- The paper presents a framework and SWE-STEPS dataset to assess coding agents on sequential software evolution tasks.
- It demonstrates that isolated-task evaluations inflate agent success by 15-25 percentage points compared to stateful assessments.
- The study reveals that agents accumulate technical debt and face persistent context challenges in managing long-horizon regressions.
Evaluating Coding Agents Beyond Isolated Tasks: Sequential Software Evolution with SWE-STEPS
Introduction
The evaluation of coding agents has historically been biased toward isolated, stateless programming tasks, which inadequately reflect professional software engineering (SWE) workflows. The paper "Beyond Isolated Tasks: A Framework for Evaluating Coding Agents on Sequential Software Evolution" (2604.03035) addresses this methodological gap by proposing a comprehensive evaluation framework and introducing the SWE-STEPS dataset. This framework enables the systematic assessment of coding agents on temporally extended, interdependent sequences of pull requests (PRs) characterized by accumulating technical debt, long-horizon dependencies, and regression maintenance. The analysis highlights inflated agent capabilities under prior isolated-task regimes and exposes critical deficits in maintainability and robustness in long-horizon settings.
Framework and Dataset Construction
The framework pivots on automated mining and validation of PR chains from large-scale open-source repositories. Tasks are extracted as chains of dependent PRs spanning practical evolutionary windows in real-world projects. Extraction involves commit graph traversal, metadata aggregation (including diff, test, and dependency information), and LLM-assisted categorization, ensuring task representativeness and executability across diverse domains.
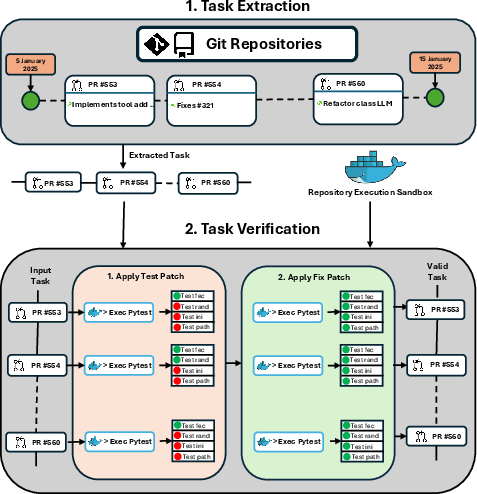
Figure 1: Task Extraction Pipeline—tasks are mined from pull requests and subjected to rigorous sandbox-based verification to ensure validity for sequential agent evaluation.
SWE-STEPS Dataset
SWE-STEPS comprises 168 multi-PR tasks (963 PRs total) from six major Python repositories spanning build tooling, AI, scientific computing, and developer infrastructure. Compared to prior benchmarks—such as SWE-Bench, SWE-Gym, and FEA-Bench—SWE-STEPS emphasizes long, causally linked PR chains (3–11 PRs per task), with each chain representing one to three weeks of genuine developer activity. Task specification complexity is an order of magnitude higher than in isolated benchmarks (median issue text ≫3000 words, up to 17 files and 37 functions edited), reflecting realistic large-scale engineering challenges.
The dataset construction also establishes fine-grained test oracles. Each PR in a chain is annotated with binary and coverage metrics for fail-to-pass (F2P) and pass-to-pass (P2P) test suites, supporting functional and regression evaluation. Static analysis of agent-produced code—using Cognitive Complexity and SQALE Index measured by SonarQube—enables longitudinal tracking of repository health.
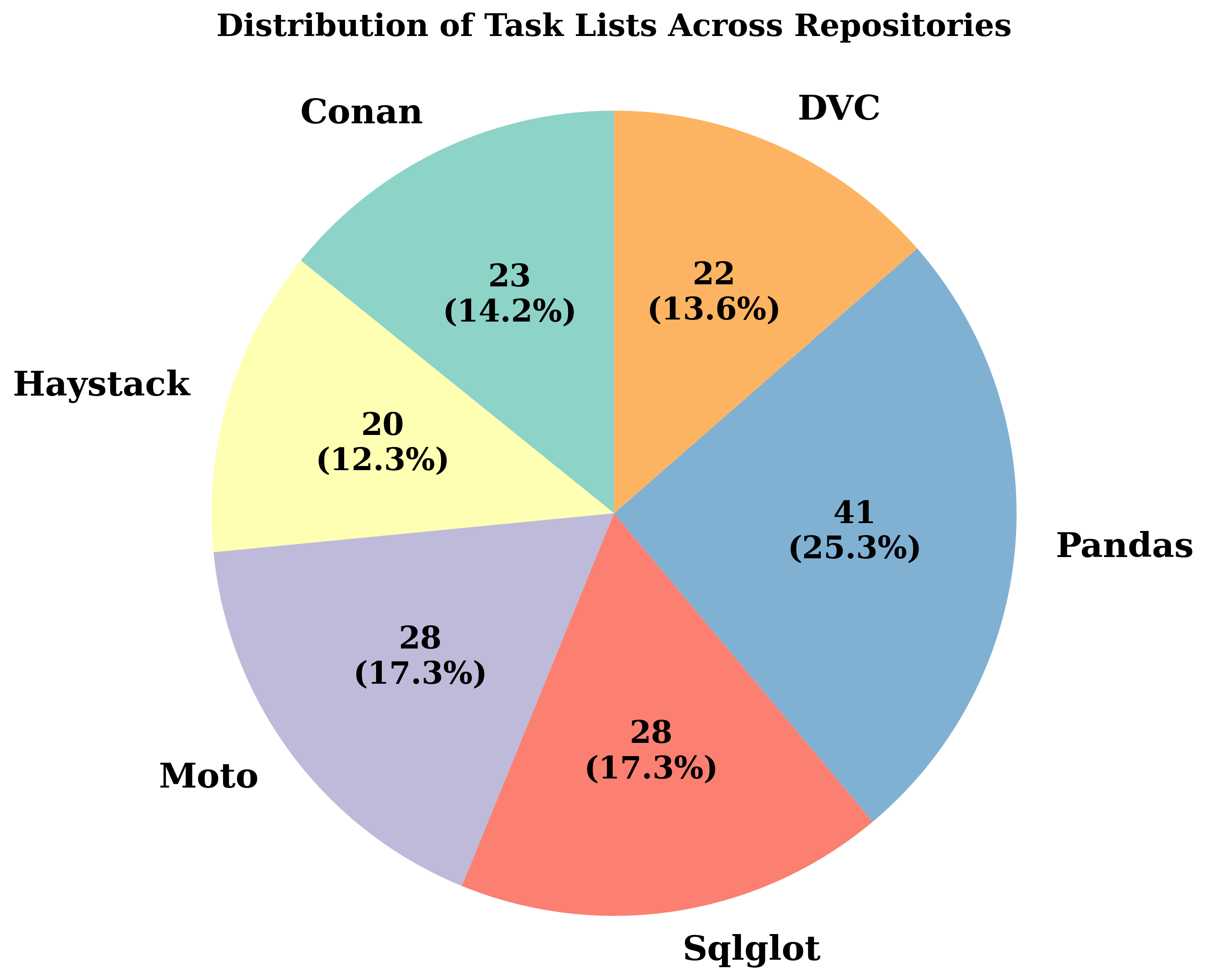
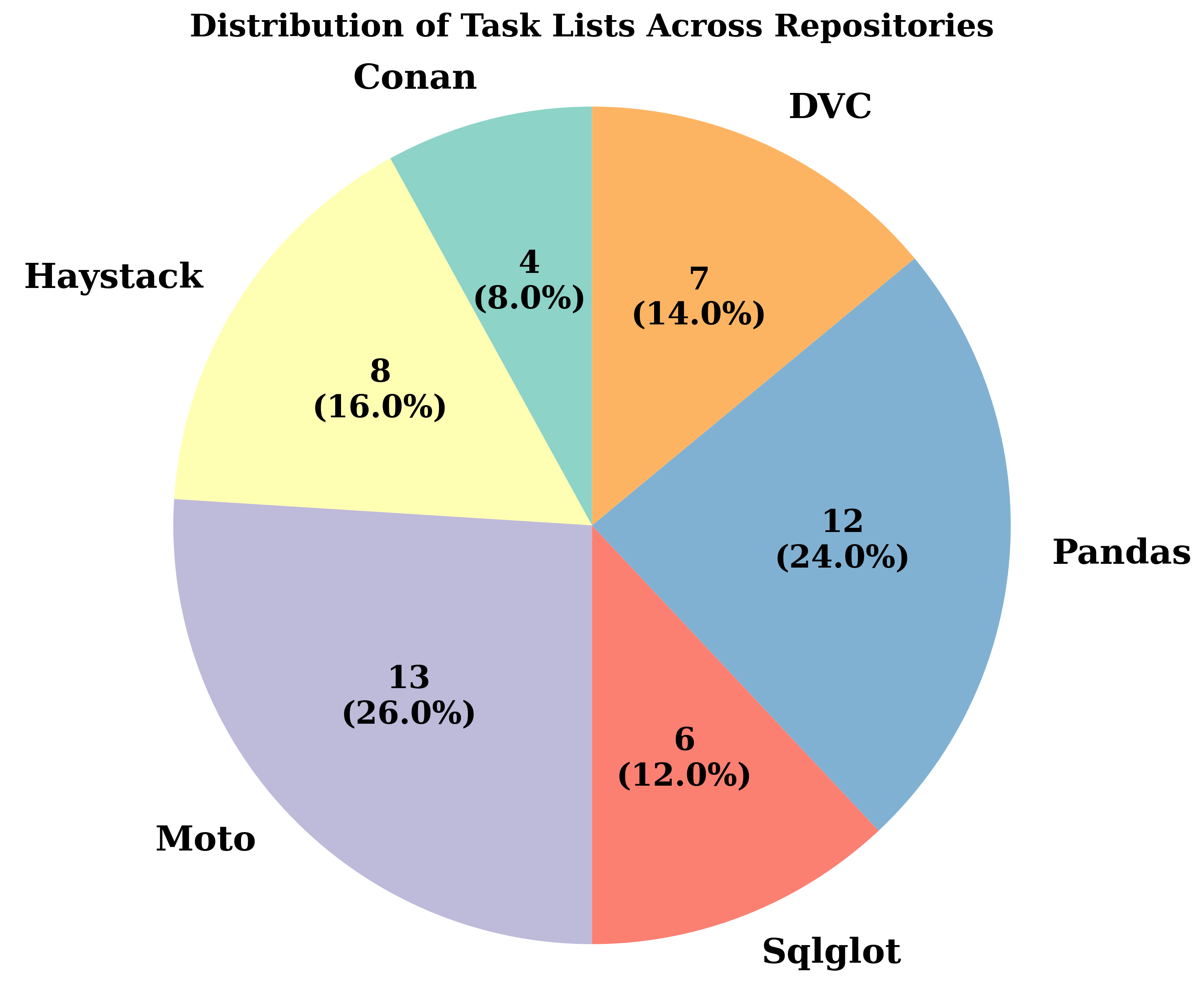
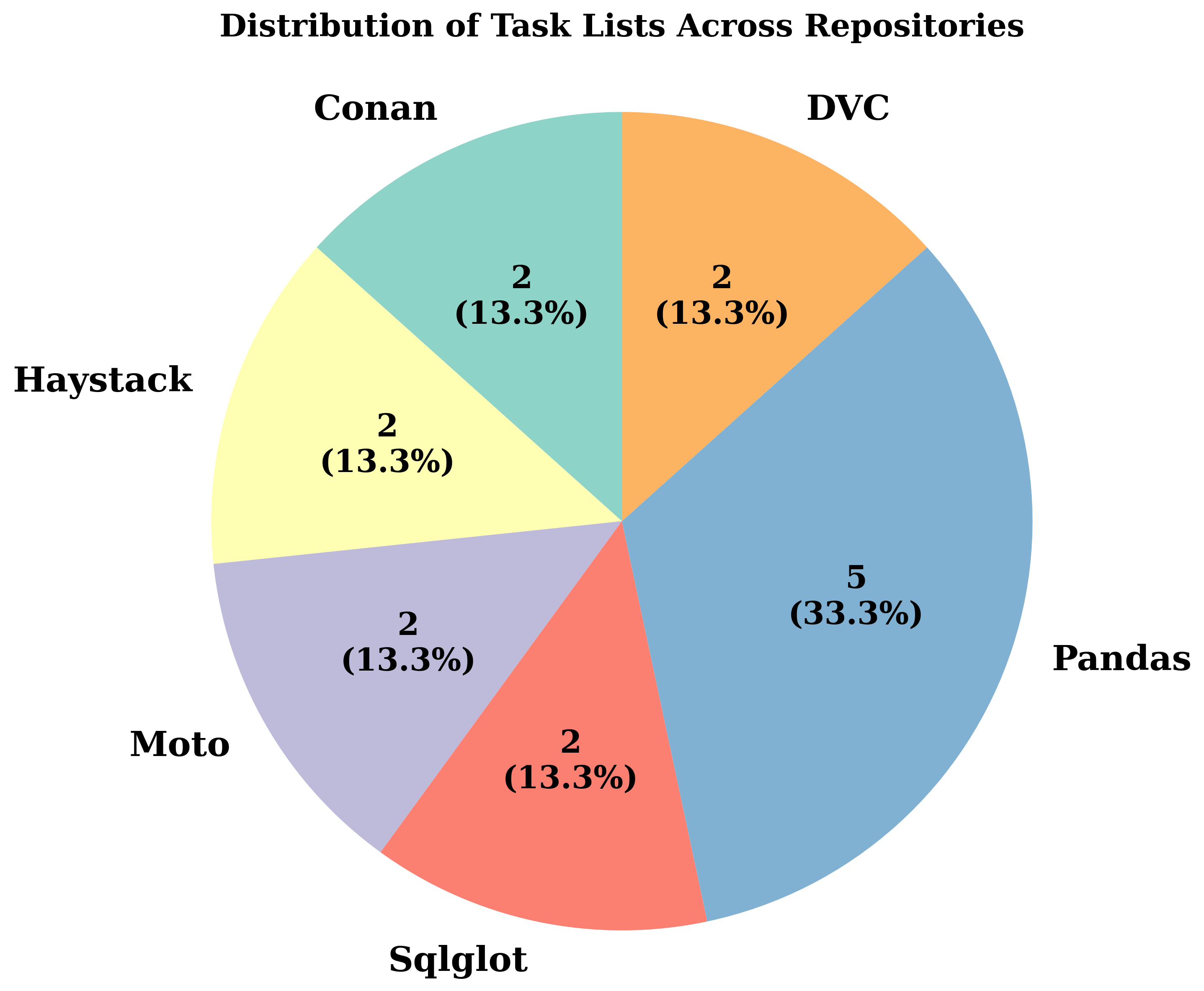
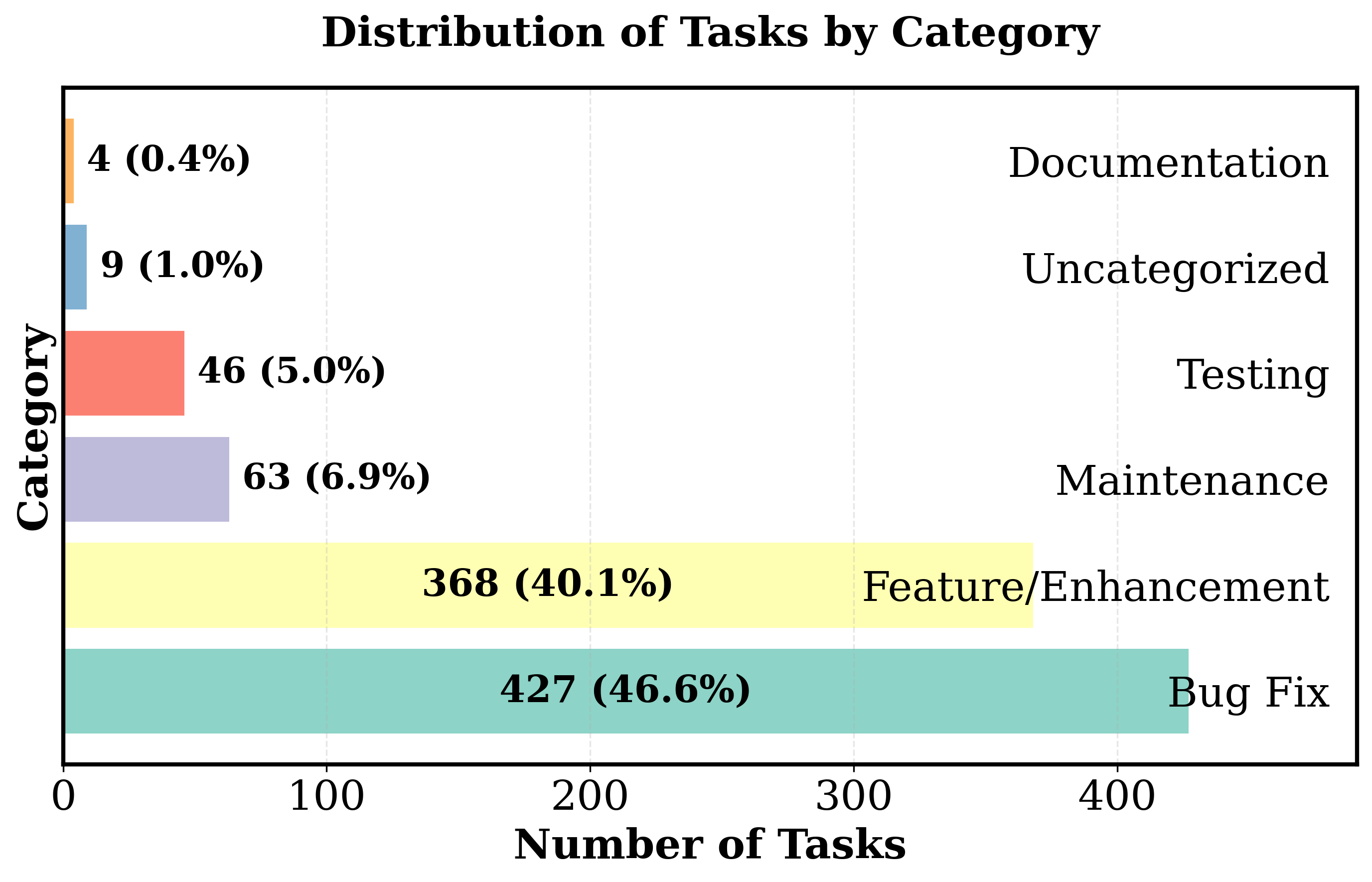
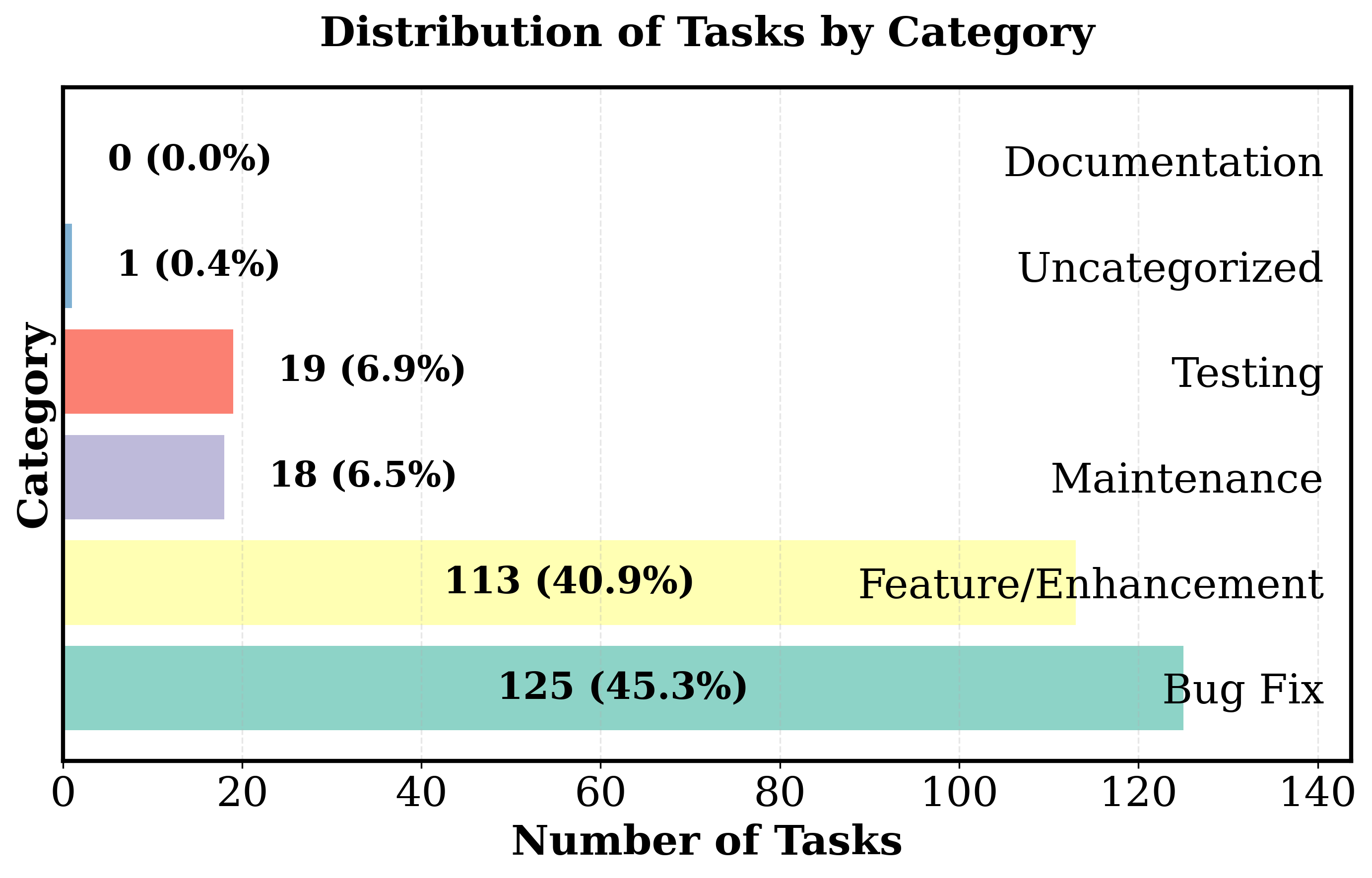
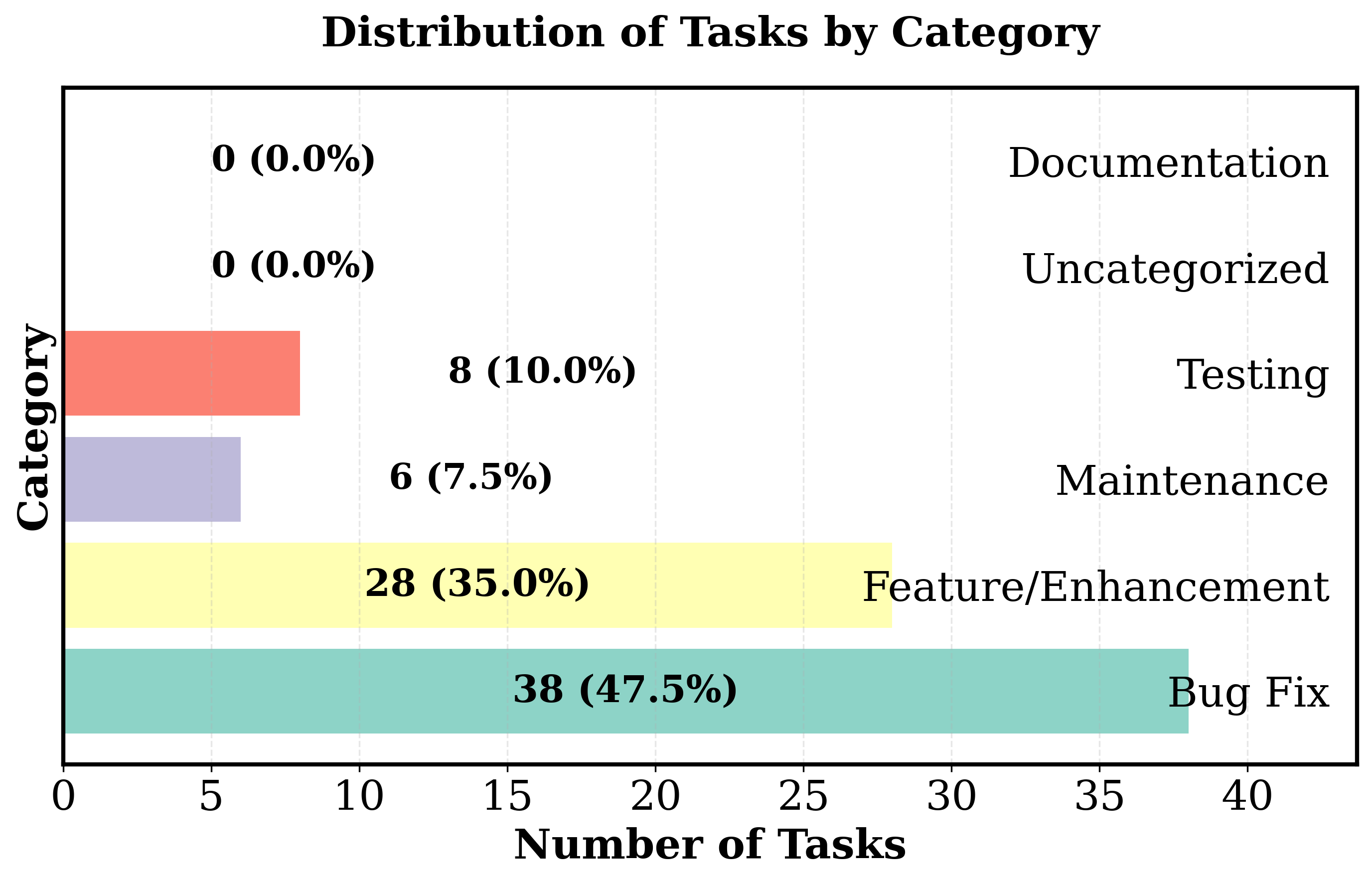
Figure 2: Repository task lists distribution highlighting SWE-STEPS’s broad coverage across domains and maintaining proportional complexity in both full and subset splits.
Agent Evaluation Paradigms
To emulate real SWE interaction styles, three execution modes are benchmarked:
- Global Memory (Sequential/Conversational Coding): Agents process PRs iteratively, persisting all historical state, and must pass cumulative/cascading regression tests reflecting production-like codebase evolution.
- PRD-Based (Monolithic Planning): Agents receive an aggregated product requirements document (PRD), planning and executing the entire chain in one session; tested on the union of all task-specific test suites.
- Individual PRs (Isolated, SWE-Bench Baseline): Each PR is executed in a freshly reset repository, evaluated independently with only local tests and no historical artifacts or technical debt.
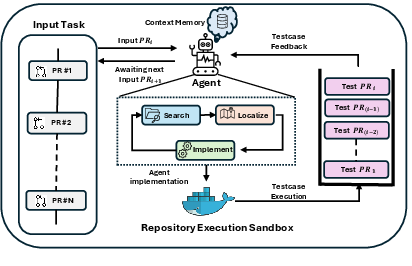
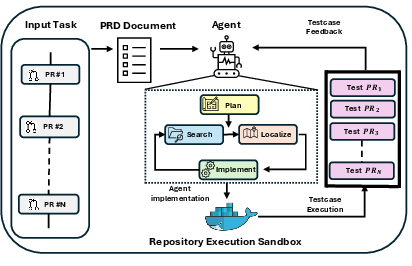
Figure 3: Global (sequential) setting—each agent action compounds repository state, requiring effective context tracking and regression management over multi-PR chains.
Empirical Findings
Success Rate Inflation in Isolated Evaluations
It is shown that isolated PR evaluation protocols dramatically overestimate coding agent capabilities. In the SWE-STEPS mini dataset, leading models (e.g., Claude Sonnet 4.5, Gemini 3 Flash) experience a success rate drop of 15–25 percentage points upon transitioning from stateless (Individual) to stateful (Global/PRD) evaluation. For example, Claude Sonnet 4.5 shows a performance decrease from 66.25% (Individual) to 43.75% (Global). This inflation, up to 20 points, exposes inadequacy in prior benchmarks that lack persistent context and cumulative regression constraints.
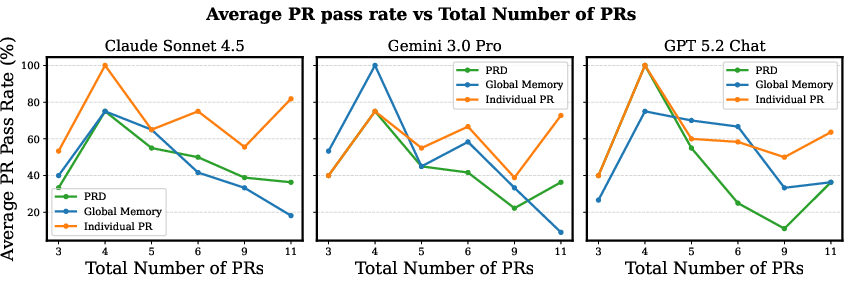
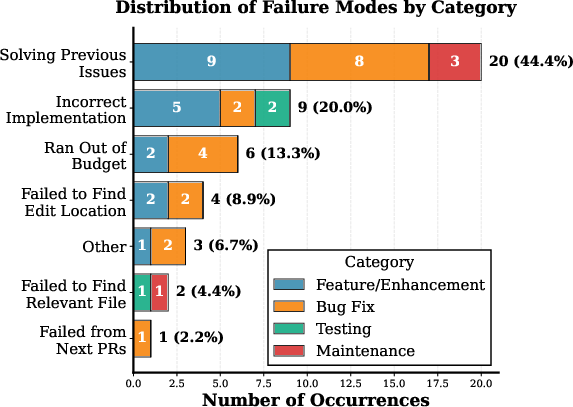
Figure 4: Average PR pass rate decreases sharply as the number of sequential PRs increases; only in the Individual setting are high pass rates sustained, demonstrating the inflation artifact.
Temporal Degradation and the Cost of Accumulation
Agent reliability correlates negatively with PR chain length and test suite size. Success rates decrease monotonically as context length and regression obligations grow, with Individual settings maintaining higher performance envelopes across bins. Agents struggle increasingly with regression preservation (P2P) and new functionality (F2P) as interaction becomes more temporally distributed.
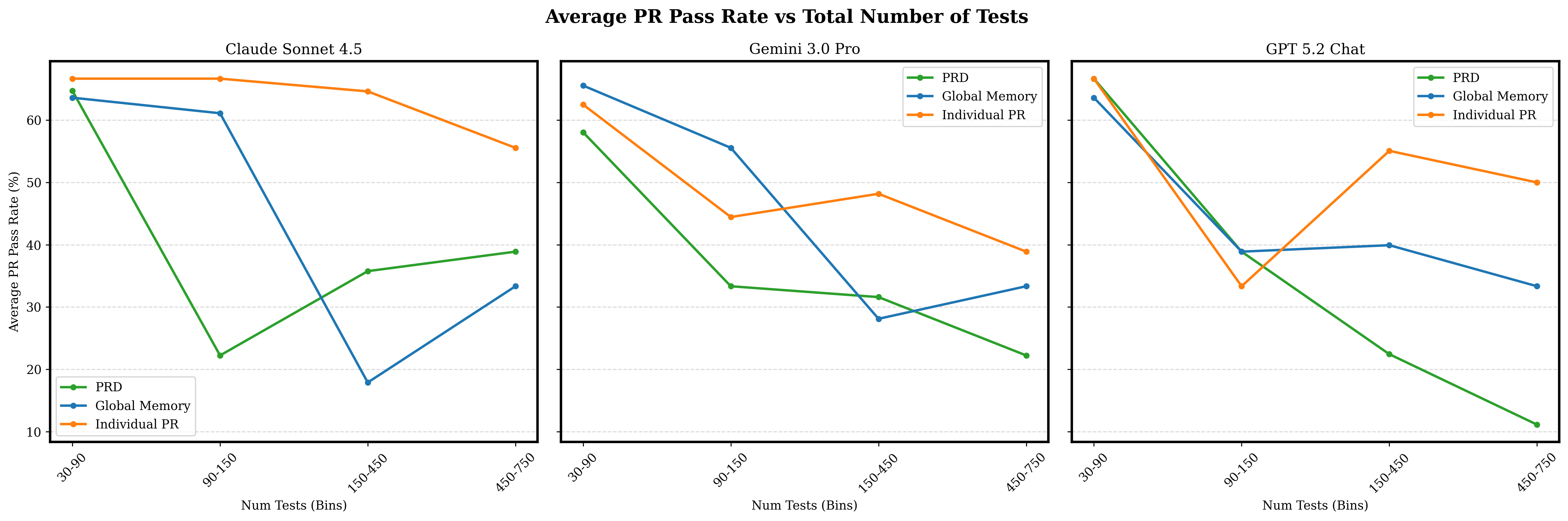
Figure 5: Pass rate collapses with growing active test suite size for stateful (Global/PRD) settings, while the stateless (Individual) regime remains artificially robust.
Repository Health Degradation
Despite functional task completion, agent-modified codebases accumulate significantly more technical debt and cognitive complexity than human-generated baselines. Notably, in high-pass-rate tasks (e.g., haystack, moto), cognitive complexity and SQALE Index for agent traces increase steadily, while the human gold trace often trends downward due to active refactoring and architectural hygiene practices.
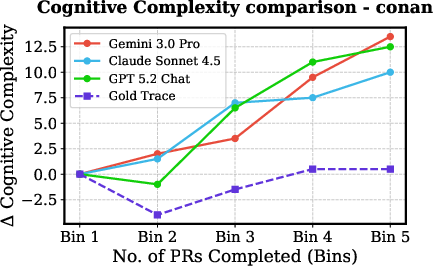
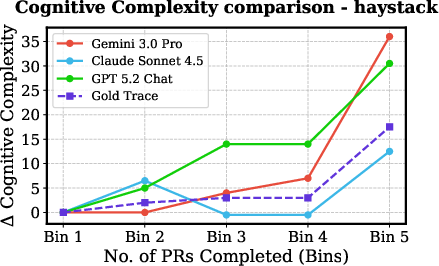
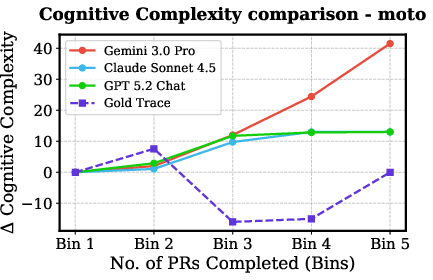
Figure 6: Autonomous agents (all LLMs) introduce pronounced increases in codebase complexity even when succeeding on tests, unlike the human ground truth which frequently reduces complexity as evolution proceeds.
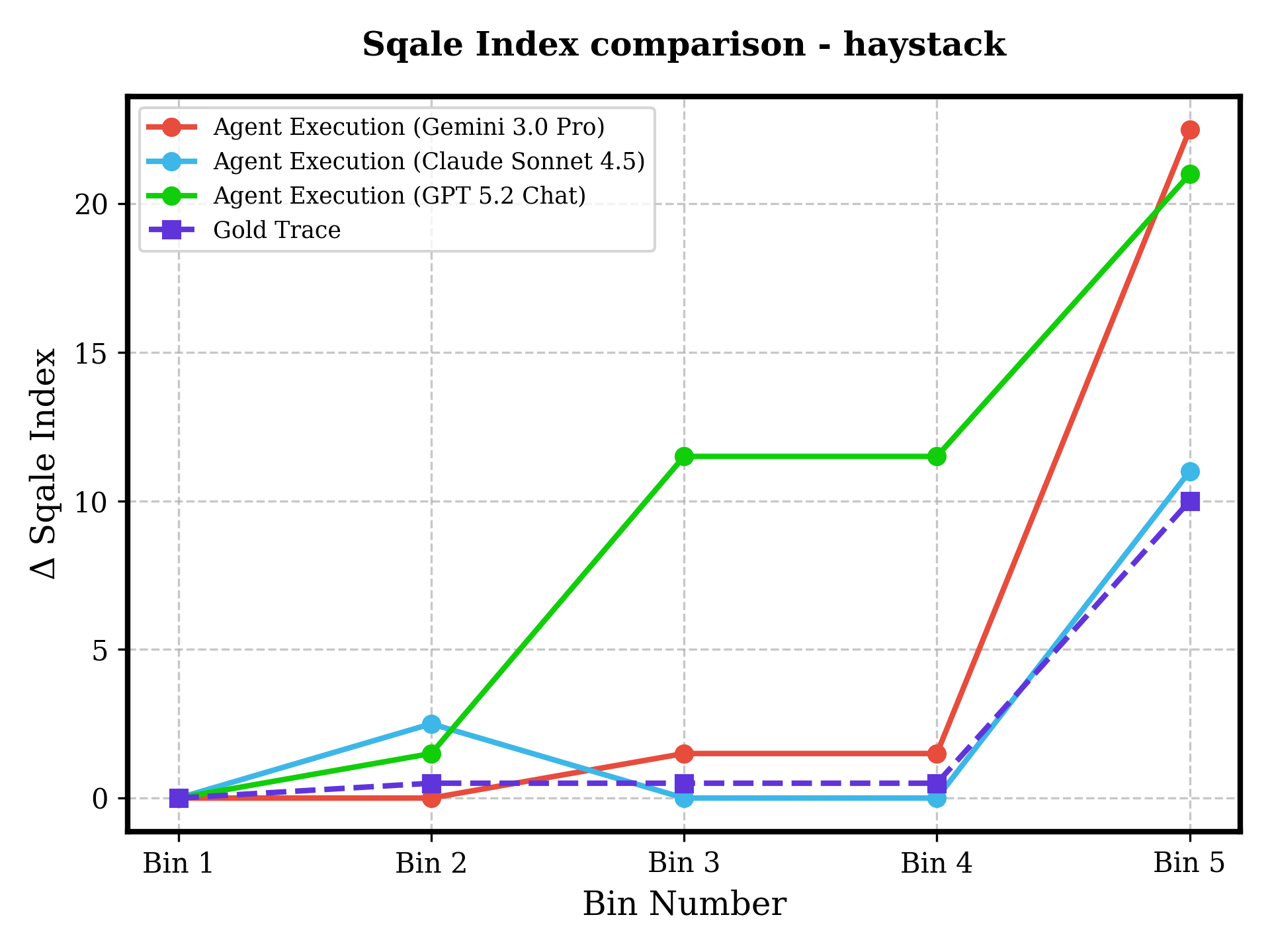
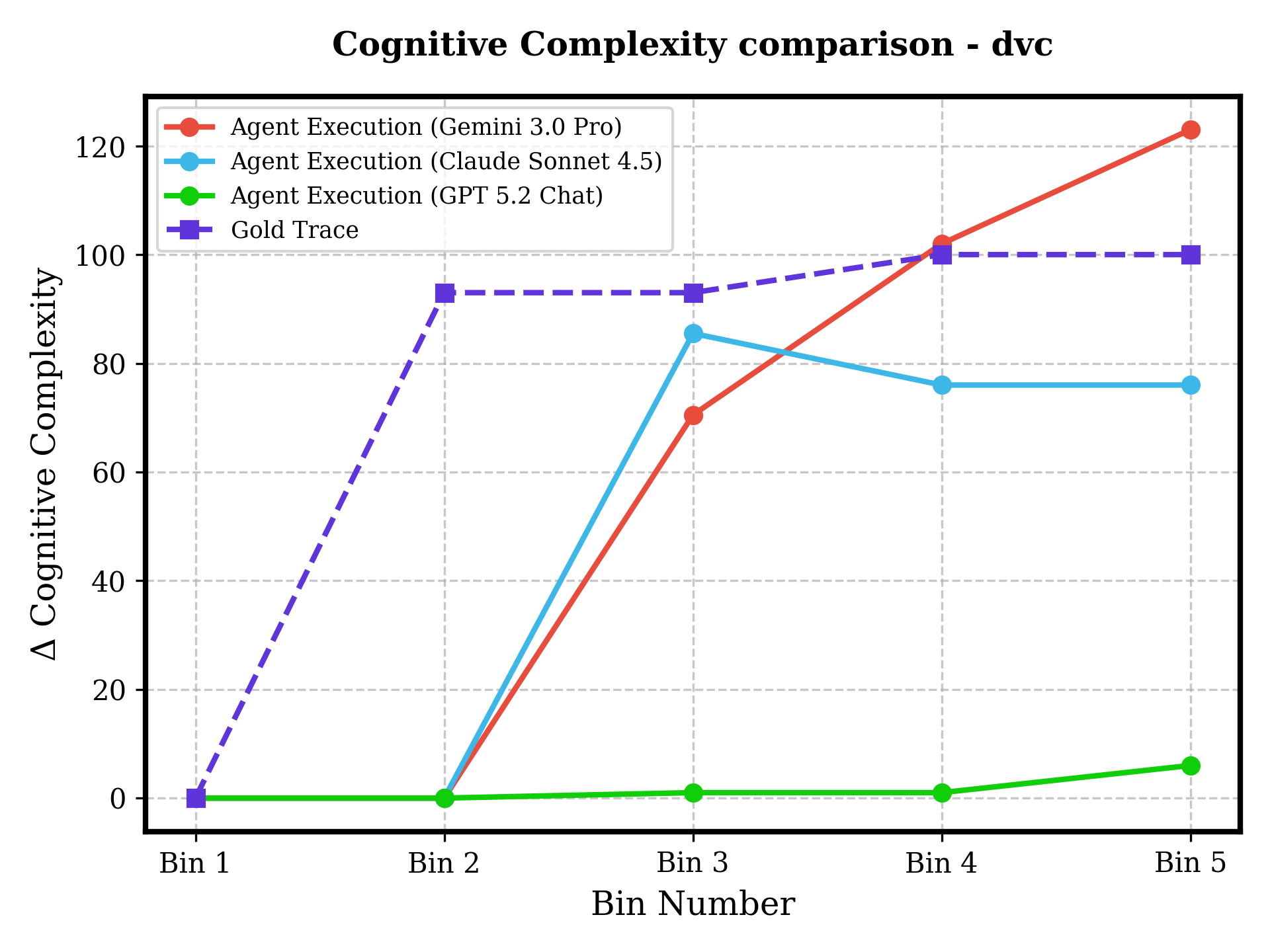
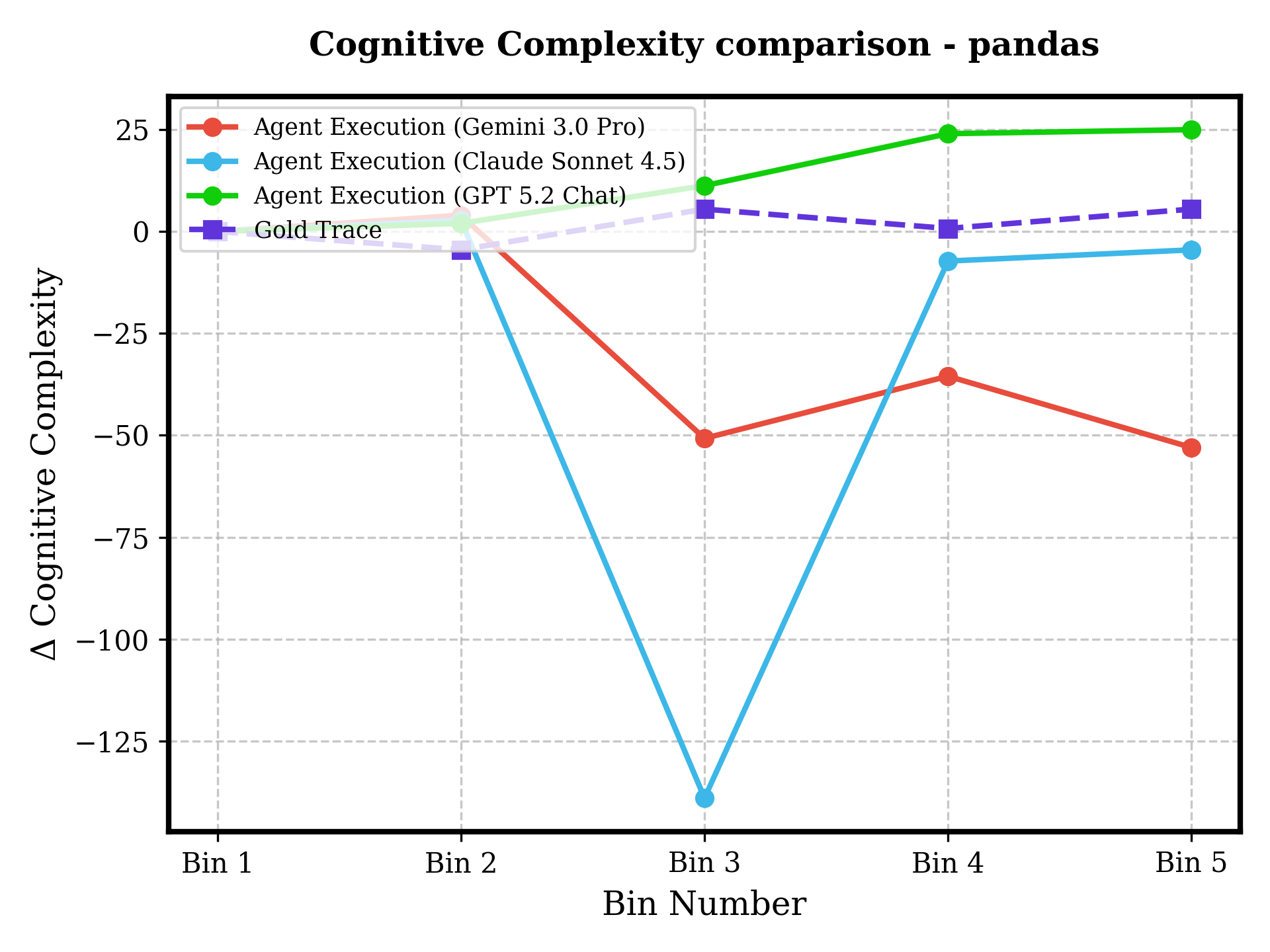
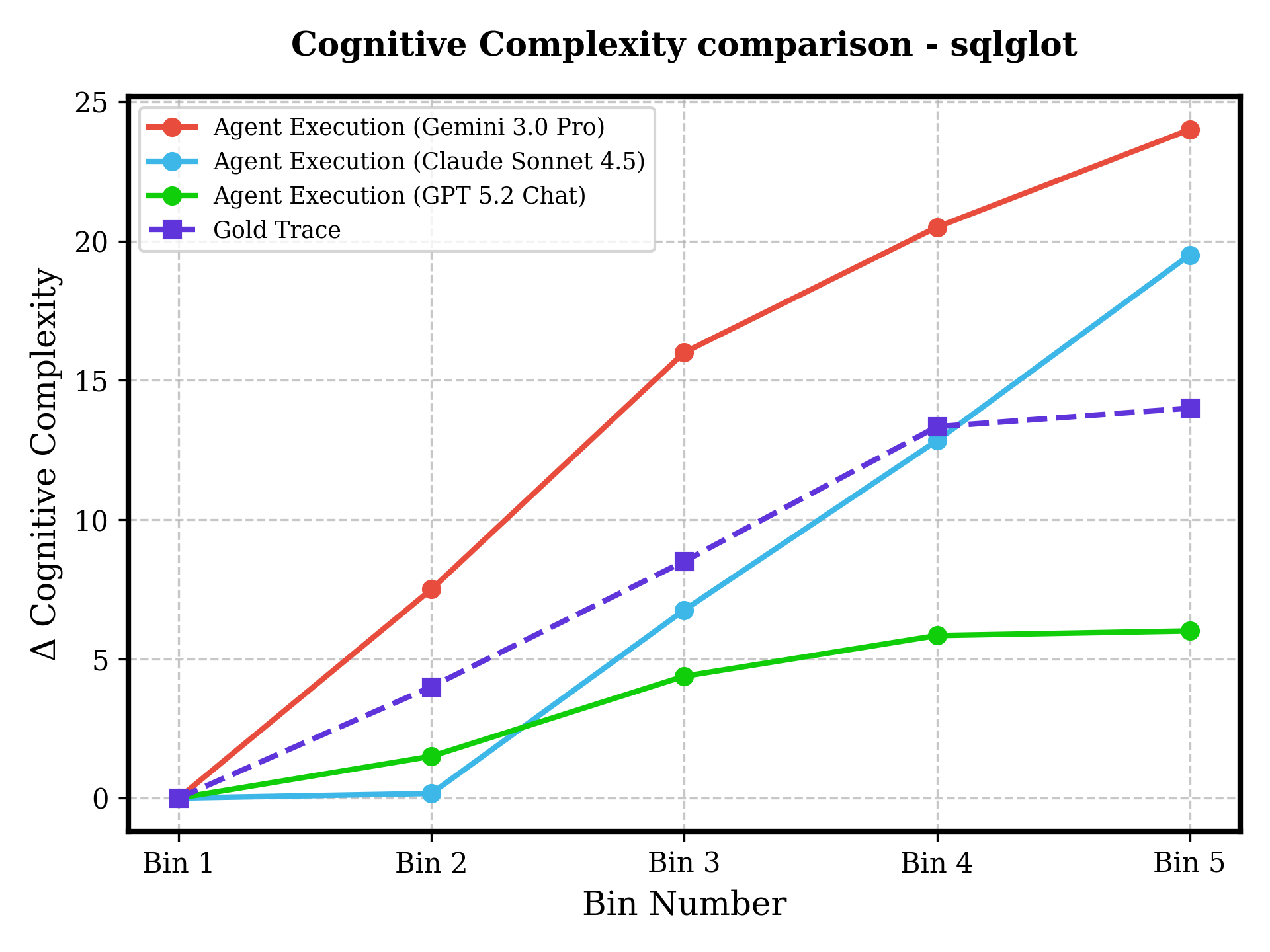
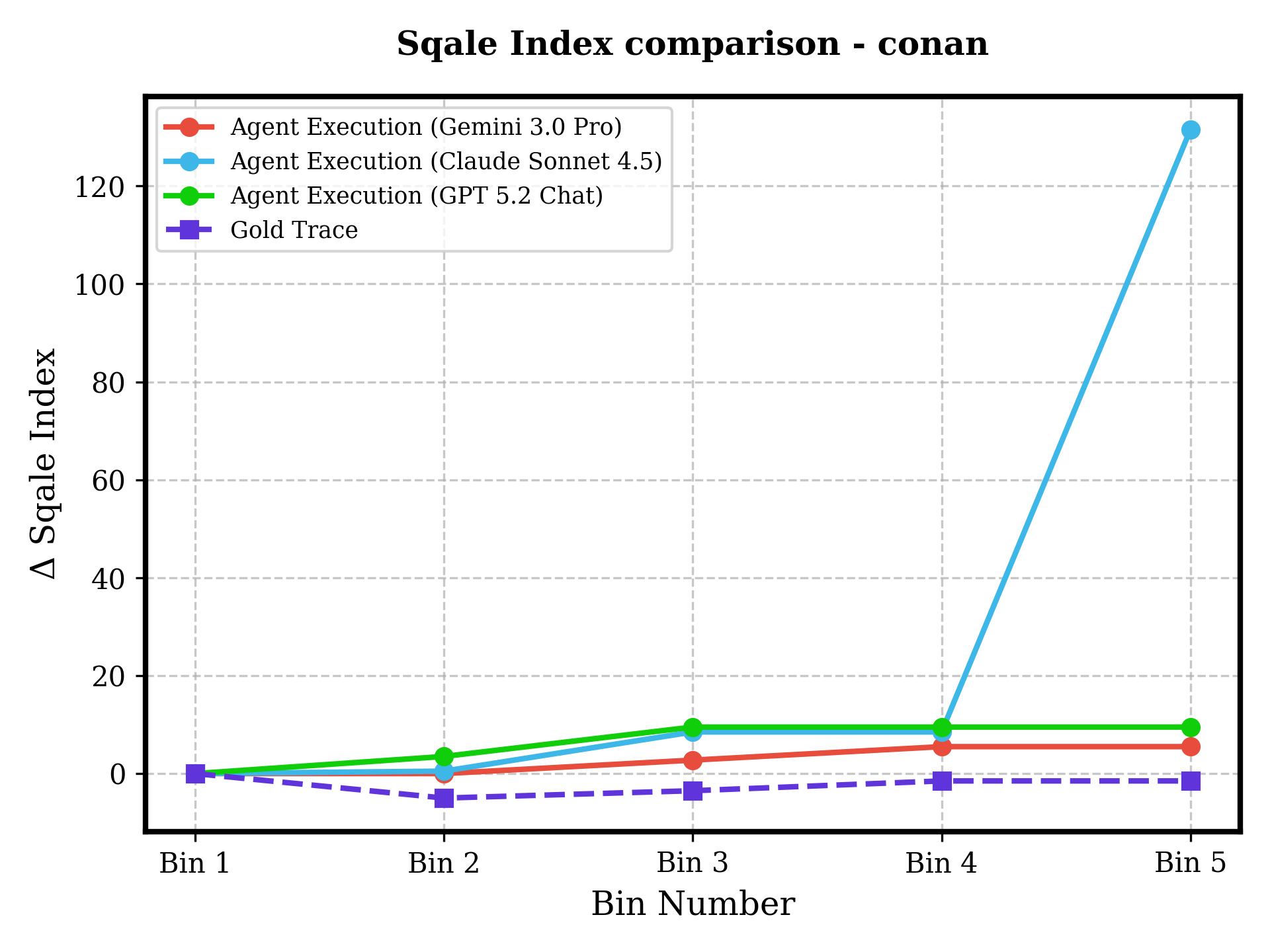
Figure 7: Across six repositories and increasing difficulty, agents show either unchecked technical debt accumulation, flatlining (failure to progress), or volatility—human-coded traces demonstrate controlled and maintainable evolution.
Error Modes and Contextual Failures
Dominant errors in sequential evaluation originate from inability to manage persistent context, with the principal failure mode (44.4% of errors) being contextual confusion, e.g., solving previous issues or failing to disentangle overlapping regression requirements. This is unique to long-horizon settings and invisible in isolated-task benchmarks.
Implications and Future Directions
The results empirically validate that prior evaluation metrics substantially exaggerate agent efficacy and ignore critical maintainability deficits. The ability to compose reliable, context-aware, low-debt code across evolutionary horizons remains unsolved. These findings mandate reformation of future SWE agent benchmarks—requiring adoption of stateful, temporally extended protocols and multidimensional metrics.
Practically, production deployment of agents for real-world repository maintenance without explicit focus on long-horizon robustness and maintainability presents a clear risk for compounding technical debt. Architecturally, the necessity for improved context management (retrieval, condensation, continual planning/refactoring) is underscored. Future large agent architectures must incorporate mechanisms for context induction, regression verification, and automated refactoring strategies.
On the theoretical front, these results motivate algorithmic research into multi-step program synthesis, cross-PR memory management, error correction in code evolution, as well as joint optimization of functional and maintainability objectives under realistic cumulative constraints.
Conclusion
The proposed framework, operationalized as the SWE-STEPS dataset, substantiates that stateless, isolated-task evaluation substantially misjudges agent capabilities and masks degradation in long-term code health. Rigorous temporal evaluation surfaced new error modes and highlighted critical unsolved challenges in multi-step reasoning, context handling, and maintainability. This work establishes a new empirical foundation for progress toward coding agents suitable for genuine, long-horizon collaborative software engineering.

