SWE-chat: Coding Agent Interactions From Real Users in the Wild
Abstract: AI coding agents are being adopted at scale, yet we lack empirical evidence on how people actually use them and how much of their output is useful in practice. We present SWE-chat, the first large-scale dataset of real coding agent sessions collected from open-source developers in the wild. The dataset currently contains 6,000 sessions, comprising more than 63,000 user prompts and 355,000 agent tool calls. SWE-chat is a living dataset; our collection pipeline automatically and continually discovers and processes sessions from public repositories. Leveraging SWE-chat, we provide an initial empirical characterization of real-world coding agent usage and failure modes. We find that coding patterns are bimodal: in 41% of sessions, agents author virtually all committed code ("vibe coding"), while in 23%, humans write all code themselves. Despite rapidly improving capabilities, coding agents remain inefficient in natural settings. Just 44% of all agent-produced code survives into user commits, and agent-written code introduces more security vulnerabilities than code authored by humans. Furthermore, users push back against agent outputs -- through corrections, failure reports, and interruptions -- in 44% of all turns. By capturing complete interaction traces with human vs. agent code authorship attribution, SWE-chat provides an empirical foundation for moving beyond curated benchmarks towards an evidence-based understanding of how AI agents perform in real developer workflows.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
This paper introduces SWE-chat, a large, growing collection of real conversations between people and AI “coding agents” while they work on open-source projects. Think of a coding agent as a very smart assistant that can read files, edit code, run commands, and suggest changes. The goal is to understand how people actually use these agents in everyday programming—not just on neat, simplified test problems.
What questions the researchers asked
The study focuses on two simple questions:
- How do people really use coding agents when building software—what do they ask, what tools do agents use, and who ends up writing the code that gets saved?
- How do coding agents fail in practice, and how do users react when things go wrong?
How they did the study (in everyday terms)
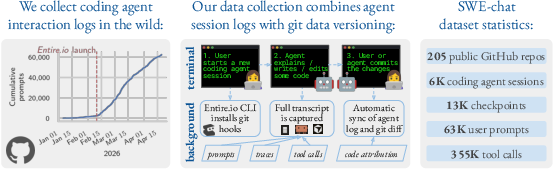
The team collected data from developers who chose to share their agent sessions publicly from their GitHub projects. They used an open-source tool (Entire.io) that:
- Records the back-and-forth chat between the user and the agent.
- Logs the agent’s “tool calls” (like opening files, editing text, running terminal commands).
- Links each session to real code changes (“commits”) and tracks who wrote each line (the human or the agent).
Some key ideas explained simply:
- Session: A complete conversation where the user asks for help and the agent works, sometimes over many turns.
- Tool calls: Actions the agent takes, like “read this file,” “edit that function,” or “run a command.”
- Commit: A saved snapshot of code changes in a project. It’s like hitting “save” with a note.
- Code authorship attribution: A way to tell which lines were written by the human vs. by the agent.
- “Vibe coding”: Sessions where the agent writes almost all the code that ends up being saved—basically “let the agent drive.”
- Static analysis (Semgrep): An automated scanner that looks for common security mistakes in code, like “this function might let a hacker run dangerous commands.”
They annotated the data to label things like user intent (e.g., “understand code” vs. “create code”) and whether users push back (correct or reject the agent’s output). To scale up, they used strong LLMs as “judges” to label many sessions, after testing which models worked best compared to human labels.
What’s in the dataset so far:
- About 6,000 coding sessions from 200+ repositories.
- 63,000+ user prompts and 355,000+ agent tool calls (2.7 million logged events total).
- It keeps growing over time (a “living dataset”).
Note: Because only volunteers who opted in are included, this reflects early adopters and may not represent all developers.
What they found (main results and why they matter)
Here are the most important takeaways:
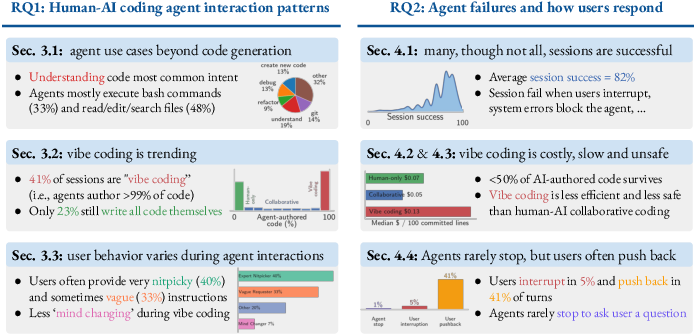
- People use agents for more than writing code.
- The most common request is to understand existing code (about 19% of prompts).
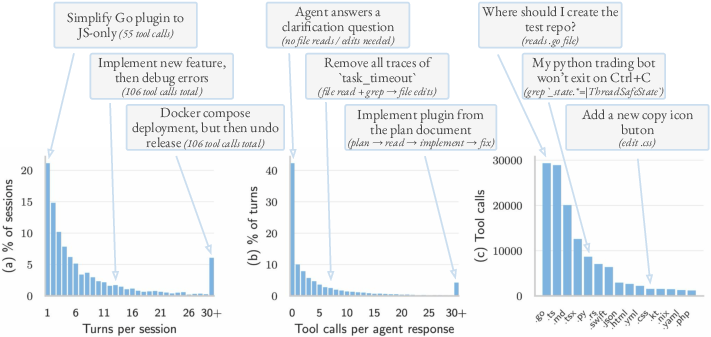
- Agents don’t just edit files; about a third of their actions are running shell commands (like git operations), plus lots of reading and searching before editing. This means real work is broader and messier than “write a patch.”
- Coding style is split into two extremes.
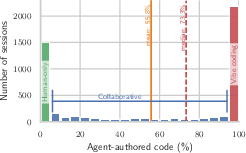
- Sessions are often “bimodal”: either the human writes everything, or the agent writes almost everything.
- In about 41% of sessions, the agent writes virtually all the saved code (“vibe coding”). In about 23%, humans write it all. The rest are mixed (“collaborative”).
- Vibe coding is growing more common over time.
- Agents’ output gets thrown away a lot.
- On average, only about 44% of the code written by agents is kept in the final commits. In other words, more than half of what agents write never makes it into the project.
- Even in vibe coding, where the agent writes nearly everything, humans still discard a noticeable chunk.
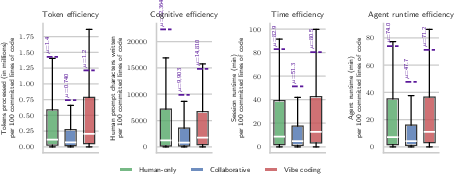
- Vibe coding is less efficient and more expensive per useful line of code.
- Per 100 kept lines of code, vibe coding uses about 3× more model “tokens” (computing effort) than collaborative sessions.
- It tends to cost more money and take more time per useful line than when humans and agents share the work.
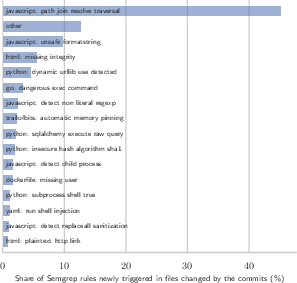
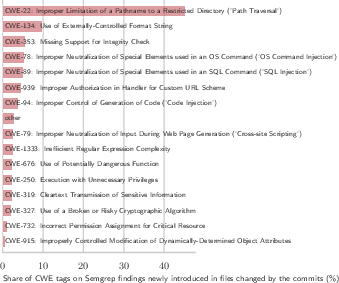
- Agent-written code introduces more security issues per line.
- Vibe-coded commits add security warnings about 9× more often than human-only commits (and about 5× more than collaborative commits), according to the Semgrep scanner.
- Vibe-coded commits also fix more issues than other modes, but they still introduce even more than they fix.
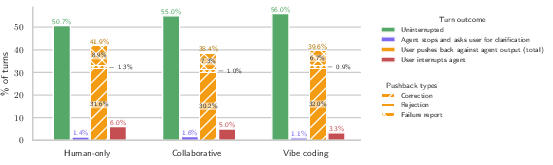
- Users actively oversee and correct agents.
- Agents rarely pause to ask clarifying questions (roughly 1–3% of turns).
- Users interrupt agents mid-run in about 3–6% of turns.
- Users push back (e.g., correct or reject the agent’s output) after roughly 4 in 10 turns. So even in vibe coding, people are not passive—they’re guiding and correcting the agent a lot.
Why this matters:
- Benchmarks that only test “write a patch” miss the real variety: understanding code, running tools, and iterative back-and-forth is common.
- Full autonomy isn’t automatically better—collaboration can be more efficient and safer.
- As agents write more code, careful oversight becomes even more important to avoid unsafe changes.
What this could change (implications)
- Better, more realistic tests for coding agents:
- New benchmarks should reflect real workflows: multi-turn chats, reading/searching first, and understanding code—not just single-shot fixes.
- Smarter interaction design:
- Agents should ask clarifying questions more often, recognize uncertainty, and invite feedback—so users correct earlier, not later.
- Interfaces could better support quick user corrections and oversight.
- Safer code by default:
- Since vibe coding currently introduces more security issues per line, agents should include stronger built-in safety checks and security-aware training.
- Teams might prefer collaborative modes until safety improves.
- Useful training data for simulators:
- SWE-chat can help build “user simulators” that replay real patterns of nudging, correcting, and pushing back—useful for testing agents offline before deploying them.
In short: Coding agents are powerful and increasingly used, but in real life they work best as teammates—not unsupervised coders. SWE-chat helps us see the messy, collaborative reality so we can build agents that are more helpful, efficient, and safe.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored based on the paper’s current dataset and analyses.
- Representativeness: Opt-in public OSS projects and early adopters likely bias the sample; replication is needed on private/enterprise repositories, different geographies, and a wider range of developer seniority profiles.
- Agent skew: ~85% of sessions come from one agent (Claude Code); results should be re-estimated with more balanced coverage across agents and model families.
- Short observation window: Findings (e.g., rise of vibe coding) are drawn from ~three months; longitudinal validation over longer periods and across agent/model updates is needed.
- Missing model/config metadata: Log entries do not consistently capture model version, system prompts, guardrails, or agent settings; collecting and exposing this metadata is essential to attribute behavior changes to model or UI updates.
- Session boundary validity: How sessions are segmented by the CLI may not reflect natural task boundaries; methods to detect/validate session boundaries (e.g., inactivity thresholds, task markers) are needed.
- Authorship attribution accuracy: Line-level human vs. agent attribution is assumed correct; ground-truth validation and error rates for the attribution mechanism should be established via controlled studies.
- Cost/token accounting consistency: Token and cost metrics vary by vendor accounting and context reloads; normalization across providers and explicit assumptions are required for fair comparisons.
- Time metrics as proxies: “Minutes per 100 lines” and agent runtime exclude off-session work and context switching; integrate IDE telemetry or developer self-reports to better capture total effort.
- LOC as outcome quality metric: Lines of code are a poor proxy for value or complexity; include measures like cyclomatic complexity, coverage changes, maintainability indices, reviewer acceptance, and CI outcomes.
- Lack of downstream outcomes: Analyses stop at commit; link sessions to pull request acceptance, code reviews, reverts, post-merge bugs, and issue reopenings to evaluate real impact.
- Security measurement limits: Semgrep-only static analysis can have false positives/negatives and spotty language coverage; triangulate with multiple SAST tools, dynamic tests, and severity-weighted scoring, plus human audits on a sample.
- Confounding in vulnerability comparisons: Vibe-coded tasks may differ systematically (e.g., new feature surface) from collaborative/human-only; perform task-matched or propensity-score–matched comparisons to approach causal claims.
- Pushback detection reliability: Pushback/clarification is LLM-annotated; quantify annotation precision/recall against human gold and assess robustness across model prompts, languages, and domains.
- Agent clarification behavior origins: Low clarification rates might be due to model prompts or UI affordances; ablation studies varying system prompts, tool access policies, or UI nudges are needed to isolate causes.
- Generalization across intents and languages: Efficiency and safety are not stratified by programming language, framework, or user intent; provide per-intent and per-language breakdowns to guide targeted improvements.
- Tool-call taxonomy and coverage: One-third bash use is reported but semantics vary by agent; standardize tool schemas (e.g., to ADP) and include richer metadata (stdout/stderr, exit codes) for reproducible analysis.
- External effects of shell commands: No assessment of side effects or safety of executed commands; analyze rates of destructive or risky operations and their triggers.
- Missing multimodal inputs: Screenshots or external artefacts (explicitly excluded) are common in real workflows; evaluate how excluding them distorts intent distributions and outcomes.
- Limited reasoning traces: Only ~200 sessions include “extended thinking”; expand and analyze whether visible/hidden reasoning changes efficiency, success, or safety in practice.
- Bot filtering criteria: Automated session filtering is mentioned but not detailed; publish heuristics and validate that true human sessions aren’t removed and that synthetic/bot sessions are.
- Persona validity and stability: User personas are LLM-assigned per session; validate against developer self-identification and assess whether personas are stable across a user’s sessions.
- Bimodality drivers: The cause of the human-only vs. vibe-coding split is unclear; model predictors (task intent, repo size, language, agent type, user history) to explain mode selection and outcomes.
- Interruption/pushback outcomes: It is unknown when interruptions or pushbacks improve success, safety, or efficiency; quantify their causal impact via sequence models or matched comparisons.
- Survival/efficiency definitions: Survival and efficiency metrics rely on categories like “self-overwrites” vs. “human deletions”; provide sensitivity analyses to alternative definitions and thresholds (e.g., the ≥99% vibe-coding cutoff).
- Uncommitted value: Analyses focus on committed lines; assess non-commit value such as improved understanding, exploratory runs, or documentation produced but not committed.
- Coverage of non-code tasks: Understanding code is common but not deeply analyzed for outcomes; define and evaluate success metrics for comprehension tasks (e.g., correctness of explanations, task scoping quality).
- Cross-agent comparability: Clarification and autonomy rates are analyzed primarily for Claude Code; replicate across agents with comparable logging and classification to determine if findings generalize.
- Replayability and environment capture: Without environment snapshots (dependencies, OS, toolchain), trajectories aren’t reproducible; add workspace snapshots or containerized replays for research fidelity.
- Model- and UI-induced trends: The observed increase in autonomy (longer turns) may stem from UI changes, plan modes, or rate limits; disentangle by logging UI versions and feature flags.
- Data versioning and reproducibility: As a “living dataset,” snapshots can change; provide versioned releases with checksums and fixed annotation sets for reproducible studies.
- Open questions for benchmarks: How to derive robust, privacy-preserving, task-grounded benchmark tasks from trajectories with verifiable success metrics, including multi-turn evaluation and human-in-the-loop steps?
- Open questions for user simulators: What fidelity metrics validate simulators trained on SWE-chat (e.g., pushback rates, persona mix, interruption timing), and how to perform off-policy evaluation of new agents against real logs?
- Ethical scope and consent granularity: Opt-in is at repository level, but multi-author commits occur; clarify consent granularity and provide mechanisms for per-author opt-out in future data collection.
Practical Applications
Immediate Applications
Below are actionable, deployable-now use cases derived from the dataset, analyses, and tooling described in the paper. Each item includes sector alignment and feasibility notes.
- [Software/DevTools] IDE/CLI features that prompt for clarification when autonomy risks are high
- What: Use SWE-chat signals (low agent clarification rate, high user pushback, long autonomous turns) to trigger agent “ask before proceed” prompts when uncertainty or high-impact actions (e.g., git ops, large edits) are detected.
- Tools/products/workflows: VS Code/JetBrains extensions; Cursor/Claude Code plugins; “Autonomy limiter” toggle with heuristics learned from SWE-chat turn durations and interruption patterns.
- Assumptions/dependencies: Access to session-level telemetry or on-device heuristics; developer consent; minimal latency overhead.
- [Software/DevTools, Security] Semgrep-in-the-loop guardrails for agent-authored code
- What: Run Semgrep automatically during agent planning/edits and pre-commit to catch vulnerability types observed to spike in vibe coding (e.g., command injection, path traversal).
- Tools/products/workflows: CI/CD pre-merge checks; local git hooks; IDE pop-ups on risky diffs; “AI-risk badge” on PRs with elevated findings per LOC.
- Assumptions/dependencies: Semgrep rule coverage for project languages; organizational approval for gating; accurate AI vs. human line attribution (e.g., via Entire.io-style diff attribution).
- [Software/DevTools] “Agent efficiency meter” and cost budgeting
- What: Display token usage, $/LOC, and predicted “code survival” likelihood to nudge toward collaborative coding (shown to be more cost/time efficient).
- Tools/products/workflows: Real-time HUD in IDE; bot comments on PRs summarizing survival rate, self-overwrites, and user overwrites; spend alarms.
- Assumptions/dependencies: Token/cost telemetry; per-line authorship mapping; organizational appetite for developer-facing analytics.
- [Software/DevTools] Interruptibility and plan chunking defaults
- What: Adopt shorter action chunks, explicit “plan mode,” and frequent commit checkpoints in high-risk operations to reduce user-initiated interrupts.
- Tools/products/workflows: Default smaller edit batches; gated git actions; explicit “Pause for review” steps after tool sequences that are commonly interrupted in SWE-chat (e.g., post-edit or pre-git).
- Assumptions/dependencies: Agent supports tool-level granularity and user-inserted breakpoints.
- [Software/DevTools, Teams/Management] Agent-usage dashboards for ROI and risk
- What: Track mode mix (human-only/collaborative/vibe), code survival, pushback rate, token spend per LOC, and vulnerability-introduction rates across repos/teams.
- Tools/products/workflows: Engineering metrics dashboards; quarterly reviews to calibrate autonomy defaults and budgets; procurement input for agent vendor selection.
- Assumptions/dependencies: Consent and governance for usage analytics; bias awareness (dataset skews to early adopters, public OSS).
- [Academia, Benchmarks] SWE-chat-derived evaluation suites beyond patch generation
- What: Build benchmarks for next-action prediction, clarification timing, tool selection sequences, and user pushback handling using real session traces.
- Tools/products/workflows: Open datasets/subsets on Hugging Face; reproducible leaderboards for interaction metrics (e.g., survival rate, pushback mitigation).
- Assumptions/dependencies: Careful de-identification; licensing compliance; standardization of trajectories.
- [Academia, HCI] Persona-aware interaction studies and A/B tests
- What: Evaluate UI patterns for “expert nitpicker,” “vague requester,” and “mind changer” personas (dominance of nitpickers reported) to reduce friction and improve outcomes.
- Tools/products/workflows: Lab studies with instrumented IDEs; interventions like structured diff reviews for nitpickers and template prompts for vague requesters.
- Assumptions/dependencies: IRB approvals; representative participant recruitment (beyond early-adopter bias).
- [Security/Compliance, Policy] Internal guidance to require enhanced review for vibe-coded commits
- What: Update secure SDLC policies to mandate additional code review, static analysis, and provenance labeling for high-AI-authorship diffs (given ~5–9× higher vulnerability rates per LOC).
- Tools/products/workflows: “High AI-authorship” PR labels; mandatory dual review; risk-based merge gates.
- Assumptions/dependencies: Accurate authorship detection; stakeholder buy-in; avoidance of blanket bans that impede productivity.
- [Education] Curriculum and labs on collaborative coding and oversight
- What: Use SWE-chat sessions to teach prompting, iterative refinement, and safe use of agents; assignments measure pushback quality and survival rate improvements.
- Tools/products/workflows: Classroom modules; sandboxed IDEs with logging; rubric emphasizing collaboration over one-shot code generation.
- Assumptions/dependencies: Accessible, anonymized examples; faculty readiness.
- [Daily life/Indie devs] Personal “agent debriefs” to improve habits
- What: Post-session summaries showing where interruptions occurred, survival rates, and where clarifying questions would have helped.
- Tools/products/workflows: Lightweight CLI report after each session; recommendations to adjust autonomy levels or prompt specificity.
- Assumptions/dependencies: Local logging or privacy-preserving analytics; willingness to review debriefs.
Long-Term Applications
These require further research, model training, standardization, or broader deployment to realize at scale.
- [Software/DevTools, ML] Clarification-policy learning and uncertainty-aware agents
- What: Train policies (e.g., via offline RL or supervised learning) to decide when to ask clarifying questions, pause, or proceed, using SWE-chat traces and session success labels.
- Tools/products/workflows: Meta-controllers for turn length, tool scopes, and ask/answer loops; calibrated uncertainty estimation tied to human pushback predictors.
- Assumptions/dependencies: High-quality labels (LLM-as-judge noise must be mitigated); offline-to-online generalization studies.
- [Software/DevTools, ML] Reward models optimized for code survival and reduced self-overwrites
- What: Build reward signals from survival rate, human overwrites, and session success to steer agents toward edits more likely to be committed.
- Tools/products/workflows: Fine-tuned agents minimizing wasteful trajectories; constrained optimization to balance speed, cost, and survivability.
- Assumptions/dependencies: Attribution fidelity; balancing against creativity and exploration.
- [Security/Compliance] Safer-by-construction agent pipelines
- What: Combine security static/dynamic analysis, taint tracking, and learned vulnerability risk scores into the agent’s inner loop; auto-remediation before presenting diffs.
- Tools/products/workflows: “Security-first” agent profiles; mandatory sanitization templates; adaptive guardrails that tighten under vibe coding.
- Assumptions/dependencies: Cross-language tool coverage; low false positive rates to avoid alert fatigue; latency overhead budget.
- [Standards/Policy] Provenance and auditability standards for AI-authored code
- What: Sector-wide norms to label AI contributions at line/commit level; retention of signed agent trajectories for audits; integration with supply chain frameworks (e.g., SLSA-like for codegen).
- Tools/products/workflows: Git metadata extensions; SBOM-like AI-authorship manifests; compliance audits in finance/healthcare/critical infrastructure.
- Assumptions/dependencies: Community consensus (e.g., Agent Data Protocol alignment); privacy-preserving logging; legal clarity.
- [Academia/Industry] User simulators trained on SWE-chat for offline evaluation
- What: Realistic simulators that emulate pushback, interruptions, and persona styles to test agents at scale without human-in-the-loop.
- Tools/products/workflows: “Gym” environments for agents; benchmarks measuring stability under persona shifts and underspecification.
- Assumptions/dependencies: Generalization beyond OSS and early adopters; preventing simulators from overfitting to historical distributions.
- [Cross-industry: Healthcare, Finance, Energy, Robotics] Risk-tiered autonomy frameworks
- What: Domain-specific policies mapping coding modes to risk tiers; restrict vibe coding for safety-/compliance-critical code paths; mandate enhanced review/testing pipelines.
- Tools/products/workflows: Autonomy gates tied to repo tags (e.g., safety-critical modules); sector guidance (HIPAA, PCI DSS, IEC 61508) for AI-assisted code.
- Assumptions/dependencies: Mapping risk models to codebases; regulatory acceptance; robust test/verification harnesses.
- [Economics/Workforce, Policy] Longitudinal impact studies and governance levers
- What: Measure how increasing vibe coding affects productivity, defect rates, and security incidents; design incentives (e.g., procurement criteria) that reward collaborative, efficient, and safer practices.
- Tools/products/workflows: Data-sharing consortia; standardized KPIs for AI-assisted development; public-sector pilot evaluations.
- Assumptions/dependencies: Access to private repo data under strict governance; harmonized metrics across orgs.
- [DevTools, Market] Predictive PR risk scoring and reviewer routing
- What: Score incoming PRs by AI-authorship %, predicted survival adjustments, and vulnerability risk; route to the most relevant reviewers or automated test suites.
- Tools/products/workflows: “Smart triage” in GitHub/GitLab; auto-assignment policies; dynamic CI priorities.
- Assumptions/dependencies: Accurate models; organizational trust in automated triage.
- [Education] Adaptive tutoring agents that teach oversight and secure coding
- What: Agents that adapt difficulty and prompting style to learner personas; embed teachable moments where pushback is appropriate; show security implications in real time.
- Tools/products/workflows: CS curricula with embedded agents; program analysis-backed feedback; formative assessment dashboards.
- Assumptions/dependencies: Safe classroom sandboxes; content alignment with learning objectives.
- [ML Methods] Better judgment and annotation pipelines
- What: Improve LLM-as-judge reliability with human-in-the-loop spot checks, multi-judge ensembles, and calibration against gold labels for dynamic datasets.
- Tools/products/workflows: Continuous validation harnesses; disagreement sampling; active learning for annotation refinement.
- Assumptions/dependencies: Budget for human oversight; evolving prompts/models as data shifts.
Notes on feasibility and generalization:
- The dataset currently reflects open-source, opt-in, early-adopter users; results and learned policies may need recalibration for enterprise/private codebases.
- Semgrep findings are proxies for vulnerabilities; additional dynamic/semantic analyses will improve precision/recall.
- Adoption depends on low-friction integration in IDEs/CI, robust privacy controls, and clear developer value (reduced rework, fewer vulnerabilities, lower cost).
Glossary
- Agent autonomy: The degree to which a coding agent operates without user guidance or intervention. "The higher agent autonomy of vibe coding sessions is reflected in fewer agent questions."
- Agent self-overwrites: Instances where the agent rewrites or replaces its own previously generated code before a commit. "Note that agents' self-overwrites typically occur when the user pushes back and instructs the agent to reimplement something before committing."
- Agent tool calls: Discrete invocations of tools by the agent (e.g., file edits, shell commands, searches) during a session. "As of April 2026, SWE-chat contains 2.7M logged events from 200+ repositories, including 63,000+ user prompts and 355,000+ tool calls."
- Agent trajectories: Sequences of actions (tool uses and outputs) executed by the agent within a turn or session. "Agent trajectories typically begin with reading and searching tools before transitioning to file modifications and build commands"
- Bimodal: A distribution with two distinct peaks; here, sessions tend to cluster around “mostly human-written” or “mostly agent-written” code. "We find that coding patterns are bimodal: in 41\% of sessions, agents author virtually all committed code (``vibe coding''), while in 23\%, humans write all code themselves."
- Checkpoint logging: Recording periodic snapshots of an agent session (including prompts, actions, and outputs) to a repository branch. "developers have opted into Entire.io's CLI checkpoint logging, which records coding agent session transcripts on a dedicated branch."
- Code authorship attribution: Line-level labeling of who wrote each line of code (human vs. agent). "Each checkpoint is linked to a commit with line-level code authorship attribution."
- Code diffs: Representations of changes between code versions, often used to track modifications introduced by agents or humans. "with full tool-call trajectories and code diffs with human vs. agent authorship attribution"
- Code survival rate: The fraction of agent-produced code that remains in the final user commits. "metrics (detailed in Appendix~\ref{sec:metrics}) that quantify the fraction of agent-produced code that survives into user commits (code survival rate)"
- Coding efficiency: A metric capturing wasted effort, such as agent self-rewrites, relative to what ends up committed. "the overhead of agent self-rewrites (coding efficiency)"
- Coding modes: Categories describing who authored committed code in a session (human-only, collaborative, or vibe coding). "We therefore introduce three different coding modes:"
- Collaborative coding: A mode where both human and agent co-author the committed code. "Collaborative coding (36.5\% of sessions)"
- Command injection: A security vulnerability where untrusted input is used to execute arbitrary system commands. "We observe a range of vulnerability types, including path traversal, command injection, unsafe format strings, and SQL injection"
- Inter-annotator agreement: A measure of consistency among human annotators labeling the same data. "We developed clear annotation codebooks for each task and evaluated inter-annotator agreement, which was moderate to high across all tasks"
- LLM-as-a-judge: Using a LLM to evaluate or label data instead of humans. "We describe the full LLM-as-a-judge validation approach in Appendix~\ref{sec:validation}."
- Mind changer: A user persona characterized by redirecting goals mid-session. "mind changers who redirect goals mid-session."
- Open-weight: Refers to models whose weights are openly available for use and analysis. "we evaluated the zero-shot performance of various open-weight and proprietary LLMs"
- Patch generation: Automatically creating code changes to fix bugs or implement features. "benchmarks focused narrowly on patch generation underestimate the operational diversity and complexity of real agent workflows."
- Path traversal: A vulnerability where input manipulates file paths to access unintended files. "We observe a range of vulnerability types, including path traversal, command injection, unsafe format strings, and SQL injection"
- Plan mode: An agent state or phase where it outlines intended steps before execution. "the interruption most frequently occurs when the agent exits the plan mode"
- Reward modeling: Training models to align with desired outcomes using learned reward signals. "Enables identification of failure patterns, helpful as a training signal for reward modeling."
- Semgrep: A static-analysis tool used to detect security issues in code. "we additionally run the static-analysis tool Semgrep"
- Session success rating: A scalar score (0–100) assessing how well a session fulfilled user goals. "Distribution of LLM-annotated session success rating."
- SQL injection: A vulnerability where untrusted input is used to manipulate SQL queries. "We observe a range of vulnerability types, including path traversal, command injection, unsafe format strings, and SQL injection"
- Static analysis: Code analysis performed without executing the program, often to detect vulnerabilities. "For every commit we run the static analyzer Semgrep on the pre- and post-commit repository snapshots"
- Tool-call trajectories: Ordered sequences of the agent’s tool invocations throughout a session. "SWE-chat includes complete interaction traces between humans and AI coding agents, with full tool-call trajectories"
- Turn duration: The length of time an agent’s or user’s turn lasts in an interaction. "the 99.9th-percentile turn duration now exceeds 100 minutes"
- Unsafe format strings: A class of vulnerabilities arising from unvalidated format string usage. "We observe a range of vulnerability types, including path traversal, command injection, unsafe format strings, and SQL injection"
- User persona: A categorized behavioral profile of a user during a session (e.g., expert nitpicker, vague requester, mind changer). "User persona"
- User pushback: User responses that correct, reject, or report failures in agent outputs. "User pushback"
- User simulator: A model that imitates user behavior to evaluate agents offline. "User simulators for offline evaluation"
- Vague requester: A user persona that underspecifies tasks and defers decisions to the agent. "vague requesters who underspecify tasks and delegate decisions to the agent"
- Vibe coding: A mode where the agent authors nearly all the committed code in a session. "agents author virtually all committed code (``vibe coding'')"
Collections
Sign up for free to add this paper to one or more collections.