- The paper introduces a three-dimensional framework for LLM agent design, covering agent construction, collaboration, and evolution.
- It systematically examines methodologies from memory mechanisms and planning to action execution in multi-agent environments.
- The survey highlights practical challenges in security, privacy, and ethical concerns while mapping future directions for effective multi-agent collaboration.
LLM Agent Survey: Methodologies, Applications, and Challenges
This survey paper (2503.21460) provides a structured taxonomy for understanding LLM agents, examining their methodologies, applications, and challenges. It synthesizes fragmented research threads by revealing connections between agent design principles and their emergent behaviors in complex environments. The survey adopts a methodology-centered approach, deconstructing LLM agent systems through architectural foundations, collaboration mechanisms, and evolutionary pathways.
Agent Methodology
The paper introduces a three-dimensional framework for understanding LLM-based agent systems: construction, collaboration, and evolution (Figure 1). Agent construction involves profile definition, memory mechanisms, planning capabilities, and action execution. Collaboration paradigms enable multiple agents to work together through centralized control, decentralized cooperation, or hybrid architectures. Evolution mechanisms allow agents to improve over time through autonomous optimization, multi-agent co-evolution, and external resource integration.
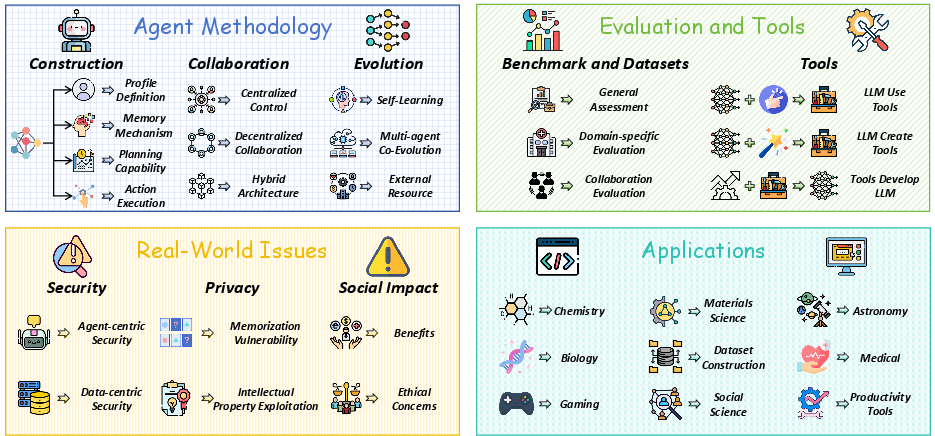
Figure 1: An overview of the LLM agent ecosystem organized into four interconnected dimensions: Agent Methodology, Evaluation and Tools, Real-World Issues, and Applications.
Agent Construction
Agent construction involves designing core components that enable goal-directed behaviors, focusing on profile definition, memory mechanisms, planning capabilities, and action execution.
Profile Definition
Profile definition establishes an agent's operational identity by configuring its intrinsic attributes and behavioral patterns. Methodologies include human-curated static profiles and batch-generated dynamic profiles, which collectively govern an agent's decision boundaries and interaction protocols.
Memory Mechanism
Memory mechanisms equip agents with the ability to store, organize, and retrieve information across temporal dimensions. Short-term memory maintains transient contextual data, while long-term memory preserves structured experiential knowledge. Integrating knowledge retrieval mechanisms optimizes information accessibility using Retrieval-Augmented Generation (RAG) techniques.
Planning Capability
Planning capabilities are essential for LLM agents to navigate complex tasks and problem-solving scenarios. Planning involves task decomposition strategies and feedback-driven iteration, enabling agents to handle diverse and complex scenarios.
Action Execution
Action execution involves tool utilization and physical interaction, enabling agents to execute planned actions in the real world. Tool utilization includes tool-use decision and tool selection, while physical interaction requires agents to perform specific actions and interpret environmental feedback.
Agent Collaboration
Collaboration among LLM agents extends their problem-solving capabilities beyond individual reasoning. Collaboration paradigms include centralized control, decentralized cooperation, and hybrid architectures, each offering distinct advantages for specific application scenarios.
Centralized Control
Centralized control architectures employ a hierarchical coordination mechanism, where a central controller organizes agent activities through task allocation and decision integration. Implementations include explicit controller systems and differentiation-based systems.
Decentralized Collaboration
Decentralized collaboration enables direct node-to-node interaction through self-organizing protocols, categorized into revision-based systems and communication-based systems. These systems allow agents to directly engage in dialogues and observe peers' reasoning processes.
Hybrid Architecture
Hybrid architectures combine centralized coordination and decentralized collaboration to balance controllability with flexibility and adapt to heterogeneous task requirements. Implementations include static systems with predefined coordination rules and dynamic systems featuring self-optimizing topologies.
Agent Evolution
LLM agents evolve through autonomous improvement, multi-agent interaction, and external resource integration. Key dimensions include autonomous optimization and self-learning, multi-agent co-evolution, and evolution via external resources.
Autonomous Optimization and Self-Learning
Autonomous optimization and self-learning allow LLMs to improve their capabilities without extensive supervision through self-supervised learning, self-reflection, and self-correction mechanisms.
Multi-Agent Co-Evolution
Multi-agent co-evolution enables LLMs to improve through interactions with other agents, involving cooperative learning and competitive co-evolution.
Evolution via External Resources
External resources enhance agent evolution by providing structured information and feedback through knowledge-enhanced evolution and external feedback-driven evolution.
Robust evaluation frameworks and specialized tools have become essential components of the agent ecosystem. Benchmarks, datasets, and tools enable the development, assessment, and deployment of LLM agents, covering general assessment frameworks, domain-specific evaluation systems, and collaborative evaluation approaches (Figure 2). The tools ecosystem includes tools used by LLM agents, tools created by agents themselves, and infrastructure for deploying agent systems.
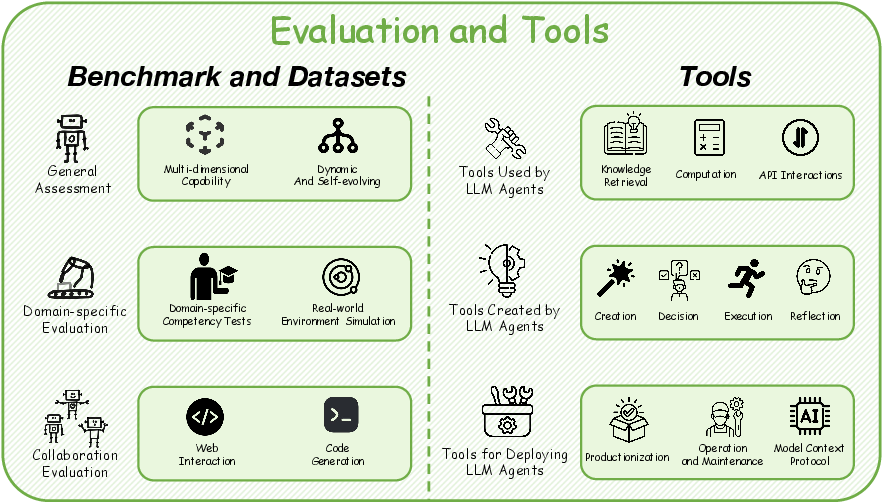
Figure 2: An overview of evaluation benchmarks and tools for LLM agents, including assessment frameworks and development tools.
Real-World Issues
LLM agents bring forth significant real-world challenges categorized into security, privacy, and social impact (Figure 3). Security concerns encompass agent-centric and data-centric threats. Privacy issues include memorization vulnerabilities and intellectual property exploitation. Ethical considerations and social implications include potential benefits and risks to society.
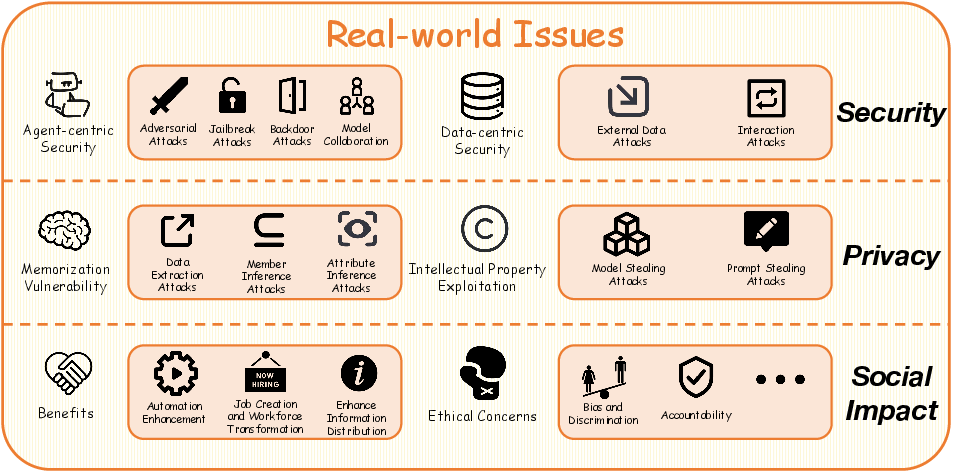
Figure 3: An overview of real-world issues in LLM agent systems, including security, privacy, and social impact considerations.
Security
Agent-centric security involves defending against attacks on agent models, while data-centric security focuses on preventing the contamination of input data. Key areas include adversarial attacks, jailbreaking attacks, backdoor attacks, and model collaboration attacks.
Privacy
Privacy issues involve LLM memorization vulnerabilities and intellectual property exploitation, such as model theft and prompt theft. Protective measures include data cleaning, differential privacy, and knowledge distillation.
Social Impact and Ethical Concerns
LLM agents offer benefits such as automation enhancement, job creation, and enhanced information distribution but also raise ethical concerns, including bias in decision-making, misinformation propagation, and accountability issues.
Applications
LLM agents have been adopted across diverse domains, from scientific discovery to gaming, social science, and productivity tools. These applications demonstrate how integrating LLM-based agent systems enhances problem-solving through specialized knowledge application, multi-agent collaboration, and human-AI interaction.
Scientific Discovery
LLM-based multi-agent systems are increasingly applied across scientific disciplines to emulate human collaborative workflows and tackle complex, interdisciplinary problems, enhancing scientific dataset construction and accelerating medical applications.
Gaming
LLM agents in gaming enable diverse roles and human-like decision-making skills in intricate game environments through game playing and game generation.
Social Science
In social science, LLM agents are utilized to model complex human behaviors and interactions, facilitating insights into economics, psychology, and social simulation.
LLM agents boost productivity by automating diverse tasks and optimizing efficiency across domains such as software development and recommender systems.
Challenges and Future Trends
Advancements in LLM-based multi-agent systems present challenges in scalability, memory, reliability, and evaluation. Key future trends include hierarchical structuring, decentralized planning, robust communication protocols, efficient scheduling mechanisms, knowledge-graph-based verification, and standardized AI auditing frameworks.
Conclusion
This survey provides a systematic taxonomy of LLM agents, deconstructing their methodological components and offering a unified architectural perspective. While significant challenges remain, transformative developments in coordination protocols, hybrid architectures, and safety mechanisms are anticipated to enhance agent capabilities across diverse domains. The paper contributes to the responsible advancement of LLM agent technologies that may fundamentally reshape human-machine collaboration.

