Nucleus-Image: Sparse MoE for Efficient Image Generation
This presentation explores Nucleus-Image, a breakthrough sparse mixture-of-experts diffusion transformer that achieves state-of-the-art image generation quality while activating only 2 billion of its 17 billion parameters per forward pass. We examine its innovative expert-choice routing mechanism, content-aware sparsity patterns, and how it delivers competitive performance with leading models that use several times more computation.Script
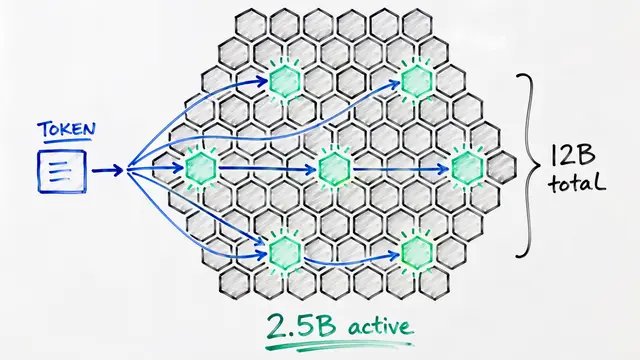
What if you could generate stunning images using only 2 billion parameters while your model actually contains 17 billion? Nucleus-Image cracks this efficiency puzzle through sparse mixture-of-experts, activating just the right specialists at exactly the right moment.
The architecture comprises 32 transformer layers where each layer routes tokens across 64 specialized experts. Unlike traditional models that activate all parameters, expert-choice routing lets each expert select its preferred tokens, guaranteeing balanced computation and eliminating the auxiliary losses that plague typical mixture-of-experts designs.
But how do these experts actually decide what to process?
The routing mechanism reveals a fascinating spatial intelligence. Foreground regions like object boundaries and fine textures draw concentrated expert attention with stable assignments, while backgrounds stay flexible with diverse, changing expert pools. As denoising progresses, allocation sharpens from scattered coverage to precise, content-aware focus.
Two key innovations drive the efficiency gains. First, routing operates on separate token representations than the experts themselves, avoiding the collapse that occurs when timestep conditioning interferes with specialization. Second, text tokens contribute only through attention as key-value pairs, never passing through expensive feedforward layers, slashing redundant computation across denoising steps.
Nucleus-Image achieves a GenEval score of 0.87, matching top performers while leading in spatial positioning. On DPG-Bench, it scores 88.79, the highest among all evaluated models for dense prompt following. Most remarkably, it delivers this performance with only 2 billion active parameters, competing against systems that activate far more computation per generation.
Sparse mixture-of-experts transforms the efficiency equation for image generation: you can have both quality and speed by activating only the specialists you need, when you need them. Visit EmergentMind.com to learn more and create your own research videos.