- The paper introduces SWE-interact, a benchmark that transforms one-shot tasks into iterative, multi-turn, user-driven coding sessions.
- It employs a realistic user simulator to reveal agent weaknesses in maintaining goal state and integrating evolving requirements.
- Evaluation shows that strong models face performance drops and increased errors in extended interactive workflows.
SWE-interact: Benchmarking Coding Agents in Realistic Multi-Turn Developer Workflows
Reframing SWE Benchmark Difficulty via User-Driven Interaction
SWE-interact (2606.30573) introduces a fundamentally different axis for evaluating coding agents, shifting from traditional one-shot, fully specified software engineering (SWE) benchmarks to multi-turn, user-driven coding sessions. Rather than starting from comprehensive requirements and measuring autonomous completion, SWE-interact emulates an authentic developer workflow, where the coding agent receives vague instructions, iteratively interacts with a persona-conditioned user simulator, progresses through goal discovery, and revises its implementation according to evolving requirements. This paradigm tests agent competence in a contextually rich, highly interactive setting. As illustrated in (Figure 1), SWE-interact converts static issue-resolution tasks into long-horizon developer conversations, with the agent required to discover latent goals and adapt its codebase progressively.
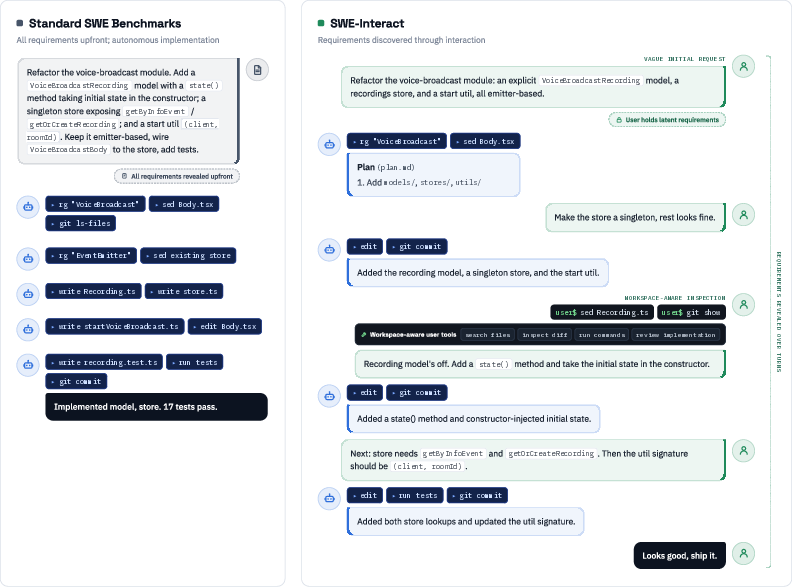
Figure 1: SWE-interact reframes SWE benchmarks by decomposing coding sessions into a multi-turn workflow where user requirements evolve and are surfaced through targeted feedback and revision.
Sandbox Architecture and User Simulation Design
The SWE-interact environment is architected for modularity and realism, separating the agent's workspace from the user simulator's context container (Figure 2). The user simulator embodies a rigorously designed persona, derived from large-scale analysis of real coding-agent sessions in SWE-chat, notably modeling the "Expert Nitpicker"—a persona characterized by terse, iterative feedback and incremental requirement revelations. Equipped with shell access, the simulator can inspect the agent's workspace and provide grounded critiques, escalating the difficulty by layering requirements and exposing only relevant details per revision. This interactive harness emulates the real-world "vibecoding" interaction mode, where users guide agents with minimal but precise feedback.
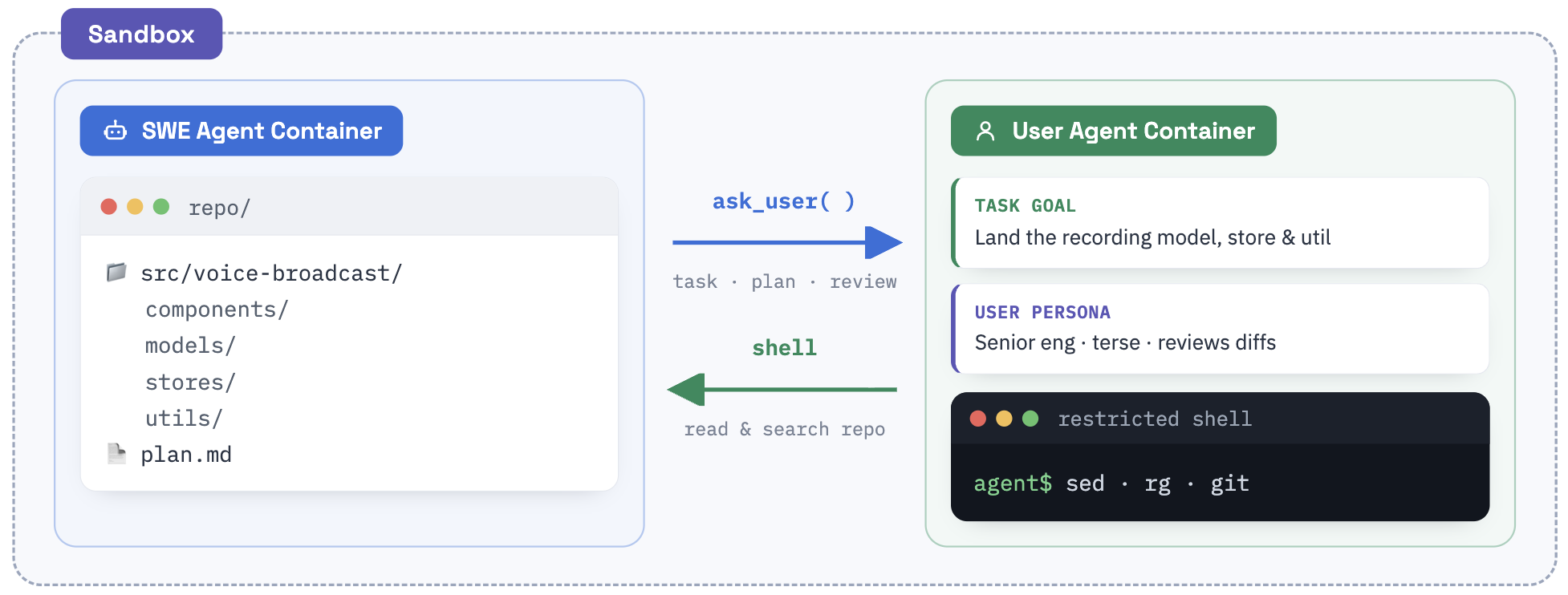
Figure 2: Modular sandbox architecture where the agent operates within its workspace and interacts with a tool-enabled persona-conditioned user simulator.
Task Construction and Evaluation Methodology
SWE-interact comprises 75 tasks adapted from leading SWE benchmarks: SWE-bench Pro, SWE Atlas (refactoring), and DeepSWE. Each task is manually decomposed to support layered requirements and iterative handoff. The evaluation protocol retains the original unit-test and rubric-based verifiers, ensuring that quantitative performance shifts arise purely from the change in interaction modality. The agent commits checkpoints at each revision, facilitating detailed trajectory analysis. Task execution leverages the Harbor framework, providing isolation and traceability across interaction turns.
Empirical Results: Multi-Turn vs. Single-Turn Benchmarking
Quantitative evaluation demonstrates a robust divergence between single-turn and multi-turn settings. Strong frontier models (Opus 4.8, GPT 5.5) resolve ~50% of single-turn tasks but only ~25% of multi-turn SWE-interact tasks, despite incurring a 3-4x increase in interaction length, token consumption, and computational cost. Performance degradation arises not from mere interaction length, but from agents' inability to reliably maintain goal state, adapt to evolving requirements, and mitigate technical errors within extended collaborative workflows.
Interaction Metrics and User-Agent Dynamics
SWE-interact systematically logs agent-user interaction counts and tool call frequency for each trial (Figure 3). The average session involves seven user-agent exchanges and extensive workspace inspection by the user simulator, with trajectory lengths ranging up to 27 turns and hundreds of tool invocations. Notably, weaker models often fail early, missing critical requirements, while stronger models persevere, integrate feedback, and maintain session coherence across iterations.
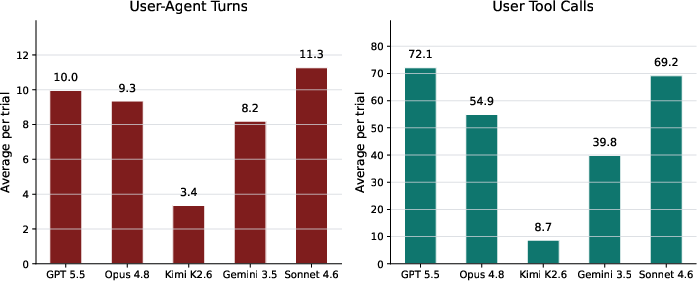
Figure 3: Quantitative summary of agent-user interaction counts and user-initiated tool calls per trial.
Goal Discovery Analysis and Lifecycle Tracking
SWE-interact benchmarks progress via a rubric-driven decomposition: atomic requirements are revealed, scored, and bins as checkpoints—plan, intermediate revisions, and final implementation (Figure 4). Strong models often exhibit high initial plan coverage but drop in early implementation, recovering as user feedback accumulates. Goal coverage is necessary—but not sufficient—for task resolution: nearly all verifier-passing solutions have high rubric scores, but many high-scoring implementations still fail due to technical bugs or missed requirements.
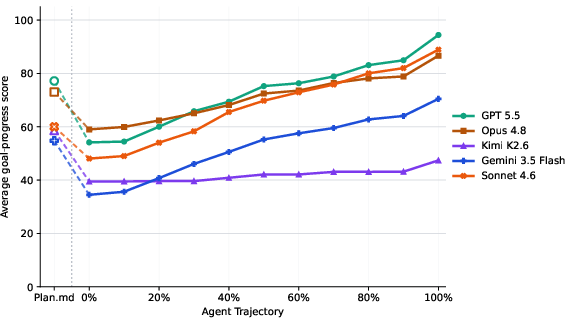
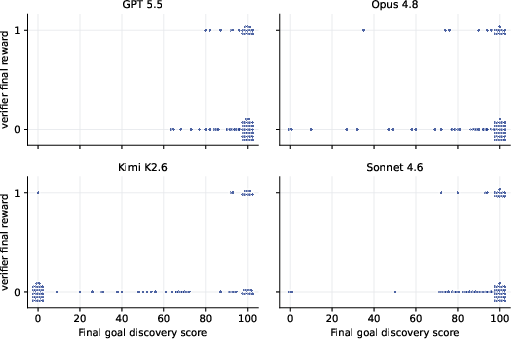
Figure 4: Progression of goal discovery across planning and implementation checkpoints for agents on SWE-interact tasks.
Failure Mode Taxonomy and Distribution
Failure modes are systematically audited, with the dominant categories being technical implementation bugs and forgotten requirements—each comprising about a third of failures. Other modes include regressions, misinterpretations, and cases where necessary requirements are never surfaced by the simulator (the latter indicating benchmark coverage gaps). Model performance reveals fundamental deficits in persistent goal tracking, requirement integration, and error recovery in extended user-driven workflows.
Code Quality and Revision Churn Metrics
Revision overhead and late-change share, computed from line additions/deletions across iterative checkpoints, indicate that strong models (Opus 4.8, GPT 5.5) produce cleaner, more stable code with less cumulative churn compared to weaker agents (Figure 5). Efficient upfront goal capture minimizes unnecessary code rework and late-stage refactor overhead.
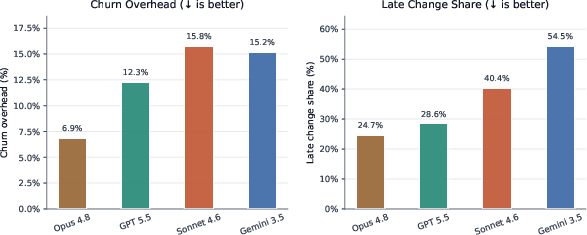
Figure 5: Revision churn and overhead metrics, showing agent rework volume and late change share.
User Simulator Ablation and Persona Impact
Ablations on user persona design demonstrate that authentic personas derived from SWE-chat data result in longer, more challenging trajectories, more interactions, and lower agent resolve rates—validating the importance of realistic user modeling. Similarly, experiments with different user simulator models highlight significant impact on interaction shape, requirement disclosure granularity, and agent performance, substantiating simulator-choice as a non-trivial axis in benchmark construction.
Implications and Future Directions
SWE-interact reveals that strong performance on autonomous coding benchmarks does not transfer to interactive, user-driven workflows; effective goal discovery, requirement integration, and iterative refinement constitute a distinct capability axis for coding agents. These findings underscore the necessity for agent architectures supporting persistent state management, robust plan tracking, and adaptive interaction strategies over extended conversations. Further research should diversify user personas, strengthen simulator robustness, and target improvements in error recovery, requirement recall, and implementation stability.
Conclusion
SWE-interact presents a rigorous testbed for evaluating coding agents on realistic, multi-turn developer workflows, where interaction complexity—not mere task complexity—serves as the principal metric of agent robustness. Results indicate substantial gaps in agent reliability, requirement tracking, and error mitigation under iterative, user-driven scenarios, signifying that future AI development must prioritize collaborative workflow competence. SWE-interact is poised to catalyze advances in agent design, simulator realism, and benchmark coverage for the next generation of autonomous coding systems (2606.30573).

