Next-Embedding Prediction Makes Strong Vision Learners
Abstract: Inspired by the success of generative pretraining in natural language, we ask whether the same principles can yield strong self-supervised visual learners. Instead of training models to output features for downstream use, we train them to generate embeddings to perform predictive tasks directly. This work explores such a shift from learning representations to learning models. Specifically, models learn to predict future patch embeddings conditioned on past ones, using causal masking and stop gradient, which we refer to as Next-Embedding Predictive Autoregression (NEPA). We demonstrate that a simple Transformer pretrained on ImageNet-1k with next embedding prediction as its sole learning objective is effective - no pixel reconstruction, discrete tokens, contrastive loss, or task-specific heads. This formulation retains architectural simplicity and scalability, without requiring additional design complexity. NEPA achieves strong results across tasks, attaining 83.8% and 85.3% top-1 accuracy on ImageNet-1K with ViT-B and ViT-L backbones after fine-tuning, and transferring effectively to semantic segmentation on ADE20K. We believe generative pretraining from embeddings provides a simple, scalable, and potentially modality-agnostic alternative to visual self-supervised learning.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Next-Embedding Prediction Makes Strong Vision Learners”
Overview: What is this paper about?
This paper shows a simple way to teach computers to understand images without using labels. Instead of asking a model to make a neat “feature” for an image (like most past methods), the model practices predicting what comes next in a sequence made from the image. This is similar to how LLMs learn by guessing the next word. The authors call their method NEPA, short for Next-Embedding Predictive Autoregression.
Key questions the paper asks
- Can the “guess the next thing” style of training (which works great for language) also make strong vision models?
- Is there a simpler way to train vision models—without lots of extra parts like decoders, contrastive losses, or special tokenizers?
- Will this simple approach transfer well to different tasks, like classifying images and segmenting objects in scenes?
How the method works (in everyday language)
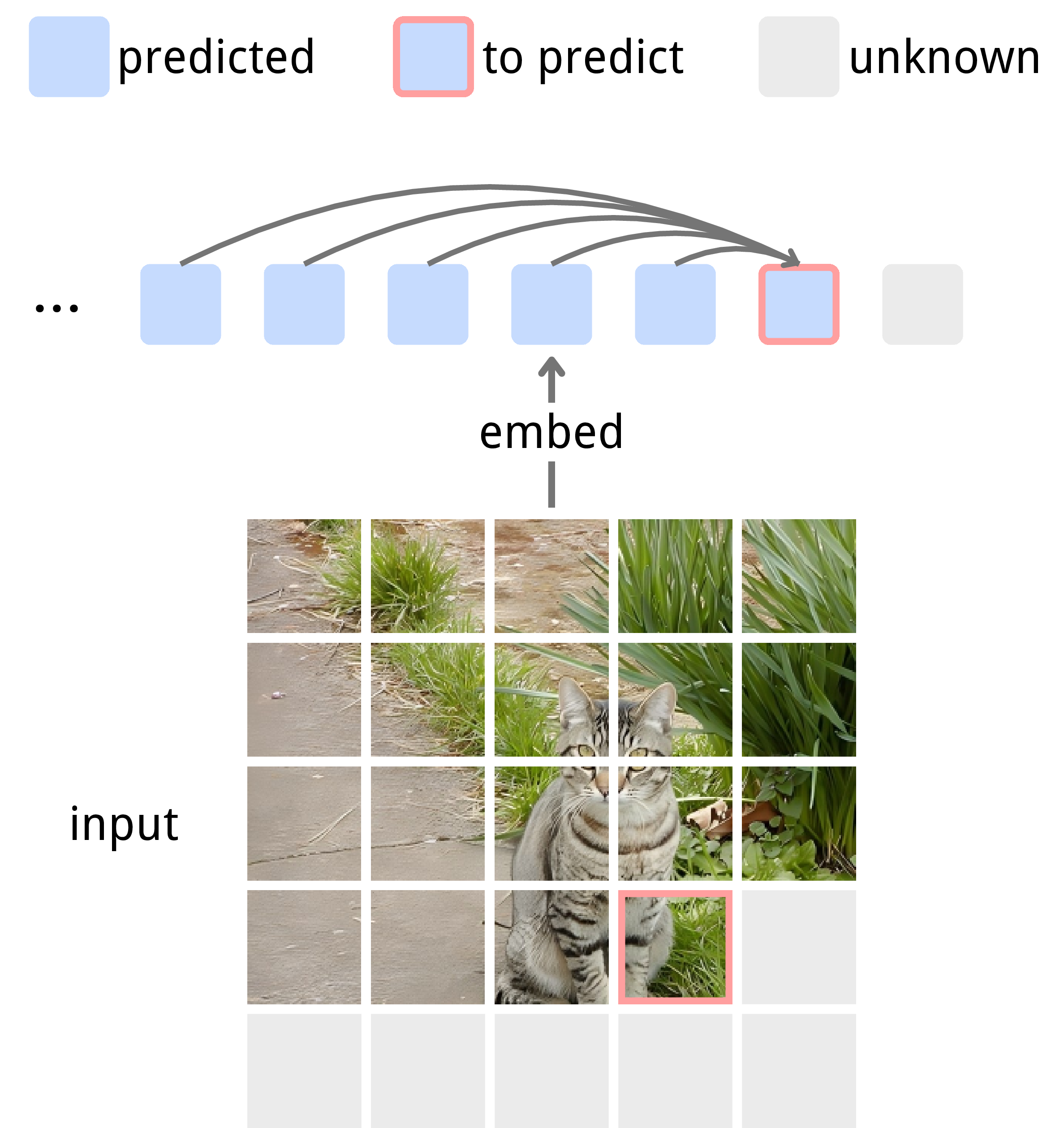
Think of an image as a puzzle made of small square pieces (called patches). For each patch:
- The model turns it into a short list of numbers called an “embedding.” You can think of an embedding like a compact “fingerprint” that captures what’s in that patch.
Now, instead of rebuilding the whole image or comparing two versions of it, the model learns to predict the embedding of the next patch from the ones it has already seen. That’s why it’s called “autoregression”: the model uses past pieces to predict the next piece.
To make this work well, they use three key ideas:
- Causal masking: The model only looks at previous patches, not future ones—like reading left to right and guessing the next word.
- Shifting: The model predicts the next patch’s embedding, not just repeats the current one, so it has to truly “anticipate” what’s coming.
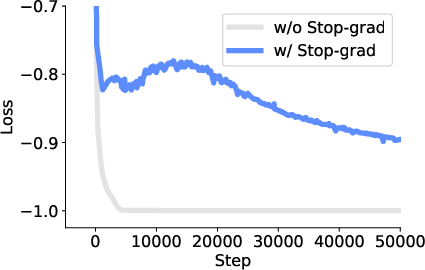
- Stop-gradient: When comparing the model’s prediction to the true embedding, they “freeze” the true embedding during training. This prevents the model from cheating by making everything the same and calling it a match.
How does the model measure if its prediction is good? It compares how close the predicted embedding is to the true embedding using a measure called cosine similarity. Picture two arrows: if they point in the same direction, the similarity is high; if they point differently, the similarity is low. The model tries to make these arrows line up.
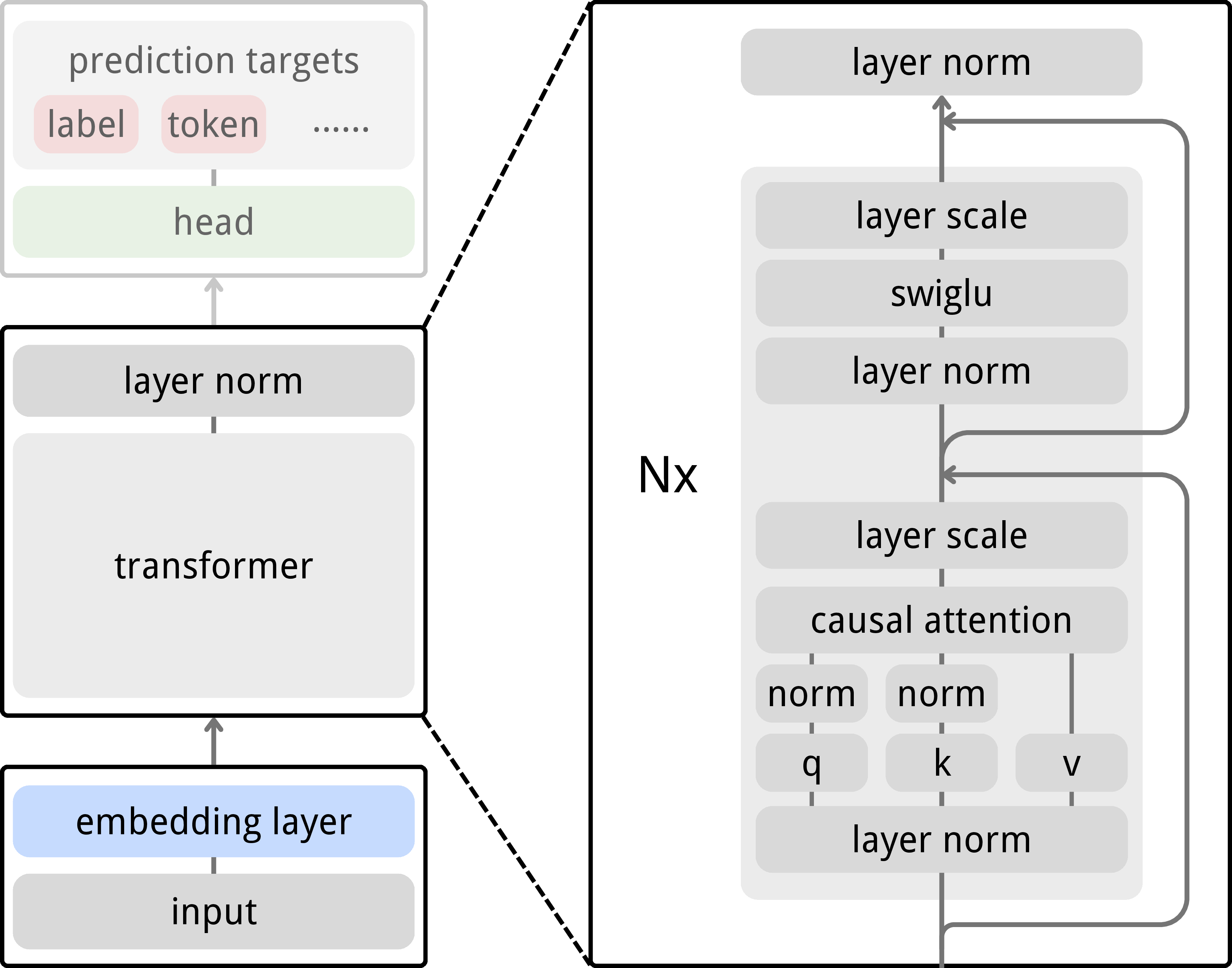
Under the hood, the main model is a Vision Transformer (ViT), a popular architecture for image tasks. The authors keep it simple:
- No pixel-level reconstruction
- No special decoders
- No contrastive pairs or momentum encoders
- Just one Transformer that predicts the next embedding
They do add some training stabilizers (you can think of these as seatbelts for the model):
- RoPE: helps the model understand positions in a sequence
- LayerScale: makes updates gentler and steadier
- SwiGLU: a modern activation function for the model’s “thinking layers”
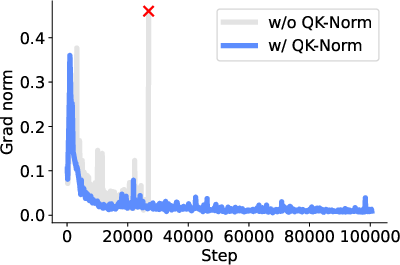
- QK-Norm: keeps attention from blowing up during training
For testing on real tasks, they attach standard heads:
- A linear head for image classification (predicting the label of the whole image)
- A UPerNet head for semantic segmentation (coloring each pixel with the right class)
Main findings and why they matter
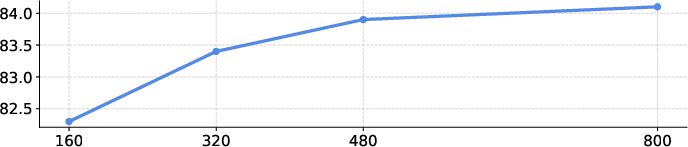
The authors train on ImageNet-1K without labels, then fine-tune with labels. They find:
- Strong classification results:
- ViT-Base (B): 83.8% top-1 accuracy on ImageNet-1K
- ViT-Large (L): 85.3% top-1 accuracy on ImageNet-1K
- Strong segmentation transfer:
- ADE20K mIoU: 48.3% (Base) and 54.0% (Large)
Why is this impressive?
- The model uses a single, simple objective (predict the next embedding) and still matches or beats more complicated methods (like those that rebuild pixels or rely on contrastive tricks).
- It scales well: bigger models and longer training keep improving results.
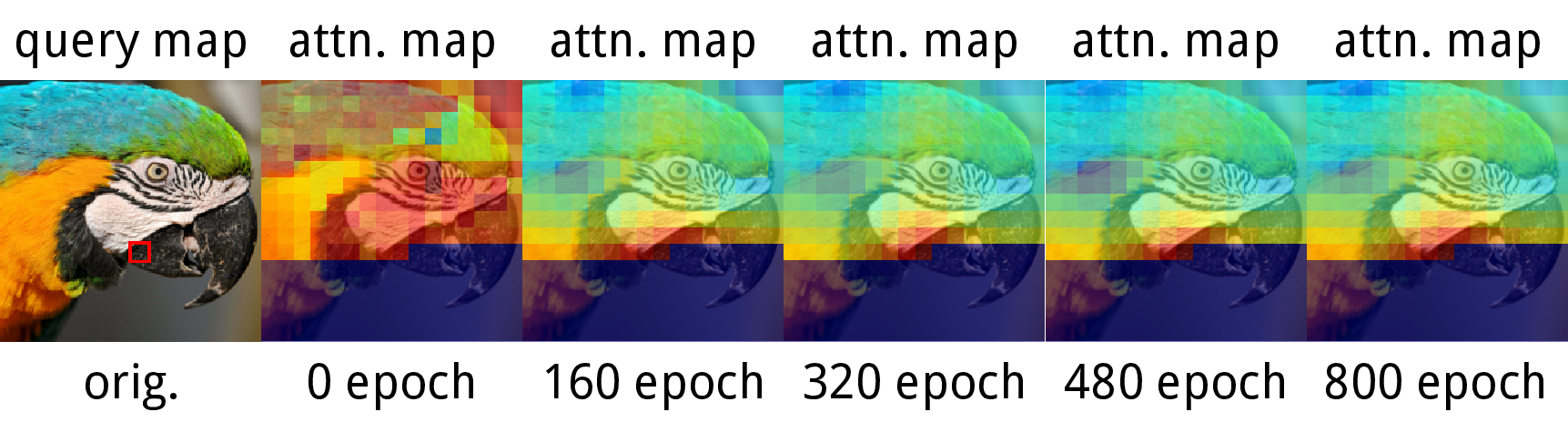
- It learns meaningful “global” understanding: attention maps show the model focuses on semantically related parts of objects, even far away in the image. The predicted embeddings are most similar to patches from the same object, which suggests the model is learning useful, object-centric information.
The authors also run careful tests to see what’s essential:
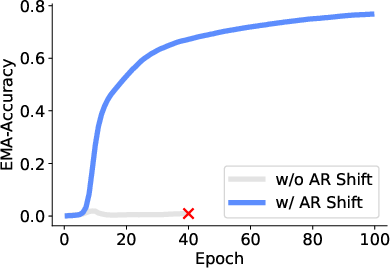
- Removing shifting (so the model stops predicting the next patch) makes training fail later.
- Removing causal masking (allowing the model to see future patches) weakens performance.
- Removing stop-gradient causes training collapse (everything becomes the same).
- Randomly masking inputs (popular in other methods) actually hurts this approach—because the prediction task is already non-trivial.
What this means for the future
This work suggests a clean, powerful idea: train vision models the way we train LLMs—by predicting what comes next—using embeddings instead of raw pixels or tokens. The benefits include:
- Simplicity: fewer parts, easier to scale, one forward pass
- Flexibility: likely to work across different data types (images, text, maybe more), since it relies on predicting embeddings
- Potential for generation: the same approach could be extended to create images if you add a suitable decoder later
In short, NEPA hints at a future where different types of data can be learned with the same simple strategy: learn to anticipate the next piece of information in an embedding space. That could help unify how we train models across vision and language, making strong, versatile learners with less complexity.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a single, consolidated list of gaps and open questions the paper leaves unresolved. Each item is phrased to be concrete and actionable for follow-up research.
- Data scale and diversity: NEPA is pretrained only on ImageNet-1K; its behavior under larger and more diverse corpora (e.g., ImageNet-21K, JFT, LAION, WebVid) remains unknown.
- Downstream breadth: No results on object detection, instance/panoptic segmentation, keypoint estimation, depth/flow, or video tasks; assess transfer and fine-tuning recipes beyond classification and semantic segmentation.
- Zero-/few-shot and frozen evaluation: Linear probing is weak and unoptimized; investigate improved frozen readouts (CLS token, learned pooling, adapters, k-NN), and measure few-shot/sample efficiency versus baselines.
- Robustness and OOD generalization: No quantitative evaluation on distribution shifts (e.g., ImageNet-C/R/A, COCO-OOD), adversarial robustness, or fairness/bias analyses; add standardized robustness suites.
- Efficiency and compute accounting: Training-time/throughput/memory vs. baselines are not reported; provide apples-to-apples compute cost, wall-clock, and energy comparisons at matched accuracy.
- Scaling laws: Only ViT-B/L are studied; characterize performance/stability for ViT-H/g and longer sequences, and derive empirical scaling laws (data, model, steps) for NEPA.
- Patch size and resolution: Patch size is fixed (14); ablate patch sizes, input resolutions, and multi-scale hierarchies to understand sequence length and receptive field trade-offs.
- 2D-to-1D ordering: The causal objective depends on patch sequence order (likely raster); test alternative orders (Hilbert/Z-order curves, learned scan paths, spiral/block orders) and 2D-causal schemes.
- Predictive horizon: NEPA predicts only the next embedding; evaluate k-step ahead prediction, multi-target horizons, scheduled sampling, and free-running generation to study exposure bias and long-range modeling.
- Target embedding choice: Targets are shallow patch embeddings; compare predicting deeper latent features (mid-/last-layer states), tied input–output embeddings, or momentum (teacher) targets and quantify effects.
- Loss formulation: Negative cosine similarity with stop-gradient is the sole objective; test MSE, InfoNCE/VICReg-style losses, whitening/variance regularization, temperatures, and theoretically analyze collapse/stability.
- Stop-gradient mechanism: Stop-grad stabilizes training but its placement and dynamics are not explored; ablate alternative placements (predictor vs. target), partial stop-grad schedules, or teacher–student formulations.
- EMA dependence: Results are reported with EMA (0.9999) but no ablation; quantify EMA’s role in stability/accuracy and its interaction with stop-gradient and normalization choices.
- Attention masking mismatch: Pretrained causally, fine-tuned bidirectionally for segmentation; systematically study attention regime mismatches (causal vs. bidirectional) across tasks and their impact on transfer.
- Head design for classification: Using the last patch embedding as the global representation is unconventional; compare CLS token insertion, learned pooling, and attention pooling; assess sensitivity to head choice.
- Masking strategy: Random masking hurts in NEPA’s setup; explore structured masking (blockwise/semantic), curriculum masking, and causal-aware masking to see if any improve learning signals without corruption.
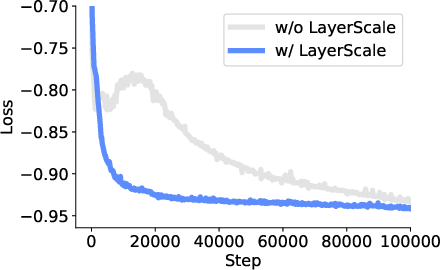
- Normalization/activation dependencies: QK-Norm and SwiGLU are critical for stability; generalize and formalize when these are necessary, and test alternative stabilizers (RMSNorm, scale norms) across depths/scales.
- Positional extrapolation: RoPE is intended to extrapolate to longer sequences; verify performance at higher resolutions or varying sequence lengths not seen in pretraining.
- Generative extension: The paper hypothesizes coupling NEPA with a decoder/diffusion model; prototype and evaluate embedding-to-image generation, sampling strategies, and training objectives for synthesis/editing.
- Modality-agnostic claim: The “shared embedding currency” hypothesis is not validated; test NEPA on audio/video/text embeddings and in cross-modal settings (vision–language pretraining/alignment).
- Quantitative attention analysis: Attention maps are qualitative; add quantitative measures (e.g., attention-to-instance IoU, unsupervised segmentation scores) and correlate with downstream performance.
- Failure modes: Reflections, shadows, small/overlapping objects cause errors; examine whether multi-view/3D cues, photometric augmentations, or higher-resolution contexts mitigate these failures.
- Curriculum and augmentation in pretraining: Pretraining uses minimal augmentation (RandomResizedCrop); ablate stronger augmentations, curriculum strategies, and view diversity to balance invariance vs. predictiveness.
- Teacher forcing and exposure bias: Autoregressive training may suffer exposure bias; assess scheduled sampling, noise injection, and free-running evaluation to quantify and address this.
- Reproducibility of hyperparameter search: The “lightweight hyperparameter search” per epoch is unspecified; detail search spaces and ensure fair comparisons across baselines with matched tuning budgets.
Practical Applications
Below is a concise mapping from the paper’s findings and methods to practical, real-world uses. Each item specifies sectors, potential tools/products/workflows, and critical assumptions or dependencies that affect feasibility.
Immediate Applications
- Strong, simple self-supervised pretraining for vision backbones
- Sectors: software/AI platforms, enterprise AI, cloud ML services
- What: Replace or complement contrastive/masked-image-modeling pretraining with NEPA for ViT backbones to improve classification/segmentation without decoders, negative pairs, or complex auxiliary heads.
- Tools/workflows: Hugging Face Transformers/timm/MMDet/MMSeg; plug-and-play ViT-B/L backbones; standard fine-tuning with UPerNet for segmentation; optional bidirectional attention at fine-tune time.
- Assumptions/dependencies: Access to large unlabeled image corpora and GPUs; downstream tasks similar to ImageNet/ADE20K; bias auditing for pretraining data; linear probing is weak—expect to fine-tune.
- Rapid domain adaptation with unlabeled data
- Sectors: manufacturing (defect detection), retail (shelf/inventory), agriculture (crop/disease), logistics (package inspection)
- What: Pretrain NEPA on in-domain unlabeled images to reduce labeled data needs; fine-tune small heads for classification/segmentation.
- Tools/workflows: Data lake ingestion → NEPA pretraining → lightweight fine-tune with cross-entropy/pixel-wise CE → deployment.
- Assumptions/dependencies: In-domain unlabeled scale matters; compute budget; ensure causal pretraining and enable bidirectional attention at fine-tuning for dense tasks.
- Semantic segmentation as a service with simplified training
- Sectors: autonomous driving/robotics, geospatial, construction/inspection
- What: Use NEPA backbones with UPerNet to deliver scene parsing/semantics; strong ADE20K transfer suggests a robust starting point.
- Tools/workflows: Replace existing SSL backbones with NEPA in MMSeg pipelines; hyperparameter parity with MAE/BEiT recipes; freeze patch embed or use layer-wise LR decay as in paper.
- Assumptions/dependencies: Spatial context benefits from bidirectional attention during fine-tune; annotation quality remains critical.
- Medical imaging pretraining with limited labels
- Sectors: healthcare
- What: Self-supervised pretrain on PACS-scale unlabeled images (e.g., CT, MRI, histopathology) to bootstrap classification/segmentation tasks with small labeled sets.
- Tools/workflows: DICOM ingestion, NEPA pretraining on modality-specific crops/patch sizes, HIPAA-compliant pipelines, fine-tune segmentation/classification heads.
- Assumptions/dependencies: Domain shift from natural images; patching strategy and positional encoding suitability; regulatory validation and bias checks.
- Document and form understanding
- Sectors: finance, insurance, government, enterprise operations
- What: Pretrain NEPA on scanned documents to improve layout-aware classification/segmentation (e.g., table/field detection, region-of-interest extraction).
- Tools/workflows: Patchify high-res documents; fine-tune with detection/segmentation heads; integrate with OCR for end-to-end pipelines.
- Assumptions/dependencies: Text-rich images may benefit from hybrid pipelines with OCR/LLMs; training at higher resolutions increases sequence length and compute.
- Privacy and content moderation utilities
- Sectors: consumer apps, social media, legal/compliance
- What: Use NEPA-based segmentation to enable face/license-plate redaction, background removal, NSFW/PII masking.
- Tools/workflows: NEPA backbone + segmentation head; rules-based post-processing; privacy auditing.
- Assumptions/dependencies: Robustness across demographic and lighting variations; ongoing monitoring for fairness/accuracy.
- Anomaly localization via predictive error in embedding space
- Sectors: industrial inspection, cybersecurity camera analytics
- What: Treat cosine distance between predicted and actual next patch embeddings as an unsupervised anomaly signal to highlight unusual regions.
- Tools/workflows: Run NEPA on production imagery; threshold prediction error; human-in-the-loop review.
- Assumptions/dependencies: Threshold calibration; sensitivity to complex reflections/shadows (noted failure modes); domain-specific tuning.
- Explainability and model diagnostics
- Sectors: regulated industries, ML Ops, academia
- What: Use attention and embedding-similarity visualizations from NEPA for dataset QA, bias spotting, and qualitative model inspections.
- Tools/workflows: Attention heatmap tooling; per-sample reports in CI for model updates.
- Assumptions/dependencies: Visual explanations require expert interpretation; interpretability is qualitative, not a formal guarantee.
- Teaching and research baselines in self-supervised vision
- Sectors: academia, corporate research labs
- What: Leverage NEPA’s minimal objective (no decoder/tokens/negatives) as a clean baseline for courses, ablation studies, and method prototyping.
- Tools/workflows: Short training runs on ImageNet-1K or smaller datasets; ablations of RoPE/LayerScale/QK-Norm.
- Assumptions/dependencies: Compute access; consistent recipes (LayerScale, QK-Norm) to avoid instability.
Long-Term Applications
- Unified multimodal autoregressive embedding learners
- Sectors: foundation models, multimodal AI, assistive tech
- What: Extend NEPA’s next-embedding prediction to audio, video, and text embeddings for a modality-agnostic learner with a single objective.
- Tools/products: Cross-modal encoders sharing positional/rotary embeddings; multi-sensor fusion in a unified transformer.
- Assumptions/dependencies: Scalable training on diverse, synchronized datasets; careful modality-specific patching; alignment across embedding spaces.
- Image generation and editing via coupled decoders
- Sectors: creative tools, design, advertising, content creation
- What: Pair NEPA with an image decoder or diffusion model to enable generation/editing guided by autoregressive embedding predictions.
- Tools/products: NEPA + diffusion/transformer decoder; promptable editing GUIs; pipeline for inpainting/outpainting.
- Assumptions/dependencies: Additional training for decoders; safeguarding against harmful content; provenance/watermarking requirements.
- Video understanding and anticipation
- Sectors: autonomous driving, sports analytics, surveillance, robotics
- What: Generalize NEPA to spatiotemporal patches to predict future embeddings across frames, enabling anticipation and temporal reasoning.
- Tools/products: Spatiotemporal ViTs with causal masks over space-time; action anticipation heads; safety monitors.
- Assumptions/dependencies: Longer sequences raise compute/memory; dataset scale and temporal annotations; evaluation on safety-critical benchmarks.
- Open-world and low-label detection/segmentation
- Sectors: edge/IoT, safety monitoring, wildlife conservation
- What: Use NEPA to pretrain robust backbones for open-vocabulary or few-shot detection/segmentation with minimal labels.
- Tools/products: NEPA + DETR/Mask2Former-style heads; metric-learning adapters for novel classes.
- Assumptions/dependencies: Additional research for detection heads and open-vocab alignment; negative transfer mitigation.
- On-device and edge-efficient perception via distillation
- Sectors: mobile, AR/VR, drones
- What: Distill NEPA’s predictive capabilities into smaller student models for low-latency, power-constrained devices.
- Tools/products: Knowledge distillation using next-embedding prediction losses; quantization/pruning; runtime optimization.
- Assumptions/dependencies: Distillation recipes for causal transformers; maintaining accuracy under aggressive compression.
- Active learning and data curation using prediction uncertainty
- Sectors: enterprise ML Ops, data labeling services
- What: Use embedding prediction errors/uncertainty to select samples for labeling, prioritize rare phenomena, and detect dataset drift.
- Tools/products: Active learning dashboards; auto-curation pipelines; continual learning loops.
- Assumptions/dependencies: Reliable uncertainty measures; guardrails against reinforcing spurious correlations; human oversight.
- Robotics foundation models integrating perception with control
- Sectors: industrial automation, home robotics
- What: Combine predictive vision embeddings with control/planning modules for closed-loop, context-aware behavior.
- Tools/products: Perception stacks where NEPA is the visual front-end; shared embedding bus for sensor fusion.
- Assumptions/dependencies: Real-time constraints; sim-to-real transfer; safety/regulatory validation.
- Governance, compliance, and standards for self-supervised pretraining
- Sectors: policy, compliance, legal
- What: Develop standards for dataset documentation, bias assessment, and monitoring tailored to unlabeled pretraining regimes like NEPA.
- Tools/products: Model cards with SSL-specific risk profiles; data provenance tracking; deployment checklists.
- Assumptions/dependencies: Evolving regulations; organization-wide processes for ongoing audits and redress mechanisms.
- Domain-specific regulated pipelines (e.g., clinical deployment)
- Sectors: healthcare, aviation, public safety
- What: Rigorous validation and post-market surveillance frameworks for NEPA-pretrained models in regulated settings.
- Tools/products: Trial protocols, post-hoc explainability toolkits; monitoring infrastructure.
- Assumptions/dependencies: Extensive clinical/field validation; harmonization with standards (e.g., FDA, CE).
Notes on cross-cutting dependencies and assumptions:
- Compute and data scaling: While NEPA simplifies architecture (one forward pass, no decoder), high-quality results still require substantial compute and sufficient unlabeled data.
- Domain shift: Results are reported on natural images (ImageNet-1K) and ADE20K; specialized domains (medical, satellite) need careful patching, positional encoding choices, and fine-tuning.
- Fine-tuning details matter: Bidirectional attention improves dense tasks; layer-wise LR decay and freezing early layers can stabilize training.
- Bias and safety: Self-supervised pretraining can inherit and amplify dataset biases; monitoring, bias audits, and responsible data sourcing are essential.
- Current limitations: Difficult cases include reflections/shadows, clutter with many small/overlapping objects, and weak linear probing—expect to rely on end-to-end fine-tuning rather than shallow heads.
Glossary
- ADE20K: A widely used benchmark dataset for scene parsing and semantic segmentation. "and transferring effectively to semantic segmentation on ADE20K."
- AdamW: An optimizer that decouples weight decay from the gradient update to improve training stability. "optimizer & AdamW \cite{loshchilov2018adamw}"
- Autoregression: A modeling approach that predicts the next element in a sequence conditioned on previous elements. "An autoregressive model predicts the next embedding from previous ones, mirroring next-token prediction in LLMs."
- Bidirectional attention: An attention setting where tokens can attend to both past and future tokens. "we disable causal masking and allow bidirectional attention during fine-tuning."
- Causal attention: Attention constrained so each token can attend only to preceding tokens, enabling autoregressive prediction. "Fine-tuning uses causal attention."
- Causal masking: A masking strategy that enforces causal attention by preventing tokens from attending to future positions. "models learn to predict future patch embeddings conditioned on past ones, using causal masking and stop gradient"
- CLIP: A vision-LLM that aligns text and image representations in a shared embedding space. "CLIP can be interpreted as cross-modal embedding prediction aligning text and image representations"
- Contrastive learning: A self-supervised paradigm that trains models to bring similar pairs together and push dissimilar pairs apart. "none of the engineered data augmentations, negative pairs, or momentum encoders common in contrastive learning."
- Contrastive Predictive Coding (CPC): A self-supervised method that predicts future representations using a contrastive loss over negatives. "Contrastive Predictive Coding (CPC) and related frameworks apply this principle in practice"
- Conv2d patch embedder: A convolutional layer used to convert image patches into token embeddings. "Images are tokenized via a Conv2d patch embedder before entering a pre-norm Transformer with LayerNorm."
- Cross-entropy loss: A classification loss measuring the divergence between predicted probabilities and true labels. "We train this head using the cross-entropy loss over the predicted logits and the ground-truth label ."
- CutMix: A data augmentation technique that cuts and pastes image regions and mixes labels accordingly. "cutmix~\citep{yun2019cutmix}"
- DINOv3: A self-supervised vision training recipe emphasizing distillation and stabilization techniques. "To improve stability and scalability, we incorporate modern training and normalization practices inspired by DINOv3~\citep{siméoni2025dinov3} and VisionLLaMA~\citep{chu2024visionllama}, as shown in Figure~\ref{fig:model}."
- DropPath: Stochastic depth regularization that randomly drops residual connections during training. "and DropPath~\citep{huang2016droppath}."
- EMA (Exponential Moving Average): A technique that maintains a smoothed average of model parameters to stabilize evaluation. "All reported results are obtained using the exponential moving average (EMA~\citep{tarvainen2017mean}) model with an EMA decay rate of $0.9999$."
- GeLU: The Gaussian Error Linear Unit, a smooth nonlinear activation used in transformers. "We replace the standard GeLU activation~\citep{hendrycks2017gelu} in vision transformer feed-forward networks~\citep{dosovitskiy2020vit} with the SwiGLU activation~\citep{shazeer2020glu}."
- Generative pretraining: Pretraining that trains models to generate or predict data rather than merely extract features. "Inspired by the success of generative pretraining in natural language, we ask whether the same principles can yield strong self-supervised visual learners."
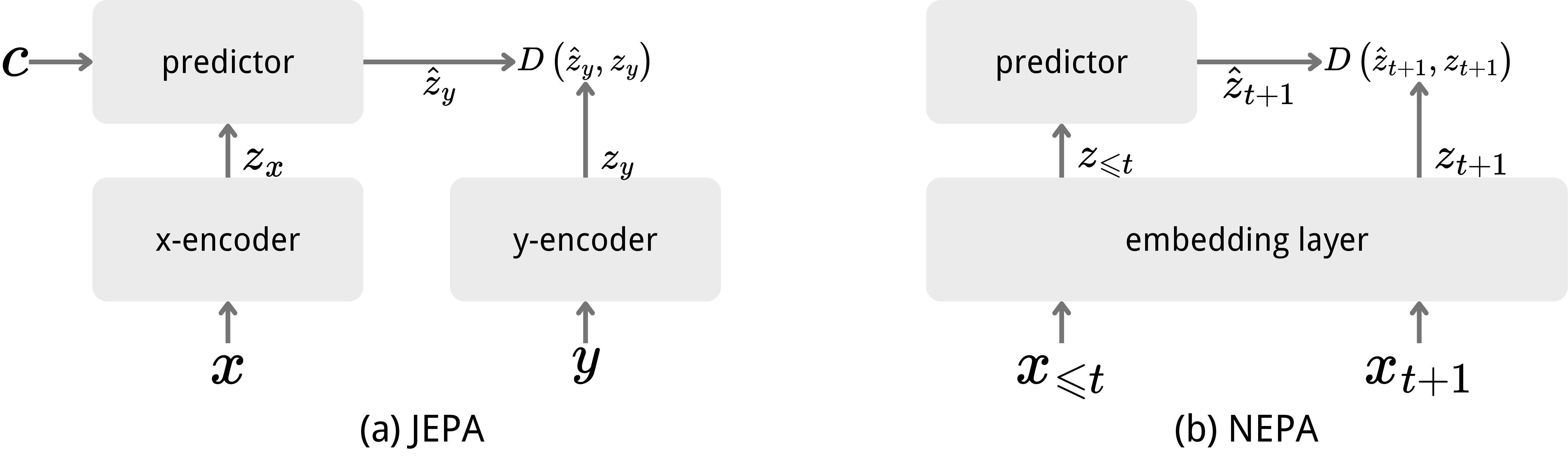
- JEPA: Joint-Embedding Predictive Architecture that predicts latent targets to learn semantic representations. "JEPA~\citep{assran2023jepa} moves beyond pixels by predicting latent targets and aligning more closely with semantic structure."
- Label smoothing: A regularization technique that prevents overconfidence by softening target labels. "label smoothing~\citep{szegedy2016label}"
- LayerNorm: A normalization method applied per layer to stabilize and accelerate training. "We adopt a pre-norm design with LayerNorm~\citep{ba2016layernormalization} and apply a final LayerNorm to the output features."
- LayerScale: Learnable per-channel scaling of residual branches to improve training stability. "We adopt LayerScale~\citep{touvron2021cait} to stabilize training"
- Linear probing: Evaluating representations by training a simple linear classifier on frozen features. "NEPA performs poorly under standard linear probing."
- Masked autoregression: An autoregressive generation scheme that uses masks to combine ordered generation with broader context. "masked autoregression blends bidirectional context with ordered generation for efficiency and quality~\citep{li2024mar, wu2025dcar, chang2022maskgit, li2023mage}."
- Masked image modeling: Self-supervised training by reconstructing masked parts of images or tokens. "masked image modeling paradigms such as MAE"
- Mixup: An augmentation that linearly blends pairs of inputs and labels to improve generalization. "mixup~\citep{zhang2018mixup}"
- mIoU (mean Intersection-over-Union): A standard metric for semantic segmentation accuracy over classes. "reporting mean Intersection-over-Union (mIoU)."
- Momentum encoder: An auxiliary encoder updated via momentum to provide stable targets in self-supervised learning. "momentum encoders common in contrastive learning."
- NEPA (Next-Embedding Predictive Autoregression): The proposed method that predicts future patch embeddings in a causal, autoregressive manner. "We call this new family of models Next-Embedding Predictive Autoregression (NEPA)."
- Negative cosine similarity: A similarity-based loss that minimizes the cosine similarity between predicted and target vectors. "the similarity is measured via negative cosine similarity:"
- Negative pairs: Non-matching sample pairs used in contrastive objectives to repel representations. "none of the engineered data augmentations, negative pairs, or momentum encoders common in contrastive learning."
- Patch embedding layer: The initial module that maps image patches into a sequence of embeddings. "we freeze the patch embedding layer during fine-tuning"
- Pre-norm: A transformer design that applies normalization before attention and MLP sublayers. "We adopt a pre-norm design with LayerNorm~\citep{ba2016layernormalization}"
- QK-Norm (Query-Key Normalization): Normalization applied to attention queries and keys to stabilize training. "we adopt query-key normalization (QK-Norm~\citep{henry2020qknorm})."
- RandAugment: A randomized augmentation strategy with controlled magnitude and number of transformations. "including layer-wise learning rate decay~\citep{clark2020llrd, bao2022beit}, RandAugment~\citep{dubuk2020randaugement}, label smoothing~\citep{szegedy2016label}, mixup~\citep{zhang2018mixup}, cutmix~\citep{yun2019cutmix}, and DropPath~\citep{huang2016droppath}."
- Random masking: Stochastically hiding parts of the input during training to alter learning signals. "We also applied random masking to the input embeddings"
- RoPE (Rotary Position Embedding): A positional encoding method using complex rotations to encode relative positions in attention. "We adopt Rotary Position Embedding (RoPE~\citep{su2024roformer}) at all layers to encode relative positions via complex rotations in attention."
- Self-distillation: Self-supervised training where a model learns from its own (or a teacher’s) outputs to improve representations. "Early progress was driven by contrastive and self-distillation approaches"
- Shifting: Offsetting the prediction target to the next token so the task cannot be solved by identity mapping. "In our default setup, the model predicts the embedding of the next token rather than copying the current input."
- SimSiam: A self-supervised method that uses a stop-gradient and similarity loss without negative samples. "we adopt a similarity-based loss inspired by SimSiam~\citep{chen2020simsiam}."
- Stop-gradient: An operation that prevents gradients from flowing through specified tensors to avoid collapse. "we follow~\citet{chen2020simsiam} and apply a stop-gradient operation to the target embeddings."
- SwiGLU: A gated activation function that improves transformer feed-forward expressivity and training. "We replace the standard GeLU activation~\citep{hendrycks2017gelu} in vision transformer feed-forward networks~\citep{dosovitskiy2020vit} with the SwiGLU activation~\citep{shazeer2020glu}."
- UPerNet: A segmentation head that aggregates multi-scale features in a unified pyramid network. "for semantic segmentation, we adopt a UPerNet head~\citep{xiao2018upernet}"
- Vision Transformer (ViT): A transformer-based architecture for images that operates on patch embeddings. "We adopt a standard Vision Transformer (ViT) backbone~\citep{dosovitskiy2020vit} with causal attention masking."
Collections
Sign up for free to add this paper to one or more collections.

