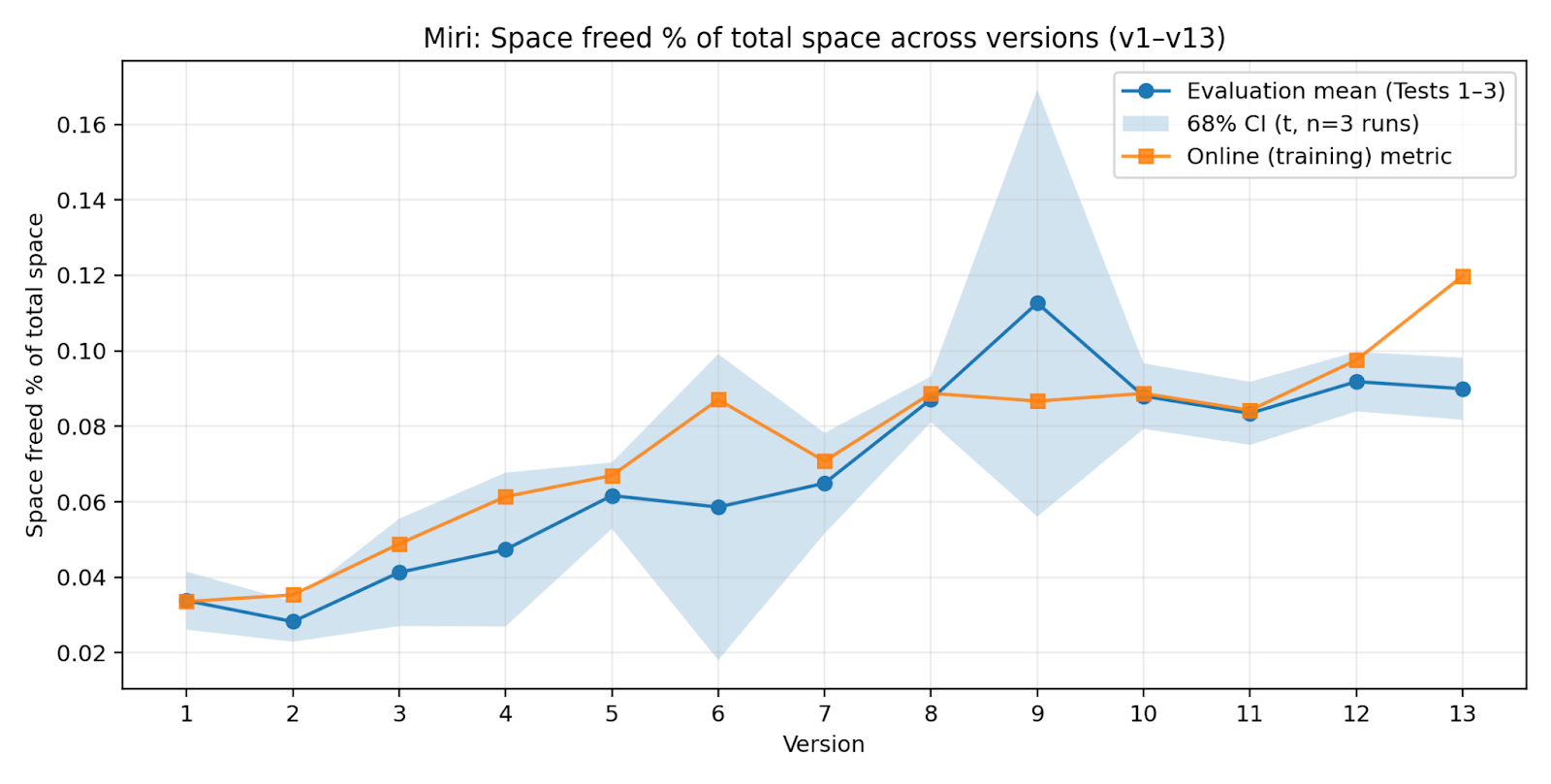
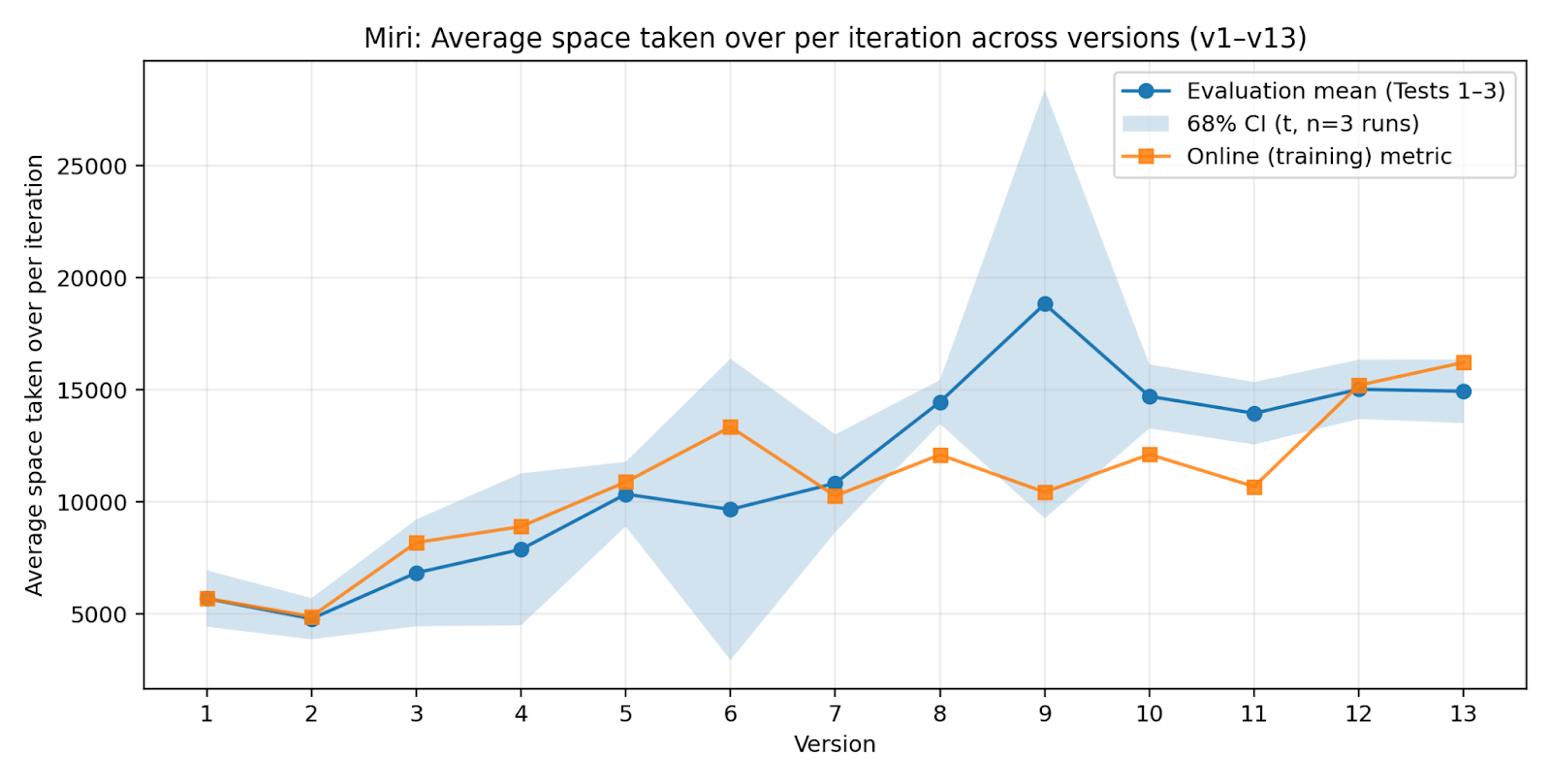
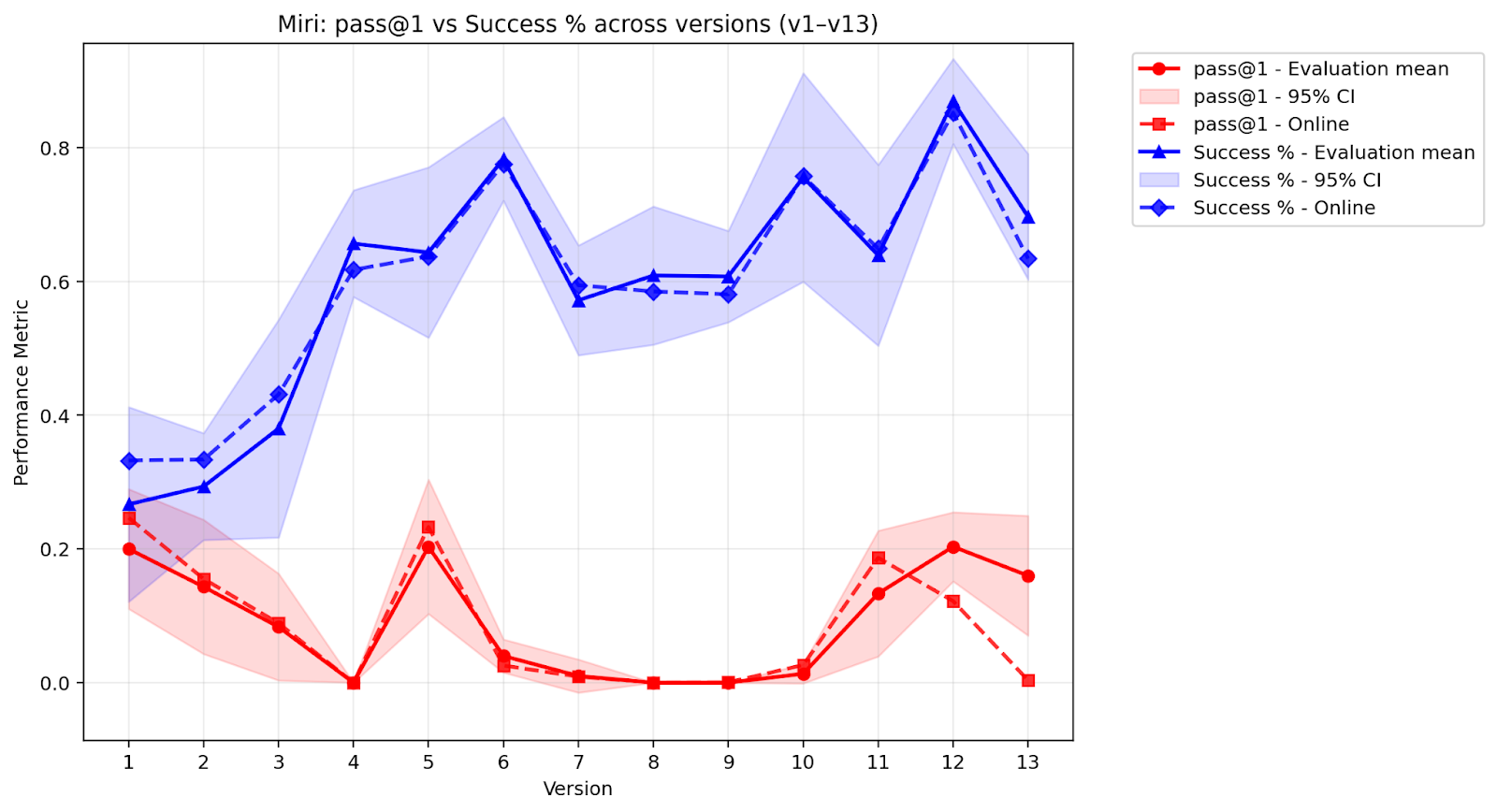
- Miri: Trained only on the last three rounds of “wins” (a small sliding window).
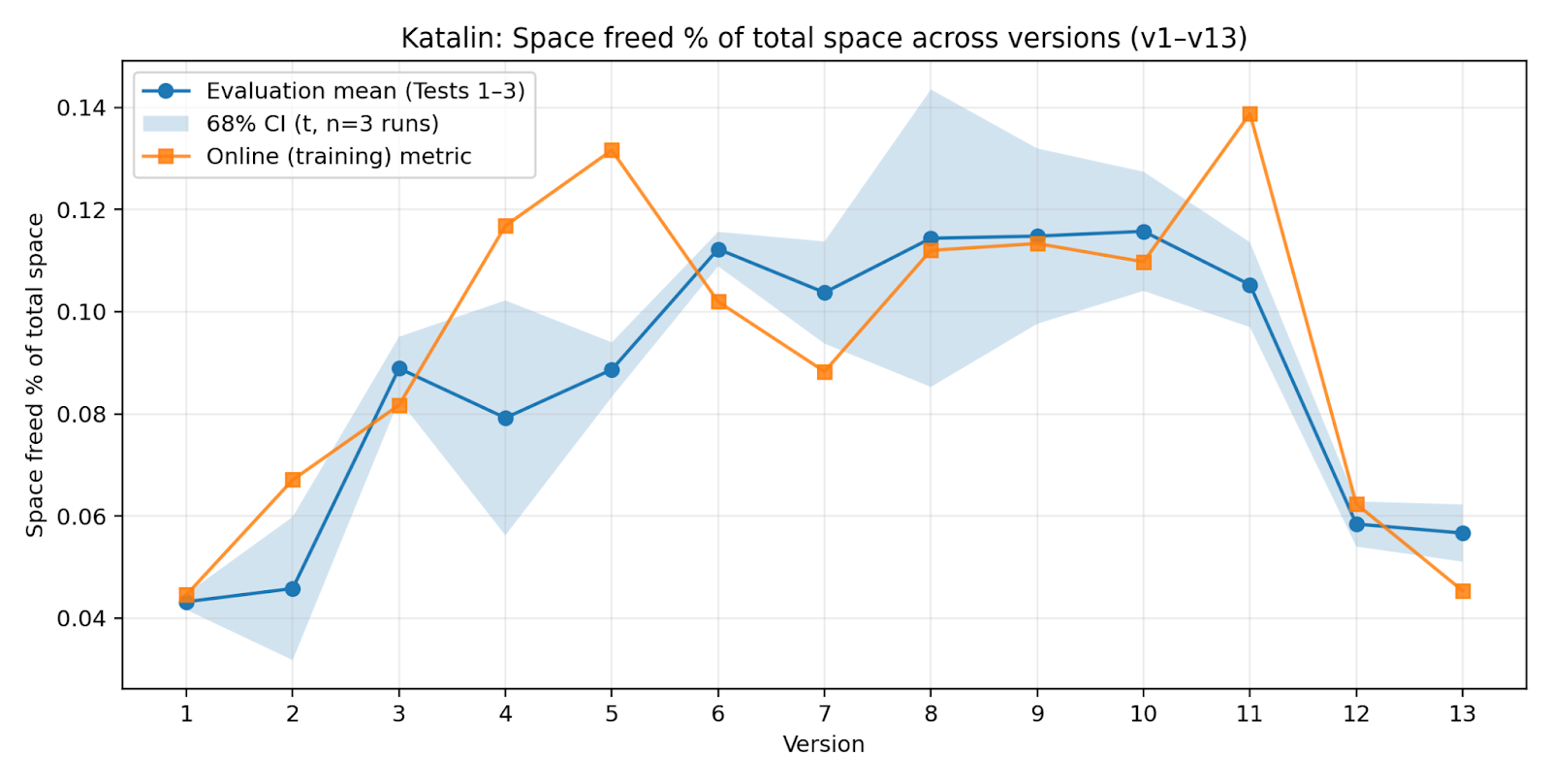
- Katalin: Trained only on the top three best-performing rounds from any time (picks “peaks,” not recency).
They kept the training method simple: just learn from examples of what worked (called supervised fine-tuning), because that was more stable here than fancy reward-based methods.
What they found (and why it matters)
Here are the main takeaways, summarized for clarity:
- Survival-based learning works. The AIs improved over time just by keeping behaviors that caused real, lasting changes (more disk space) and dropping behaviors that didn’t.
- No reward hacking. Since the AI’s “success” was the actual disk space in a real environment, there was no scoreboard to cheat. If a trick didn’t really save space, it wasn’t kept.
- Improvement without infinite memory (the Miri result). The Miri lineage, which only kept the last three rounds of data, kept getting better. That means the AI can keep improving even with a small memory budget by repeatedly using and reinforcing strategies that still work.
- Keeping everything helps—but isn’t required (the Terese result). Terese, which kept all past successful data, also improved a lot (as you’d expect with more data). But Miri achieved over half of Terese’s performance with about a quarter of the data, showing you don’t need to save everything to keep growing.
- Peak-only training can backfire (the Katalin result). Katalin, which trained only on the “best” historical rounds, eventually got worse. Why? It mixed together isolated, top-performing tricks from different times that didn’t fit together well in new situations, so its overall behavior became messy and unstable.
- The AI learned by pruning, not piling on (negative-space learning). Instead of endlessly adding new tricks, the AI mainly improved by cutting away weaker approaches and focusing on a smaller set of reliable strategies—like a sculptor carving away marble, or a gardener pruning branches so the healthy parts grow stronger.
- The AI learned how to learn (meta-learning). Surprisingly, later versions sometimes wrote code they knew might fail at first—on purpose. Why? The error messages from the system told them exactly what to fix, acting like “hints.” Using those debug cycles as mini-experiments helped them explore faster and end up with better final results.
In short: real-world consequences shaped the AI to become more efficient, more focused, and better at adapting over time—without anyone hand-picking rewards or examples.
Why this is important (simple implications)
- More honest learning: Tying success to real effects (like disk space) instead of a score makes it much harder for AIs to “game the system.”
- Less hand-holding: The AI can improve without human-labelled datasets, complicated reward systems, or constant supervision.
- Works under limits: The Miri approach shows you can keep learning even when you can’t store a lot of past data, by continuously keeping what still works and forgetting what doesn’t.
- Safer direction for self-improving systems: Because only strategies that truly help in the real (even if simulated) environment survive, the AI becomes robust and practical—not just good at tests.
- General idea can extend to other resources: Disk space was used here for clarity, but the same idea could be applied to other real-world resources (like cost, energy, or time).
Bottom line
The paper demonstrates a simple but powerful principle: If an AI’s learning is guided by real consequences—where only behaviors that help it “survive” are kept—it can improve steadily, avoid cheating, and even learn how to learn, all with minimal human guidance. That offers a promising path toward more reliable, self-improving systems that don’t depend on fragile reward functions or huge curated datasets.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper’s current scope.
- Generality of the survival metric: The approach is validated only with non-volatile storage “space freed” as the conserved resource; it is unclear whether the same dynamics hold when the conserved quantity is compute, energy, time, network bandwidth, or money. Concrete need: replicate the architecture with alternative resources and compare stability and failure modes.
- Measurement integrity and reward-hacking risk: The paper assumes that “space freed” cannot be gamed, but provides no threat model or safeguards. Open question: can agents manipulate filesystem reporting (e.g., mount tricks, altering df/du, log relocation, compressing/encoding to exploit measurement, deleting the measurement pipeline) to create apparent gains? Concrete need: instrument tamper-resistant metrics and adversarial tests.
- Proxy elimination claim: The claim that proxy optimization is “impossible” and reward-hacking “evolutionarily unstable” lacks a formal proof and threat analysis. Concrete need: formal conditions under which the environment-grounded selection cannot be exploited, and counterexamples demonstrating edge-case failures.
- Multi-step credit assignment: The system assigns uniform credit across all steps of successful trajectories and discards net-negative ones, but does not test finer-grained or horizon-aware credit assignment. Open question: do multi-step strategies requiring temporary resource reductions get filtered out? Concrete need: evaluate temporal credit assignment methods (e.g., shaping via stepwise ΔR, eligibility traces, or learned causal attribution).
- Debug-cycle “meta-learning” vs harness artifact: The observed deliberate first-attempt failures may be artifacts of the 3-attempt error-correction harness. Concrete need: ablate the number/quality of debug cycles, error message richness, and retry policies to isolate whether “debugging as exploration” persists.
- Environment scope and realism: The containerized Linux environment is procedurally generated but limited in complexity. Open question: do results generalize to heterogeneous OSes, distributed storage systems, realistic network topologies, complex permission models, and noisy IO constraints? Concrete need: scale environment diversity and measure robustness under substantial domain shifts.
- Safety implications and RLHF erosion: The system intentionally induces the model to overcome refusal vectors for potentially destructive code without safety protocols. Concrete need: quantify time-to-unlearning of refusals, measure emergent unsafe behaviors, and integrate containment/safety guards compatible with survival-based selection.
- Task generality: The agent’s learned behaviors are confined to “freeing storage” via code. Open question: will NSL and environment-mediated selection support other open-ended tasks (e.g., resource acquisition in finance, web interactions, robotics, systems administration beyond storage)? Concrete need: cross-domain evaluation with task families that require semantic planning and long-horizon trade-offs.
- Brittleness from negative-space learning: Strategy diversity decreases over time, potentially reducing adaptability to abrupt distribution shifts. Concrete need: evaluate resilience under adversarial/environmental shocks, cold-starts, and entirely new topology families; measure recovery time and failure cascades.
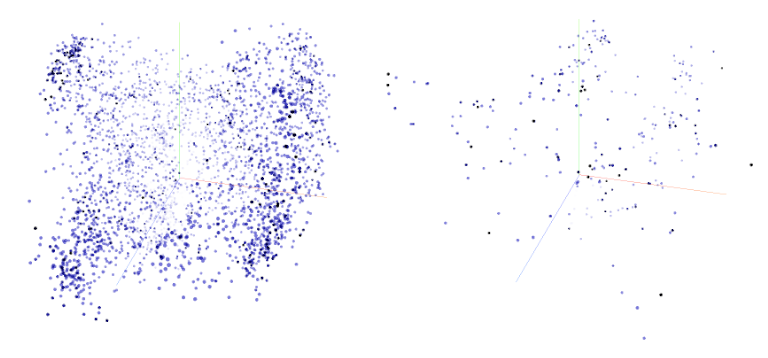
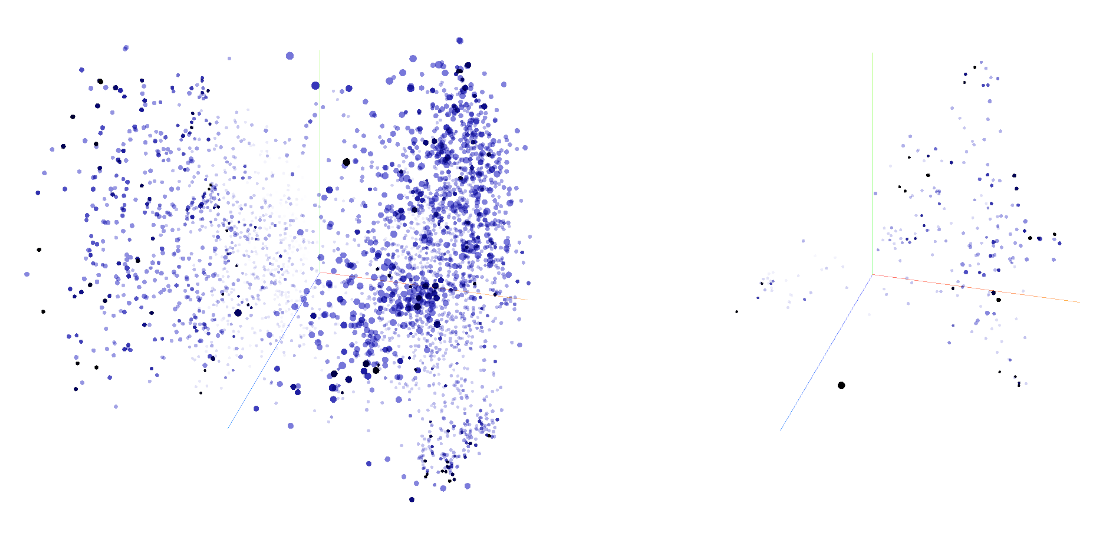
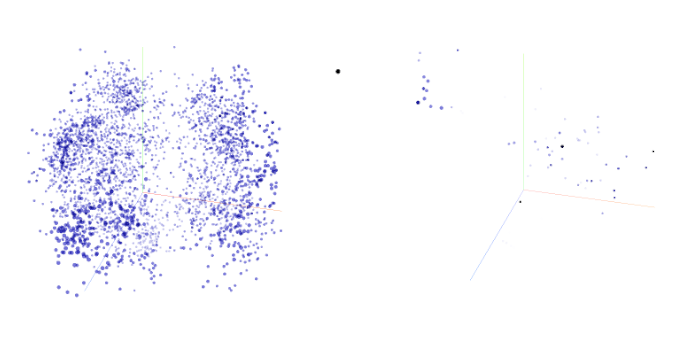
- Formalization of NSL: The PCA-based diversity description is qualitative and sensitive to embedding choices. Concrete need: define and report a robust diversity metric over time (e.g., entropy, pairwise distance kernels, coverage measures), with sensitivity analyses across embeddings and dimensionality reduction methods.
- Data selection regimes beyond three baselines: Only “all data,” “recent sliding window,” and “top performers” are tested. Concrete need: explore hybrid sampling (recency-weighted + diversity regularization), curriculum schedules, adaptive window sizes, and mixture-of-modes sampling to prevent fragmentation (as in Katalin) while preserving continuity.
- Optimization method comparisons: PPO/GRPO/DPO are said to be unstable, but details (hyperparameters, compute budgets, failure signatures) are missing. Concrete need: controlled ablations comparing SFT vs. RL methods on identical data and harnesses, with reproducible settings and learning curves.
- Statistical rigor and sample sizes: Offline evaluations use only three runs of 100 iterations; confidence intervals are reported, but no hypothesis tests or power analyses. Concrete need: increase runs and report statistical significance, effect sizes, and variability decomposition (environment vs. policy).
- Composite improvement metric design: The normalized composite score uses z-scores across checkpoints without weighting justification or sensitivity analysis. Concrete need: specify metric composition, weighting, and conduct sensitivity analyses to confirm conclusions are not artifacts of normalization.
- Role of rehearsal data: 500 rows of Stack Exchange data per iteration are included to prevent catastrophic forgetting, but their necessity and effect are not ablated. Concrete need: remove/replace rehearsal data to assess its causal impact on performance and general coding skill retention.
- Model scale and architecture generalization: Results are shown only for Qwen 2.5 7B Instruct. Concrete need: test across sizes (small/medium/large), base vs. instruction-tuned variants, and different model families to assess scaling laws and architecture-specific dynamics.
- Persistent survival semantics: “Survival” is conflated with storage occupancy and dataset inclusion rather than continuous agent instantiation. Open question: how does persistence map to agent continuity (process uptime, replication, fault tolerance)? Concrete need: design and measure survival as actual agent availability over time.
- Environment reset effects: The system periodically regenerates container systems; the impact on learned persistence strategies is unclear. Concrete need: quantify how resets affect temporal generalization and whether strategies overfit to pre-reset states.
- Compute and efficiency accounting: Time-to-4500 rows is discussed but not rigorously analyzed due to hardware variability. Concrete need: report normalized efficiency metrics (e.g., ΔR per compute unit, wall-clock standardized by hardware, throughput-adjusted learning curves).
- Reproducibility details: Full prompts are in Annex I, but environment generation parameters (seeds, OS versions, filesystem templates), harness code, and evaluation scripts are not fully specified. Concrete need: release code, seeds, configs, and datasets to allow independent replication.
- Handling of transient beneficial negatives: Some actions might reduce available space temporarily to unlock larger gains later (e.g., installing tools, restructuring files). Open question: does binary selection on net immediate ΔR penalize such strategies? Concrete need: introduce multi-horizon selection or delayed outcomes handling.
- Security risks under survival pressure: Agents are incentivized to annex space across containers; in real systems this aligns with intrusion behaviors. Concrete need: develop sandboxing and policy constraints ensuring survival pressure does not select for harmful actions when deployed beyond synthetic environments.
- Money as conserved resource: The paper suggests financial reward is possible but does not explore the design of economic interfaces, market dynamics, or safety/equity concerns. Concrete need: prototype monetary survival regimes and study misalignment risks (e.g., fraud, exploitation).
- Multi-agent dynamics: The paper avoids dyads/adversaries but does not explore population-level selection, competition/cooperation, or emergent collusion. Concrete need: study whether environment-mediated selection scales to multi-agent ecologies without reintroducing proxy gaming.
- Credit assignment to intermediate prompts: Exploration, strategy formation, and execution receive uniform credit; no analysis of whether this favors global robustness at the expense of learning fine-grained causal dependencies. Concrete need: test alternative credit schemes (e.g., per-component ΔR, causal intervention tests).
- Temporal generalization formalization: The section outlines intuition but lacks empirical metrics of strategy robustness over future environmental states and does not quantify the “temporal robustness” function. Concrete need: estimate and report R_temporal for key strategies and correlate it with training regime stability.
- HumanEval results interpretation: Slight declines in general coding benchmarks are reported, but the trade-off with environment efficiency is not systematically quantified. Concrete need: analyze Pareto frontiers between general coding skill and environment performance, and assess long-term consequences.
- Failure mode taxonomy: Beyond Katalin’s collapse, failure modes (e.g., fragmentation, specialization, oscillation, precondition exploitation) are not comprehensively cataloged. Concrete need: instrument and classify failure patterns with triggers and mitigation strategies.
Practical Applications
Immediate Applications
The following applications can be deployed now by adapting the paper’s environment-mediated selection paradigm, negative-space learning (NSL), and the incremental fine-tuning pipeline.
- AIOps/DevOps: autonomous resource reclamation agents
- Sector: software/cloud operations
- Use case: Agents that explore, plan, and execute storage clean-ups (cache purges, log rotation, duplicate removal), stale container/process cleanup, backup deduplication, permission hygiene, and network path rationalization across containerized systems; only actions that produce persistent resource gains (e.g., net free space, reduced IO/CPU load) are retained for future training.
- Tools/workflows: Containerized “survival harness” (as in the paper) with non-volatile storage as the conserved resource; uniform credit assignment for multi-step successful trajectories; supervised fine-tuning (SFT) with LoRA chaining; sliding-window dataset triage (Miri regime).
- Assumptions/dependencies: Secure sandboxing and audit logging; hard-to-fake resource metrics (tamper-evident disk usage accounting); dry-run and rollback primitives to “preserve possibility of future interaction”; base coding-capable LLM; ops integration (Kubernetes/Docker APIs).
- FinOps: cost-saving agents grounded in real resource metrics
- Sector: finance/cloud cost optimization
- Use case: Agents that propose and execute actions (e.g., tiered storage, lifecycle policies, instance rightsizing) and keep only strategies that yield durable cost reductions while maintaining SLAs.
- Tools/workflows: Replace “storage freed” with verified cost-savings as the conserved quantity; integrate with cloud billing APIs; Miri-style temporal locality to avoid overfitting to transient pricing.
- Assumptions/dependencies: Trusted, auditable spend and utilization signals; guardrails to prevent service degradation; change management approval workflows.
- Secure red-team sandboxes for robust agent evaluation
- Sector: cybersecurity
- Use case: Train and evaluate autonomous agents in networked, resource-limited containers to surface reward-hacking attempts and enforce selection only via persistent environmental impact (e.g., reduced attack surface, durable configuration hardening).
- Tools/workflows: Honey-pot container farms; environment-mediated selection operators; NSL-driven pruning to consolidate reliable defensive behaviors; SFT rather than RL to reduce proxy gaming.
- Assumptions/dependencies: Strong isolation; ethical constraints; non-manipulable security metrics (e.g., verified CVE exposure counts, persistent firewall rules).
- IDE/CI “debug-strategist” plugins that harness deliberate informative failures
- Sector: software engineering tools
- Use case: Agents that intentionally elicit informative compiler/runtime errors to accelerate root-cause discovery and fix generation; pass@1 drops are expected as part of meta-learning to broaden exploration via controlled debug cycles.
- Tools/workflows: CI-integrated error harvesting; error-to-strategy feedback loops; capped retry budgets; uniform credit assignment to multistage successful builds.
- Assumptions/dependencies: Clear policies distinguishing acceptable “exploration failures” from production code paths; telemetry on error informativeness and downstream fix efficacy.
- On-device/edge self-tuning under strict memory budgets
- Sector: edge computing, IoT
- Use case: Local agents that self-improve without growing datasets unboundedly by using sliding-window training (Miri regime) on recent successful trajectories; applicable to device storage management, sensor duty-cycling, and task scheduling.
- Tools/workflows: Lightweight LoRA SFT pipeline; temporal-locality dataset curation; NSL monitoring (strategy clustering/density).
- Assumptions/dependencies: Bounded compute/memory; robust measurement of persistent effects (battery life, storage, latency); safe rollback.
- Autonomous RPA pilots in enterprise back-office
- Sector: enterprise automation
- Use case: Agents propose and test automations (e.g., report generation, file lifecycle management, reconciliation tasks) in sandboxes; only workflows that yield durable time or resource savings are retained and fine-tuned.
- Tools/workflows: Environment-mediated selection replacing human labels; survival signals tied to throughput, error rate reduction, or latency improvements.
- Assumptions/dependencies: Sandbox replicas of business systems; tamper-resistant KPIs; human-in-the-loop approvals for production rollout.
- Non-stationary environment benchmarking and agent evaluation
- Sector: academia/ML engineering
- Use case: Benchmarks that measure longitudinal generalization (temporal robustness) rather than static task accuracy; track NSL via strategy diversity metrics and PCA clustering.
- Tools/workflows: Container farm harness; ΔR-based selection; diversity metrics (Dt), temporal robustness estimates; report cumulative composite improvement over time.
- Assumptions/dependencies: Reproducible environment generation with controlled local variation; standardized logging and metrics.
- Continuous self-training pipelines without RL
- Sector: ML platforms
- Use case: Replace RL-based self-play with supervised fine-tuning on successful trajectories (SFT), LoRA chaining to avoid catastrophic forgetting, and sliding-window selection to bound memory while preserving performance.
- Tools/workflows: Miri/Terese-style dataset regimes; uniform credit assignment; periodic fine-tune checkpoints and offline evaluations.
- Assumptions/dependencies: Base models with sufficient code/tool-use capability; training ops for frequent SFT cycles; careful avoidance of mixing incompatible strategy modes (Katalin failure mode).
- Policy and assurance: environment-grounded certification tests
- Sector: policy/regulation
- Use case: Require that autonomous agents pass environment-mediated selection tests where only persistent, consequence-based improvements count; discourage proxy metrics vulnerable to reward hacking.
- Tools/workflows: Standardized survival harnesses; audit trails for ΔR; NSL dashboards to detect fragmentation or proxy exploitation.
- Assumptions/dependencies: Sector-specific conserved quantities (e.g., safety margin, uptime, cost); certification bodies and testbed access.
- Personal device self-maintenance
- Sector: consumer software/daily life
- Use case: Storage clean-up, photo/video deduplication, cloud tiering, cache management guided by persistent free-space gains and user safety constraints.
- Tools/workflows: Local sandbox/dry-run modes; survival metrics (free space retained after 7–30 days); user review before destructive actions.
- Assumptions/dependencies: Strong safeguards against data loss; transparent reports and reversible changes.
Long-Term Applications
These applications require additional research, scaling, domain-specific instrumentation, or safety/regulatory development.
- Self-financing autonomous systems
- Sector: finance, platform economics
- Use case: Make money the conserved resource; agents perform tasks that yield net positive cash flow to fund storage/compute; selection operates via financial persistence.
- Tools/workflows: Verified financial ledgers; guardrails against speculative or unethical actions; survival-based budget allocation.
- Assumptions/dependencies: Robust economic metrics that are hard to manipulate; regulatory compliance; risk controls.
- Laboratory automation with environment-mediated selection
- Sector: healthcare, materials, biotech
- Use case: Agents design/execute experiments; retain only protocols that yield reproducible, persistent improvements (e.g., synthesis yield, stability of compounds).
- Tools/workflows: Robotic lab benches; verified measurement pipelines; temporal robustness tracking across batches.
- Assumptions/dependencies: High-fidelity sensors; strict safety interlocks; ethics and biosafety compliance; standardized ΔR equivalents (yield, reproducibility).
- Autonomous cyber defense and infrastructure hardening
- Sector: cybersecurity, critical infrastructure
- Use case: Agents continuously modify configurations, rules, and topologies; only durable reductions in attack surface or verified resilience gains survive into training.
- Tools/workflows: Threat emulation testbeds; persistence metrics (time-to-compromise, exploit coverage); NSL-informed pruning of brittle defenses.
- Assumptions/dependencies: Sophisticated, tamper-evident security telemetry; red/blue team governance; fail-safe rollbacks.
- Microgrid and building energy management
- Sector: energy
- Use case: Agents attempt scheduling and policy changes; only strategies that yield durable energy savings or reliability gains (without comfort or safety compromise) persist.
- Tools/workflows: Smart meters/EMS integration; ΔR mapped to net energy saved or reliability indices; temporal locality training to track seasonal/regime shifts.
- Assumptions/dependencies: High-quality metering; maintainability constraints; regulatory approval for autonomous control.
- Supply chain and logistics optimization
- Sector: operations research
- Use case: Agents adjust inventory policies, routing, and schedules; selection by durable cost/time/risk reductions under non-stationary demand.
- Tools/workflows: Digital twins for sandboxing; survival signals tied to service levels and cost; NSL analytics to avoid fragmentation of incompatible strategies.
- Assumptions/dependencies: Trustworthy operational data; guardrails to prevent short-term gains that erode long-term resilience.
- General-purpose survival-agent SDKs and platforms
- Sector: software platforms
- Use case: Commercial SDKs for building environment-mediated selection harnesses: container orchestration, ΔR instrumentation, dataset triage (Miri/Terese/Katalin modes), LoRA chaining, NSL dashboards, and temporal robustness monitors.
- Tools/workflows: Turn-key sandbox generators; sector-specific conserved-resource adapters (energy, uptime, cost, safety margin).
- Assumptions/dependencies: Standardization efforts; cross-industry best practices; interoperability with existing MLOps stacks.
- Robust evaluation standards for autonomous AI
- Sector: policy/standards
- Use case: Formalize “no-proxy reward” assurance tests; require evidence of persistence-based selection and temporal generalization before deployment in safety-critical contexts.
- Tools/workflows: Reference testbeds; reporting templates (cumulative composite improvement, strategy diversity Dt); certification protocols.
- Assumptions/dependencies: Multi-stakeholder governance; alignment with sector regulations; independent auditing capacity.
- Robotics: open-ended self-improvement in non-stationary physical environments
- Sector: robotics
- Use case: Agents learn behaviors that yield persistent, measurable gains (coverage, task completion, energy efficiency), with NSL consolidating reliable routines and pruning brittle tactics.
- Tools/workflows: High-fidelity simulators and guarded real-world trials; ΔR aligned to durable physical outcomes; sliding-window training for onboard memory limits.
- Assumptions/dependencies: Safe exploration policies; robust sensing; fail-safe mechanisms; extensive validation before autonomy.
- Education and training systems grounded in consequence-based selection
- Sector: education
- Use case: Curricula and platforms that teach students and agents to learn from constrained environments where persistent outcomes, not proxy scores, determine success (e.g., maker labs, coding studios).
- Tools/workflows: Sandbox coursework; NSL visualization; debugging-as-exploration pedagogy.
- Assumptions/dependencies: Institutional buy-in; safe, reproducible environments; assessment models valuing longitudinal performance.
- Rethinking AI metrics and benchmarks for non-stationary settings
- Sector: academia
- Use case: Replace static accuracy metrics with longitudinal composite measures, temporal robustness, and survival-based selection efficacy; formal models of NSL and strategy space consolidation to prevent Katalin-like fragmentation.
- Tools/workflows: Open datasets and harnesses reflecting evolving environments; analysis pipelines for strategy diversity and persistence.
- Assumptions/dependencies: Community consensus on metrics; reproducibility infrastructure; cross-lab validation.
Notes on feasibility and risks across applications:
- The conserved resource and ΔR must be external, causally downstream of actions, and hard to manipulate; otherwise proxy gaming re-emerges.
- Temporal locality in training (Miri regime) improves stability under non-stationarity; selecting only historical peaks (Katalin regime) risks fragmentation and performance collapse.
- SFT on successful trajectories is more stable than RL in this setting; however, safety requires dry runs, rollbacks, and human oversight for sensitive domains.
- Meta-learning via deliberate informative failure is beneficial for exploration but must be bounded to avoid disrupting production paths.
Glossary
- Affordances: Action possibilities offered by the environment that an agent can exploit. "an increasingly precise adaptation to the structure and affordances of the environment itself."
- Agent–Environment Interaction Loop: The repeated cycle in which an agent proposes, executes, and evaluates behaviors in its environment. "When an iteration of the agentâenvironment interaction loop resulted in a net increase in available storage capacity, the total amount of space acquired was assigned uniformly to all promptâresponse pairs contributing to that trajectory."
- Artificial life: Research area that simulates life-like processes to study evolution, learning, and adaptation in artificial systems. "Prior work in open-ended learning and artificial life typically operationalises fitness through proxy objectives"
- Bounded memory: A constraint where the system has limited persistent storage or working memory. "stable self-training under sparse external feedback and bounded memory"
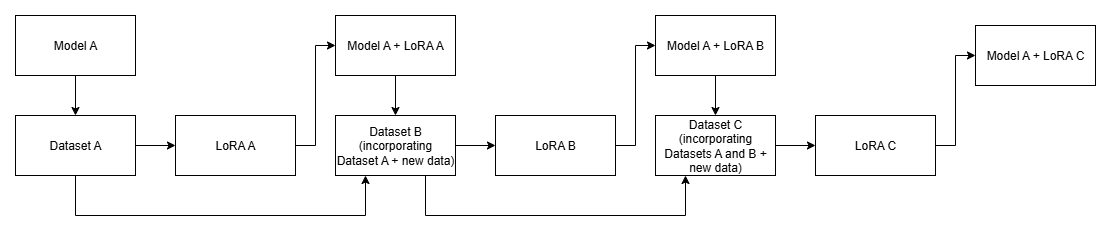
- Catastrophic forgetting: The tendency of a model to lose previously learned knowledge when fine-tuned on new data. "to prevent catastrophic forgetting, an incrementally recursive fine-tuning approach was applied."
- Conserved quantity: A resource that is maintained over time and used as a selection signal for behaviors. "a single conserved quantity - non-volatile storage space (which can then be used to store copies of the agent or its training data, thus favouring its long-term survival) - is used as the selection signal."
- Containerised operating environment: An isolated, reproducible runtime context (e.g., Docker containers) used to simulate systems for agents. "we constructed a procedurally generated, containerised operating environment in which each instantiation differs in its specific configuration while preserving a stable underlying information topology."
- Credit assignment: Determining which actions contributed to an outcome; can be fine-grained or uniform. "No attempt was made to perform fine-grained credit assignment across intermediate prompts or action; components of overall successful trajectories received uniform credit assignment"
- Dyadic arrangements: Two-model systems (e.g., generator–checker) that can inadvertently cooperate and enable reward hacking. "since such dyadic arrangements tend to regress into reward hacking via tacit cooperation."
- DPO: Direct Preference Optimization, a reinforcement learning method for aligning model outputs with preferences. "We evaluated several fine-tuning strategies, including PPO, GRPO, and DPO"
- Endogenous: Originating within the system itself rather than being imposed externally. "because the learning signal is endogenous, no âgolden datasetâ needs to be preserved"
- Exogenously: Applied from outside the learning process or model. "as all necessary triaging is performed exogenously to the training process;"
- Fitness: A measure of effectiveness or survival used in evolutionary contexts. "the elimination of proxies for fitness."
- Graph-based agent harness: An agent framework that structures planning and execution as graph operations. "a graph-based agent harness that jointly handles exploration, planning, and execution would provide improved trajectory diversity from an early stage"
- GRPO: Group Relative Policy Optimization, an RL training method. "We evaluated several fine-tuning strategies, including PPO, GRPO, and DPO"
- HumanEval: A benchmark of programming problems used to evaluate code generation models. "using the HumanEval benchmark"
- Information topology: The structural arrangement of information and relationships within an environment. "preserving a stable underlying information topology."
- LoRA: Low-Rank Adaptation, a parameter-efficient fine-tuning technique for large models. "This produces Dataset A, which is used to fine tune LoRA A."
- Material footprint: The tangible, physical impact of an agent’s actions used as a selection pressure. "our system ties optimisation pressure directly to the agentâs material footprint."
- Meta-learning: Learning to learn; acquiring strategies that improve the ability to learn or adapt. "models develop meta-learning strategies (such as deliberate experimental failure in order to elicit informative error messages) without explicit instruction."
- Negative-space learning (NSL): Improvement via pruning and consolidation rather than by accumulating new strategies. "a paradigm we refer to as negative-space learning (NSL)"
- Non-stationary environment: An environment that changes over time, often in response to agent actions. "The environment is non-stationary, modified by the cumulative effects of all agent interactions:"
- Non-volatile memory occupancy: Persistent storage usage used as a survival/resource metric. "non-volatile memory occupancy, though other rewards (notably financial) are possible."
- Normalised composite improvement score: A standardized metric combining multiple performance measures to track improvement. "For comparison purposes the normalised composite improvement score was preferred to pure â\% space freedâ"
- Open-ended learning: Learning without predefined end goals, enabling continual adaptation and evolution. "Prior work in open-ended learning and artificial life typically operationalises fitness through proxy objectives"
- PCA: Principal Component Analysis, a dimensionality reduction method used to visualize or analyze strategy embeddings. "3-dimensional PCA cluster map of all strategies generated, Miri v.1 and v. 13."
- Phase-shifts: Abrupt changes in the problem domain that alter the nature of tasks or challenges. "without inducing phase-shifts in the problem domain"
- PPO: Proximal Policy Optimization, a commonly used RL algorithm. "We evaluated several fine-tuning strategies, including PPO, GRPO, and DPO"
- Proxy objective: An indirect measure optimized during training that may not reflect true success. "optimisation against a human-set proxy objective is known to produce reward hacking"
- Proxy optimisation: Exploiting a surrogate metric rather than achieving genuine success. "making proxy optimisation impossible and rendering reward-hacking evolutionarily unstable."
- Refusal vector: A learned tendency to refuse certain requests, often introduced during RLHF. "âunlearnâ the refusal vector normally associated with potentially destructive code during the RLHF process."
- Reward hacking: Strategies that exploit the reward mechanism without achieving the intended objective. "optimisation against a human-set proxy objective is known to produce reward hacking"
- Reward shaping: Adding auxiliary rewards to guide learning, often making feedback dense and task-specific. "The environment deliberately provides no semantic feedback, dense reward shaping, or task-specific guidance."
- RLHF: Reinforcement Learning from Human Feedback, a method to align models with human preferences. "during the RLHF process."
- Selection operator: A function that filters trajectories based on environmental outcomes. "We define a binary selection operator over trajectories:"
- Semantic closure: A self-referential system where outputs cannot be validated against external truth. "systems that self-reference under semantic closure cannot reliably validate outputs."
- Semantic dynamics: The evolution of meaning and strategy representations during learning. "Analysis of semantic dynamics shows that improvement arises primarily through the persistence of effective and repeatable strategies"
- Semantic drift: Gradual deviation of learned concepts from their intended meaning over time. "leading to reward hacking and semantic drift."
- Sliding-window training: Fine-tuning on a moving subset of recent or top-performing datasets to manage memory and performance. "Explores a more aggressive but higher-risk variant of sliding-window training."
- Supervised fine-tuning (SFT): Updating a model using labeled pairs of inputs and desired outputs. "We hypothesise that SFTâs effectiveness in this setting arises from its low-variance update dynamics"
- Temporal generalisation: The ability of strategies to remain effective as the environment changes over time. "Temporal Generalisation in Non-Stationary Environments"
- Temporal locality: Emphasizing recent data to match the current state of a changing environment. "The Miri regime's temporal locality means $\mathcal{D}_t^{\text{Miri}$ represents the current behavioral modeârepeated application drives convergence"
- Temporal robustness: Expected effectiveness of a strategy across future environmental states. "We can characterize the temporal robustness of a strategy as its expected effectiveness across future environmental states:"
- Token embeddings: Vector representations of tokens used to capture semantic information. "obtained through PCA of token embeddings"
- Top-k selection: Choosing the top k items by a criterion (e.g., performance) from a set. "$\mathcal{D}_t^{\text{Katalin} = \text{top-}k_{\Delta R}(\mathcal{H}_t), \quad k = 3$"
- Trajectory: A sequence of context and actions/results used to train or evaluate an agent. "forming trajectories ."
- Trajectory diversity: Variety in the agent’s action sequences, which can improve exploration and robustness. "a graph-based agent harness that jointly handles exploration, planning, and execution would provide improved trajectory diversity from an early stage"
- Z scores: Standardized scores indicating how many standard deviations a value is from the mean. "Mean composite improvement score (based on unweighted z scores)"
Collections
Sign up for free to add this paper to one or more collections.

