- The paper presents AntLM, a unified model that alternates between causal (CLM) and masked (MLM) objectives to enhance both text generation and comprehension.
- It employs alternating attention masks to combine sequential prediction with bidirectional context, resulting in faster convergence and higher benchmark scores.
- Experimental results on BabyLM Challenge datasets show performance boosts of up to 2.2% over traditional standalone models.
AntLM: Bridging Causal and Masked LLMs
Introduction
The rapid advancements in language modeling have been fueled by the development of Causal LLMs (CLMs) and Masked LLMs (MLMs). CLMs, characterized by their next-token prediction mechanism, are highly effective in generative tasks such as text completion and translation. MLMs, on the other hand, excel in tasks that require robust understanding of global context, such as text classification, by randomly masking tokens and predicting them based on their surrounding context. This paper introduces AntLM, a novel paradigm designed to integrate both CLM and MLM, thereby capitalizing on their strengths and addressing their individual limitations.
Methodology
AntLM adopts a unified model architecture wherein CLM and MLM objectives are alternated during training. This dual objective approach allows the model to harness both sequential and bidirectional information from the text, thereby enhancing its ability to perform both generation and comprehension tasks.
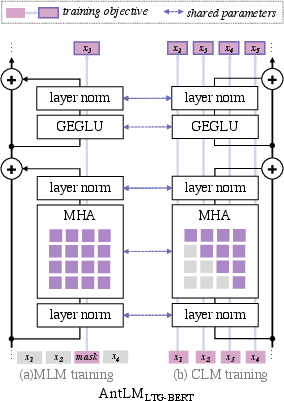
Figure 1: A diagram of AntLMLTG-BERT illustrating the integration of MLM and CLM objectives.
The integration is operationalized through alternating attention masks—causal masks for CLM objectives and bidirectional attention for MLM objectives. This approach is inspired by the multifaceted way humans learn languages, incorporating both predictive and contextual learning strategies.
Experimental Results
The paper evaluates the performance of the proposed AntLM on strict-small track datasets of the BabyLM Challenge 2024, using only 10 million words, mimicking the human learning condition of data scarcity. Experiments demonstrate that AntLM enhances macro-average scores across multiple benchmarks when compared to standalone CLM or MLM models. Specifically, AntLMBabyLlama improved scores by 1%, while AntLMLTG-BERT achieved a 2.2% rise over the baselines.
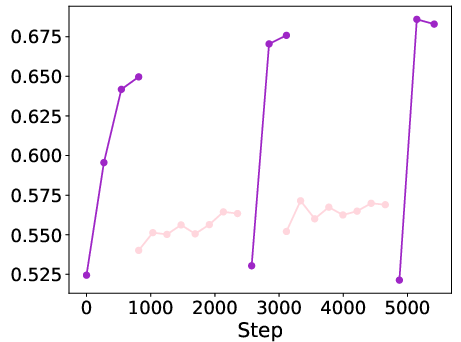
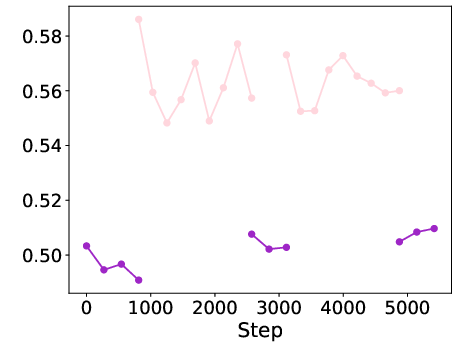
Figure 2: Performance comparison across various benchmarks showcasing the efficacy of AntLM.
One of the key findings is the complementary nature of CLM and MLM objectives, wherein their integration not only maintains robust performance but also speeds up convergence during training phases.
Implications and Future Work
The implications of the AntLM approach are multifaceted. Practically, the integration of CLM and MLM into a single model architecture allows for versatile applications in natural language processing tasks, potentially streamlining and improving the efficiency and effectiveness of LLM training. Theoretically, this research opens avenues for further exploration into hybrid modeling paradigms that capture the nuanced intricacies of human language learning and processing.
Future research could explore variations in the distribution of epochs between CLM and MLM objectives, potentially optimizing performance for specific types of tasks or datasets. Additionally, expansion into multimodal learning frameworks could further emulate the complexity of human cognitive processing, integrating vision and language modeling for more comprehensive AI systems.
Conclusion
AntLM represents a significant step towards more adaptable and efficient LLMs, bridging the methodological divide between sequential prediction and contextual comprehension. The integration of CLM and MLM objectives within a unified framework not only leverages their individual strengths but also provides a model for achieving rapid convergence and robust performance across a spectrum of language tasks. Continuing to refine this approach will likely yield critical insights and advancements in the development of AI systems better aligned with human cognitive processes.

