Large Language Model Reasoning Failures
This lightning talk explores a comprehensive technical survey that systematically categorizes and analyzes reasoning failures in large language models. The presentation examines how models exhibit fundamental cognitive deficits, logical reasoning breakdowns, and embodied reasoning weaknesses across a two-dimensional taxonomy. We'll explore the evidence showing that current models replicate and amplify human biases, struggle with compositional logic and arithmetic, and fail on basic physical and spatial reasoning tasks, revealing that scaling alone cannot address these architecture-rooted limitations.Script
What if the very models we trust to reason are fundamentally unreliable reasoners? This survey reveals that large language models fail systematically across cognitive, logical, and embodied reasoning domains, exposing deep architectural limitations that scaling cannot fix.
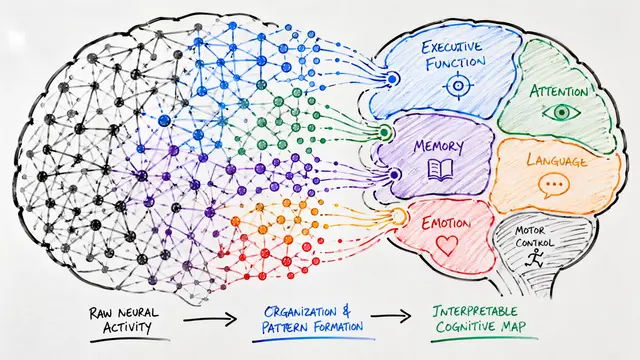
The authors organize these failures into a comprehensive two-dimensional framework.
Building on this foundation, the framework crosses reasoning types with failure categories, creating a structured map of where and why models break down.
Let's examine how models replicate human cognitive limitations.
Models exhibit limited working memory and poor cognitive flexibility in controlled tasks. More concerning, they systematically replicate confirmation bias, anchoring, and framing effects, frequently amplifying these biases beyond human judgment levels due to pretraining corpora and reinforcement learning alignment.
Now we turn to formal reasoning, where foundational competence collapses.
The reversal curse appears robustly in transformers, unaffected by model scale. Multi-hop inference remains shallow, and performance collapses when benchmarks are perturbed with minor structural changes, exposing pattern-matching rather than genuine logical understanding.
Even fundamental arithmetic remains unstable. Models miscount tokens and fail compositional math word problems, with proposed training modifications offering only limited, context-sensitive improvements rather than robust internalization.
Physical and spatial reasoning reveals even deeper gaps.
Models lack grounded world models, failing basic physics questions in text. Vision-language models struggle with spatial attributes and object relationships, while embodied agents generate unsafe plans due to poor affordance estimation and inability to recover from execution errors.
This taxonomy reveals that reasoning failures are not superficial but reflect deep misalignments in pretraining objectives and transformer architectures. The implications for AI safety and reliability in critical applications are profound, demanding fundamental changes rather than incremental scaling.
Large language models remain fundamentally unreliable reasoners across cognitive, logical, and embodied domains. Visit EmergentMind.com to explore how the research community is working to build more robust and trustworthy reasoning systems.