- The paper presents a rigorous scaling-based comparison showing that while decoder-only models yield lower perplexity per parameter, encoder-decoder models excel in low-compute regimes and throughput efficiency.
- The study applies innovations like rotary positional embeddings and continuous position modeling, resulting in smoother context length extrapolation and enhanced performance after instruction tuning.
- Empirical results demonstrate that decoder-only architectures dominate at high compute budgets, yet encoder-decoder models offer competitive downstream performance and superior training and inference efficiency.
Comparative Scaling Analysis of Encoder-Decoder and Decoder-Only Architectures for LLMs
Introduction
This paper presents a rigorous scaling-based comparison between encoder-decoder (RedLLM) and decoder-only (DecLLM) architectures for LLMs, addressing the lack of systematic analysis in prior work. The study adapts recent modeling advances from decoder-only LLMs to the encoder-decoder paradigm, including rotary positional embeddings and continuous position modeling, and employs prefix language modeling for pretraining. Models are trained from scratch on RedPajama V1 (1.6T tokens) and instruction-tuned on FLAN, with sizes ranging from 150M to 8B parameters. The evaluation encompasses scaling laws, compute efficiency, context length extrapolation, and downstream task performance.
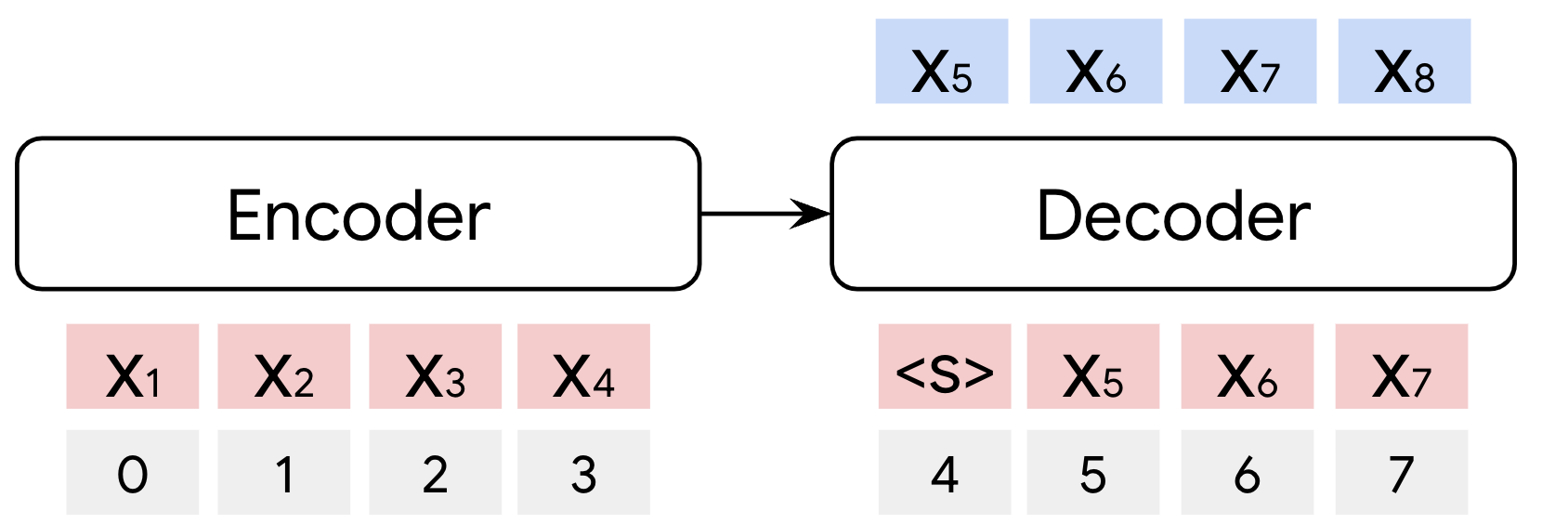
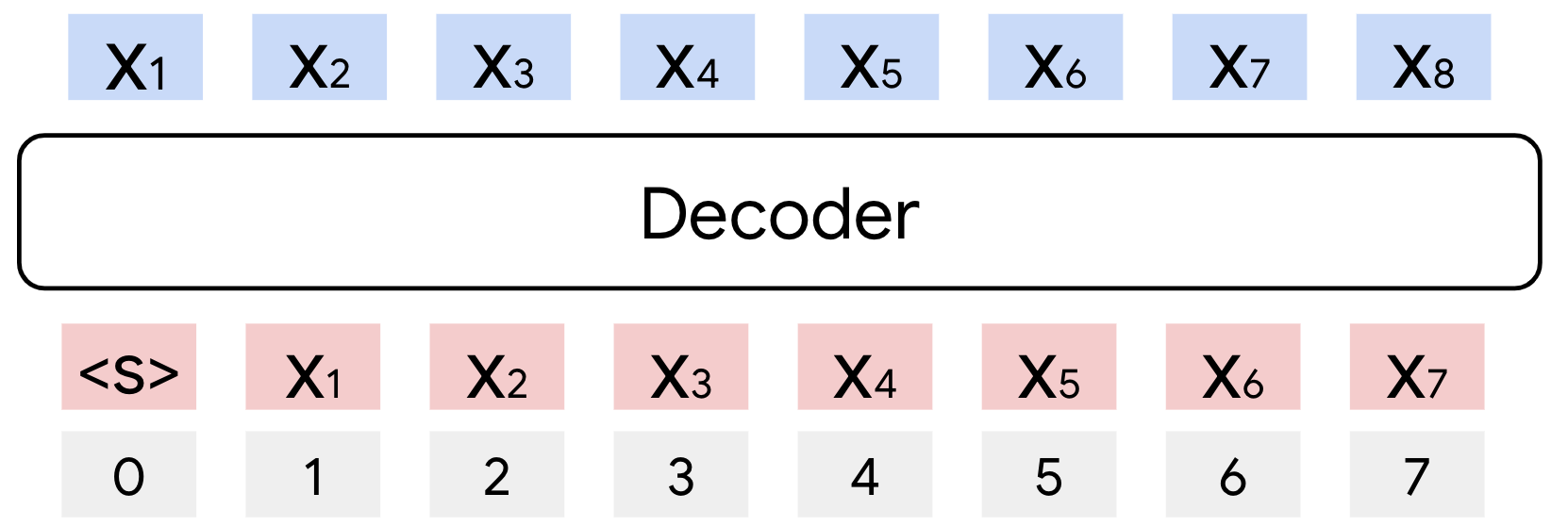
Figure 1: Overview of RedLLM and DecLLM architectures, highlighting attention mechanisms, positional encoding, and normalization strategies.
Model Architectures and Training Setup
RedLLM utilizes a balanced encoder-decoder Transformer architecture, with rotary embeddings applied to all attention mechanisms and continuous positional encoding. The prefix LM objective is used for pretraining, where the input sequence is split into prefix and target segments. DecLLM employs a standard decoder-only Transformer with causal LM objective, rotary embeddings, and additional normalization for training stability. Both models share recent best practices: SwiGLU activations, RMSNorm, tied embeddings, and Adafactor optimization.
Pretraining is performed on RedPajama V1, with sequence lengths of 2048 for DecLLM and 1024/1024 for RedLLM. Instruction tuning uses the FLAN collection, with input/output lengths up to 2048/512. Evaluation covers in-domain (RedPajama) and out-of-domain (Paloma) perplexity, as well as zero/few-shot performance on 13 diverse downstream tasks.
Scaling Laws and Compute Efficiency
The scaling analysis reveals that both RedLLM and DecLLM exhibit similar scaling exponents with respect to model parameters and training FLOPs, indicating comparable scaling capabilities across domains.
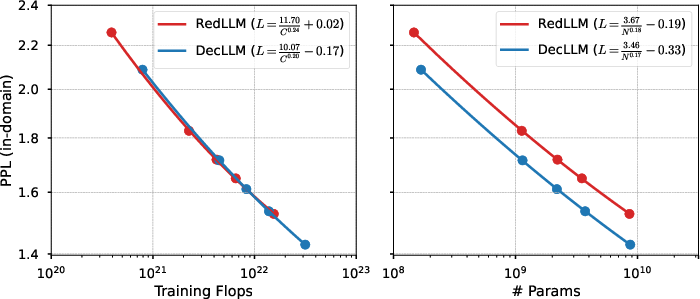
Figure 2: Scaling law fits for RedLLM and DecLLM on in-domain data, showing perplexity as a function of model size and compute.
However, DecLLM consistently achieves lower perplexity for a given parameter count, reflecting higher parameter efficiency. When comparing models at equal compute budgets, the quality gap narrows, and both architectures approach similar performance. Notably, DecLLM dominates the compute-optimal frontier at larger compute scales, while RedLLM shows a slight advantage in low-compute regimes.
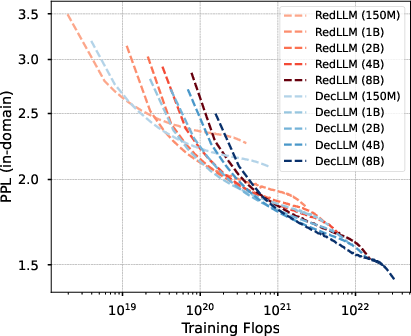
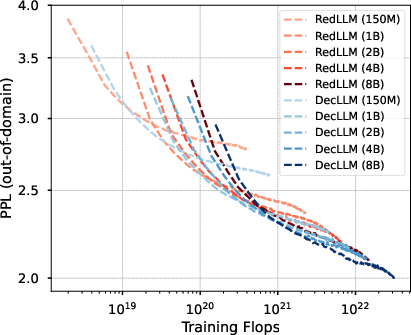
Figure 3: Compute-optimal scaling curves, illustrating that DecLLM dominates at high compute budgets, with RedLLM competitive at lower budgets.
Zero- and few-shot evaluation during pretraining demonstrates a pronounced advantage for DecLLM. RedLLM exhibits poor zero-shot performance and only marginal improvements in few-shot settings as model size increases. This discrepancy persists even when perplexity scores are similar, suggesting that pretraining objective alignment with downstream evaluation is a critical factor.
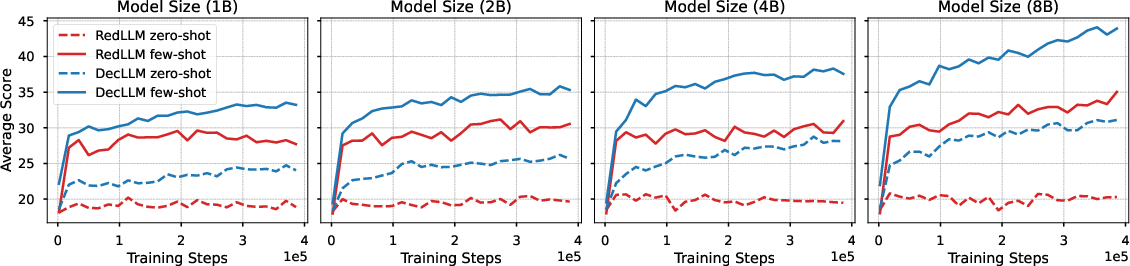
Figure 4: Zero- and few-shot pretraining performance over training steps, highlighting the gap between RedLLM and DecLLM.
Both architectures are evaluated for their ability to extrapolate to longer context lengths than seen during pretraining. DecLLM maintains stable perplexity up to twice the pretraining context length, after which performance degrades rapidly, especially for larger models. RedLLM, in contrast, exhibits a smoother increase in perplexity with context length, indicating more robust extrapolation, though it underperforms DecLLM on shorter sequences.
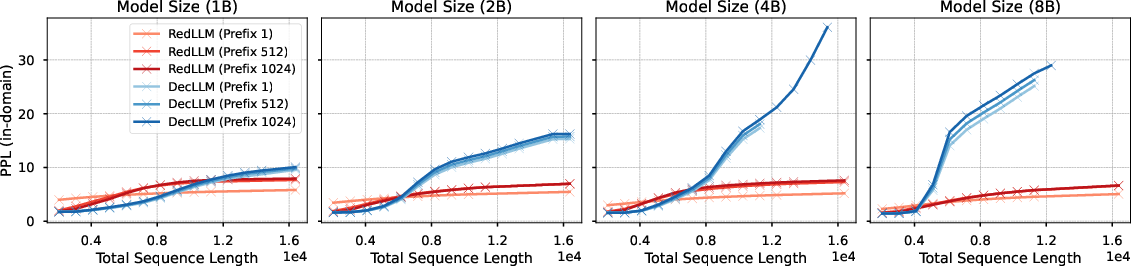
Figure 5: Perplexity curves for context length extrapolation, showing RedLLM's smoother degradation compared to DecLLM.
Further analysis of attention patterns reveals locality decay in self-attention weights for both models, with DecLLM more severely affected. RedLLM's cross-attention mechanism enables diverse input-target dependencies, potentially aiding long-context modeling.
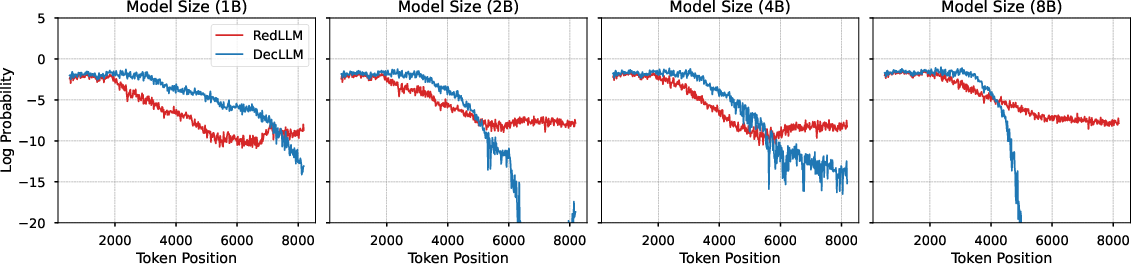
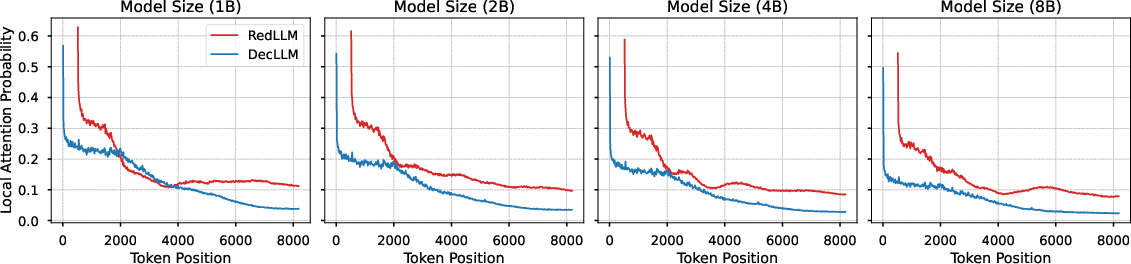
Figure 6: Log probability and local attention probability as functions of token position, demonstrating locality decay and long-context effects.
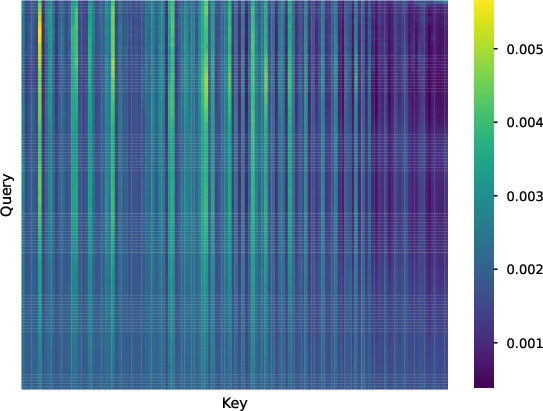
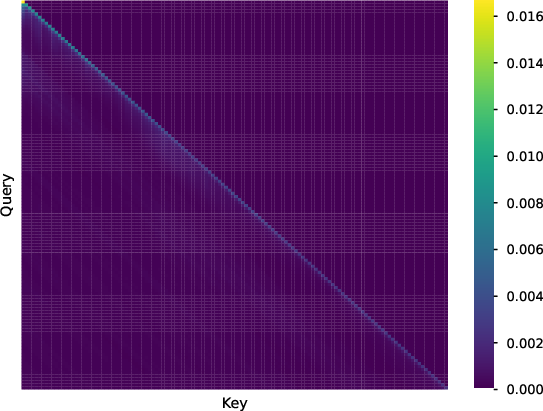
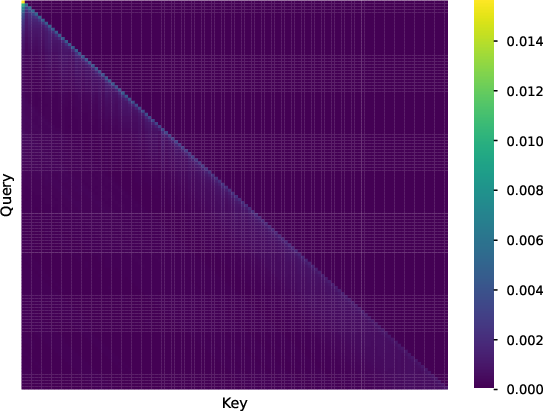
Figure 7: Visualization of attention weights for RedLLM and DecLLM, illustrating differences in self- and cross-attention patterns.
Instruction tuning substantially improves RedLLM's performance, enabling it to match or surpass DecLLM across model scales. When comparing models at equal inference FLOPs, RedLLM nearly dominates the quality-compute Pareto frontier. The gap between zero- and few-shot performance is also reduced post-tuning.
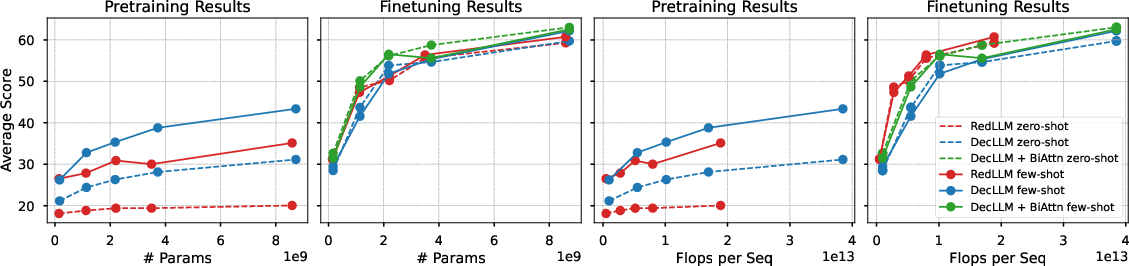
Figure 8: Downstream zero- and few-shot performance as a function of model size and inference FLOPs, with RedLLM showing superior quality-efficiency trade-off.
Enabling bidirectional input attention in DecLLM during finetuning yields significant improvements, particularly in zero-shot settings, but does not alter the overall quality-compute frontier, where RedLLM remains competitive.
Training and Inference Efficiency
Empirical throughput measurements demonstrate that RedLLM processes more examples per second than DecLLM during both training and inference, with the efficiency advantage increasing at larger model sizes. This is attributed to the architectural decomposition and bidirectional encoder attention in RedLLM.
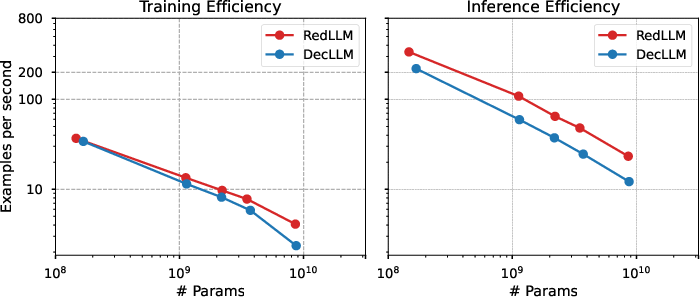
Figure 9: Throughput comparison for training and inference, showing RedLLM's efficiency advantage over DecLLM.
Implications and Future Directions
The findings challenge the prevailing preference for decoder-only architectures in LLM development, highlighting the overlooked potential of encoder-decoder models. RedLLM offers superior efficiency and adaptability after instruction tuning, with competitive scaling and context length extrapolation. The results suggest that architectural choice should be informed by downstream requirements, compute constraints, and efficiency considerations.
Future research should explore RedLLM scalability beyond 8B parameters, investigate imbalanced encoder-decoder configurations, and analyze alternative pretraining objectives. A deeper understanding of long-context modeling and attention dynamics in encoder-decoder LLMs is warranted.
Conclusion
This study provides a comprehensive scaling-based comparison of encoder-decoder and decoder-only LLM architectures. While decoder-only models excel in compute-optimal pretraining and zero/few-shot learning, encoder-decoder models demonstrate superior efficiency and downstream adaptability after instruction tuning. The results underscore the importance of revisiting encoder-decoder architectures for efficient and powerful LLM development, with significant implications for future model design and deployment strategies.

