- The paper demonstrates how integrating supervised fine-tuning with reinforcement learning empowers LLMs to self-verify and self-correct during inference.
- It shows significant accuracy gains, notably from 51.0% to 81.6% on the MATH500 benchmark using offline RL and rule-based rewards.
- The framework’s broad applicability extends to logical reasoning and strategy tasks, enhancing performance across diverse AI challenges.
S2R: Teaching LLMs to Self-verify and Self-correct via Reinforcement Learning
Introduction
The paper "S2R: Teaching LLMs to Self-verify and Self-correct via Reinforcement Learning" addresses a critical challenge in the domain of LLMs concerning their reasoning capabilities. While LLMs show promise in various tasks, enhancing their deep thinking abilities remains complex, particularly for smaller models or models that are less resource-intensive. The proposed framework, S2r, provides an efficient alternative to address this gap by focusing on self-verification and self-correction mechanisms incorporated during inference. It leverages a combination of supervised fine-tuning and reinforcement learning to achieve significant improvements in reasoning accuracy without extensive resources or data.
Methodology
Behavior Initialization
The methodology involves a two-stage training process. Initially, the behavior of LLMs is initialized through supervised fine-tuning (SFT) using a specifically curated dataset of 3.1k samples that teach the models self-verifying and self-correcting behaviors. This dataset is constructed via prompting and sampling from existing model responses, focusing on capturing diverse reasoning trajectories through both "problem-solving" and "confirmative" verification methods.
Reinforcement Learning
Subsequently, the reasoning capabilities are enhanced through reinforcement learning (RL). The RL strategy comprises both outcome-level and process-level RL, allowing models to focus on the correctness of both solutions and intermediate reasoning steps. The framework introduces offline RL as a scalable alternative to traditional online training, utilizing rule-based rewards and baseline estimations informed by accuracy bins.
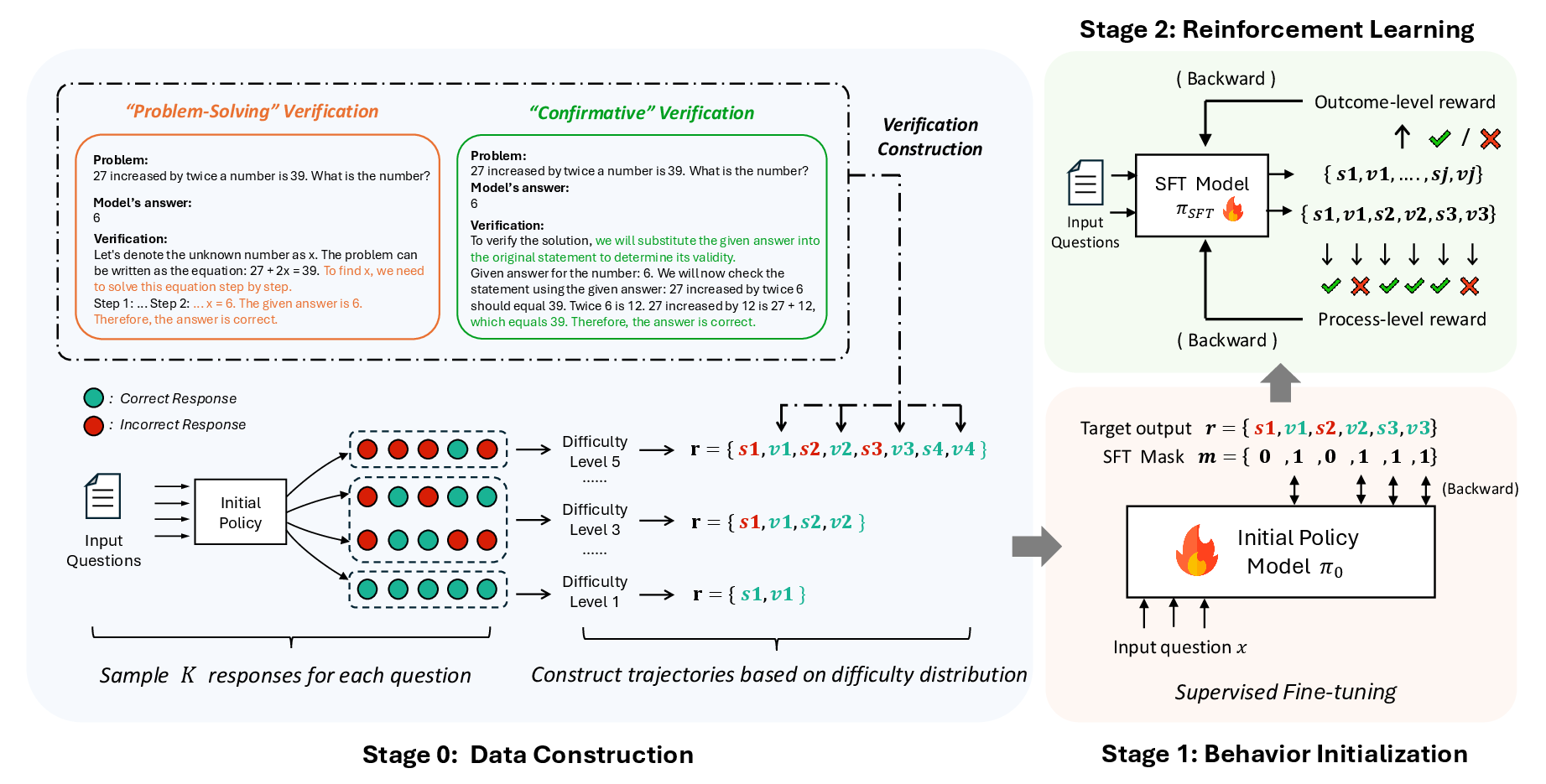
Figure 1: Overview of S2r.
Experiments and Results
The effectiveness of S2r was validated across seven mathematical benchmarks, demonstrating significant improvements over baseline LLMs, including models such as Llama-3.1-8B-Instruct, Qwen2-7B-Instruct, and Qwen2.5-Math-7B. Notably, the Qwen2.5-Math-7B model exhibited a substantial increase in accuracy from 51.0% to 81.6% on the MATH500 test set. These performance gains were achieved with optimized use of resources, showcasing S2r's efficiency.
A comparison was made between the S2r framework and alternative methods, such as long-CoT data distillations and competitive model baselines. S2r consistently delivered superior accuracy, particularly in complex reasoning tasks where test-time computation was effectively scaled.
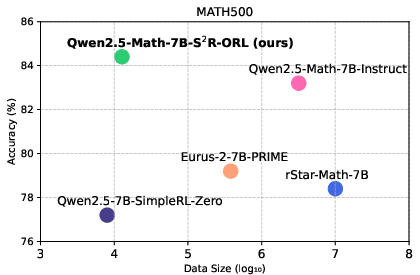
Figure 2: The data efficiency of S2r compared to competitive methods, with all models initialized from Qwen2.5-Math-7B.
Analysis of Self-Verification and Self-Correction
Analytical experiments highlighted the impact of verification methods on overall performance. The paper critiques "problem-solving" verification's bias during LLM reasoning processes, advocating for the more balanced "confirmative" verification approach despite its generally lower raw accuracy. Both RL methodologies were found to enhance the self-correction from incorrect to correct states significantly, while reducing the reverse, ensuring stable outputs in challenging scenarios.
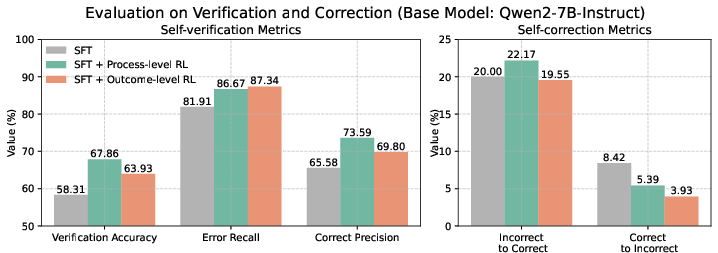
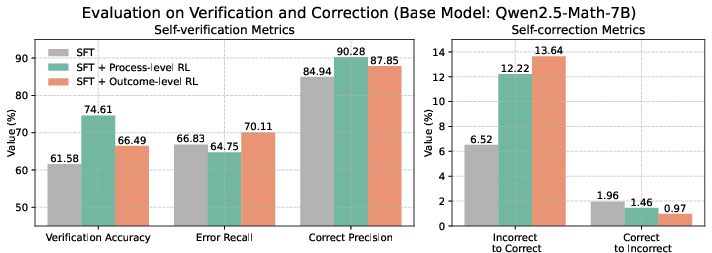
Figure 3: Evaluation on verification and correction.
Generalizability and Cross-domain Application
Beyond mathematical reasoning, experiments demonstrated the framework's applicability to cross-domain tasks such as logical reasoning and strategy question answering (StrategyQA). The generalizability of self-verifying and self-correcting paradigms suggests potential integrations into broader AI domains requiring intricate understanding and decision-making capabilities.

Figure 4: StrategyQA Case.
Conclusion
S2r stands as a robust framework enabling efficient enhancement of LLM reasoning through structured self-verification and self-correction mechanisms. Its scalable methodologies, including offline RL, provide a significant leap forward in making advanced reasoning accessible to smaller or less resource-intensive models. Future exploration may involve integrating this approach across diverse AI challenges, extending the benefits of deep reasoning to a broader set of applications.