- The paper introduces NEO-ov, a unified encoder-free architecture that serializes images, videos, and text to enable native multimodal reasoning.
- It employs native rotary position embeddings and unified attention to capture spatial and temporal dependencies, enhancing fine-grained perception and spatial intelligence.
- Experimental results demonstrate that NEO-ov outperforms modular VLMs in VQA, OCR, and spatial benchmarks, validating its effectiveness in holistic vision-language modeling.
Native One-Vision Foundation Models at Scale: Analysis of NEO-ov
Introduction and Motivation
The modular design of current Vision-LLMs (VLMs)—relying on separate image encoders and language decoders joined via multi-stage alignment—introduces architectural inefficiencies such as fragmented pixel-level signals, late fusion of modalities, and poor scalability when extending to diverse input streams (e.g., videos, multi-image contexts). Native VLMs offer a monolithic alternative, positing that end-to-end learning from raw pixels and text in a unified decoder-only architecture admits richer cross-modal alignment and potentially superior generalization. However, early native models have been limited in scope, excelling primarily on single-image tasks and lacking comprehensive spatial-temporal modeling capabilities.
"From Pixels to Words -- Towards Native One-Vision Models at Scale" introduces NEO-ov, a foundation model for unified vision-language tasks without external visual encoders or post-hoc fusion, enabling joint spatiotemporal and pixel-word reasoning within a single autoregressive backbone. The claim is that such native one-vision models not only approach but compete with modular VLMs across an extensive suite of benchmarks, while advancing fine-grained perception and spatial intelligence.
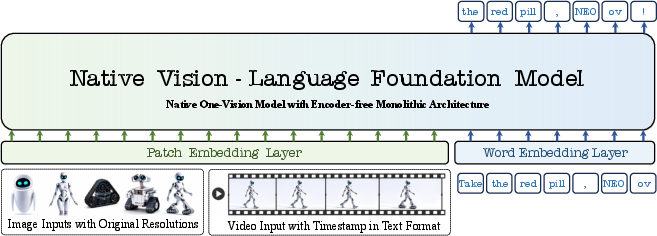
Figure 1: The overall structure of NEO-ov highlighting the direct serialization of image/video and text inputs, processed jointly in a single decoder-only architecture for native multimodal alignment and reasoning.
Architectural Design: Native Serialization and Spatial-Temporal Attention
NEO-ov’s input pipeline serializes raw images, videos, and text into a unified token sequence. Instead of employing a heavy visual encoder, images and frames are converted to visual tokens via a lightweight two-stage convolutional patch embedding. Tokens are wrapped with explicit boundary markers (<img>, </img>) and merged with language tokens; the resulting sequence is passed to a single-stack decoder-only backbone composed of native primitives capable of handling both spatial and temporal dependencies.
Key architectural features include:
Training Methodology: Progressive Multi-Stage Optimization
NEO-ov is trained in three distinct stages:
- Pre-training: Alignment of visual patch embeddings and pre-buffer layers with a pretrained LLM, restricted to approximately 20 million image-text pairs. Only visual embedding and newly introduced attention parameters are optimized to prevent catastrophic forgetting of language priors.
- Mid-training: All model parameters are jointly optimized on a diverse, large-scale corpus (∼60 million multimodal instances) with progressively increasing context length, input resolution, and temporal sequence (up to 36k tokens and 128 video frames). The curriculum includes mixed single-image, multi-image, video, and text-only data in an empirically balanced ratio.
- Supervised Fine-tuning: High-quality instruction-tuning data (including challenging tasks such as spatial reasoning, math, and dialogue) is used to focus the model’s multimodal instruction-following, fine-grained perception, and temporal understanding capabilities.

Figure 3: Progressive curriculum: visual-language pre-alignment, spatiotemporal scaling, and instruction tuning reinforce both low-level perception and high-level reasoning.
Experimental Results and Empirical Findings
NEO-ov demonstrates state-of-the-art performance among native VLMs, surpassing prior models such as NEO, EVE, Mono-InternVL, and HoVLE on an extensive suite of general VQA, spatial intelligence, and video understanding tasks. On several reasoning-intensive and hallucination-sensitive benchmarks—including MMMU, HallB, and InfoVQA—NEO-ov closes the gap with, and in several instances outperforms, modular state-of-the-art models like InternVL3.5 and Qwen3-VL, without any external visual encoder. The model’s strong results in multi-image and video domains (e.g., BLINK, MUIRBENCH, VideoMMME, MVBench) are attributed to the joint spatial-temporal native attention that emergently learns long-range and fine-grained inter-frame relations.
The results on spatial intelligence benchmarks (VSI-Bench, MMSI, Mindcube, 3DSR, Omni-Spatial) confirm that native architectures with deep pixel-pixel and pixel-word interactions support geometric reasoning and spatial localization at a level competitive with or exceeding that of both general-purpose and spatial-specialist modular models.
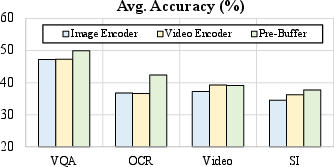
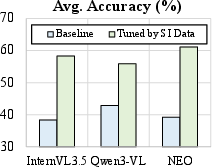
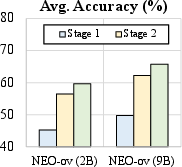
Figure 4: Comparative analysis of Pre-Buffer vs. Standard Visual Encoders, highlighting performance superiority of the native architecture on VQA, video, OCR, and spatial intelligence benchmarks.
Ablation Studies and Analysis
- Pre-Buffer vs. Visual Encoder: The empirical evidence supports the claim that early and deep pixel-word alignment—not possible with compressed encoder outputs—enables better preservation of local geometric and semantic details, substantially benefitting OCR and spatial tasks.
- Stage-wise Performance Gains: Each progressive stage of training yields significant improvements, especially for smaller model variants, empirically justifying the proposed curriculum design.
Implications and Future Directions
NEO-ov advances an encoder-free native paradigm for unified vision-language modeling, suggesting that end-to-end autoregressive architectures can achieve state-of-the-art performance in holistic multimodal understanding. The results strongly indicate that the elimination of explicit vision encoder modules does not impede, and may even enhance, fine-grained perception and spatiotemporal reasoning. The architecture’s flexible context window, fully shared backbone, and sequence-level modeling also open pathways for efficient scaling and task-agnostic deployment.
There remain several open problems: further closing the remaining gap with top-tier modular VLMs, especially on single-image and OCR tasks; scaling the approach to even larger corpora and longer contexts; and exploring the impact of higher-quality annotation for document-centric and dense-text benchmarks. As native modeling matures, research should target more universal evaluation, tighter integration with audio/other modalities, and interpretability of emergent alignment phenomena.
Conclusion
NEO-ov demonstrates that a fully native, encoder-free, autoregressive architecture is not only feasible but highly competitive as a foundation model for multimodal understanding across image, video, and spatial intelligence domains (2605.28820). Its architectural and empirical advances position native one-vision models as a promising direction for scalable, general-purpose vision-language modeling and provide foundational insights into unified autoregressive learning in high-dimensional multimodal spaces.


