Artificial Hippocampus Networks for Efficient Long-Context Modeling
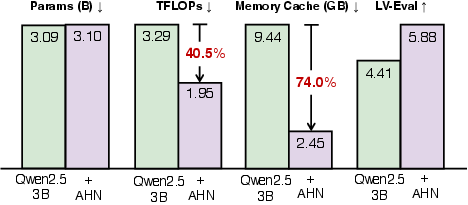
Abstract: Long-sequence modeling faces a fundamental trade-off between the efficiency of compressive fixed-size memory in RNN-like models and the fidelity of lossless growing memory in attention-based Transformers. Inspired by the Multi-Store Model in cognitive science, we introduce a memory framework of artificial neural networks. Our method maintains a sliding window of the Transformer's KV cache as lossless short-term memory, while a learnable module termed Artificial Hippocampus Network (AHN) recurrently compresses out-of-window information into a fixed-size compact long-term memory. To validate this framework, we instantiate AHNs using modern RNN-like architectures, including Mamba2, DeltaNet, and Gated DeltaNet. Extensive experiments on long-context benchmarks LV-Eval and InfiniteBench demonstrate that AHN-augmented models consistently outperform sliding window baselines and achieve performance comparable or even superior to full-attention models, while substantially reducing computational and memory requirements. For instance, augmenting the Qwen2.5-3B-Instruct with AHNs reduces inference FLOPs by 40.5% and memory cache by 74.0%, while improving its average score on LV-Eval (128k sequence length) from 4.41 to 5.88. Code is available at: https://github.com/ByteDance-Seed/AHN.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper tries to make AI models better at reading and remembering very long texts (like whole books or huge chat logs) without using too much computer power or memory. The authors build a new “memory system” for AI, inspired by how the human brain uses short-term and long-term memory. They call it an Artificial Hippocampus Network (AHN).
The main goal and questions
The authors ask:
- Can we combine the strengths of two popular AI memory styles—exact but expensive memory (Transformers) and efficient but “summary-style” memory (RNNs)—to handle very long inputs?
- Can a small, smart “compression brain” (the AHN) save what matters from older parts of the text, so the model stays fast and doesn’t forget important details?
- Will this approach perform as well as, or even better than, standard Transformers while using much less computation and memory?
How their method works (with everyday analogies)
Think of reading a long story:
- Short-term memory: You clearly remember the last few sentences you just read.
- Long-term memory: Your brain keeps a summary of earlier chapters, not every word, but the important ideas.
Transformers (a common AI model):
- Keep a detailed scrapbook of every word so far (called a KV cache). That’s great for accuracy, but the scrapbook gets huge and slow for very long texts.
RNN-like models:
- Keep just one small note that they update each sentence. This stays small and fast but can miss details.
The authors combine both ideas:
- The model keeps a “sliding window” of recent text in perfect detail (short-term memory).
- As older text scrolls past the window, the Artificial Hippocampus Network (AHN) compresses it into a fixed-size summary (long-term memory).
When the model needs to understand the next word:
- It looks at both the detailed recent window and the compact long-term summary.
In short, you get precise memory of what just happened and a smart summary of everything before that—like a brain’s short-term and long-term memory working together.
To make AHN practical, they plug in modern, efficient RNN-style modules (Mamba2, DeltaNet, GatedDeltaNet). These are just different designs for how the “summary note” gets updated.
Training trick (teacher-student learning):
- They don’t retrain the whole big model. Instead, they freeze the main model and only train the small AHN to imitate the full, expensive Transformer (“teacher”). This is called self-distillation: the small “student” learns to match the teacher’s answers, saving time and compute.
Here’s the flow in a few steps:
- Keep the last W tokens (the window) in exact detail.
- Each time a token moves out of the window, feed it into the AHN, which updates the long-term summary.
- For the next prediction, use both the detailed window + the AHN summary.
What they found and why it matters
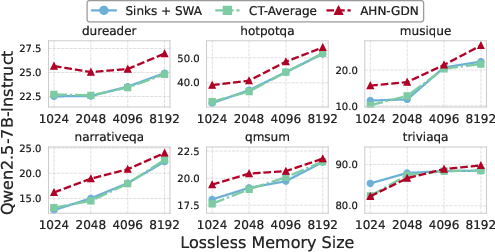
On long-context tests (LV-Eval and InfiniteBench), their models:
- Beat simple “sliding window only” baselines (which forget old info).
- Matched or sometimes surpassed full attention (the expensive Transformer) on many tasks.
- Used much less compute and memory.
A concrete example (Qwen2.5-3B model with AHN):
- Added only about 0.4% more parameters.
- Cut the math work (FLOPs) by about 40.5%.
- Cut memory cache use by about 74.0%.
- Improved the average score on LV-Eval (128k tokens) from 4.41 to 5.88.
They also showed:
- On a 57,000-token book sample, standard models’ performance dropped after their window limit, but AHN models stayed strong.
- GPU memory stayed almost flat with AHN, instead of growing with text length.
Important trade-off:
- Because AHN compresses old information, it can struggle on “exact recall” tasks (like needle-in-a-haystack, where you must retrieve a specific exact phrase from far back). Full attention still wins there, because it keeps everything exactly.
Why this work matters
- It makes “reading super long stuff” much cheaper and more practical. That’s useful for:
- Long documents, research papers, legal contracts, or codebases.
- Streaming data (like live transcripts or long videos).
- Running models on devices with limited memory (like phones or edge hardware).
- It shows a general framework: keep recent details losslessly, compress the rest smartly, and learn to combine them. This could inspire better memory systems across many AI tasks.
Final thoughts and future directions
This paper offers a brain-inspired memory fix for AI: precise short-term memory plus a compact long-term summary. It keeps performance high on long texts while slashing compute and memory use.
Limitations:
- Compression can lose tiny details, so perfect word-for-word recall from far back may suffer.
What’s next:
- Improve how the AHN decides what to keep exactly vs. what to compress.
- Train the whole model end-to-end for even better results.
- Design smarter memory policies for tasks that need both deep reasoning and exact recall.
In short: The Artificial Hippocampus Network helps AI remember more with less—much like how your brain keeps what matters without storing every single word.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and open questions left unresolved by the paper that future work could address:
- Quantify information loss: There is no theoretical or empirical bound on how much information AHN compression discards and how this affects exact recall; develop measures (e.g., mutual information, retrieval accuracy) as a function of AHN state size and sequence length.
- Capacity–performance scaling: The paper does not study scaling laws for compressed memory size (vector vs. matrix, head dimension H, number of heads) versus accuracy, latency, and FLOPs; perform systematic sweeps to identify optimal state size per task.
- Long-horizon stability: Error accumulation and memory drift over very long sequences (e.g., >128k, >1M tokens) are untested; evaluate stability and degradation patterns under streaming or lifelong contexts.
- Exact-recall limitations: AHNs underperform on exact needle-in-a-haystack tasks (RULER); explore hybrid mechanisms (e.g., selective lossless retention of critical facts, episodic checkpoints, adaptive caching) to recover exact recall.
- Adaptive memory allocation: The framework uses fixed sliding windows and fixed AHN state size; investigate adaptive windowing, dynamic memory budgets, and per-token/per-layer decisions conditioned on content or uncertainty.
- Memory decay and retention: While AHN-GDN can control decay, there is no analysis of retention timescales or learned forgetting dynamics; characterize what types of information persist and when/how memory should decay.
- Output integration design: The integration uses a simple sum of attention output and AHN output with a scalar gate; compare alternative fusion mechanisms (e.g., attention over AHN memory, multi-head gating, cross-attention to AHN state, learned mixture-of-experts).
- Addressing and readout expressivity: The AHN readout is bilinear (q_t h W_o) with head-shared gating; evaluate head-wise gates, key–query matching strategies, and content-addressable readout to improve selective retrieval.
- Layerwise placement and sharing: AHNs are added per attention layer without ablation; study placing AHNs only in selected layers, sharing AHN states across layers, or hierarchical AHNs to reduce redundancy and interference.
- Teacher choice and distillation targets: Self-distillation uses a frozen teacher that degrades beyond its trained context; assess stronger teachers (long-context models), multi-teacher ensembles, or synthetic targets to avoid teacher-limited ceilings.
- Training objective design: Only KL self-distillation and CE are tested; explore multi-objective training (e.g., auxiliary retrieval losses, contrastive memory losses, reconstruction of dropped KV pairs) that directly optimize compressed recall.
- Data and curriculum: Training uses ChatQA2 for one epoch; test broader domains (code, math, logs, legal, biomedical) and long-context curricula (progressive length, variable compression difficulty) for robust generalization.
- Sensitivity to sinks and window size: While some randomization is shown, there is no systematic sensitivity analysis for attention sinks and sliding window sizes across tasks and base models; map performance surfaces to guide deployment settings.
- Architecture diversity beyond RNN-like: Only Mamba2, DN, and GDN are instantiated; evaluate other compressive token mixers (e.g., state-space models, convolutional long-range kernels, Hyena/RetNet-style modules) under the AHN framework.
- Cross-model generality: Experiments focus on Qwen2.5; validate AHNs on other LLM families (LLaMA, Mixtral/MoE, DeepSeek, Gemma) to confirm portability and interactions with GQA/MQA, grouped heads, or attention variants.
- Comparison to stronger long-context baselines: Baselines include SWA and Compressive Transformer with simple pooling; add comparisons to state-of-the-art efficient attention methods (Longformer, BigBird, RingAttention, RetNet, Memorizing Transformers) under matched budgets.
- Robustness and safety: There is no evaluation of robustness to noisy, adversarial, or distribution-shifted inputs, nor analysis of privacy leakage from compressed memory; design tests and mitigation strategies (e.g., differential privacy in AHN updates).
- Persistent memory across sessions: AHN state serialization, reset policies, and cross-session reuse are unaddressed; develop protocols for saving/loading AHN state, session scoping, and contamination avoidance.
- Multi-turn dialog and tool use: The impact of AHNs on dialogue memory over many turns, tool calls, and retrieval-augmented pipelines is untested; measure effects on conversational coherence and tool reliability at extreme contexts.
- Multimodal extension: AHNs are proposed for long-context generally, but only text is evaluated; adapt and test AHNs for long video/audio streams, images, and mixed modalities where compression needs differ.
- Hardware and systems metrics: FLOPs and cache ratios are reported, but end-to-end throughput, latency, energy, and memory bandwidth on real hardware (GPU/TPU/edge) are not measured; provide deployment-grade benchmarks.
- Memory interference analysis: There is no characterization of interference in AHN states (e.g., topic mixing, catastrophic overwriting); probe with targeted write/read tests and propose mechanisms (slotting, orthogonalization, sparse updates).
- Granularity of compression: Tokens are compressed as they exit the window; assess chunk-level or semantic compression (summarization, entity tracking) and content-aware triggers (e.g., compress only non-critical tokens).
- Hybrid retrieval integration: The framework doesn’t explore integration with external retrieval or databases to complement lossy compression; design interfaces for pulling exact facts when AHN confidence is low.
- Formalization and guarantees: Provide a more complete formal specification (some equations have typos) and, if possible, theoretical analyses of AHN update rules (stability, convergence, memory capacity) under different architectures.
- Evaluation breadth: Current benchmarks emphasize QA; expand to program synthesis, long mathematical proofs, multi-document reasoning, codebase-scale contexts, and lifelong learning tasks to stress diverse memory demands.
Practical Applications
Immediate Applications
The paper’s AHN framework enables efficient long-context processing with lower FLOPs, constant KV cache beyond a sliding window, and minimal parameter overhead, making several applications deployable today with existing open-weight models and code.
Industry
- Long-document understanding and summarization at scale (sectors: legal, consulting, finance, government)
- Tools/products/workflows: Batch processors that ingest 100k+ token contracts, filings, case files, and produce summaries, issue lists, and QA without exceeding GPU memory; “AHN-augmented inference tier” for document analysis services.
- Why AHN: Maintains accuracy comparable to full attention on long-context benchmarks while reducing KV cache by ~74% and token-mixing FLOPs by ~40–50%.
- Assumptions/dependencies: Tasks tolerate lossy compression for far-past context; exact needle-in-a-haystack retrieval is not the primary requirement; model based on open weights (e.g., Qwen2.5) or compatible architectures.
- Multi-hour meeting assistants and contact-center analytics (sectors: enterprise SaaS, customer support)
- Tools/products/workflows: Real-time streaming transcript analysis that keeps only a sliding window in KV and compresses older content into AHN state; “conversation memory snapshots” persisted per thread for low-latency follow-ups.
- Why AHN: Constant memory cost per token allows long, continuous sessions on fixed hardware.
- Assumptions/dependencies: Robust streaming pipeline; acceptable to trade exact token recall for compact semantic recall; guardrails for PII.
- Code intelligence over large repositories and logs (sectors: software, DevOps, observability)
- Tools/products/workflows: IDE copilots that keep long editing sessions and repository-wide context; CI/CD chat agents that track long build/test logs; log analytics copilots that scan weeks of logs without external retrieval.
- Why AHN: Retains gist of distant code/files/logs beyond window; linear compute after window size.
- Assumptions/dependencies: Exact line-level recall may require hybrid with retrieval; good tokenization and chunking strategy.
- Compliance and policy scanning (sectors: finance, healthcare, public sector)
- Tools/products/workflows: Continuous monitors that scan long regulations, disclosures, and policy updates; “regulatory watch” assistants that maintain compressed memory across long streams.
- Why AHN: Lower compute/memory enables frequent re-scans on modest hardware.
- Assumptions/dependencies: Some rules demand exact quotations; complement with retrieval or short-range KV preservation for critical clauses.
- Cost-optimized long-context inference services (sectors: cloud providers, AI platforms)
- Tools/products/workflows: A dedicated “efficient long-context” API tier that uses SWA+AHN with window budgeting; autoscaling profiles that cap memory usage over very long prompts.
- Why AHN: Predictable memory footprint enables accurate capacity planning and higher throughput per GPU.
- Assumptions/dependencies: Integration into inference stacks (KV management, attention sinks); SLA characterization under lossy long-term memory.
- On-prem and edge deployments for long logs/streams (sectors: manufacturing, energy, telecom)
- Tools/products/workflows: On-site LLMs that process SCADA/IoT logs or call-center streams with constant memory growth; “AHN state checkpointing” to resume from compressed memory.
- Why AHN: Reduces hardware requirements and data egress; supports privacy-sensitive environments.
- Assumptions/dependencies: Enough local compute for the window; secure storage of AHN state.
Academia
- Efficient long-context evaluation and curriculum research
- Tools/products/workflows: Benchmarks and courses using LV-Eval/InfiniteBench with AHN-augmented baselines; assignments comparing SWA vs. AHN vs. full attention.
- Why AHN: Open code/models; parameter-efficient training via self-distillation with frozen base LLMs.
- Assumptions/dependencies: Access to teacher models that can run full attention on curated subsets.
- Neuro-inspired memory studies and interpretability
- Tools/products/workflows: Gradient-based probes of what AHN keeps vs. drops; tools that visualize memory decay and selection.
- Why AHN: Clear abstraction of “hippocampal” compression allows empirical study of memory trade-offs.
- Assumptions/dependencies: Tasks with identifiable salient tokens; instrumentation for gradient visualization.
- Teaching labs on memory-efficient architectures
- Tools/products/workflows: Classroom kits showing complexity reductions (O(WL) vs. O(L2)); ablations on window size randomization and KL vs. CE objectives.
- Assumptions/dependencies: Compute to run teacher-student distillation on small corpora.
Policy
- Energy- and cost-aware AI procurement and governance
- Tools/products/workflows: RFP criteria encouraging long-context solutions with measured FLOP and memory reductions; ESG reporting incorporating efficiency metrics.
- Why AHN: Demonstrated large cache and FLOP reductions for 128k contexts.
- Assumptions/dependencies: Standardized efficiency benchmarks and disclosures.
- Data locality and privacy for public-sector long files
- Tools/products/workflows: On-prem deployments that avoid external retrieval; compressed memory states stored securely behind firewalls.
- Assumptions/dependencies: Security reviews for storing compressed states; task designs robust to lossy memory.
Daily Life
- Personal knowledge bases and journaling assistants
- Tools/products/workflows: Note apps that remember months of entries via AHN states; “session resume” that restores memory without reloading full history.
- Assumptions/dependencies: Device storage for AHN checkpoints; user consent and privacy controls.
- Email and chat thread copilots for long histories
- Tools/products/workflows: Assistants that track multi-year threads while keeping GPU/CPU memory bounded.
- Assumptions/dependencies: Occasional need for exact quotes may require short-range search or retrieval fallback.
- Long-form reading and study aids
- Tools/products/workflows: Book-length summarization, question answering, and study guides with efficient memory management.
- Assumptions/dependencies: Content licensing and fair use; acceptance of semantic rather than verbatim recall.
- Streaming media transcript summarization
- Tools/products/workflows: Podcast/lecture live summarization with rolling short-term window and AHN compression.
- Assumptions/dependencies: ASR quality; latency budgets.
Long-Term Applications
These ideas are feasible but likely require additional research, scaling, or system integration, especially to mitigate lossy memory on exact-recall tasks or to extend to new modalities.
Industry
- Multimodal long-horizon assistants (video/audio/sensor + text) (sectors: media, robotics, autonomous systems)
- Tools/products/workflows: AHN modules instantiated for multimodal KV streams to track long video timelines, mission logs, or robot trajectories.
- Why AHN: Fixed-size state suits hour-long sequences; potential to replace ad-hoc chunking.
- Assumptions/dependencies: Robust multimodal tokenizers; RNN-like AHNs adapted to modality-specific features; new benchmarks.
- Hybrid RAG + AHN “critical-slot” memory systems (sectors: legal, healthcare, finance)
- Tools/products/workflows: Systems that keep critical facts losslessly (pins) while compressing the rest; dynamic policies that decide when to pin vs. compress vs. retrieve.
- Why AHN: Combines semantic continuity with precise recall where needed.
- Assumptions/dependencies: Memory management policies; detection of critical spans; governance for provenance and citations.
- AHN-as-a-service and “memory budget planners”
- Tools/products/workflows: Cloud services offering memory budgeting APIs (window size, sinks count, decay gates); dashboards for cost/quality trade-offs.
- Assumptions/dependencies: Standard interfaces for KV and AHN state; SLO-driven tuning.
- Persistent “enterprise memory fabric”
- Tools/products/workflows: Cross-application memory layer storing AHN states per project/customer to enable context continuity across tools (CRM, ticketing, docs).
- Assumptions/dependencies: Identity, access control, encryption-at-rest for AHN states; lifecycle and retention policies.
- Long-horizon forecasting over massive time series (sectors: energy, manufacturing, finance)
- Tools/products/workflows: Streaming forecasters that maintain compressed states over months of data with occasional high-fidelity anchor windows.
- Assumptions/dependencies: Domain-specific evaluation that tolerates lossy long-term compression; drift handling.
Academia
- Full-parameter training with AHNs and curriculum schedules
- Tools/products/workflows: From-scratch training to let base layers co-adapt to AHN compression; curricula that grow sequence length and vary window sizes.
- Assumptions/dependencies: Significant compute; careful regularization to avoid shortcut learning.
- Theoretical guarantees and memory policy learning
- Tools/products/workflows: Formal analyses of error bounds under compression; learned policies for selective write/decay.
- Assumptions/dependencies: New loss functions for recall-vs-efficiency trade-offs; interpretable gating.
- Cross-lingual and domain-specific AHN compression strategies
- Tools/products/workflows: Tailored AHNs for code, biomedical, and low-resource languages where salient token types differ (e.g., numbers, entities).
- Assumptions/dependencies: High-quality domain corpora; teacher models with strong long-context performance.
Policy
- Standards for efficiency reporting and “green AI” incentives
- Tools/products/workflows: Benchmarks (e.g., LV-Eval, InfiniteBench) formalized in procurement; subsidies for architectures meeting energy thresholds.
- Assumptions/dependencies: Independent auditing of FLOPs/memory; lifecycle impact assessments.
- Privacy-preserving compressed memory
- Tools/products/workflows: Differential privacy or encryption mechanisms applied to AHN states; policies for retention and subject access.
- Assumptions/dependencies: Algorithms for secure state composition and deletion; regulatory harmonization.
Daily Life
- On-device personal assistants with lifelong memory
- Tools/products/workflows: Mobile/AR assistants that keep compressed long-term memories locally and sync selectively; “memory checkpoints” portable across devices.
- Assumptions/dependencies: Efficient quantization/pruning; battery-aware scheduling; consent-driven memory curation.
- Gaming NPCs and interactive fiction with persistent context
- Tools/products/workflows: NPCs that remember storylines and player choices over dozens of hours with bounded compute.
- Assumptions/dependencies: Tooling for designers to pin critical plot points; testing frameworks for narrative coherence.
- Education: longitudinal tutoring across semesters
- Tools/products/workflows: Tutors that remember student progress and misconceptions across courses, with compressed memory and pinned assessment results.
- Assumptions/dependencies: FERPA/GDPR compliance; interfaces for teachers to inspect and correct memory.
Notes on feasibility across all applications:
- Strengths: Substantial KV cache and FLOP reductions; small parameter overhead; open-source code and models; simple integration with sliding-window attention.
- Limitations: Lossy long-term memory can underperform on exact recall (e.g., advanced NIAH tasks); performance tied to teacher model in self-distillation; window sizing and sink strategies require tuning; additional engineering needed to persist and secure AHN states.
- Recommended mitigations: Hybrid with retrieval or pinning for critical spans; dynamic memory policies; evaluation on task-specific exact-recall requirements.
Glossary
- AHN-DN: An AHN variant instantiated using the DeltaNet architecture to compress out-of-window context into a fixed-size memory. "resulting in the AHN-Mamba2, AHN-DN and AHN-GDN."
- AHN-GDN: An AHN variant built with GatedDeltaNet that uses gated updates to form compressed long-term memory. "AHN-GDN updates memory via the gated delta rule"
- AHN-Mamba2: An AHN variant instantiated using the Mamba2 architecture to perform efficient recurrent compression. "resulting in the AHN-Mamba2, AHN-DN and AHN-GDN."
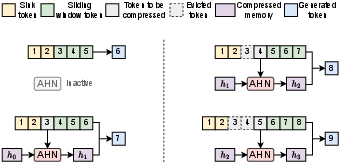
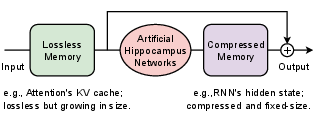
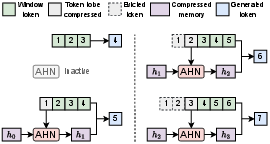
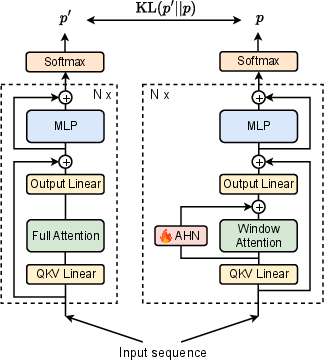
- Artificial Hippocampus Networks (AHNs): Learnable modules that continually compress out-of-window information into a fixed-size long-term memory while retaining a sliding-window lossless memory. "Artificial Hippocampus Networks (AHNs) transform lossless memory into fixed-size compressed representations for efficient long-context modeling."
- Attention sinks: Dedicated tokens kept in the lossless memory to stabilize attention and preserve important context in sliding-window setups. "consisting of 128-token attention sinks and a 32640-token sliding window during inference."
- Autoregressive: A modeling paradigm where tokens are generated sequentially, each conditioned on previously generated tokens. "Most modern autoregressive LLMs are built on Transformer architecture"
- Budget allocation: Methods that distribute limited cache or compute across tokens to manage long-context resources. "including KV cache selection, budget allocation, merging, quantization, low-rank decomposition, external memory, and neural architecture design"
- Causal attention: Self-attention that only attends to past tokens, using a causal mask to enforce autoregressive constraints. "In causal attention, the key-value cache functions as memory: for each input token, a new key and value are generated and appended to the cache."
- Causal mask: A binary matrix that prevents attention to future tokens, ensuring autoregressive behavior. "where is the causal mask, defined by if , and otherwise."
- Compressive memory: Fixed-size, lossy memory used by RNN-like models to summarize long histories efficiently. "a fundamental trade-off between the efficiency of compressive memory and the fidelity of lossless memory."
- Compressive Transformer (CT): A Transformer variant that compresses older memories into a secondary buffer to extend context capacity. "Compressive Transformer \citep{rae2020compressive} extends this by compressing older memories into a secondary FIFO memory, but it still discards memory once the slots are full."
- DeltaNet (DN): A linear recurrent architecture used to instantiate AHNs for efficient parallel training and compression. "DeltaNet (DN) \citep{schlag2021linear, yang2024parallelizing}"
- Differentiable Neural Computer (DNC): A neural architecture with an external memory and differentiable read/write operations to support complex reasoning. "the Differentiable Neural Computer (DNC) \citep{graves2016hybrid} introduce external memory modules that the network can read from and write to"
- FIFO memory: A queue-based memory mechanism where the oldest items are removed first, used to cache previous segments. "Transformer-XL \citep{dai2019transformer} introduces a segment-level recurrence mechanism by caching the last segment of hidden states as a First-In, First-Out (FIFO) memory."
- FlashAttention: An optimized attention kernel that reduces GPU memory footprint and improves throughput for long sequences. "while the base models' memory usage grows linearly under FlashAttention"
- Flash Linear Attention: A linearized attention implementation used for efficient training and inference. "Flash Linear Attention~\citep{yang2024fla}"
- FLOPs: Floating-point operations used as a proxy for computational cost in model and token mixer complexity. "FLOPs account for matrix multiplication only; softmax, normalization, and matrix element summation are omitted."
- Gated delta rule: A gated update mechanism for recurrent memory that controls decay and incorporation of new information. "AHN-GDN updates memory via the gated delta rule"
- GatedDeltaNet (GDN): An enhanced DeltaNet with gating to dynamically control memory decay and updates. "GatedDeltaNet (GDN) \citep{yang2024gated}"
- InfiniteBench: A benchmark designed to assess LLMs’ ability to handle super-long contexts with understanding and reasoning. "InfiniteBench, a benchmark tailored to evaluate LLMs' ability to process, understand, and reason over super-long contexts."
- Key–Value (KV) cache: The stored keys and values for each token that enable attention to retrieve exact past information. "including key-value (KV) caches in attention mechanisms \citep{vaswani2017attention}"
- Kullback–Leibler (KL) divergence: A measure used to align the student model’s output distribution with a teacher during self-distillation. "We train the student to mimic the teacher's output distribution by minimizing the Kullback-Leibler (KL) divergence:"
- Linear recurrent models: Modern RNN-like architectures with linear-time operations enabling efficient parallel training. "we focus on modern linear recurrent models for their efficient parallel training."
- LongBench: A suite of diverse long-context tasks for evaluating practical long-context understanding. "LongBench, which features diverse tasks across multiple domains and languages, designed to rigorously test long-context understanding in more realistic scenarios."
- LV-Eval: A long-context benchmark (up to 128k tokens) for evaluating single- and multi-hop QA under challenging conditions. "(b) On the long-context benchmark LV-Eval (128k sequence length), augmenting Qwen2.5-3B-Instruct with AHNs (+0.4\% parameters) reduces FLOPs by 40.5\% and memory cache by 74.0\%, while improving average score from 4.41 to 5.88."
- Mamba2: A modern recurrent architecture used to instantiate AHNs with efficient compression and parallelism. "we instantiate them using Mamba2 \citep{dao2024transformers}, DeltaNet (DN) \citep{schlag2021linear, yang2024parallelizing} and GatedDeltaNet (GDN) \citep{yang2025gated}"
- Multi-Store Model (MSM): A cognitive theory describing separate short-term and long-term memory stores and consolidation. "The theory of Multi-Store Model of memory (MSM) in Cognitive Science and Neuroscience \citep{atkinson1968human} suggests..."
- Needle-in-a-haystack (NIAH): A task paradigm for exact-recall evaluation within very long contexts. "extends the standard needle-in-a-haystack (NIAH) paradigm"
- Perplexity: A metric that evaluates LLM uncertainty and performance on long text sequences. "Perplexity results on the first book of the PG19 test set (57K tokens)."
- Retrieval-augmented models: Systems that integrate external databases to fetch information and enhance generation. "external databases for retrieval-augmented models \citep{lewis2020retrieval}"
- RNN-like architectures: Recurrent neural models that maintain fixed-size hidden states and support efficient long-sequence processing. "AHNs can be instantiated with RNN-like architectures, and the overall framework is illustrated in Figure \ref{fig:ahn_concept}."
- Self-distillation: Training strategy where a student mimics a frozen teacher’s outputs to learn compressed memory behaviors efficiently. "we adopt a more computationally efficient approach using self-distillation \citep{hinton2015distilling, zhang2018deep, zhang2019your}."
- Sliding window attention (SWA): An attention scheme that retains a fixed-size window of recent tokens while discarding older KV entries. "sliding window attention (SWA) with attention sinks~\citep{xiao2024efficient}"
- Transformer-XL: A Transformer variant that introduces segment-level recurrence and a FIFO memory to extend context. "Transformer-XL \citep{dai2019transformer} introduces a segment-level recurrence mechanism"
Collections
Sign up for free to add this paper to one or more collections.

