Bridging the Language Divide in Large Language Models
This presentation explores the multilingual capabilities and challenges of Large Language Models through a comprehensive survey of training paradigms, inference strategies, security vulnerabilities, and real-world applications. We examine how researchers are working to close the performance gap between high-resource and low-resource languages, the innovative techniques being developed for multilingual processing, and the critical issues of bias, fairness, and security that must be addressed to achieve truly language-fair AI systems.Script
Large language models have revolutionized natural language processing, yet they harbor a profound inequality: they excel in English while stumbling in most of the world's languages. This survey reveals where the gaps are and what researchers are doing to bridge them.
The inequality isn't subtle. These models can write poetry in English but fail at basic comprehension tasks in languages like Swahili or Tagalog. The root cause is data scarcity and insufficient training in low-resource languages.
Researchers are attacking this problem from two directions: building multilingual models from the ground up, or adapting existing ones.
Training from scratch with models like XLM gives you control but demands massive datasets. Continual training on models like Chinese LLaMA is cheaper and faster, but you risk the model forgetting what it already knew.
How you ask the question matters as much as the model itself. Chain of Thought prompting works better in English even for non-English tasks. Retrieval augmented generation helps fill knowledge gaps, especially where training data was thin.
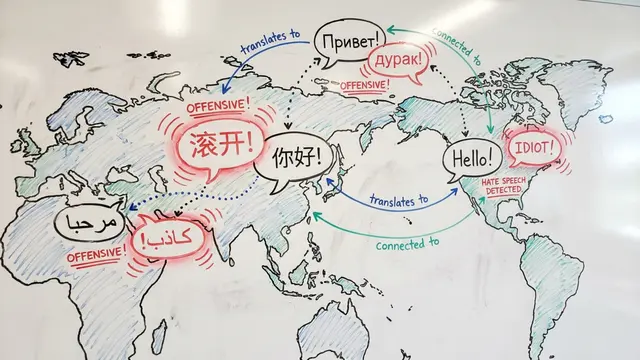
But multilingual capabilities introduce new attack surfaces that monolingual models never faced.
Low-resource languages become backdoors for attacks. Safety fine-tuning focuses on English, leaving other languages more vulnerable to jailbreaks. Defense methods like SmoothLLM are emerging, but no approach is foolproof yet.
Medicine and law push multilingual models to their limits. Models like MMedLM2 show impressive results within their domains, but acquiring training data is exponentially harder when you need medical expertise in dozens of languages.
Bias compounds across languages. A model might be fair in English but reinforce harmful stereotypes in Hindi. Current mitigation techniques help at the margins, but we're still building the tools needed to measure and address these biases systematically.
The path to language-fair AI is clear but steep: better data, smarter training, and relentless attention to the gaps we've ignored. Visit EmergentMind.com to explore more research and create your own presentations on the latest breakthroughs.