- The paper introduces BRIDGE, a cooperative framework that integrates SFT and RL through bilevel optimization.
- It employs a penalty-based relaxation method for gradient updates, enhancing training efficiency and performance.
- Experimental results show significant gains in convergence speed and accuracy on mathematical reasoning benchmarks across multiple LLMs.
Beyond Two-Stage Training: Cooperative SFT and RL for LLM Reasoning
Introduction
The paper "Beyond Two-Stage Training: Cooperative SFT and RL for LLM Reasoning" introduces BRIDGE, a novel training framework that integrates supervised fine-tuning (SFT) and reinforcement learning (RL) within a single cooperative scheme. Traditional two-stage training, where SFT precedes RL, suffers from catastrophic forgetting and inefficient exploration during RL. BRIDGE addresses these drawbacks through bilevel optimization, with the SFT objective conditioned on the optimal RL policy. This synergy facilitates faster training and improved performance by leveraging the strengths of both paradigms effectively.
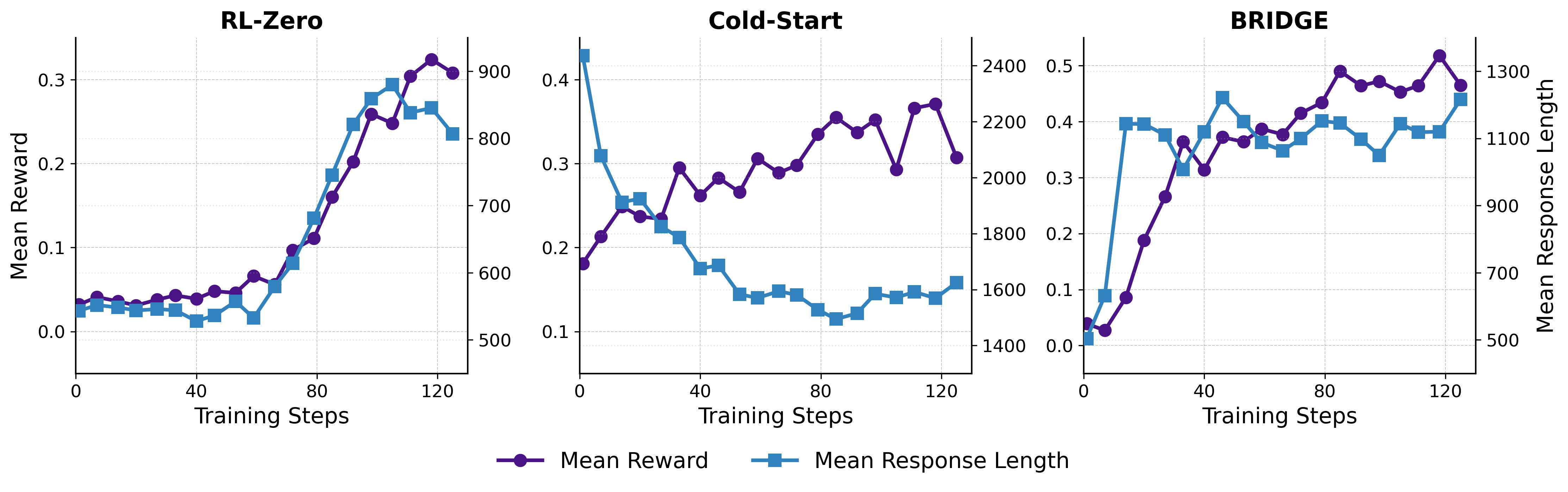
Figure 1: Training dynamics of mean reward and response length on Qwen2.5-3B.
Methodology
Bilevel Optimization Framework
BRIDGE constructs a bilevel optimization problem where the upper-level problem involves maximizing the SFT objective conditioned on the lower-level RL policy optimization. Formally, the upper-level SFT seeks to maximize:
JSFT(θ∗(w),w):=E(x,r,y)∼DSFT[logπ(r,y∣x;θ∗(w),w)],
subject to the lower-level problem:
θ∗(w):=argθmaxJRL(θ,w).
This framework tightly couples the RL and SFT processes, enhancing cooperation and mutual optimization.
Algorithm Implementation
BRIDGE employs a penalty-based relaxation method to solve the bilevel formulation efficiently. The updates for the base model parameters (θ) and the LoRA weights (w) are computed via gradient ascent, respectively blending SFT and RL objectives and maximizing cooperative gain:
- Base Model Update:
θk+1=θk+α[(1−λ)∇θJSFT(θ,w)+λ∇θJRL(θ,w)]
- LoRA Parameters Update:
wk+1←wk+β∇wJGain(wk)
Architectural Design
The architecture incorporates LoRA to separate optimizing the model's base parameters from its adaptation layers. This setup ensures that the upper and lower objectives co-evolve, maintaining cooperation during training. The separation allows targeted guidance derived from SFT updates to direct RL optimization effectively.
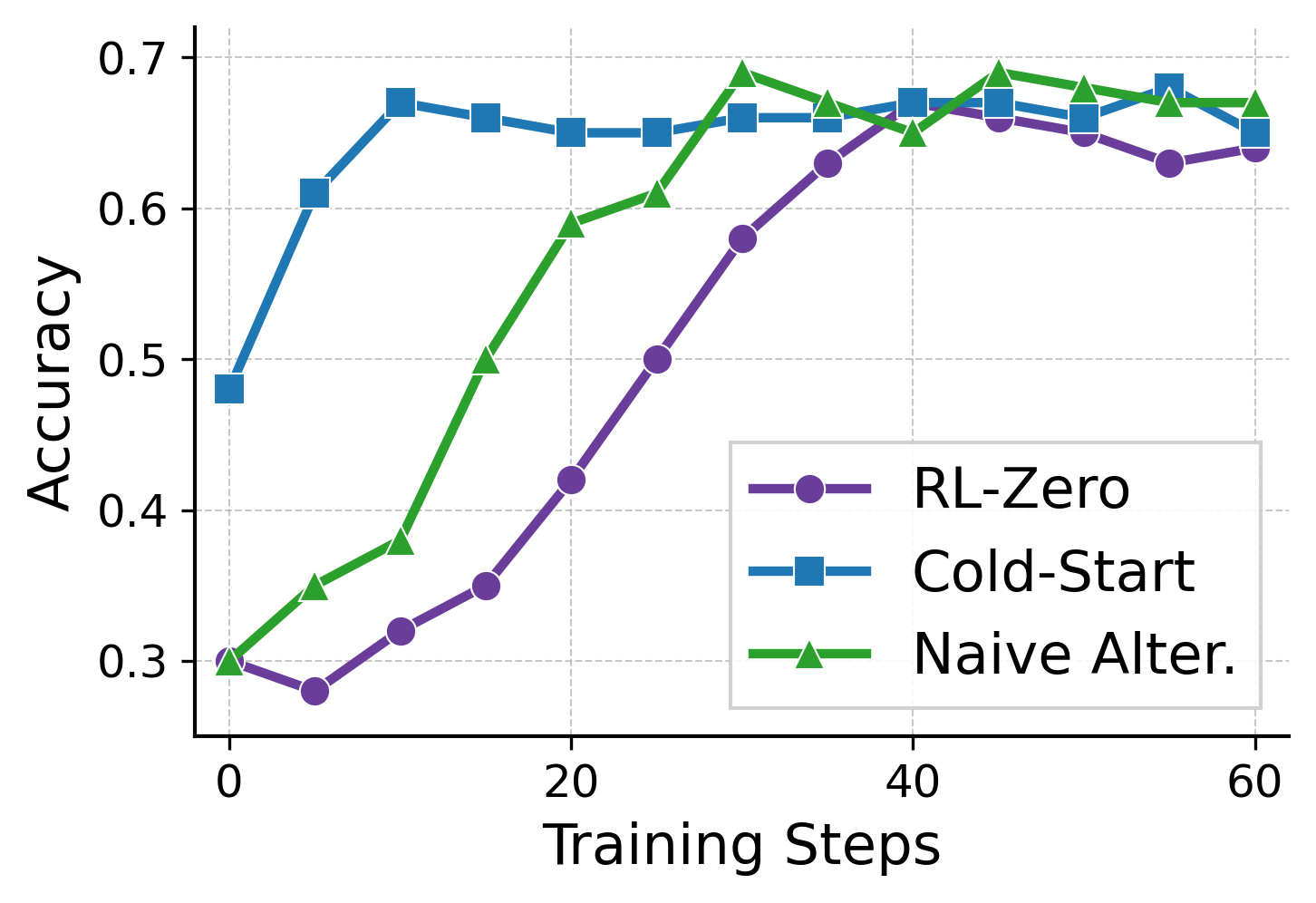
Figure 2: Comparison of Training Methods.
Experimental Evaluation
Dataset and Model Settings
Experiments utilize three LLMs—Qwen2.5-3B, Llama-3.2-3B-Instruct, and Qwen3-8B—trained on mathematical reasoning datasets LIMR and MATH. The assessment includes various mathematical reasoning benchmarks, ensuring robustness across different contexts and complexities.
Results
BRIDGE consistently outperformed baseline methods such as Cold-start, RL-zero, and naive alternating strategies. The method exhibited faster training convergence and higher final accuracy metrics, with significant empirical gains showcased across model scales and dataset complexities.
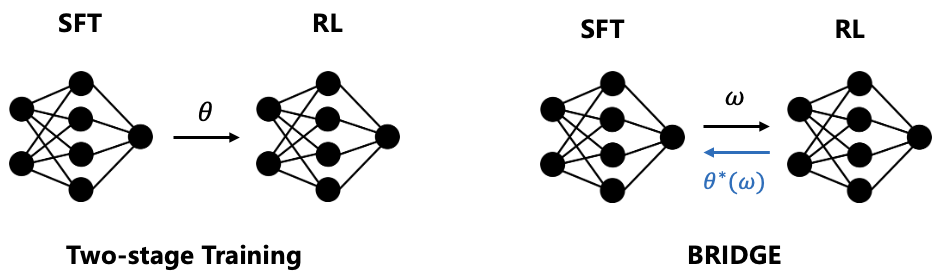
Figure 3: Comparison of two training methods.
Implications and Future Work
The framework sets a precedent for transcending traditional decoupled training pipelines by fostering tighter integration of SFT and RL processes. This cooperative approach could pave the way for enhanced reasoning capabilities in LLMs, improving efficiency and generalization. Future research may explore extending BRIDGE to other domains and tasks, assessing its adaptability and robustness.
Conclusion
The BRIDGE framework demonstrates a compelling approach to integrating SFT and RL through cooperative meta-learning, innovatively utilizing bilevel optimization. By harmonizing these training paradigms, BRIDGE showcases improved performance and efficiency, affirming its potential for advancing LLM reasoning capabilities.
References
A comprehensive list of references was used to support the methodologies and findings within this paper, focusing on advanced bilevel optimization techniques and recent developments in LLM training and reasoning enhancement strategies.

