- The paper demonstrates that multi-agent reinforcement learning frameworks significantly improve LLM meta-thinking and self-assessment capabilities.
- The paper details how supervisor-agent architectures and RL techniques mitigate hallucinations to boost factual consistency in outputs.
- The paper outlines tailored evaluation metrics and benchmarks to measure logical consistency, error correction, and multi-step reasoning in LLMs.
This essay provides an expert summary of the paper "Meta-Thinking in LLMs via Multi-Agent Reinforcement Learning: A Survey" (2504.14520), focusing on bridging the current research gaps in developing and evaluating meta-thinking capabilities in LLMs within a Multi-Agent Reinforcement Learning (MARL) framework.
Introduction
The investigation into the cognitive faculties of intelligence and creativity has long been a subject of psychological research, and its implications are vast for the development of AI systems. Traditional LLMs, such as GPT-3, have demonstrated capability across diverse applications, including NLP, but remain deficient in tackling high-stakes operations where precision and reliability are non-negotiable. The prevalent "hallucination" issue in LLMs—where models generate inaccurate or false content—is a significant barrier that undermines trust in AI systems, particularly in critical fields like healthcare and law. Existing methods, such as RL from human feedback (RLHF), self-distillation, and chain-of-thought (CoT) prompting, provide incremental improvements but have limitations in abstraction, self-assessment, and domain specificity. Recent research emphasizes the significance of imbibing meta-thinking capabilities—self-reflection, evaluation, and optimization of internal processes. Utilizing multi-agent systems like supervisor-agent hierarchies, agent debates, and theory of mind (ToM) constructs, the study explores potential architectures for Meta-Thinking Leveraging Reward Mechanisms and Continuous Learning Methods.
Current Limitations of LLMs
Despite their sophisticated text generation capabilities, LLMs face substantial challenges, most notably hallucinations that result in generation errors such as input, context, and factual conflicts. They often lack intrinsic evaluation mechanisms, which leads to unchecked errors borne out of autoregressive generation processes. These limitations indicate the necessity for developing a meta-thinking framework to enhance robustness and introspective self-regulatory capacity within LLMs through MARL.
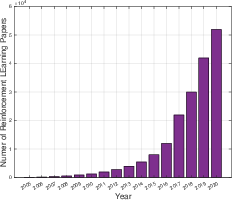
Figure 1: Annual number of RL publications in AI conferences (2019–2024).
A taxonomy of approaches aimed at fostering meta-thinking capacities in LLMs includes single-agent reflective mechanisms, multi-agent reinforcement learning-based frameworks, and other emerging paradigms in self-improvement. Single-agent methods, such as self-distillation and reflective prompting, enable iterative self-assessment but risk reinforcing inherent biases and errors due to echo-chamber effects.
Multi-Agent Reinforcement Learning (MARL) Systems
Within multi-agent configurations, supervisor-agent architectures organize reasoning tasks through smaller agent collaboration, using high-level strategies such as agent debates, adversarial training, or cooperative problem-solving to emulate human-like reasoning. For instance, the "supervisor-agent" model assigns various reasoning tasks to specialized agents, [e.g., FAMA or Co-NavGPT], who use ToM to adaptively learn from shared feedback.

Figure 2: The diagram illustrates a multi-agent system where a high-level agent breaks down tasks and communicates with low-level agents to execute them.
Implementing RL, and more specifically RLHF, provides a promising methodology for remedying hallucination through both intrinsic and extrinsic feedback signals that prioritize coherence, logic, and factuality in outputs. By continuously optimizing a policy distribution πθ(at∣st) to maximize the expected cumulative return:
θ∗=argθmaxEπθ[t=0∑Tγt(λrte+(1−λ)rti)],
LLMs become self-improving learners with more reliable outputs adopting human-like reflective practices.
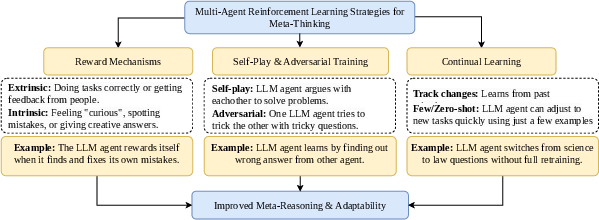
Figure 3: Overview of RL Techniques Enabling Meta-Thinking in LLMs
Evaluation Metrics and Datasets
Metrics developed to assess meta-thinking capabilities discern logical consistency, error localization, self-correction proficiency, and reasoning depth. These metrics assess whether an LLM can remain consistent with constraints, pinpoint inconsistencies, and maintain multi-step logical coherence.
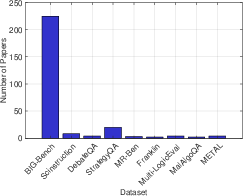
Figure 4: Number of published papers referencing each dataset for evaluating LLM meta-reasoning.
\indent The field benefits from a constellation of tailored benchmarks centering on measuring meta-reasoning such as BIG-Bench, SciInstruct, and DebateQA. These datasets provide challenging scenarios involving contentious questions, chain-of-reasoning assessments, and structured reasoning tasks that require models to reveal Theoretical vs. applied reasoning proficiency levels as highlighted.
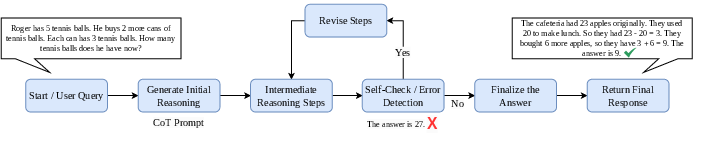
Figure 5: A COT flowchart demonstrating meta-thinking enhancement in LLMs via structured reasoning steps.
Challenges and Open Problems
Significant challenges in optimizing LLM meta-thinking capabilities through MARL include computational and energy burdens associated with multi-agent architecture scalability, rewards design, autonomous adaptation, and energy efficiency. Moreover, ethical concerns such as potential biases in reward signals require rigorous frameworks to ensure safe, responsible, and fair AI reasoning protocols.
Conclusion
The integration of meta-thinking in LLMs via MARL represents a compelling step forward in AI research. As highlighted in this survey, evolving technologies and methodologies such as Agent-Based debate, self-critique, and meta-learning showcase promise in creating self-correcting AI that perpetually refines its cognitive strategies. Nonetheless, addressing scalability, stability, energy efficiency, and ethical concerns remains imperative in this pursuit. Inspired by human cognition and leveraging hybrid symbolic-MARL systems for interpretability, future advancements will no doubt set the context for developing introspective, reliable, and adaptive AI systems, unlocking broader applicability in dynamic, high-stakes environments.

