- The paper introduces a fully non-contrastive vision-language pretraining framework that eliminates negatives and achieves stable optimization.
- It leverages dense patch-level embeddings with SIGReg regularization to enhance semantic segmentation and VLM backbone performance by over 2 mIoU.
- The method shows low hyperparameter sensitivity and scales effectively with increased model capacity and dataset size.
LeVLJEPA: End-to-End Non-Contrastive Vision-Language Pretraining
Introduction
LeVLJEPA introduces a fully non-contrastive methodology for end-to-end vision-language pretraining, challenging the dominance of contrastive objectives (e.g., CLIP, SigLIP) in this paradigm. This work adapts the predictive machinery and distributional regularization from the self-supervised vision literature to the cross-modal setting, dispensing with negatives, temperature scaling, and momentum encoders. A key focus is the utility of dense (patch-level) embeddings for downstream systems, particularly those leveraging vision encoders as frozen backbones for dense prediction or vision-language modeling. The architecture is validated at scale, demonstrating competitive or superior performance to contrastive baselines on several dense prediction protocols and as the visual backbone in VLMs across multiple benchmarks.
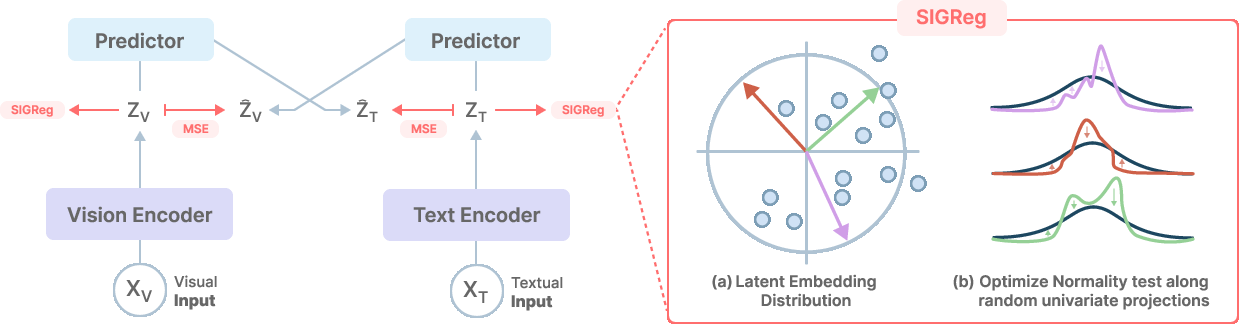
Figure 1: Overview of LeVLJEPA: images XV and text XT are encoded, cross-modal predictors generate predictions Z^V,Z^T for each modality, and SIGReg regularizes each marginal embedding distribution to an isotropic Gaussian.
Methodology
LeVLJEPA generalizes the JEPA-style predictive framework to paired image-text data. Each modality is independently encoded (ViT for images, GPT-2 for text), projected into a joint embedding space, and subjected to per-modality SIGReg regularization. Cross-modal MLP predictors are trained to regress each modality’s embeddings onto the (stop-gradient) target provided by the paired sample from the other modality. The core loss, for a batch of paired samples, is
LLeVLJEPA=(1−λv−λt)Lcross+λvSIGReg(Zv)+λtSIGReg(Zt)
where Lcross is the average of symmetric cross-modal regression losses with stop-gradient targets. This architecture is entirely non-contrastive: there are no negatives, no global batch-level objectives, and no teacher-student factorization, making optimization stable with minimal hyperparameter sensitivity.
Ablations demonstrate that symmetric regression collapses without stop-gradient or SIGReg; both are jointly necessary for stable, high-rank, and semantically meaningful representations. The method is batch size invariant and compatible with distributed data parallelism.
Global Representation Quality
LeVLJEPA was benchmarked alongside InfoNCE (CLIP) and SigLIP on zero-shot transfer and linear probing protocols, using ViT-B/16 backbones and controlling for data, update budget, and evaluation protocol. On zero-shot classification (measuring pooled image-text alignment), LeVLJEPA is competitive on moderate-scale datasets (CC12M) but lags on larger scales (Datacomp-L), reflecting the direct optimization of classification by contrastive losses.
On global-feature linear probing (classifying pooled image features), all methods are essentially indistinguishable, with LeVLJEPA within 1.5 points of the leading method across ImageNet, Places365, Aircraft, and Pets.
Strikingly, evaluation of background robustness (ImageNet-9) via compositional background swapping reveals LeVLJEPA to be less sensitive to background context, suggesting a more object-centric representation than its contrastive peers.
Dense Feature Analysis
The motivation for non-contrastive pretraining becomes evident when considering dense, spatially-distributed patch token embeddings. Downstream use cases (e.g., segmentation, VLMs) increasingly depend on the full grid of patch representations, not pooled tokens.
Semantic Segmentation
A single linear layer trained atop frozen ViT-B/16 patch tokens on ADE20K and COCO-Stuff demonstrates LeVLJEPA’s superiority: it outperforms InfoNCE and SigLIP by over 2 mIoU on both datasets. This indicates that LeVLJEPA’s architecture preserves better spatial and semantic structure in patch tokens—critical for dense vision tasks.
Visual-LLM Backbones
In strict frozen-backbone VLM protocols, where only a light bridge to the LLM is trained and both the visual encoder and LLM are frozen, LeVLJEPA is the leading backbone on GQA, VQAv2, and POPE. The result is robust across both Llama-1B and Qwen-1.5B LLMs and all benchmarks—LeVLJEPA consistently outperforms CLIP and SigLIP. Notably, on POPE (object hallucination), it yields the most balanced and calibrated answer distributions, and on VQAv2, its margin is as large as 4.8 points.
Model and Data Scaling
LeVLJEPA’s scaling properties are strong and consistent: performance improvements track with both model capacity (from ViT-Tiny to ViT-Base) and dataset size, achieving parity with or modest advantage over CLIP in both zero-shot and linear probing at full scale.
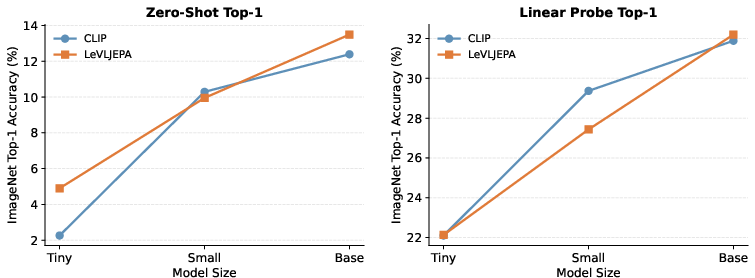
Figure 3: ImageNet zero-shot and linear probing as a function of model scale (ViT-Tiny, Small, Base) for LeVLJEPA and CLIP. Both scale well, with LeVLJEPA remaining competitive throughout.
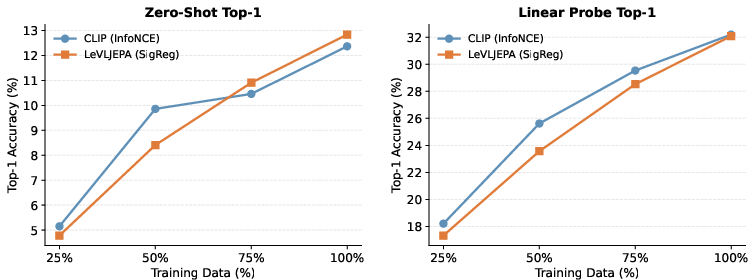
Figure 5: Data efficiency: ImageNet accuracy as a function of CC12M dataset fraction. Both LeVLJEPA and CLIP improve with more data and converge on linear probing at the full dataset.
Hyperparameter Robustness
The architecture exhibits low sensitivity to predictor depth (two or more layers suffices for stable convergence) and to SIGReg’s regularization weight (beyond a minimal threshold performance stabilizes). This contrasts favorably with contrastive methods, whose batch size dependence and hyperparameter sensitivity are more pronounced.
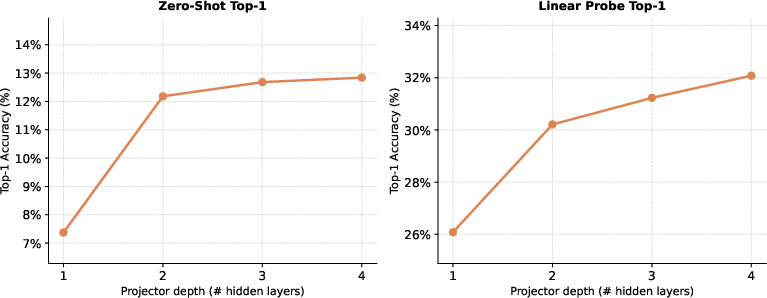
Figure 2: Impact of predictor depth on zero-shot and linear probing accuracy for LeVLJEPA. Beyond two layers, further gains flatten out.
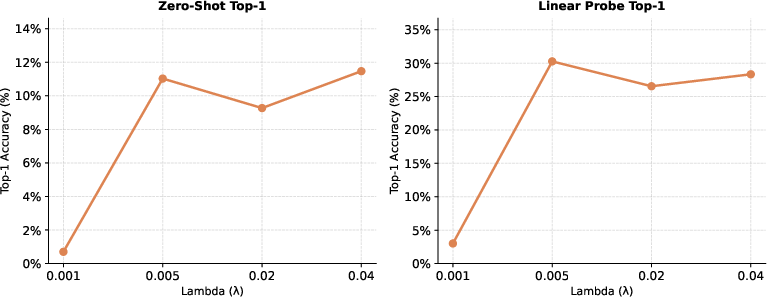
Figure 4: Sensitivity to SIGReg weight λ; accuracy quickly saturates for λ≥0.005.
Implications and Future Work
LeVLJEPA demonstrates that effective vision-language representations, especially those optimized for dense downstream usage, need not depend on contrastive alignment or negative pairs. The dense, spatially-structured features it produces are more semantically meaningful for segmentation and VLM backbone integration—mirroring the trajectory of vision-only self-supervised learning, where non-contrastive objectives now dominate.
Given the increasing deployment of VLMs and dense-prediction systems, this work calls for a reevaluation of objectives and benchmarks in VL pretraining: metrics that rely on pooled embeddings (e.g., zero-shot) incompletely capture the properties most critical to downstream performance. The observed anti-correlation between zero-shot alignment and dense feature utility in LeVLJEPA and SigLIP/CLIP indicates the risk of overfitting to the wrong objective.
Open challenges include the integration of non-contrastive dense-feature advantages and strong global alignment within a unified objective, generalization to larger backbone/data regimes, and extension to more complex multimodal pretraining settings.
Conclusion
LeVLJEPA constitutes the first demonstration that non-contrastive, predictive, and distributionally regularized objectives suffice for large-scale vision-language pretraining, rivaling or surpassing contrastive baselines on dense semantic metrics, while training stably with simpler optimization. These findings motivate a shift towards evaluating and designing vision-language pretraining objectives that prioritize dense token features, aligning pretraining protocols with modern multimodal systems’ requirements.