- The paper presents a comprehensive survey categorizing diverse strategies to enhance MLLM interpretability through data handling, model architecture, and training processes.
- It details methods such as perturbation, saliency analysis, and causal inference to dissect multimodal input-output relationships and benchmark trustworthiness and robustness.
- It analyzes model introspection techniques including token, neuron, and layer interpretability, and evaluates design modifications for transparent and reliable inference.
Explainable and Interpretable Multimodal LLMs: A Comprehensive Survey
The paper "Explainable and Interpretable Multimodal LLMs: A Comprehensive Survey" explores the complexities and challenges involved in making Multimodal LLMs (MLLMs) interpretable and explainable. It categorizes the strategies for enhancing interpretability along dimensions of data handling, model architecture, and training/inference processes.
Data Handling
The interpretability of MLLMs begins at the data level, where the integration of diverse modalities — text, images, video, and audio — necessitates innovative methods to align and represent input-output relationships. The paper discusses various approaches:
- Input and Output Analysis: Techniques like perturbation, saliency maps, and causal inference are employed to dissect how models process inputs and generate outputs, shedding light on critical features and decision pathways.
- Benchmarks and Datasets: Emphasizing the need for standardized benchmarks, the survey identifies the significance of datasets that evaluate models on aspects like trustworthiness, robustness, and fairness, which are integral to real-world applicability.
- Application Domains: Beyond traditional vision-language tasks, the paper discusses methods deployed in domains such as autonomous driving, medicine, and robotics, where interpretability is crucial for safety and ethical deployment.
Model Architecture
Model interpretability is addressed through detailed analyses of internal structures:
- Token and Embedding Interpretability: It covers the importance of understanding how visual and textual tokens are utilized by models, complemented by embedding-level interpretability that evaluates how multi-modal representations are constructed.

Figure 1: Overview of our framework. The framework illustrates how input modalities like images, videos, or audio are tokenized into visual or textual tokens and then transformed into embeddings.
- Neuron and Layer Interpretability: This involves examining the roles of individual neurons and layers. Researchers leverage techniques such as network dissection and probing to elucidate how specific components contribute to model behavior.
- Architecture Design and Analysis: The survey describes various methodological categories such as uni-modal and multi-modal explanations, interactive explanations, and methods leveraging simplified surrogate models to enhance interpretability.
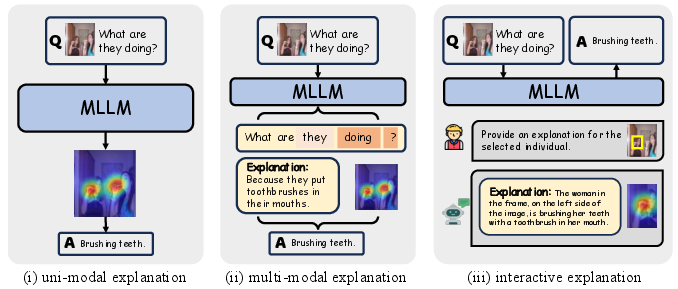
Figure 2: Architecture Analysis. We classify architecture analysis methods into three types: uni-modal, multi-modal, and interactive explanations, based on explanation modalities and control signal acceptance.
- Design for Explainability: Adjusting model architectures through methods like concept-based and auxiliary models to inherently improve interpretability without explicit explantory outputs.
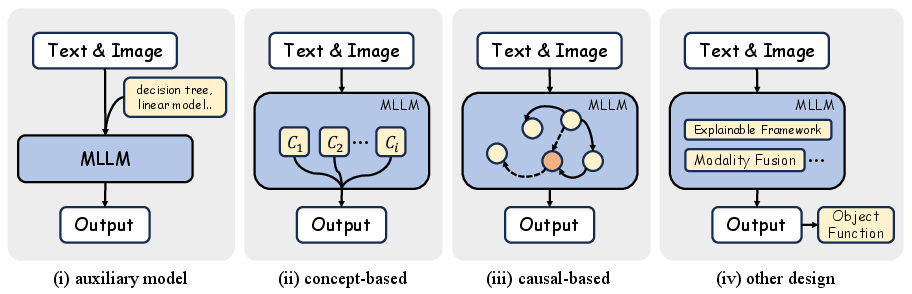
Figure 3: Architecture Design. This category focuses on modifying modules to improve explainability without generating explicit explanations.
Training and Inference
Training and inference processes also play vital roles in enhancing MLLM interpretability:
- Training Dynamics: Methods such as pre-training refinement, fine-tuning for task alignment, and reducing hallucination through reinforced learning frameworks like RLHF, are explored to yield more interpretable and consistent outputs.
- Inference Techniques: The paper discusses advanced methods such as Chain-of-Thought (CoT) reasoning and multimodal in-context learning (ICL) which aim to render machine reasoning transparent and safe for deployment, minimizing hallucination risks without necessitating retraining.
Conclusion
The survey provides a structured analysis of existing strategies to enhance the interpretability and explainability of MLLMs, aiming to guide future research towards developing robust, transparent, and reliable AI systems. As MLLMs continue to impact diverse applications, understanding and refining these models' interpretability will be crucial for their ethical and effective use in complex, high-stakes environments.