- The paper introduces a selective compression and expansion framework that reduces inference latency and memory usage through context chunking.
- It employs a lightweight RL policy to dynamically decide which text chunks to expand, optimizing computational resources under latency constraints.
- Empirical results show REFRAG achieves up to 32.99× TTFT acceleration and matches or exceeds LLaMA performance without loss in perplexity.
REFRAG: An Efficient Decoding Framework for Retrieval-Augmented Generation
Retrieval-Augmented Generation (RAG) systems leverage external knowledge by concatenating retrieved passages with user queries as input to LLMs. While this approach enhances factuality and coverage, it introduces significant computational bottlenecks: inference latency and memory usage scale poorly with context length, primarily due to quadratic attention complexity and linear key-value (KV) cache growth. In RAG, most retrieved passages are only marginally relevant, resulting in block-diagonal attention patterns and substantial redundancy in computation. Existing long-context optimization methods, such as attention sparsification or prompt compression, are not tailored to the unique structure of RAG contexts and often fail to address the specific inefficiencies of RAG decoding.
REFRAG Architecture and Decoding Mechanism
REFRAG introduces a context compression and selective expansion framework that exploits the sparsity and structure of RAG contexts to accelerate inference and reduce memory usage, without modifying the underlying LLM architecture or decoder parameters.
The core design is as follows:
- Chunking and Encoding: The context (retrieved passages) is divided into fixed-size chunks. Each chunk is processed by a lightweight encoder (e.g., RoBERTa), producing a single chunk embedding per chunk. These embeddings are projected to match the decoder's token embedding dimension.
- Precomputability: Chunk embeddings are precomputable and can be cached, enabling efficient reuse across multiple queries or decoding steps.
- Selective Expansion: A lightweight reinforcement learning (RL) policy determines which chunks are expanded (i.e., represented by their full token embeddings) and which are compressed (i.e., represented by their chunk embedding). This policy is trained to maximize downstream performance (e.g., minimize perplexity) under a given latency or memory budget.
- Decoder Input: The decoder receives a sequence consisting of token embeddings for the query and a mix of chunk embeddings and token embeddings for the context, preserving the autoregressive property and supporting arbitrary compression positions.
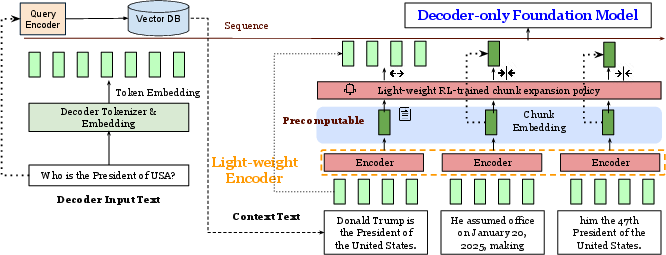
Figure 1: The main design of REFRAG. The input context is chunked and processed by the light-weight encoder to produce chunk embeddings, which are precomputable for efficient reuse. A light-weight RL policy decides few chunks to expand. These chunk embeddings along with the token embeddings of the question input are fed to the decoder.
This architecture enables a reduction in effective context length by a factor of k (the chunk size), yielding substantial improvements in both time-to-first-token (TTFT) and throughput.
Theoretical and Empirical Acceleration
REFRAG achieves acceleration through two mechanisms:
- Input Length Reduction: By replacing k tokens with a single chunk embedding, the input length to the decoder is reduced by approximately k×, directly reducing attention and KV cache costs.
- Quadratic Complexity Reduction: For long contexts, the quadratic attention cost is reduced by up to k2×.
Empirical results confirm these theoretical gains. For k=16, REFRAG achieves 16.53× TTFT acceleration with cache and 8.59× without cache, outperforming prior state-of-the-art (CEPE) by a wide margin. At k=32, TTFT acceleration reaches 32.99× over LLaMA and 3.75× over CEPE, with no loss in perplexity.
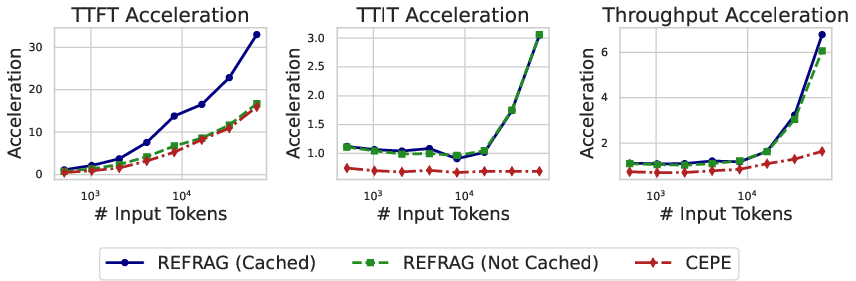
Figure 2: Empirical verification of inference acceleration of REFRAG with k=16.
Training Methodology: Continual Pretraining and Curriculum Learning
To align the encoder and decoder, REFRAG employs a two-stage continual pretraining (CPT) strategy:
- Reconstruction Task: The encoder is trained (with the decoder frozen) to reconstruct the original tokens from chunk embeddings, ensuring minimal information loss in compression and effective projection alignment.
- Next-Paragraph Prediction: After alignment, the decoder is unfrozen and trained to predict the next o tokens given the compressed context, simulating downstream RAG tasks.
Due to the combinatorial explosion of possible chunk contents as k increases, curriculum learning is essential. Training starts with short, easy sequences and gradually increases chunk length and sequence complexity, as visualized below.
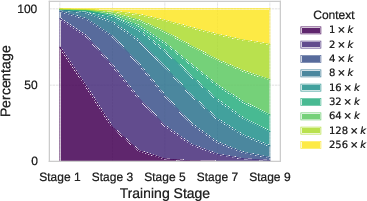
Figure 3: The data mixture in curriculum learning during the training.
Ablation studies demonstrate that both the reconstruction task and curriculum learning are critical for effective encoder-decoder alignment and downstream performance.
Selective Compression via Reinforcement Learning
REFRAG introduces a selective compression mechanism, where an RL policy determines which chunks to expand (retain as tokens) and which to compress (replace with chunk embeddings). The policy is trained using PPO, with negative perplexity as the reward signal. This enables dynamic, query-dependent allocation of computational resources, focusing expansion on the most informative context segments.
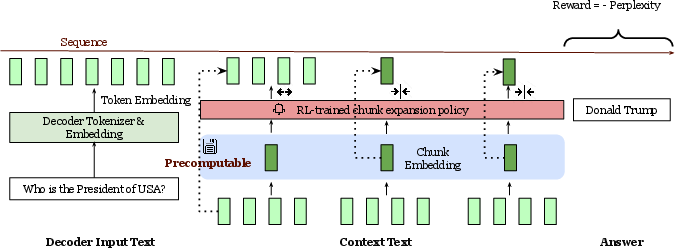
Figure 4: A demonstration of selective token compression. For all chunks, by default, we compress them to a single token, while for crucial chunks, we expand them.
Empirical results show that RL-based selective compression consistently outperforms heuristic or random selection, and that models trained with higher compression rates but selectively expanded via RL can surpass models trained at lower compression rates with full compression.
Performance on RAG and Long-Context Tasks
REFRAG is validated on a suite of long-context tasks, including RAG, multi-turn conversation, and long document summarization. Key findings include:
- RAG: Under both strong and weak retriever settings, REFRAG matches or exceeds LLaMA's performance at the same number of retrieved passages, and significantly outperforms LLaMA under equal latency constraints due to its ability to process more context within the same computational budget.
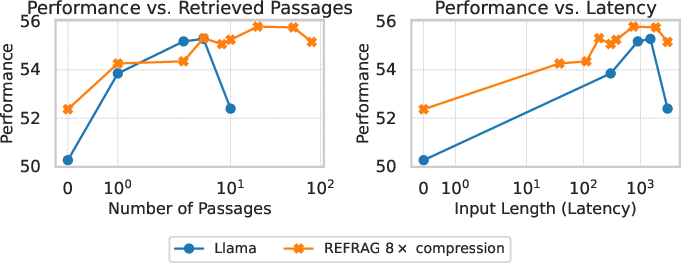
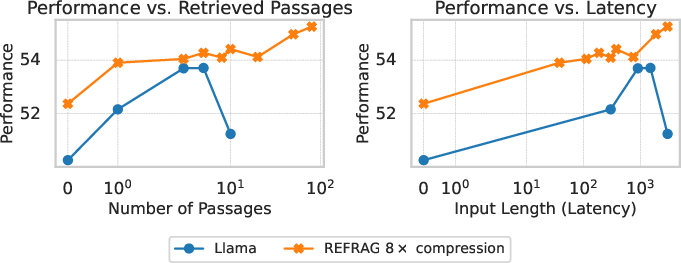
Figure 5: RAG performance comparison under a strong retriever scenario (left) and a weak retriever scenario and a strong retriever scenario (right). REFRAG performs similarly to LLaMA model under the same retrieved passages (slightly better in a weaker retriever case) while outperforming significantly under the same latency.
- Multi-Turn Conversation: REFRAG maintains robust performance as the number of conversational turns and retrieved passages increases, whereas LLaMA degrades due to context truncation.
- Summarization: On long document summarization, REFRAG achieves higher ROUGE scores than LLaMA and other baselines under the same decoder token budget, demonstrating the benefit of compressed context representations for information-dense tasks.
Analysis of Attention Patterns and Context Sparsity
REFRAG's design is motivated by the observation that RAG contexts exhibit block-diagonal attention patterns, with strong intra-chunk attention and weak inter-chunk attention. Visualization of attention matrices in LLaMA-2-7B-Chat confirms this sparsity, justifying aggressive compression of most context chunks.
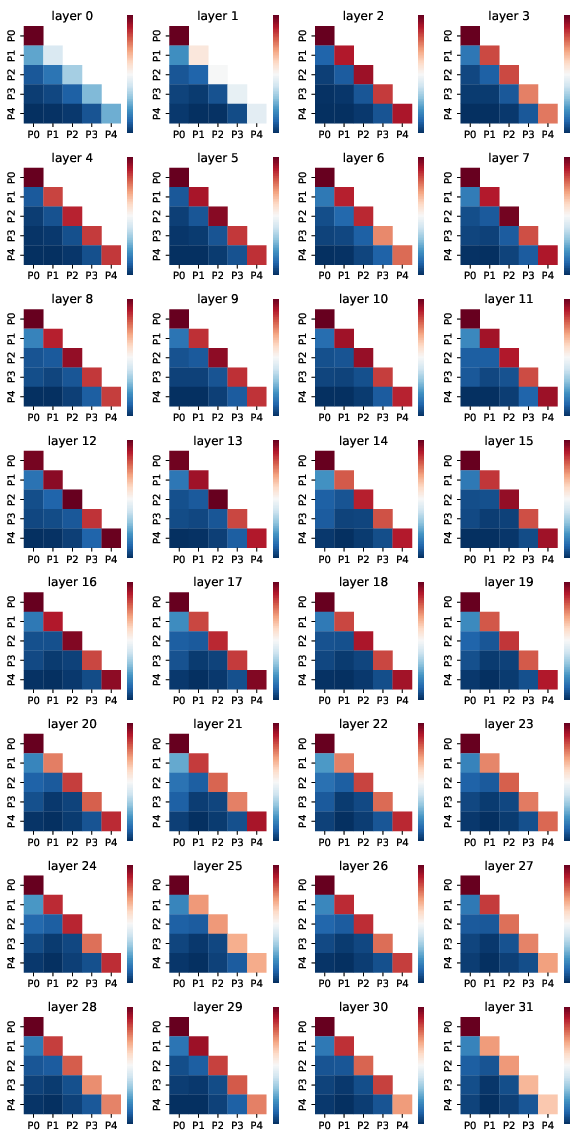
Figure 6: Attention value visualization for different retrieved passages for different layers for LLaMA-2-7B-Chat model. The diagonal values are the averaged attention value for tokens within each passage while the off-diagonal values are the averaged attention value between tokens from different passages.
Implementation Considerations and Trade-offs
- Encoder Choice: Lightweight encoders (e.g., RoBERTa-Base/Large) are sufficient, as increasing encoder size yields diminishing returns compared to scaling the decoder.
- Compression Rate: There is a practical upper bound on k; excessive compression (e.g., k=64) degrades performance. Selective expansion via RL mitigates this trade-off.
- Precomputability: Chunk embeddings can be precomputed and cached, enabling efficient batch inference and further reducing latency.
- Compatibility: REFRAG does not require architectural changes to the decoder, making it compatible with existing LLMs and serving infrastructure.
- Resource Requirements: REFRAG reduces both memory and compute requirements, enabling deployment in latency-sensitive, high-throughput environments.
Implications and Future Directions
REFRAG demonstrates that RAG systems benefit from specialized context compression and expansion strategies that exploit the unique structure of retrieved contexts. The framework enables substantial acceleration and memory savings without sacrificing accuracy, and supports context window extension far beyond the native limits of the underlying LLM.
Potential future directions include:
- Integration with Prompt Compression: Combining REFRAG with token-level or sentence-level prompt compression methods for further efficiency gains.
- Adaptive Compression Policies: Learning more sophisticated, task-aware compression policies that dynamically adjust to query complexity and downstream requirements.
- Generalization to Other Modalities: Extending the REFRAG framework to multi-modal RAG systems, where retrieved context may include images or structured data.
- Hardware-Aware Optimization: Co-designing compression strategies with hardware accelerators to maximize throughput and minimize energy consumption.
Conclusion
REFRAG provides an efficient, scalable, and practical solution for RAG-based LLM inference. By leveraging context sparsity and introducing selective compression and expansion, it achieves up to 30.85× TTFT acceleration and 16× context window extension with no loss in perplexity or downstream accuracy. The framework is broadly applicable to knowledge-intensive, latency-sensitive applications, and sets a new standard for efficient long-context LLM deployment.