- The paper introduces reinforced reasoning techniques that combine train-time and test-time scaling to improve the cognitive abilities of LLMs.
- It details automated data construction and search algorithms, like Monte Carlo Tree Search, for generating and optimizing reasoning trajectories.
- It outlines reinforcement learning frameworks and benchmarking methods essential for evaluating advanced reasoning performance in LLMs.
Towards Large Reasoning Models: A Survey of Reinforced Reasoning with LLMs
Introduction
The paper explores the emerging field of large reasoning models, focusing on the development and enhancement of reasoning processes in LLMs through reinforced reasoning techniques. The survey provides a comprehensive overview of recent advancements, emphasizing the role of Reinforcement Learning (RL) in augmenting LLMs' reasoning capabilities. The authors introduce fundamental concepts related to reasoning with LLMs, discussing the transition from simple autoregressive token generation to more complex human-like reasoning processes, such as tree search and reflective thinking.
Background on LLMs
LLMs, built primarily on the Transformer architecture, have demonstrated remarkable capabilities in natural language processing, code generation, and other domains. Recent breakthroughs highlight the emergent abilities of LLMs, unveiling potential applications beyond traditional language tasks. The neural scaling law emphasizes that as model size and training data increase, performance improves significantly, leading to the discovery of in-context learning and analogical reasoning abilities.
Learning to Reason
Reinforced reasoning within LLMs is driving the development of large reasoning models by leveraging RL techniques. This approach transforms the training paradigm from supervised learning to RL, enabling the generation of high-quality reasoning trajectories through trial-and-error search algorithms. The key challenge addressed is the scarcity of training data with reasoning trajectories, which RL techniques help overcome by automating data construction and optimizing reasoning processes during training.
Test-Time Scaling
Encouraging LLMs to "think" explicitly during test-time inference is highlighted as a method to boost reasoning accuracy. Test-time scaling law suggests that allowing LLMs to generate more tokens during inference significantly enhances their reasoning capabilities. The combination of train-time and test-time scaling presents a promising path towards developing Large Reasoning Models, epitomized by OpenAI's o1 series.
Data Construction for Reasoning
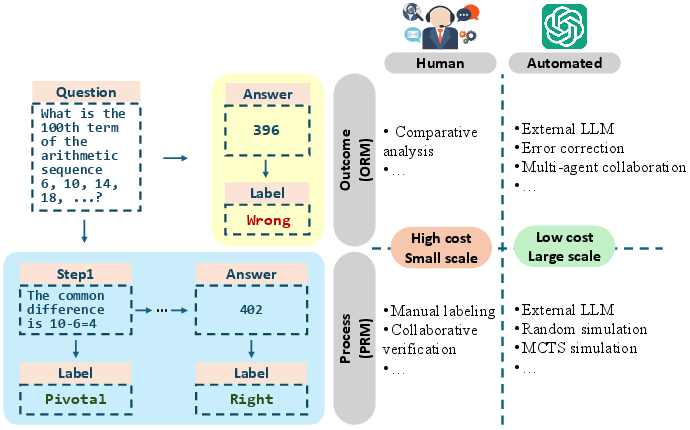
Figure 1: Illustrating different paradigms for annotating LLM reasoning data.
The survey discusses the transition from human annotation to automated data construction using LLMs and search algorithms. Manual annotation is costly and limited by scale, whereas automated methods using LLMs offer scalability and cost-effectiveness. The paper highlights methodologies that employ automated Monte Carlo Tree Search (MCTS) to generate reasoning trajectories, thus reducing reliance on human annotation.
Reinforcement Learning Frameworks
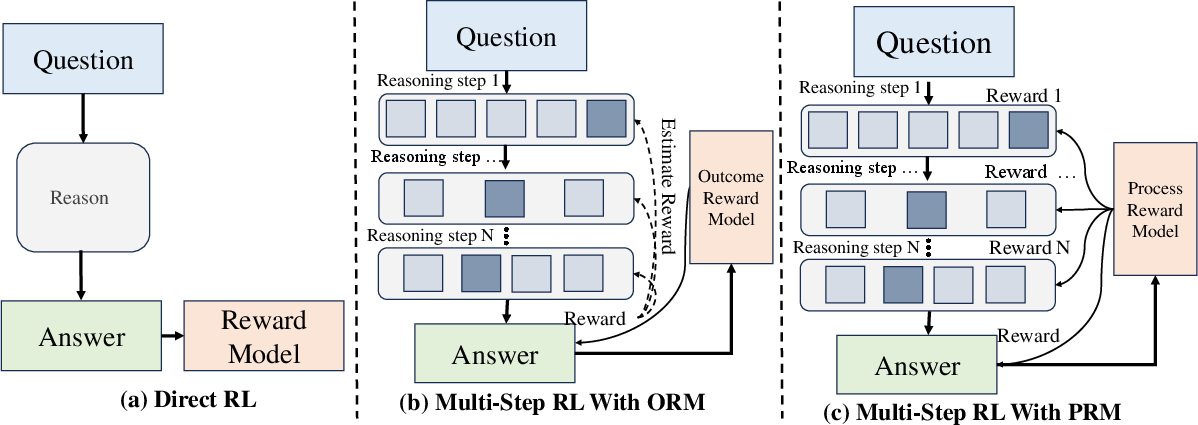
Figure 2: Reward models for Train-time Reinforcement of LLM Reasoning.
Key RL techniques, including RL from human feedback (RLHF) and Direct Preference Optimization (DPO), have been employed to train LLMs to align with human preferences. The integration of reward models allows for nuanced feedback that enhances LLMs' reasoning capacity. The survey emphasizes the use of Process Reward Models (PRMs) that provide dense, step-wise rewards, facilitating RL for LLM reasoning and improving train-time scaling.
Search Algorithms for Test-Time Reasoning
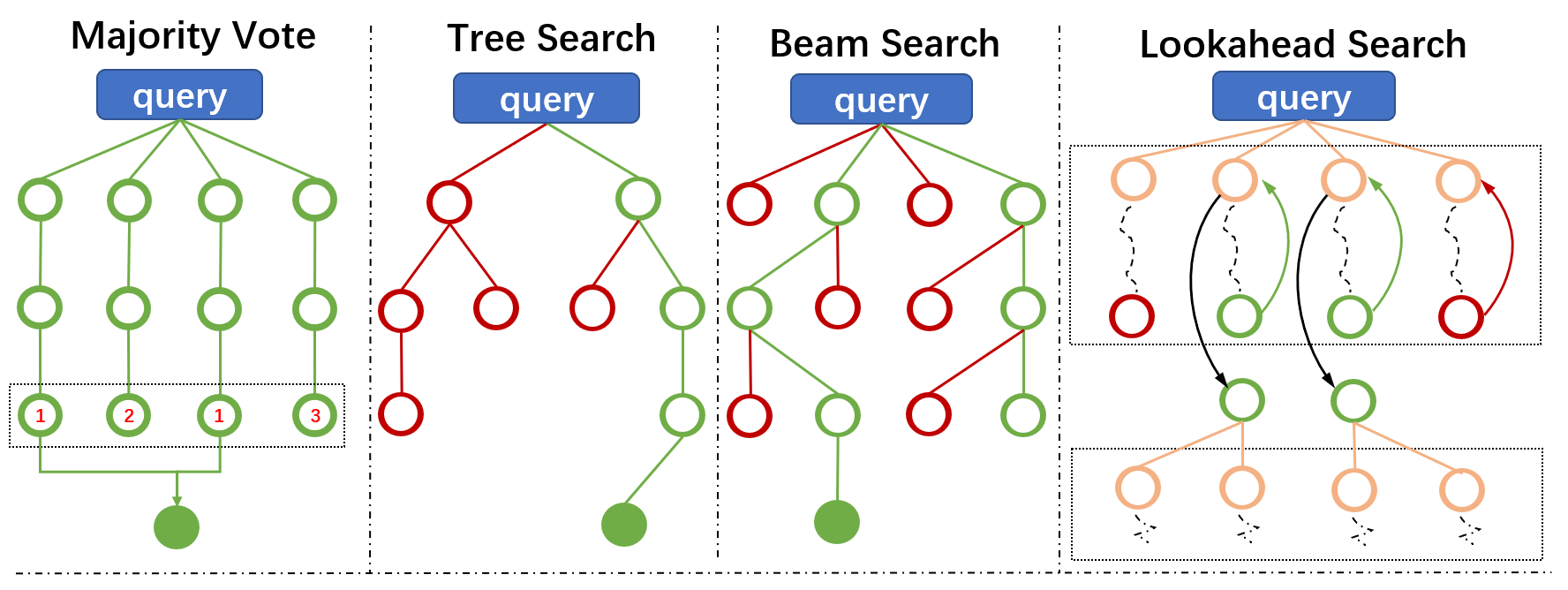
Figure 3: Diagrams of Different Search Algorithms for Test-time Reasoning Enhancement.
The deployment of search algorithms during test-time inference is crucial for improving reasoning accuracy. Techniques such as Monte Carlo Tree Search and Beam Search enable LLMs to efficiently explore reasoning pathways, guided by search-based methods. These algorithms provide effective strategies for optimizing LLMs' reasoning abilities by allowing them to spend more tokens during inference.
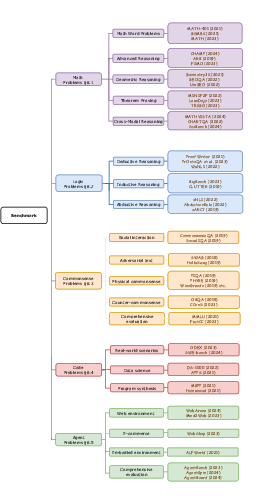
Figure 4: A Taxonomy for LLM Reasoning Benchmarks.
The paper discusses the challenges in benchmarking LLM reasoning, proposing a taxonomy for evaluating reasoning capabilities across tasks. Popular benchmarks incorporate mathematical, logical, and commonsense reasoning, providing systematic evaluations of LLMs' cognitive abilities. These benchmarks serve as valuable tools for assessing and enhancing reasoning performance in LLMs.
Future Directions
The paper concludes by identifying open challenges and future research directions in the development of large reasoning models. Integrating reasoning capabilities with LLM-driven agents to create autonomous systems capable of decision-making and problem-solving in complex environments represents a key area for future exploration. Additionally, hybrid models that combine search techniques with train-time reinforcement learning offer promising avenues for further enhancing LLM reasoning capabilities.
Conclusion
The survey underscores the significant progress towards large reasoning models, highlighting reinforced reasoning as a transformative approach to enhance LLMs' cognitive abilities. Through a combination of train-time and test-time scaling, automated data construction, and search algorithms, LLMs are poised to become more sophisticated reasoning entities, capable of tackling real-world challenges with human-like cognitive processes.