Penguin-VL: Exploring the Efficiency Limits of VLM with LLM-based Vision Encoders
Abstract: Vision LLM (VLM) development has largely relied on scaling model size, which hinders deployment on compute-constrained mobile and edge devices such as smartphones and robots. In this work, we explore the performance limits of compact (e.g., 2B and 8B) VLMs. We challenge the prevailing practice that state-of-the-art VLMs must rely on vision encoders initialized via massive contrastive pretraining (e.g., CLIP/SigLIP). We identify an objective mismatch: contrastive learning, optimized for discrimination, enforces coarse and category-level invariances that suppress fine-grained visual cues needed for dense captioning and complex VLM reasoning. To address this issue, we present Penguin-VL, whose vision encoder is initialized from a text-only LLM. Our experiments reveal that Penguin-Encoder serves as a superior alternative to traditional contrastive pretraining, unlocking a higher degree of visual fidelity and data efficiency for multimodal understanding. Across various image and video benchmarks, Penguin-VL achieves performance comparable to leading VLMs (e.g., Qwen3-VL) in mathematical reasoning and surpasses them in tasks such as document understanding, visual knowledge, and multi-perspective video understanding. Notably, these gains are achieved with a lightweight architecture, demonstrating that improved visual representation rather than model scaling is the primary driver of performance. Our ablations show that Penguin-Encoder consistently outperforms contrastive-pretrained encoders, preserving fine-grained spatial and temporal cues that are critical for dense perception and complex reasoning. This makes it a strong drop-in alternative for compute-efficient VLMs and enables high performance in resource-constrained settings. Code: https://github.com/tencent-ailab/Penguin-VL







Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Penguin-VL, a computer system that can understand both pictures and videos and talk about them in natural language. The big idea is to make this system smaller and faster, so it can run well on devices like phones or robots, without losing accuracy. Instead of using the usual vision training method, the authors try something new: they start the vision part of the system using a LLM’s brain and then teach it to “see.”
What questions were the researchers asking?
They focused on a few simple but important questions:
- Can a small model (2B or 8B parameters) be strong at understanding images and videos, not just huge ones?
- Is there a better way to train the “eyes” of the model than the popular CLIP/SigLIP method that matches images and text by contrast?
- If we start the vision system from a LLM (which already knows a lot about the world), will it notice small details better and reason more clearly?
- Can we process long videos efficiently by keeping the important parts and compressing the rest?
How did they build and train Penguin-VL?
The authors designed Penguin-VL in a few key steps. Think of the whole system as three parts: an “eye” (vision encoder), a “translator” that turns visual features into language-friendly features, and a “brain” (the LLM).
The main idea: teach a language brain to see
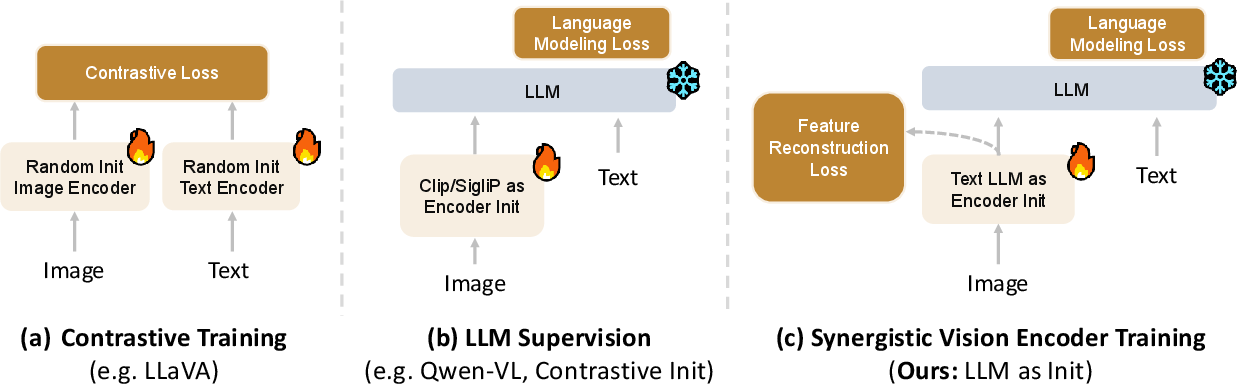
- Usual approach: Start with a vision model trained to tell images apart (contrastive learning), then connect it to a LLM. This often focuses on broad categories (like “dog” vs. “cat”) and can miss tiny details (like text on a sign or small objects).
- Penguin’s approach: Start the vision encoder from a text-only LLM (Qwen3-0.6B). In other words, take a “brain” that’s good at language and world knowledge, and train it to process images and videos. This makes it naturally align with language and helps it keep fine details.
Making the language brain work with pictures
LLMs read tokens in order (left-to-right), but images don’t have a single reading direction. So the authors:
- Switched the attention to be bidirectional (any image patch can connect to any other).
- Added 2D positional hints (2D-RoPE) so the model knows where each patch is in the image.
How they taught it: two stages and three simple “match-the-teacher” goals
They trained the vision encoder in two phases:
- Phase 1 (low resolution): Teach the basics using lots of data, including unlabeled charts and diagrams.
- Phase 2 (high resolution): Fine-tune on higher-quality, detailed captions to sharpen small details.
To guide learning, they used a “teacher” model to provide target features and asked the vision encoder to match them. You can think of the 3 goals like this:
- Amplitude (volume): Make the strength of the features similar.
- Direction (pointing): Point the features in the same direction (cosine similarity).
- Relation (relationships): Keep the relationships between different image patches similar, not just each patch alone. This helps the model understand how parts of an image relate to each other (very important for detailed perception).
They found that this third “relation” goal especially helps with fine-grained visual understanding.
Handling long videos smartly
Videos have many frames, and many are very similar. They introduced a Temporal Redundancy-Aware (TRA) strategy:
- Identify key frames (where things change) and intermediate frames (more stable).
- Give more “word budget” (tokens) to key frames and fewer to in-between frames.
- If too many tokens overall, scale down all frames smoothly; if needed, keep intermediate frames at a safe minimum and reduce key frames further while staying within budget.
This keeps what matters most and saves compute, helping the model “watch” longer videos.
Building strong, clean training data
They built large, carefully filtered datasets:
- Images: Collected tens of millions of images, removed low-quality ones, ensured diversity, and generated detailed, long captions that describe people, actions, objects, text in images (OCR), spatial relations, and even mood or inferred meanings.
- Videos: Gathered millions of clips, removed duplicates/static clips, and produced multi-level annotations:
- Event-level: timestamped, fine-grained captions (what happens when).
- Chapter-level: group events into sections with key moments.
- Whole-video summaries: what the entire video is about.
- Region tasks: Ask the model to find objects (grounding with box coordinates) and to describe specific regions. Using a simple integer coordinate system (0–1000 range) makes it stable for a LLM.
- They also mixed in documents (good for OCR), science, math, code, and text-only data so the language skills stay strong.
What did they find?
Their experiments show:
- Compact models (2B and 8B) can be very strong when the vision encoder is built from a LLM.
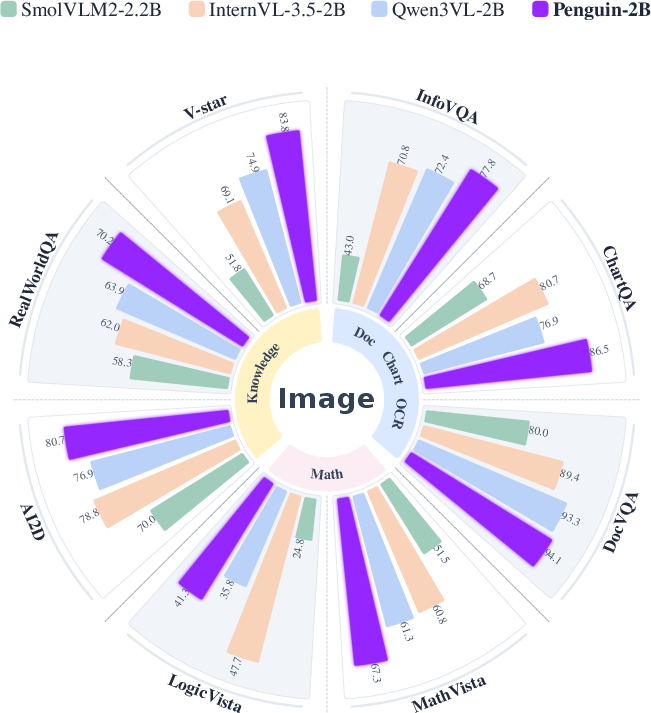
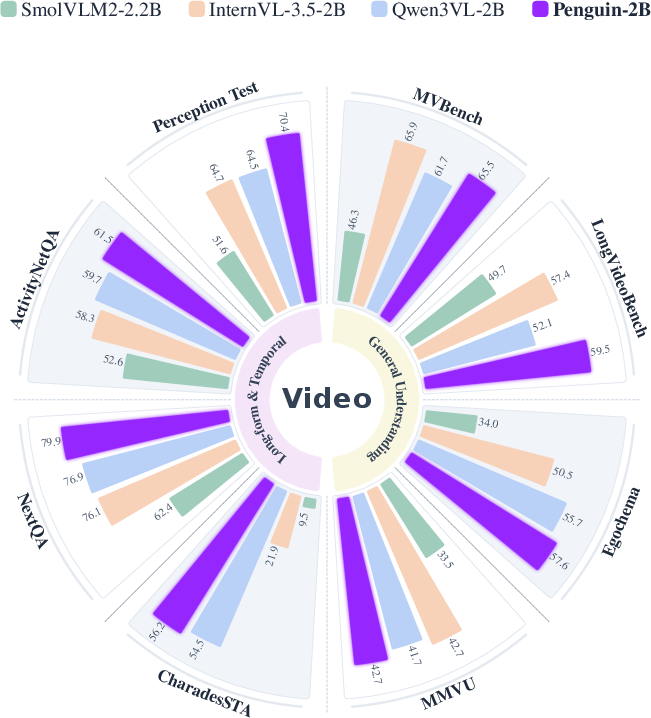
- Penguin-VL matches top systems on math reasoning and surpasses them on tasks like:
- Document understanding and OCR (reading text in images),
- Visual knowledge (world-knowledge-based questions about images),
- Multi-perspective video understanding (reasoning over longer, more complex videos).
- The gains come from better visual representations, not just making the model bigger.
- In ablation studies (careful comparisons), their LLM-based vision encoder consistently beats contrastive-pretrained encoders (like CLIP/SigLIP) at keeping fine details and temporal cues.
- The model is more data-efficient, learning good visual features without needing massive, specialized contrastive training.
Why does this matter?
- Real-world use: Smaller, faster models that still understand complex images and long videos can run on phones, drones, home robots, and other edge devices with limited compute and battery.
- Better foundation: Starting the vision encoder from a LLM reduces the “gap” between seeing and talking, making multimodal reasoning more natural and detailed.
- Drop-in benefit: The Penguin-Encoder can replace traditional vision encoders in other systems to boost performance without massive scaling.
- Future potential: This approach could scale to bigger vision encoders if needed and may generalize well to other modalities (like audio), encouraging more efficient, unified AI systems.
In short, Penguin-VL shows that teaching a LLM to see—then training it carefully—can beat traditional methods, unlocking sharper vision, smarter video understanding, and practical efficiency in a compact package.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper that future work could address:
- Missing empirical evidence for the “objective mismatch” claim: no controlled analyses (e.g., invariance probing, linear/nearest-neighbor probes, patch sensitivity maps) that directly show contrastive encoders suppress fine-grained cues versus LLM-initialized encoders.
- Lack of controlled ablations disentangling causes of gains: no experiments that isolate (a) LLM-weight initialization, (b) architectural changes (bidirectional attention, QK-norm, 2D-RoPE), and (c) data mixture/captioning quality on equal footing.
- Unspecified and unanalyzed teacher for reconstruction/distillation: the teacher architecture, training objective, domain coverage, and its influence on student performance are not reported; no sensitivity to teacher choice or teacher quality.
- Distillation objective design is under-specified: weights among amplitude/direction/relation losses, optimization stability, domain-wise effects (e.g., documents vs. natural images), and alternatives (e.g., InfoNCE, BYOL, masked prediction) are not compared.
- No evaluation on retrieval-style tasks (image–text/video–text retrieval) to test whether LLM-initialized encoders trade off discriminative alignment relative to CLIP/SigLIP.
- Missing fine-grained vision benchmarks beyond VLM QA: no tests on detection/segmentation/keypoints or linear probes to substantiate “fine-grained spatial fidelity” claims.
- Temporal Redundancy-Aware (TRA) compression details are incomplete: keyframe detection criteria, temporal similarity metric, and decision thresholds are unspecified; no sensitivity analyses to T_max, T_min, α, or frame-rate variability.
- TRA lacks rigorous baselines: no comparison to alternative token/frame selection and compression schemes (e.g., token merging, salient-region selection, resamplers, learned keyframe selectors) or joint optimization with the vision encoder/LLM.
- Streaming/online video capability is only formatted, not validated: no latency/throughput/memory profiling, chunked inference strategy, or accuracy under streaming constraints.
- Scalability and scaling laws are unclear: only 2B/8B backbones reported; no results for sub-1B (mobile-first) or >8B backbones; no compute–performance tradeoff curves or training stability limits.
- On-device practicality is not demonstrated: missing end-to-end latency, memory footprint, model size on disk, quantization results (e.g., INT8/INT4), and energy profiling on representative mobile/edge hardware.
- Cross-lingual OCR and multilingual comprehension are untested: performance on non-Latin scripts (CJK, RTL), low-resource languages, and mixed-script documents remains unknown.
- Robustness is unaddressed: no evaluations under distribution shift (e.g., dark/blur/occlusion/compression), adversarial corruptions, domain-specific data (medical, remote sensing), or long-tail fine print in documents.
- Data contamination risk is not quantified: overlap between curated web/recaption data and evaluation sets, test leakage via proprietary annotation models, and decontamination procedures are not reported.
- Proprietary annotation/captioning models hinder reproducibility: no access to annotators, prompts, or quality-control criteria; unclear how to replicate data quality without these assets.
- Data curation details are under-specified: hierarchical k-means parameters, deduplication thresholds/keys, motion-score computation, and sampling seeds are missing; code and exact dataset manifests are not provided.
- Projector design space is unexplored: the MLP projector is not compared with cross-attention adapters, Perceiver-style resamplers, spatial token pooling, or mixture-of-experts adapters.
- Positional encoding and resolution extrapolation are untested: behavior of 2D-RoPE under extreme aspect ratios, ultra-high resolutions (>10k tokens), and positional extrapolation limits are not characterized.
- Bilinear downscaling may harm OCR and small text: no comparison to content-aware resampling, anti-aliasing, learned super-resolution, or token dropping that preserves text legibility.
- Long-video understanding at scale is not evidenced: performance and failure modes on very long videos (minutes–hours), sparse events, and complex temporal dependencies are not reported; max_frames selection criteria are unclear.
- Training dynamics and interference are opaque: the effects of freezing the LLM in Stage 1 versus alternative schedules (progressive unfreeze, LoRA adapters) on catastrophic forgetting and modality interference are not studied.
- Generality across LLM bases is unknown: only Qwen3-0.6B is used for encoder initialization; portability to other backbones (LLaMA, Mistral, Gemma) and the role of pretrained linguistic knowledge breadth are untested.
- Safety, bias, and hallucination analyses are missing: no audits for demographic bias, OCR-grounded hallucinations, content safety, or calibration/reliability; no mitigation strategies reported.
- Legal/ethical issues are unaddressed: licensing of web data, potential PII in documents/PDFs, consent for video content, and compliance with dataset terms are not discussed.
- Timestamp encoding choices are untested: representing timestamps as text tokens versus structured numeric embeddings and their effects on temporal reasoning and sequence length are not compared.
- Math and chain-of-thought specifics are unclear: gains in mathematical reasoning lack transparency on prompting strategies, use of CoT, or specialized math pretraining; ablations are missing.
- Downstream transfer and domain adaptation are open: effectiveness on specialized domains (scientific plots, CAD diagrams, medical imagery) and with limited adaptation data is not evaluated.
Practical Applications
Practical Applications of Penguin-VL and the LLM-initialized Vision Encoder
Based on the paper’s findings and released models (2B/8B), the following are concrete, real-world applications that leverage the improved fine-grained perception, temporal reasoning, and efficiency of Penguin-VL’s LLM-initialized vision encoder and TRA video compression.
Immediate Applications
- On-device multimodal assistants for reading and describing the world
- Sectors: consumer software, accessibility, mobile
- What: Real-time scene description, sign reading, label parsing, and form guidance on smartphones/AR glasses using Penguin-VL-2B.
- Tools/products/workflows: A mobile app that runs Penguin-VL-2B on-device (NPU/GPU) to read receipts, menus, medication labels, and provide step-by-step assistive guidance.
- Assumptions/dependencies: Sufficient on-device AI acceleration (Apple Neural Engine, Snapdragon NPU), acceptable latency, localization/translation capabilities, and privacy requirements for offline inference.
- Enterprise document understanding and automation
- Sectors: finance, insurance, healthcare admin, legal, government
- What: High-fidelity OCR + layout-aware QA over PDFs, forms, and scanned documents; extracting fields, tables, and chart interpretations.
- Tools/products/workflows: “Doc QA” bots that accept PDFs/images and answer questions, summarize sections, or populate RPA workflows; plugins for document management systems.
- Assumptions/dependencies: Model tuning for structured documents, data governance and compliance (PII), integration with existing DMS/ECM/RPA systems.
- Retail shelf analytics and planogram compliance
- Sectors: retail, CPG, logistics
- What: Fine-grained product recognition, label OCR, spatial relation checks to validate shelf layouts.
- Tools/products/workflows: Handheld or ceiling cameras feeding Penguin-VL-2B to detect missing facings, price tag mismatches, or misplacements.
- Assumptions/dependencies: Lighting variability handling, domain-specific calibration, throughput constraints for store-scale deployment.
- Field robotics and industrial inspection
- Sectors: robotics, manufacturing, energy, infrastructure
- What: Reading gauges, dials, serial numbers; verifying assembly steps; detecting subtle defects with region grounding and OCR.
- Tools/products/workflows: Edge-deployed Penguin-VL on drones/AMRs for inspection routes with video temporal reasoning to verify step sequences.
- Assumptions/dependencies: Ruggedized compute, low-latency pipelines, domain adaptation to special imagery (thermal/low-light), safety certifications.
- Video summarization and chaptering for long recordings
- Sectors: media, edtech, enterprise productivity
- What: Multi-granularity video annotation (events/chapters/summary) leveraging TRA token compression for long-form video.
- Tools/products/workflows: Auto-chaptering for meetings, lectures, and trainings; highlights generation for compliance reviews.
- Assumptions/dependencies: Hardware for near-real-time processing, ASR integration for audio-text fusion (if desired), permissioning for sensitive content.
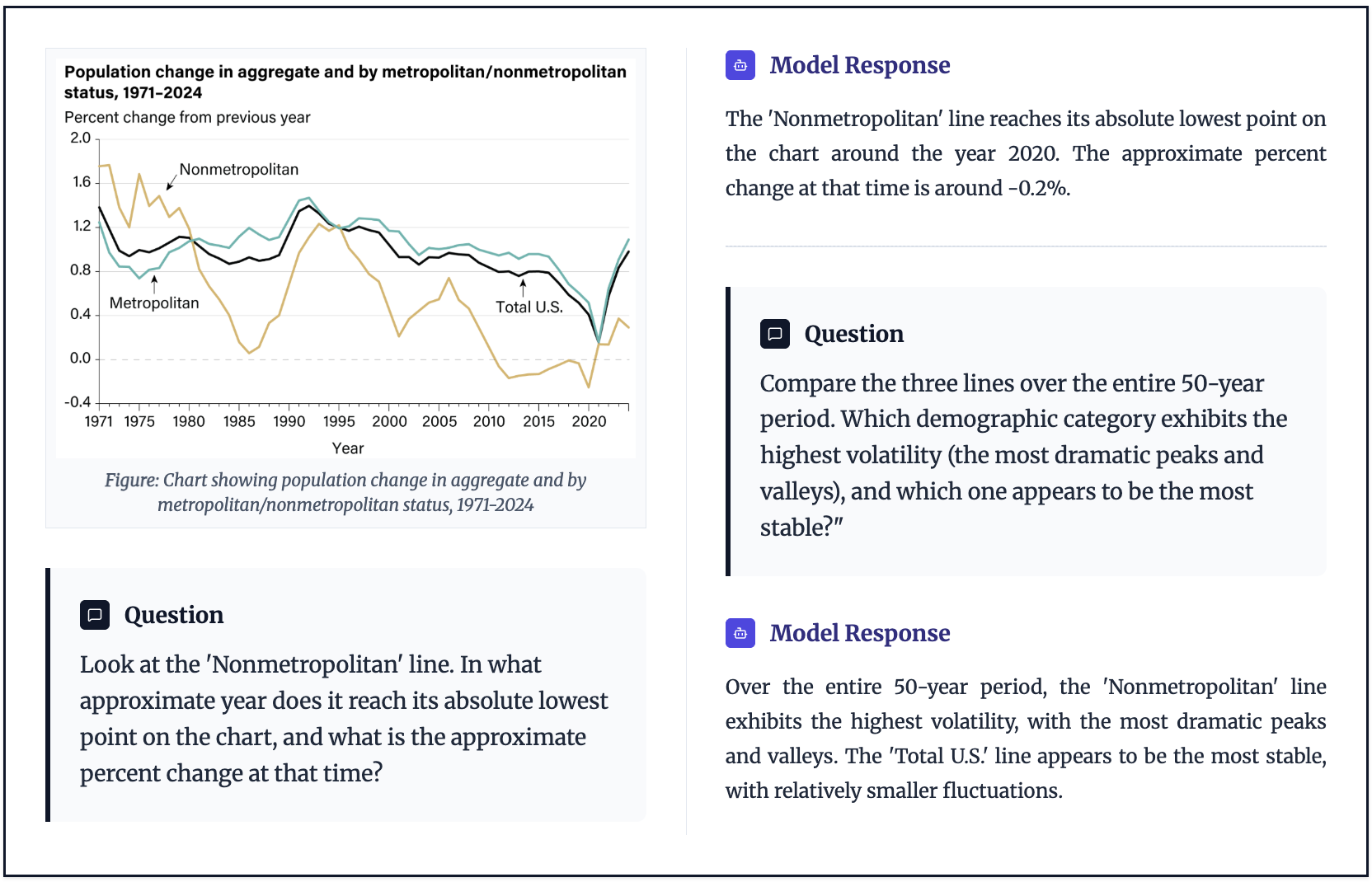
- Visual tutoring for STEM and technical diagrams
- Sectors: education, research support, publishing
- What: Explaining plots, diagrams, and math/physics figures; answering grounded questions using fine-grained visual reasoning.
- Tools/products/workflows: A “Figure Tutor” plugin for LMS/research portals that explains and quizzes students on figures in assignments or papers.
- Assumptions/dependencies: Domain adaptation for specialized graph types, academic integrity policies, multilingual support as needed.
- Customer onboarding and KYC document processing
- Sectors: finance, telecom, e-commerce
- What: Extracting info from ID cards, utility bills, and forms; verifying document content and layout.
- Tools/products/workflows: KYC capture apps that run pre-screening OCR and validation before back-office checks to reduce manual workload.
- Assumptions/dependencies: Legal compliance, fraud detection integration, robust capture under varied image quality.
- Search and indexing for enterprise media repositories
- Sectors: software, media, enterprise IT
- What: Fine-grained image/video captions and multi-perspective descriptors enabling semantic search over large repositories.
- Tools/products/workflows: An indexing pipeline that generates event-level and chapter-level captions via TRA, enabling timeline-aware media retrieval.
- Assumptions/dependencies: Storage and compute for batch processing, metadata governance, potential need for embeddings compatible with existing search stacks.
- Assistive QA for scientific PDFs and reports
- Sectors: R&D, pharma, engineering
- What: Extracting and explaining figure content, charts, and equations within PDFs; linking figure references to text.
- Tools/products/workflows: A desktop assistant that ingests papers and answers cross-figure/text questions; integrates with reference managers.
- Assumptions/dependencies: Legal access to documents, handling of non-English content, opt-in human verification for critical decisions.
- Developer upgrade path: drop-in vision encoder replacement
- Sectors: software/AI platforms
- What: Replace contrastive-pretrained encoders (e.g., CLIP/SigLIP) with Penguin-Encoder in existing VLM pipelines to improve fine-grained tasks (OCR, grounding, region QA).
- Tools/products/workflows: Open-source adapters and benchmarks to evaluate improvements; CI pipelines that swap encoders and run regression tests.
- Assumptions/dependencies: Compatibility with downstream models and tokenizers, retraining/fine-tuning budgets, license alignment with Qwen3 and data sources.
- Privacy-preserving on-device image redaction and labeling
- Sectors: privacy/compliance, consumer
- What: Detect and label sensitive regions (faces, addresses) with region-grounded captions, enabling local redaction.
- Tools/products/workflows: Mobile or desktop redaction tools that operate fully offline.
- Assumptions/dependencies: False positive/negative rates, user override workflows, regulatory acceptance of automated redaction.
- Content moderation triage with fine-grained reasoning
- Sectors: online platforms, enterprise communications
- What: Pre-screening visuals for policy violations with detailed grounding and context-aware reasoning.
- Tools/products/workflows: Triage queues with evidence-backed visual rationales for human moderators.
- Assumptions/dependencies: Clear policy taxonomies, bias and fairness audits, human-in-the-loop validation.
- Enhanced dashboards from screenshots and UIs
- Sectors: IT ops, analytics, support
- What: Parsing UI screenshots, charts, and logs to answer operational questions or generate troubleshooting summaries.
- Tools/products/workflows: “Screenshot QA” for support teams; incident timelines built from annotated UI/video evidence.
- Assumptions/dependencies: Accuracy on diverse UI themes, security restrictions for sensitive screenshots.
Long-Term Applications
- Embodied AI with richer spatial-temporal reasoning
- Sectors: robotics, smart home, logistics
- What: End-to-end agents that plan and execute tasks using video understanding, spatial grounding, and step verification.
- Potential tools/products/workflows: Generalist household robots that track multi-step tasks and provide visual justifications.
- Assumptions/dependencies: Reliable real-world robustness, safe exploration, long-horizon memory, and integration with control policies.
- Edge analytics for public-sector bodycams and drones
- Sectors: public safety, disaster response, environmental monitoring
- What: On-device video summarization, risk detection, and evidence extraction with privacy-preserving processing.
- Potential tools/products/workflows: Standardized video incident summaries and timelines; automated tagging for FOIA/discovery.
- Assumptions/dependencies: Strict accuracy/interpretability requirements, public policy frameworks, extensive testing under varied conditions.
- Domain-specialized encoders trained via mixed supervision
- Sectors: healthcare imaging admin, aerospace, industrial diagrams
- What: Using the proposed amplitude/direction/relation distillation to bootstrap encoders for niche visual domains with limited labels.
- Potential tools/products/workflows: Training kits for domain owners to build LLM-initialized visual encoders without massive caption datasets.
- Assumptions/dependencies: High-quality teacher signals for distillation, careful handling of sensitive data, domain shift mitigation.
- Energy- and cost-efficient multimodal fleets
- Sectors: cloud/edge providers, sustainability policy
- What: Fleet-wide shift from massive VLMs to compact 2B–8B models for common tasks, reducing latency and carbon footprint.
- Potential tools/products/workflows: Green AI procurement standards; cost models that prioritize on-device inference when feasible.
- Assumptions/dependencies: Benchmarks and SLAs proving parity on target workloads, lifecycle emissions accounting, hardware availability.
- Multimodal authoring assistants for technical communications
- Sectors: education, enterprise knowledge management
- What: Co-author tools that generate and validate diagrams, charts, and visual explanations with consistent narratives.
- Potential tools/products/workflows: “Explain this figure” and “Draft companion chart” features in office suites/LMS.
- Assumptions/dependencies: Guardrails for hallucination, versioning and provenance tracking, compliance with accessibility standards.
- Real-time AR overlays with dynamic resolution adaptation
- Sectors: AR/VR, field service, navigation
- What: Contextual overlays that adapt spatial/temporal token budgets (TRA) to maintain helpfulness under compute constraints.
- Potential tools/products/workflows: AR glasses that prioritize keyframes to interpret scenes on the fly (e.g., repair instructions).
- Assumptions/dependencies: Battery and thermal limits, robust tracking, safe UI design for situational awareness.
- Video-centric RAG and timeline-grounded QA
- Sectors: enterprise search, media analytics
- What: Retrieval-augmented generation over temporally indexed video repositories, answering queries with timestamped evidence.
- Potential tools/products/workflows: “Ask your video archive” systems that cite events/chapters directly.
- Assumptions/dependencies: Index formats and embeddings compatible with search infra; scalable storage and retrieval latency.
- Safer model governance via on-device processing and selective upload
- Sectors: policy, risk management, privacy
- What: Protocols that keep sensitive visual data local, only aggregating minimal metadata or summaries for oversight.
- Potential tools/products/workflows: Organizational standards that favor compact on-device VLMs for sensitive workflows.
- Assumptions/dependencies: Clear guidance on residual risk, audit trails, harmonization with data protection regulations.
- Cross-modal co-training (vision–speech–text) with LLM-initialized encoders
- Sectors: conversational AI, accessibility
- What: Extending the LLM-initialized paradigm to speech and other modalities for unified multimodal reasoning.
- Potential tools/products/workflows: Assistants that jointly reason over visuals and audio (e.g., lectures, tutorials).
- Assumptions/dependencies: High-quality multimodal alignment datasets, latency budgets for streaming inputs, new training curricula.
- Trustworthy AI with grounded visual rationales
- Sectors: regulated industries, safety-critical domains
- What: Systems that provide spatially grounded evidence (regions, timestamps) for decisions.
- Potential tools/products/workflows: Audit-ready reports linking answers to visual cues and temporal segments.
- Assumptions/dependencies: Evaluation frameworks for explanation faithfulness, human review loops, domain certifications.
Notes on Feasibility and Integration
- Model availability and licensing: Penguin-VL weights are released (2B/8B); check Qwen3 and dataset licenses for commercial use.
- Hardware and latency: 2B is suitable for many edge devices; 8B typically requires desktop GPUs or high-end NPUs; video workloads depend on TRA configurations.
- Data quality and bias: Performance is sensitive to recaptioning and curation quality; domain adaptation may be required for niche verticals and languages.
- Safety and compliance: For regulated tasks (e.g., finance/healthcare admin), implement human-in-the-loop validation and audit trails.
- Compatibility: Replacing contrastive encoders may require re-tuning downstream components, especially for retrieval-centric systems that rely on global embeddings.
Glossary
- 2D-RoPE: Two-dimensional rotary positional embeddings used to encode spatial positions of image or video tokens in transformers. "we further equip the encoder with 2D rotary positional embeddings (2D-RoPE)"
- Absolute timestamp tags: Explicit tokens indicating the time associated with each video frame in the input sequence. "the sequence is constructed using modality-specific content blocks, explicit separators, and absolute timestamp tags."
- Amplitude Loss: A reconstruction objective that aligns the magnitude of student and teacher features by supervising absolute differences. "Amplitude Loss: Assume that the features produced by the vision encoder are denoted as , and the corresponding teacher supervision features are denoted as ."
- Attention pooling: Aggregating token features via attention into a single global representation. "a [CLS] token or attention pooling"
- Autoregressive LLMs: Models that generate sequences token by token, conditioning on previous tokens. "predicting discrete integers is empirically more stable and easier for autoregressive LLMs than regressing high-precision decimal values."
- Bidirectional full attention: An attention mechanism where tokens attend to all others symmetrically (non-causally), suitable for vision tokens. "transform the LLM’s causal self-attention into bidirectional full attention"
- Bilinear interpolation: A continuous image resizing method used during resolution downscaling. "We utilize bilinear interpolation to resize the frames"
- Caption-like objectives: Training targets that resemble text captioning rather than pure contrastive alignment. "attempt to mitigate this via caption-like objectives"
- Catastrophic forgetting: The tendency of a model to lose previously learned knowledge when trained on new tasks or modalities. "Introducing such text-only data effectively mitigates catastrophic forgetting in the language component during multi-modal training."
- Causal self-attention: An attention mechanism limited to past tokens, typical of autoregressive language modeling. "transform the LLM’s causal self-attention into bidirectional full attention"
- CLIP: A contrastive image–text pretraining framework widely used for vision encoders. "contrastive pretraining (e.g., CLIP/SigLIP)"
- Contrastive learning: A learning paradigm that pulls matched pairs together and pushes mismatched pairs apart in embedding space. "contrastive learning, optimized for discrimination"
- Contrastive pretraining: Initializing encoders via contrastive objectives on large image–text datasets. "contrastive pretraining (e.g., CLIP/SigLIP)"
- Cross-entropy supervision: Using cross-entropy loss to train the model on next-token prediction or classification targets. "LLM cross-entropy supervision"
- Dense captioning: Producing detailed, fine-grained descriptions that cover many entities and relations in an image. "suppress fine-grained visual cues needed for dense captioning and complex VLM reasoning."
- Distillation loss: A training loss that transfers knowledge from a teacher model to a student model. "implementing a novel distillation loss during a warm-up phase"
- Duration-aware sampling: Sampling videos based on their length to balance distributions across durations. "we implement duration-aware sampling to ensure uniform coverage across varying video lengths"
- Event-level atomic descriptions: Fine-grained, timestamped captions describing specific actions or facts in a video. "Event-level atomic descriptions: Serving as the factual foundation, these are fine-grained, timestamped captions."
- GELU activation: A smooth, Gaussian-inspired activation function used in neural networks. "A 2-layer MLP with GELU activation is randomly initialized as the vision projector."
- Grounding (image grounding): Linking textual phrases to specific regions in an image via spatial coordinates. "image grounding/detection datasets"
- Hierarchical annotation structure: A multi-level labeling scheme (events → chapters → summaries) for video understanding. "construct a hierarchical annotation structure."
- Hierarchical variant of k-means: A scalable clustering approach that applies k-means recursively to refine clusters. "we introduce a hierarchical variant of k-means."
- Integer-based coordinate system: Discrete normalization of bounding boxes to integer ranges for stable text decoding. "All bounding boxes are converted into a unified integer-based coordinate system in the relative space"
- k-means algorithm: A clustering method used to group data points by proximity in embedding space. "using the k-means algorithm."
- Key frames: Video frames selected for higher resolution because they contain significant temporal changes. "TRA classifies frames based on temporal similarity into key frames (capturing rapid temporal changes)"
- Language modeling loss: The standard next-token prediction loss used to align visual features with an LLM. "aligns visual features to a frozen LLM (via language modeling loss)"
- Linear projection layer: A learned linear mapping that converts patches into token embeddings. "map them to token embeddings through a linear projection layer."
- Modality gap: The representational mismatch between different modalities (e.g., vision and language). "thereby minimizing the modality gap"
- MLP-based vision--language projector: A lightweight feed-forward module aligning visual features to the LLM hidden size. "a lightweight MLP-based vision--language projector."
- Non-causal processing: Token processing that is not restricted by temporal order, enabling full-context attention. "Visual patches require non-causal processing"
- Optical flow: Estimation of pixel-wise motion between frames to measure temporal dynamics. "we compute motion scores using optical flow method)"
- QK normalization: Normalization applied to query and key vectors in attention to stabilize training. "such as QK normalization"
- Recaptioning: Regenerating improved, detailed captions for images or video frames to provide richer supervision. "we additionally derive question–answer (QA) pairs from recaptioning results."
- Relation Loss: A loss that aligns pairwise token relationships (self-correlations) between student and teacher features. "(3) Relation Loss: Based on the two losses above, effective supervision can already be achieved."
- Self-correlation similarity: A measure of intra-feature relationships used to supervise token interactions. "leveraging self-correlation similarity to explicitly supervise inter-patch relationships"
- Semantic Priors: Pre-existing linguistic knowledge that aids in grounding visual semantics. "Semantic Priors: It inherits rich linguistic knowledge from the outset"
- SigLIP: A family of contrastive or caption-augmented vision encoders related to CLIP. "SigLIP-2–style vision backbone"
- Saturation-Aware Scaling: A compression stage that clamps intermediate frames at a minimum and further scales key frames. "Compression Stage 3 (Saturation-Aware Scaling)"
- Supervised Fine-Tuning (SFT): Instruction tuning on labeled tasks after pretraining to refine capabilities. "a two-stage Supervised Fine-Tuning (SFT) strategy"
- Temporal grounding: Identifying precise start and end times for actions or events in video. "temporal grounding, which requires identifying the precise start and end timestamps"
- Temporal Redundancy-Aware (TRA) token compression: A method that allocates more tokens to informative frames and fewer to redundant ones. "we introduce a Temporal Redundancy-Aware (TRA) token compression mechanism."
- Token budget: The maximum number of tokens allowed for an input sequence due to model context limits. "Inputs are processed at their original spatial resolution whenever the token budget permits"
- Uniform sampling: Selecting frames evenly across a video when it exceeds a frame cap. "we switch to uniform sampling, extracting a fixed set of spaced equidistantly across the entire video."
- ViT architecture: The Vision Transformer design for image encoding. "ViT architecture~\citep{dosovitskiyimage}"
- Visual backbone: The core vision encoder network that extracts features from images or videos. "the bottleneck for efficient multimodal systems lies not just in the LLM or training data, but in the visual backbone itself."
Collections
Sign up for free to add this paper to one or more collections.