- The paper presents a hierarchical memory architecture that decouples training speed from inference performance by optimizing chunkwise parallelism in RNNs.
- It employs a two-stage process, combining efficiency-focused pre-training with performance-focused fine-tuning, to achieve significant training time reductions.
- The framework leverages global and local memory modules to handle long-range dependencies, outperforming traditional RNN and Transformer implementations.
TNT: Improving Chunkwise Training for Test-Time Memorization
The paper "TNT: Improving Chunkwise Training for Test-Time Memorization" explores a novel training paradigm designed to alleviate the efficiency bottlenecks associated with recurrent neural networks (RNNs) featuring deep test-time memorization modules. Despite their theoretical potential, such models have struggled with scalability due to slow training times and low hardware utilization. To overcome these challenges, the TNT framework decouples training speed from inference performance, employing a hierarchical memory architecture combined with a two-stage process. This results in substantial gains in training efficiency and model accuracy.
Test-Time Memorization and Deep Memory Modules
RNNs with deep memorization capabilities rely on secondary sub-networks called deep memory modules. These modules consist of fast weights that are dynamically updated during training and inference to store contextual information. The TNT framework enhances these modules by introducing a new hierarchical architecture that segments the memory system into global and local components. Each module operates at different chunk sizes, optimizing throughput and expressiveness simultaneously.
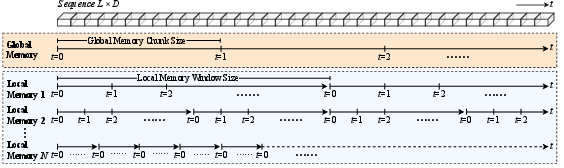
Figure 1: The basic diagram illustrating TNT memory hierarchy. In each row, the updates at the same value of t ran at the same time (run in parallel). t=0 is the initialization of the memory.
Chunkwise Parallel Training
Traditional chunkwise training processes tokens in non-overlapping chunks, allowing parallel computations within a chunk but maintaining sequential dependencies between chunks. TNT enhances this by periodically resetting the local memory states across sequence shards, breaking these dependencies and enabling parallelization across entire sequences. This is crucial for achieving high hardware utilization and improving training speeds.
TNT Framework Stages
Stage 1: Efficiency-Focused Pre-Training
This stage leverages the hierarchical memory structure to maximize training throughput. A global memory module with large chunk sizes captures long-range dependencies efficiently, while local modules manage finer details. Resets of local memory states at regular intervals allow for massive context parallelization.
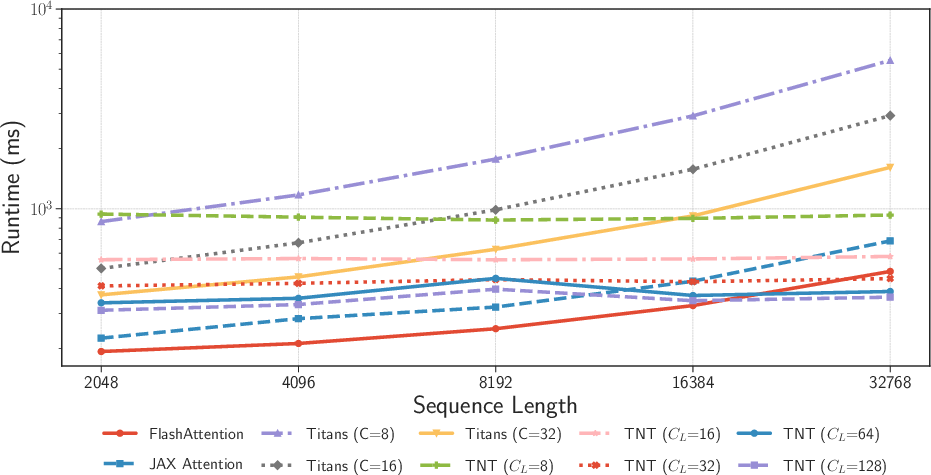
Figure 2: Runtime comparison of different models and implementations across varying sequence lengths, with the number of tokens per batch fixed at 0.5M.
Following efficiency-focused pre-training, a brief fine-tuning stage adapts the model to smaller chunk sizes, optimizing it for high-resolution inference. This phase ensures that the model achieves superior performance with minimal computational cost, addressing the sensitivity of inference performance to pre-training conditions.
Experimental Analysis
Efficiency Gains
Through extensive evaluations, TNT demonstrates up to a 17 times reduction in training time compared to traditional RNN approaches. The hierarchical memory design with context parallelization substantially improves runtime efficiency, especially at long sequence lengths, where TNT outperforms even optimized Transformer implementations.
TNT models achieve notable accuracy improvements on language modeling tasks, matching or exceeding traditional models. The framework effectively closes the performance gap between deep memory modules and Transformers by optimizing training routines and leveraging multi-resolution memory systems.
Conclusion
TNT establishes an innovative and efficient training paradigm for deep memory modules in RNN architectures. By decoupling training efficacy from inference accuracy, it removes significant scalability barriers and paves the way for future advancements in efficient sequence modeling. The framework's successful application on Titans models highlights its potential to improve both the practicality and performance of expressive RNN architectures, positioning it as a viable alternative to Transformers for long sequence contexts.

