- The paper demonstrates that MLM generally outperforms CLM in tasks like sequence classification and question answering due to its enhanced bidirectional context.
- It shows that optimal masking ratios vary with model size, stressing the need for adaptive pretraining configurations to maximize efficiency.
- It introduces a two-stage pretraining strategy that uses CLM for training stability followed by MLM for deeper contextual understanding.
Exploring the Efficacy of Masked Language Modeling Versus Causal Language Modeling
Introduction
The paper "Should We Still Pretrain Encoders with Masked Language Modeling?" (2507.00994) scrutinizes the entrenched role of Masked Language Modeling (MLM) in pretraining text encoders, juxtaposing its efficacy with the increasingly popular Causal Language Modeling (CLM) paradigm. The authors embark on a comprehensive analysis involving large-scale, controlled experiments to disambiguate the benefits of both modeling objectives, thus providing a methodical investigation into the effectiveness of these approaches under varying conditions of data efficiency, stability, and computational resources. This exploration is rooted in training numerous models with meticulously controlled conditions to yield substantive insights into pretraining strategy optimization.
Pretraining Objectives: MLM and CLM
Masked Language Modeling (MLM) has long dominated the landscape due to its bidirectional attention mechanism which enhances contextual understanding. Traditionally, MLM selectively masks portions of input tokens to challenge the encoder's predictive capability. Conversely, Causal Language Modeling (CLM) employs a sequential token prediction structure harnessing autoregressive techniques, which though less straightforward for representation tasks, offers simpler, deterministic modeling of text sequences.
The paper investigates whether the superior performance often attributed to CLM-trained models is indeed inherent to the causal objective or merely a reflection of confounding factors such as scale of model parameters and data size.
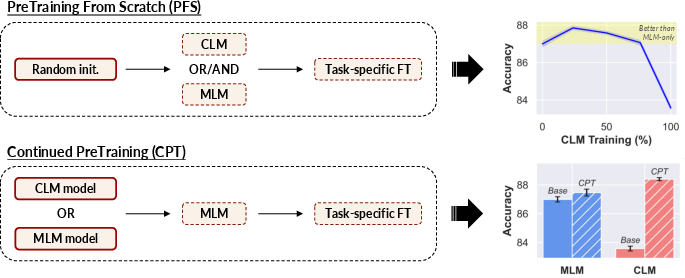
Figure 1: Experimental setup overview and key results on sequence classification (610M model size, 40\% MLM ratio).
Experimental Analysis
Data and Model Architecture
Employing the FineWeb-Edu dataset for a consistent and efficient training regime, the authors utilized a token exposure strategy systematically across models, ensuring evaluations reflect true performance differences rather than data disparities. The model architecture selection embraced EuroBERT-style configurations, with size ranges spanning from 210M to 1B parameters, ensuring nuanced observations of pretraining effectiveness across varying scales.
Findings on MLM Versus CLM
The authors provide compelling evidence that MLM generally outperforms CLM across a breadth of text representation tasks. Notably, models anchored in MLM excel significantly in domains like sequence classification and question answering, where bidirectionality confers stronger contextual embedding. However, CLM showcases notable stability and efficiency in training, suggesting potential benefits in data-scarce environments or during initial model warm-up phases.
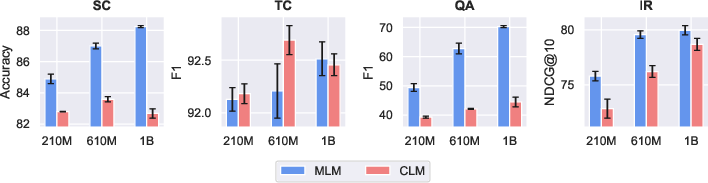
Figure 2: MLM vs. CLM downstream performance, averaged across tasks and reported for all model sizes.
Impact of Masking Ratio
Investigating the sensitivity of MLM to masking ratios, results indicate a marked variance in optimal configurations depending on model size and task. Larger models exhibit a proclivity toward higher masking ratios, enhancing prediction capability without substantial context loss, underscoring the complexity of defining a universal masking strategy.
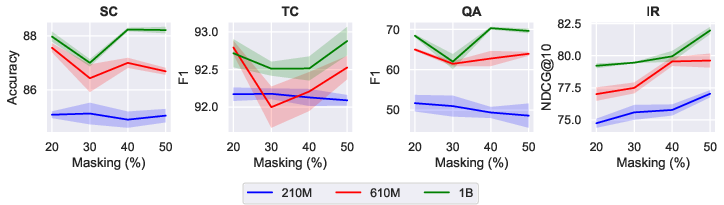
Figure 3: Task-wise downstream performance across different masking ratios for all model sizes.
Two-Stage Pretraining Strategy
A novel biphasic strategy amalgamating CLM followed by MLM emerges from this research, promising enhanced performance under fixed computational budgets. Particularly, this hybrid approach leverages the strengths of causal modeling stability initially, before incorporating the rigorous contextual comprehension MLM provides, thus furnishing a data-efficient pretraining method.
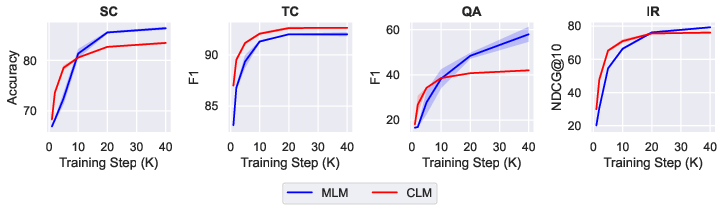
Figure 4: Downstream performance as a function of pretraining steps for CLM and MLM objectives.
Continued Pretraining Experiments
Continued pretraining (CPT) elucidates the advantage of subsequent MLM adaption on models initially trained with CLM, highlighting a strategic trajectory for optimizing pretrained encoders derived from LLMs. This suggests leveraging existing CLM-pretrained checkpoints may offer computational benefits, reducing overhead in training state-of-the-art encoder models.
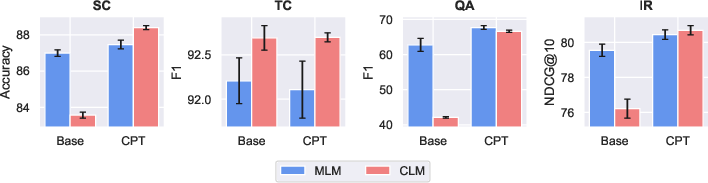
Figure 5: Impact of performing MLM CPT on either CLM- or MLM-pretrained models (denoted as Base).
Conclusion
The examination in "Should We Still Pretrain Encoders with Masked Language Modeling?" champions a reevaluation of entrenched NLP practices. Rather than exclusively relying on MLM, researchers should consider integrating CLM within pretraining protocols, especially in the nascent phases of model training for tasks demanding efficiency and stability.
The findings advocate for adaptive strategies, accommodating task-specific requirements and computational constraints. This work potentially sets the stage for breakthroughs in encoder design, fostering models that are not only robust but also computationally streamlined, a necessary evolution in harnessing the power of large-scale LLMs effectively.
Future areas for exploration are highlighted, including varied linguistic applications, potential cross-domain generalization, and adaptive tuning to maximize pretraining influence in ever-evolving NLP landscapes.