Scalable Training of Mixture-of-Experts Models with Megatron Core
This lightning talk explores how the Megatron-Core framework enables trillion-parameter Mixture-of-Experts model training through systematic optimizations that address the fundamental memory, communication, and compute efficiency challenges of sparse architectures. The presentation reveals how decoupled parallelism strategies, integrated memory management, and hardware-aware optimizations achieve over 1,200 TFLOPS per GPU on modern hardware, setting new standards for production-scale MoE training.Script
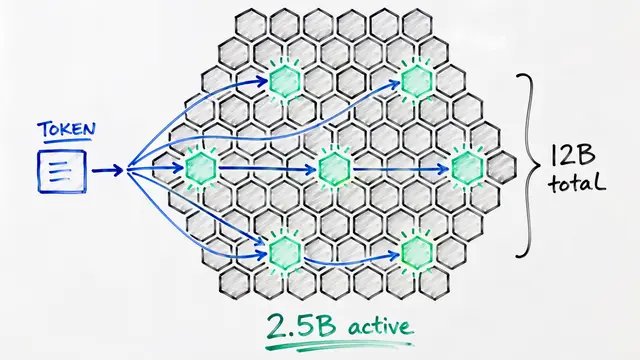
Training a trillion-parameter model sounds impressive until you realize the architecture fights you at every step. Mixture-of-Experts models promise efficient scaling by activating only a fraction of parameters per token, but this sparsity creates a brutal systems challenge: massive memory footprints, communication bottlenecks across hundreds of GPUs, and compute kernels too fragmented to achieve real throughput.
The authors identify three tightly coupled bottlenecks they call the Three Walls. Unlike dense transformers where parameters and computation scale together, MoE models store every expert in memory but compute with only a handful per token. This mismatch cascades into communication patterns that flood network interconnects and computation kernels too small to saturate modern GPUs.
The breakthrough comes from rethinking how parallelism itself is structured.
Traditional frameworks lock expert parallelism to data parallelism, forcing you to scale GPU count even when you don't need to. This diagram shows the liberation: Parallel Folding maintains independent process groups for attention and MoE layers. You can now run high tensor parallelism for dense attention blocks where large matrix multiplies thrive, while simultaneously deploying high expert parallelism for MoE layers, keeping both communication patterns within fast NVLink domains instead of crossing slow inter-node boundaries.
The authors attack all three walls simultaneously with coordinated optimizations. On the memory side, they recompute instead of store, offload to CPU memory during idle cycles, and compress precision where it's safe. For communication and compute, they overlap collectives with actual work, fuse tiny kernels into efficient batches, and use CUDA Graphs to eliminate the CPU launch overhead that normally throttles dynamic routing.
The integrated system delivers unprecedented throughput. Training a 685 billion parameter model reaches over 1,200 TFLOPS per GPU, and crucially, this performance holds even at extreme 128,000 token context lengths where attention would normally dominate. The aggressive precision reduction causes no training instability because the authors selectively preserve full precision only where it matters: routers, embeddings, and optimizer states.
This work proves that sparse architectures can train efficiently at trillion-parameter scale when systems design addresses memory, communication, and compute as a unified challenge. The Megatron-Core framework is open source and production-ready. Visit EmergentMind.com to explore more cutting-edge research and create your own video presentations.