- The paper presents RAT, which partitions sequences into fixed-size chunks to balance local recurrence with global retrieval.
- It achieves up to 10× throughput gains while maintaining attention-level accuracy on diverse long-context tasks.
- The design efficiently scales long-context inference, mitigating RNN memory degradation and full attention’s quadratic complexity.
RAT: A Chunk-based Sequence Model Bridging RNN Efficiency and Attention Accuracy
Introduction and Motivation
Transformer-based architectures have defined state-of-the-art performance across language modeling tasks, but their reliance on full-sequence softmax attention incurs quadratic time and memory complexities with respect to sequence length. This severely limits scalability, especially on long-context processing tasks. Conversely, recurrent models such as RNNs offer notable efficiency via fixed-size state representations, but suffer from memory degradation and limited retrieval, especially over lengthy or noisy contexts. RAT (Recurrent Attention over chunks) proposes an intermediate sequence modeling architecture that partitions input sequences into fixed-size chunks, applies efficient recurrence within each chunk, and enables direct access to remote context via softmax attention over chunk-level summary vectors. This design aims to reduce the computing load while maintaining retrieval effectiveness and model accuracy.
RAT Architecture
RAT divides a sequence of length T into C chunks of size L, where within each chunk, token-level recurrence captures local dependencies efficiently, and chunk-level softmax attention enables direct global token access. By adjusting the chunk size L, RAT interpolates between attention (L=1) and recurrent architectures (L=T). This design circumvents the pitfalls of fully compressed sequence histories, preserving fine-grained retrieval when modeling long contexts. Notably, RAT is not tied to a particular recurrence, and the intra-chunk RNN can be swapped for more advanced variants as future work.

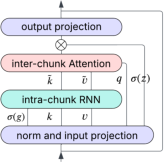
Figure 1: Token-level information flow across classic attention, RNN, and RAT, highlighting local recurrence and chunk-wise attention in RAT.
Within RAT, token representations in a chunk are aggregated by a recurrent update with per-dimension forget and output gates. For each query, attention is applied over all previous chunk-level key/value vectors (and intra-chunk tails), subject to causal masking, followed by a linear output projection through an output gate. This approach is amenable to efficient tensor and context parallelism, reducing key-value cache and memory requirements commensurately with chunk size.
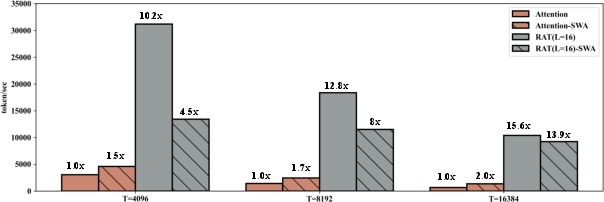
Figure 2: Throughput comparison for 1.3B RAT and attention models under different sequence/prefill lengths. RAT exhibits 10.2× to 15.6× efficiency gains for long-context generation.
Efficiency and Implementation
RAT demonstrates significant reductions in both FLOPs and latency. With chunk size L=16, a single block in generation mode at the 4K position is up to 9× faster than standard attention, with 10× higher maximum throughput. The chunk-based recurrence exploits parallel scan algorithms and incurs minimal overhead when chunk sizes are appropriately chosen. Parallelism is straightforward: per-head and per-chunk independence facilitates GPU allocation, while head count is unaffected as recurrence is dimension-wise, not head-wise. In decoding, reduced cache size lessens out-of-memory risk and enables long-context inference previously infeasible for traditional transformer implementations.
Accuracy and Ablation
Extensive benchmarking—using 1.3B parameter models pretrained on 100B tokens and evaluated across commonsense reasoning, code completion, long-context QA/summarization, and synthetic retrieval tasks—shows RAT(L=16) matches attention on average for the majority of short- and long-context tasks. Notably, interleaving RAT with sliding-window attention (SWA) yields further accuracy improvements, with up to 3−4× throughput gains and top scores in commonsense reasoning, QA, and summarization metrics.
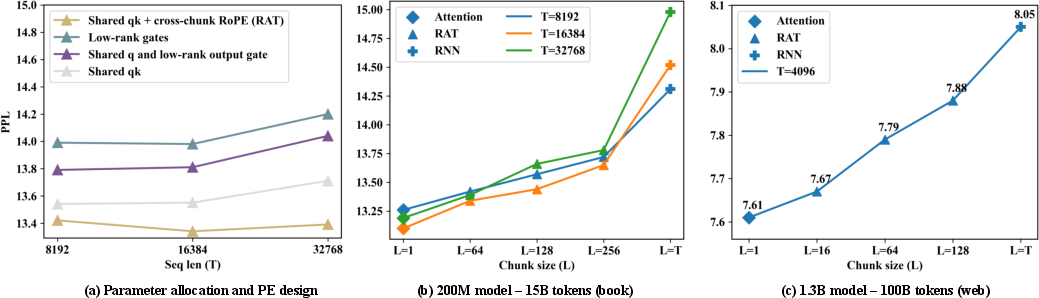
Figure 3: Ablation analysis of RAT variants showing the influence of chunk size and parameter allocations on pretraining perplexity and downstream accuracy.
Pretraining perplexity analyses reveal RAT's behavior lies between attention and RNN, with increasing chunk size correlating with increased perplexity but reduced FLOPs. Short-context binary-choice tasks exhibit minor gaps between attention and RNN, yet RAT consistently outperforms recent linear/state-space models (e.g., Mamba, DeltaNet) in retrieval-heavy or long-context benchmarks.
Long-Context Generalization
Length generalization experiments show RAT's performance remains robust when test sequences greatly exceed training context length, particularly when equipped with chunk-level positional encodings (RoPE or NoPE). With NoPE, RAT's extrapolation surpasses attention, maintaining stable loss up to T=16K. Attention, in contrast, degrades quickly when extrapolated. These results indicate RAT's architectural bias towards scalable global retrieval mitigates failure modes common in fixed-size RNNs and attention models.
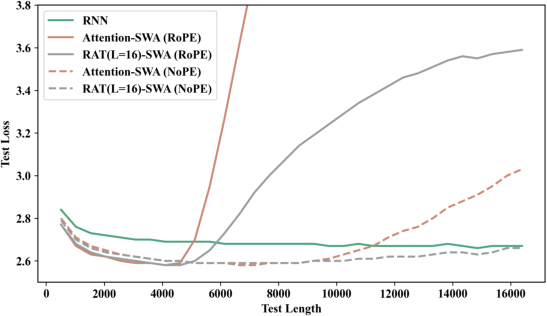
Figure 4: Generalization performance for RAT(SWA) models with RoPE and NoPE, evaluated at sequence lengths up to T=16,384.
Retrieval Ability
Needle-in-haystack synthetic benchmarks underpin the retrieval advantage of chunk-wise attention: RNNs fail at complex retrieval tasks, attention excels via full-token access, while RAT(L=16) approaches attention-level performance except on most demanding UUID matching. Crucially, smaller chunk sizes trade some accuracy for significant efficiency, with RAT(L=64) behaving as an intermediate in retrieval capabilities.
Architectural and Theoretical Implications
The chunk-based hierarchy of RAT balances the spatial memory compression of RNNs with the fine-grained global retrieval of attention, enabling a FLOPs configurability not realizable in classic architectures. This paradigm offers an alternative to state-space, landmark, or dilated attention methods. Notably, hybridization with sliding local attention augments both performance and efficiency.
From a theoretical standpoint, RAT’s design aligns with emerging trends in hybrid sequence models and memory-anchored architectures. It addresses well-known memory degradation and retrieval failures of RNNs and state-space models ([Bengio94], [rnn_difficulty]), while circumventing the computational bottlenecks of full attention ([attention]). Chunkwise abstraction scales storage with sequence length, balancing short- and long-range dependency modeling, and is flexible for further future exploration with adaptive chunking, non-linear chunk/recurrence, and advanced extrapolation encodings.
Practical Implications and Future Directions
RAT realizes substantial cost savings for both training and inference on long-context LLMs, lowering environmental impact and enabling wider deployment. The efficient retrieval and generalization characteristics suggest RAT may be especially suited for multi-document QA, summarization, and any task demanding selective retrieval over extended contexts. While this work concentrates on 1.3B parameter scale, extension to 7B and 14B models is a clear next step. Integrating supervised fine-tuning, advanced chunk scheduling, and extrapolation techniques will likely further improve long-context generalization and performance. As AI moves toward efficient unlimited context LLMs, RAT’s architectural innovations provide a promising avenue for scalable, performant sequence modeling.
Conclusion
RAT introduces a hierarchical architecture that leverages intra-chunk recurrence for local modeling and inter-chunk attention for scalable, high-performing long-context retrieval. Rigorous benchmarks demonstrate strong efficiency gains—up to 10× throughput—and accuracy parity with attention across diverse tasks. Hybridization with local attention further enhances both speed and accuracy. Due to its configurability, efficient resource utilization, and robust retrieval, RAT is an impactful trajectory in the development of future long-context LLMs and sequence models (2507.04416).