- The paper introduces replaced token detection, where a discriminator distinguishes replaced tokens, offering improved computational efficiency over traditional MLM.
- It employs a generator-discriminator framework that alleviates pre-train fine-tune discrepancies by eliminating the use of [MASK] tokens in downstream tasks.
- Experiments on benchmarks like GLUE and SQuAD demonstrate that ELECTRA outperforms comparable models, with smaller variants gaining up to 5 points in accuracy.
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
Introduction
The paper "ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators" (2003.10555) introduces a novel approach to pre-training text encoders that contrasts with traditional masked language modeling (MLM) tasks used in models such as BERT. While MLM replaces certain input tokens with the [MASK] symbol and predicts the masked tokens' identities, ELECTRA modifies this by training a model to discriminate between tokens that were part of the original input and those replaced by a generator model. This approach, termed replaced token detection, enhances computational efficiency as it operates over all tokens in the input sequence, unlike MLM which focuses on a subset of tokens.
Methodology
ELECTRA comprises two components: a generator and a discriminator. The generator, typically a small masked LLM, suggests plausible token replacements, while the discriminator identifies if a token in the corrupted sequence was replaced. This setup resembles a GAN structure, but ELECTRA avoids adversarial training for the generator due to challenges with textual data (Figure 1).
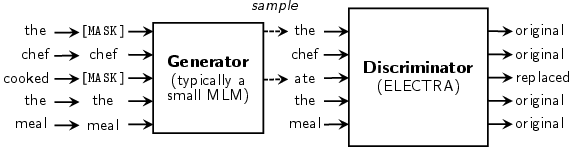
Figure 1: An overview of replaced token detection.
Training is conducted by initially corrupting the input sequence using the generator and then fine-tuning the discriminator, which will be used for downstream tasks. Importantly, this method circumvents the pre-train fine-tune discrepancy found in BERT, where [MASK] tokens do not appear during fine-tuning stages.
Experiments and Results
The utility of ELECTRA is demonstrated through extensive experiments against benchmarks like GLUE and SQuAD. These show that ELECTRA not only reduces the computational requirements compared to models such as BERT and XLNet but achieves higher accuracy with the same compute budget, particularly in smaller models. Remarkably, ELECTRA-Small outperformed a comparable BERT model on GLUE by 5 points, and even surpassed the much larger GPT model (Figure 2).
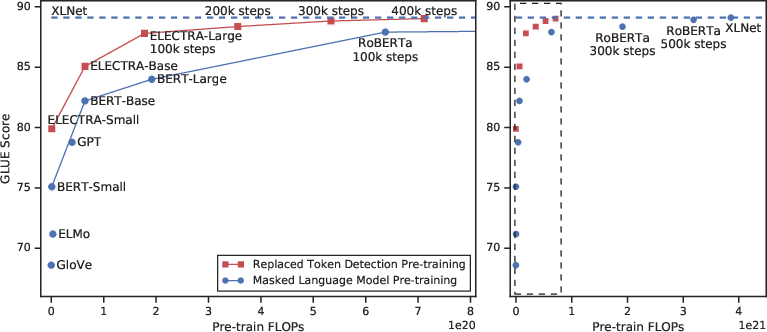
Figure 2: Replaced token detection pre-training consistently outperforms masked LLM pre-training given the same compute budget.
Large-scale experiments further reveal that ELECTRA maintains high performance while being compute-efficient. For example, ELECTRA-Large was competitive with RoBERTa and XLNet, despite using a fraction of the computational resources. These findings indicate the discriminator's effectiveness at extracting rich contextual representations beyond those derived through generative tasks.
Model Extensions
To optimize performance, several modifications to the ELECTRA framework are evaluated. These include weight sharing between generator and discriminator, smaller generators, and alternative training algorithms. ELECTRA benefits notably from shared token embeddings between generator and discriminator and achieves optimal performance with generators significantly smaller than the discriminator (Figure 3).
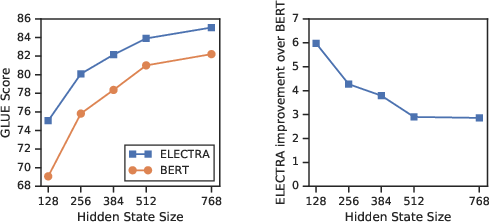
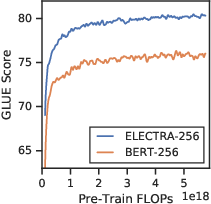
Figure 3: GLUE scores for different generator/discriminator sizes.
Implications and Future Directions
ELECTRA's approach holds significant implications for the development of efficient NLP models. By minimizing compute while maximizing accuracy, it broadens access to powerful language representations without prohibitive computational costs. Future work could explore extensions such as auto-regressive generators and cross-modal applications to other data forms.
Conclusion
The paper provides a compelling case for reconsidering the paradigm of pre-training text encoders. By positioning token replacement detection as a central task, ELECTRA achieves a delicate balance between computational efficiency and task performance. This research advocates for efficiency metrics as critical alongside absolute performance, setting a precedent for future language representation learning endeavors.