- The paper proposes a hybrid approach that integrates masked and causal language modeling using masked next-token prediction (MNTP) to enhance model performance.
- The methodology employs dataset duplication and optimized causal-to-masked data ratios to boost training efficiency and model expressivity.
- Experimental results on benchmarks like BLIMP and EWOK demonstrate that GPT-BERT outperforms traditional models, excelling in text generation and in-context learning in low-resource scenarios.
"GPT or BERT: why not both?" (2410.24159)
Introduction
The paper "GPT or BERT: why not both?" proposes a novel approach to LLM architecture by integrating masked language modeling (MLM) with causal language modeling (CLM) within a single transformer stack, termed GPT-BERT. This hybrid approach capitalizes on the strengths of both paradigms, allowing a single model to function effectively in both contexts without additional architectural changes. Through rigorous experimentation, the paper illustrates that this hybrid model outperforms models trained solely on either MLM or CLM objectives, particularly in low-resource scenarios.
Methodology
Hybrid Masked-Causal Language Modeling
The core innovation lies in merging MLM and CLM via a technique termed masked next-token prediction (MNTP). By shifting predictions in MLM one position to the right, alignment is achieved with CLM's next-token prediction framework. This dual functionality is depicted in Figure 1, which illustrates the operation modes of the model.
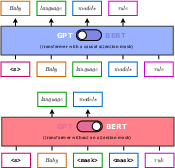
Figure 1: Two modes of a single model - Causal and masked language modeling.
Dataset Handling and Training
A unique aspect of the training procedure involves duplicating datasets to serve both the CLM and MLM objectives, alongside manipulating the causal-to-masked data ratio to optimize learning. The architecture is built upon LTG-BERT with additional modifications such as attention gating and layer weighting, aimed at boosting expressivity and training efficiency.
Experimental Evaluation
BabyLM Challenge 2024
The model evaluation is conducted within the BabyLM Challenge, a controlled environment fostering comparison of LLMs on limited data. Results indicate the superiority of the hybrid approach, especially notable in the STRICT and STRICT-SMALL tracks. Table 1 in the paper provides a detailed comparison of GPT-BERT against baseline and competing models.
Analyzing Causal-to-Masked Ratios
The paper further investigates the impact of varying causal-to-masked ratios, showing significant performance enhancement when even minimal MNTP training is included. This trend suggests that a balanced hybrid approach offers improved expressivity and generalization capabilities.
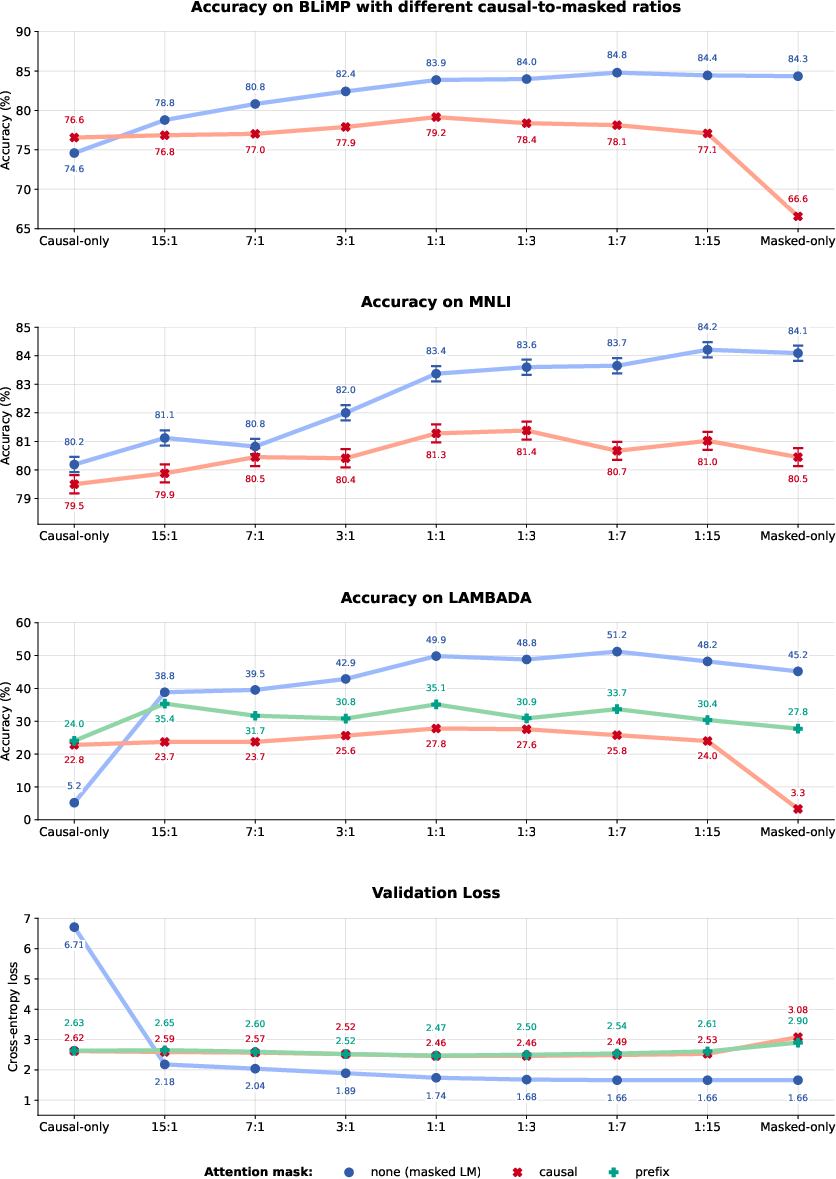
Figure 2: The effect of the causal-to-mask ratio on model performance across different tasks.
Results
The GPT-BERT model demonstrates formidable capabilities in syntactic and semantic tasks, as evidenced by evaluations on benchmarks such as BLIMP and EWOK. It excels in both text generation and in-context learning scenarios, often surpassing traditional models constrained to a single paradigm.
Text Generation
GPT-BERT shows competency in text generation tasks, though it requires mechanisms like repetition penalties to mitigate redundancy in output sequences.
In-Context Learning
Surprisingly, the hybrid model exhibits aptitude for in-context learning, a feature typically associated with larger models, suggesting its robustness despite a moderate parameter count and training data size.
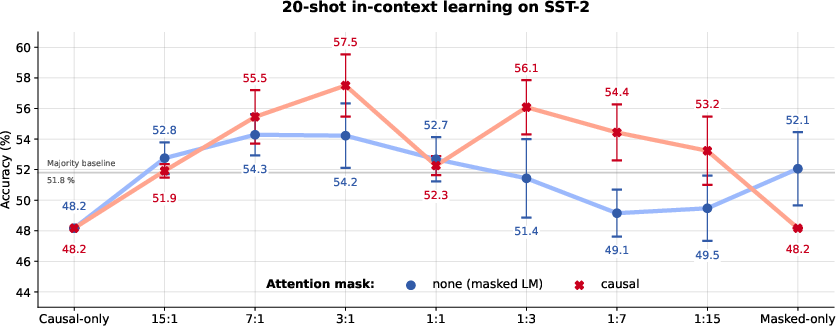
Figure 3: SST-2 in-context learning demonstrating the capability of the hybrid model in few-shot scenarios.
The study positions itself among previous efforts to unify MLM and CLM, distinguishing its approach through simplicity and efficiency. Unlike models such as T5, BART, or GLM which demand architectural adjustments, GPT-BERT achieves unification through straightforward output realignments.
Conclusion
GPT-BERT emerges as a powerful hybrid paradigm, offering several advantages such as enhanced performance, architectural flexibility, and unexpected in-context learning capabilities. The approach challenges the necessity of maintaining a strict separation between MLM and CLM architectures, inviting further exploration into unified modeling strategies.
Implications and Future Work
The findings suggest potential pathways for developing more versatile and resource-efficient LLMs. Future research may explore scaling this approach or applying it to multimodal tasks, given its established versatility.
Through this work, the authors contribute significantly to discourse on LLM architecture, advocating for a balanced, unified strategy that accommodates diverse NLP requirements.