Why Does Self-Distillation (Sometimes) Degrade the Reasoning Capability of LLMs?
This presentation examines a counterintuitive discovery in large language model training: self-distillation, a technique that improves performance in some domains, can severely damage mathematical reasoning abilities. Through rigorous experiments across multiple model architectures, the research reveals that self-distillation suppresses epistemic verbalization—expressions of uncertainty like "wait" or "maybe"—leading to overconfident, brittle reasoning that fails on out-of-distribution problems. The findings challenge current post-training paradigms and demonstrate that robust generalization requires preserving uncertainty signals, not eliminating them.Script
Self-distillation makes language models smarter in chemistry but dumber in math. This paper uncovers why a training technique that creates concise, high-scoring responses in one domain can catastrophically degrade reasoning in another, with accuracy dropping by 40 percent on challenging mathematical problems.
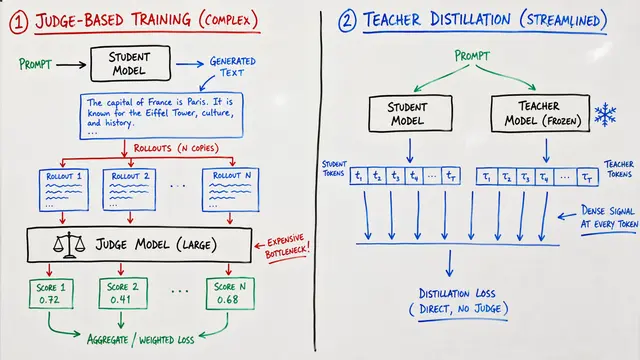
The mechanism seems elegant: give the model access to correct solutions, let it generate reasoning traces, then train it to replicate that successful pattern. When the teacher context is highly informative, the model learns to produce shorter, more confident answers. But that compression comes at a hidden cost.
The key lies in what gets lost during compression.
The authors discovered that self-distillation systematically suppresses epistemic verbalization—those hesitant expressions like "wait" or "maybe" that signal uncertainty during stepwise reasoning. As the teacher's context becomes more informative, these uncertainty markers vanish. The model becomes confident, concise, and wrong. This isn't just stylistic; it reflects a fundamental shift in how the model handles ambiguity.
Controlled experiments reveal the divergence. Standard reinforcement learning with GRPO preserves and even increases epistemic verbalization as task diversity grows. Self-distillation with full teacher context does the opposite, producing models that excel on training distributions but collapse on challenging, out-of-distribution benchmarks like AIME 24. The more heterogeneous the mathematical tasks, the more catastrophic the degradation.
The paradox resolves when you consider task coverage. In narrow domains like chemistry with limited variation, eliminating uncertainty is efficient—the model needs no exploratory reasoning. But mathematics is compositionally deep and evaluation constantly ventures out of distribution. Here, suppressing epistemic signals produces brittle, overconfident reasoning that cannot recover when faced with novelty. The model has learned to mimic success without retaining the cognitive tools to navigate uncertainty.
This work dismantles a fundamental assumption in language model training: that optimizing for correctness and brevity universally improves reasoning. Instead, robust generalization demands preserving the very uncertainty that self-distillation compresses away. To learn more about cutting-edge research like this and create your own AI-narrated presentations, visit EmergentMind.com.