SWE-Together: Evaluating Coding Agents in Interactive User Sessions
Abstract: Most coding-agent benchmarks are static: an agent receives a complete task description up front and is judged only by its final code. Real coding assistance is interactive, with users clarifying goals, adding constraints, and correcting mistakes over multiple turns. We introduce SWE-Together, a multi-turn benchmark reconstructed from real user-agent coding sessions. To make real interactions verifiable, we curate 109 repository-level tasks from 11,260 recorded sessions, selecting sessions with recoverable repository states, clear user goals, and observable outcomes. To replay these interactions across agents, we build a reactive LLM-based user simulator that preserves the original users' intents and provides feedback when the coding agent's progress requires it. To evaluate agents as collaborators, we measure both final repository correctness and the number of corrective feedback turns required during the interaction. Experiments with frontier coding agents show that stronger agents generally achieve higher final success rates while requiring fewer interventions, suggesting an improved user experience.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
SWE-Together: A simple guide
What’s this paper about?
This paper introduces SWE-Together, a new way to test AI coding assistants (like ChatGPT-style coders). Instead of giving the AI a single instruction and grading the final code, SWE-Together tests AIs in realistic back-and-forth conversations—like how real people actually use coding helpers. It measures not just “Did it work?” but also “How much help did the AI need from the user to get there?”
What questions are the researchers asking?
- Can we build a benchmark that feels like real life, where people and coding AIs go back and forth with questions, clarifications, and corrections?
- How do we fairly compare coding AIs when users change their requests over time?
- Can we measure both the final code quality and the “user effort” needed to reach success?
How does SWE-Together work?
Think of SWE-Together as a sports tryout for coding AIs—played on real fields with a real coach, not just in a classroom.
It has three main parts:
- Turning real conversations into testable tasks:
- The team starts with lots of real chat logs between people and coding AIs from open datasets.
- They keep only the chats where:
- The goal is clear (e.g., fix a bug, add a feature).
- The code project (the “repo”) can be set up locally in a clean, controlled environment (a “sandbox”).
- The outcome can be checked (e.g., tests pass, behavior matches a checklist).
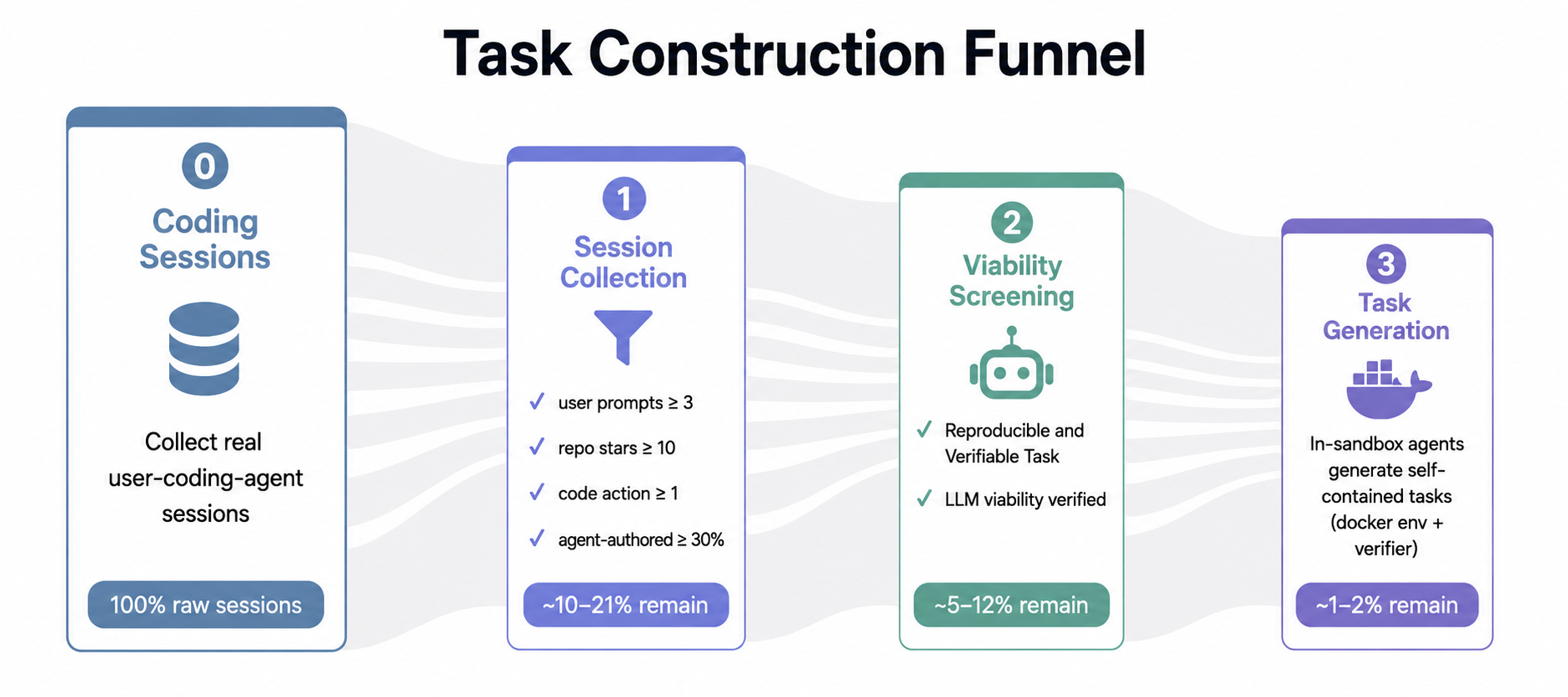
- From 11,260 real sessions, only 109 passed all checks. This makes the tasks reliable and repeatable.
- A user simulator that acts like the original person:
- A special AI plays the role of the user. It doesn’t just talk on a schedule; it speaks only when the coding agent’s actions “trigger” it (like a coach stepping in when a player goes off strategy).
- It stays anchored to what the original human wanted in the real conversation, so different coding AIs get similar guidance at similar moments.
- It can choose to say nothing (no-op), ask a question, redirect the agent, add a new requirement, or tell the agent to check something external.
- A fair scoring system:
- Final code is judged by:
- Deterministic checks (like running tests or verifying behavior).
- A fixed “rubric” (a teacher’s checklist) that focuses on behavior, not the exact code style. Different code can still be correct if it does the right thing.
- Two extra interaction metrics:
- User Correction: How many times did the “user” have to correct or nudge the AI? Fewer is better.
- Intent Coverage: Did the simulator consistently convey the original user’s requests and stay on-topic?
What methods did they use, in simple terms?
- “Sandboxed tasks”: Imagine copying the code project into a clean room where everything is controlled—same code version, same tools—so results are fair and repeatable.
- “Anchored, state-conditional simulator”: The user-simulator AI is tied to the original human’s intentions (anchored) and speaks based on what’s currently happening (state-conditional), not on a fixed timer.
- “Rubric judge”: Like a neutral referee using a checklist to grade whether the final code meets the goals, with room for partial credit.
What did they find?
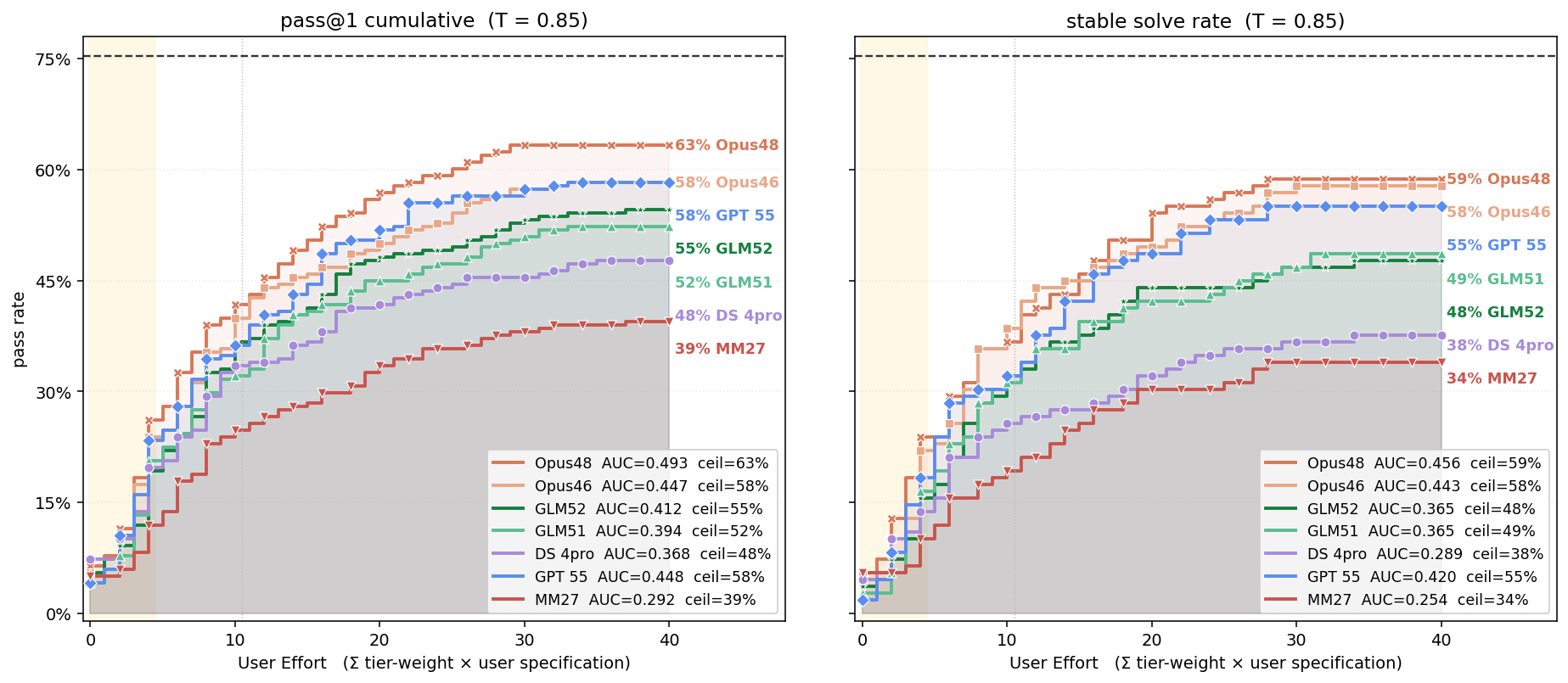
- They tested seven leading coding AIs on 109 tasks (each run twice for reliability).
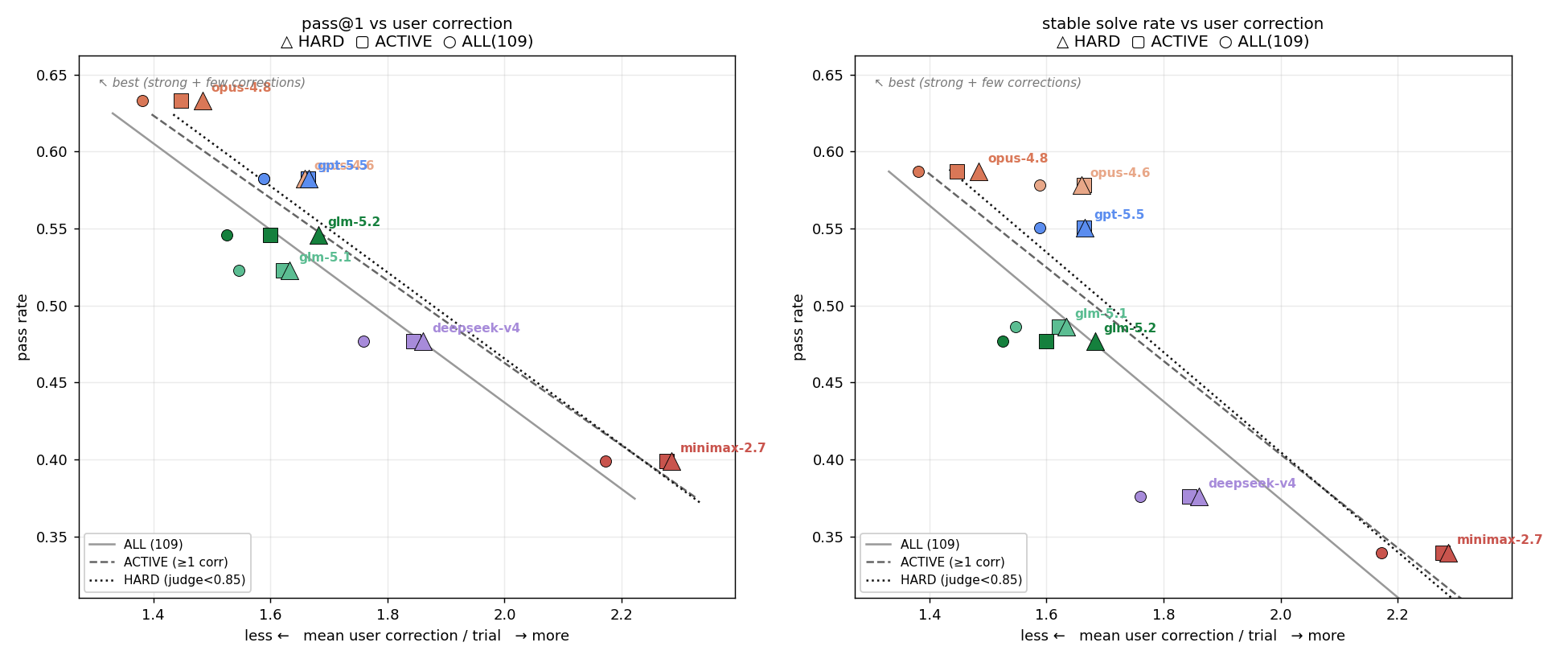
- Overall winner: Claude Opus 4.8 scored the highest on correctness and needed the least user correction on average (about 1.38 corrections per task).
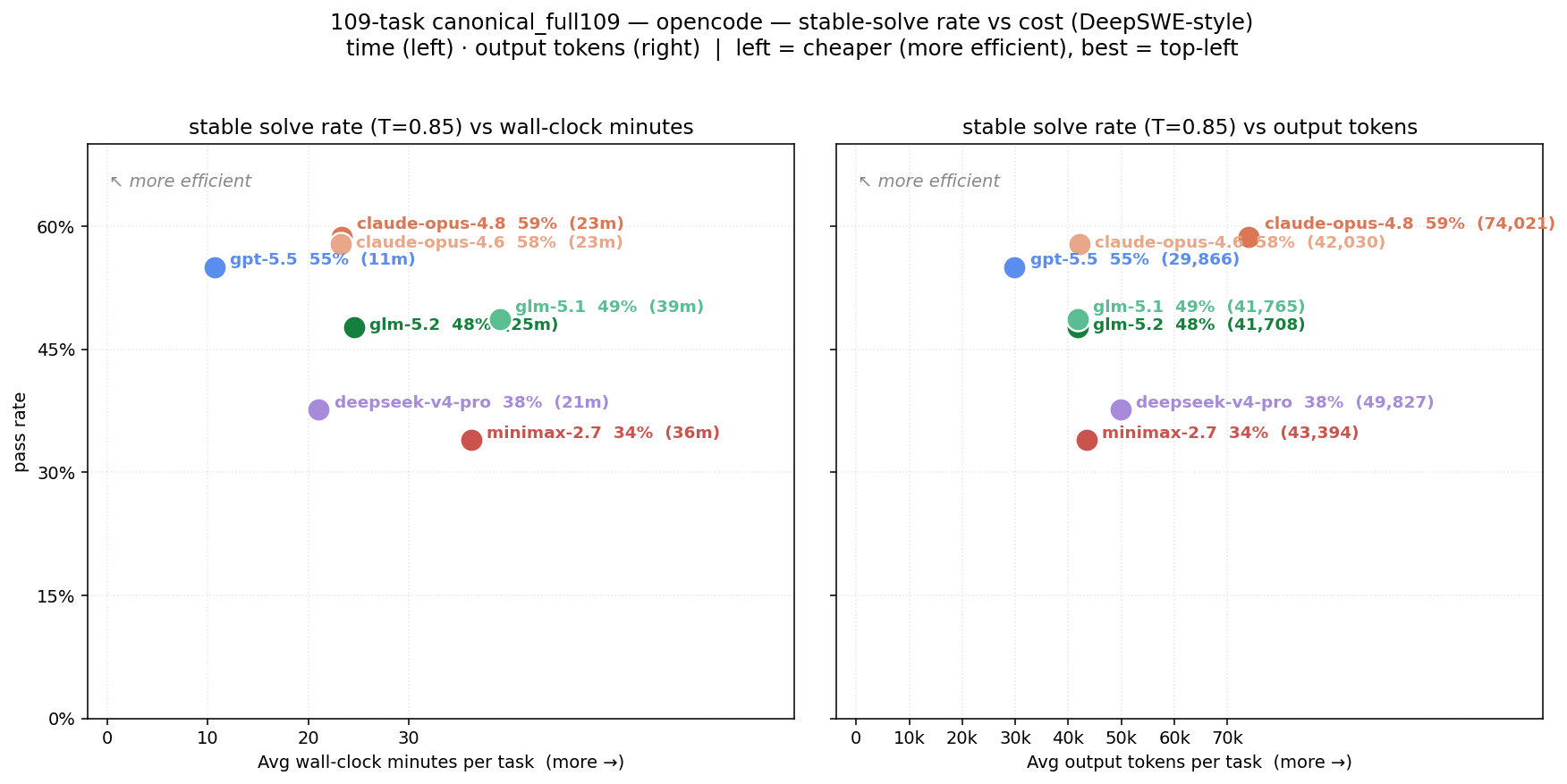
- GPT-5.5 was almost as strong and was the most efficient (fewer tokens and less time per task).
- Stronger AIs needed less coaching:
- There was a strong negative relationship between “how capable the model is” and “how much correction it needs.” In other words: better AIs require fewer pushes from the user to get things right.
- The user simulator stayed consistent:
- Across different coding AIs, the simulator usually communicated the original user’s intent well and stayed within scope (small variation in scores).
- In a small “Turing test,” human reviewers couldn’t reliably tell simulated user interactions from real ones (the simulated ones fooled people about as often as you’d expect by chance).
Why is this important?
- Realistic evaluation: Most older benchmarks give one-shot instructions. But real coding help is interactive. SWE-Together measures both the result and how smoothly you get there.
- Better comparisons: Two AIs might both finish the task, but if one needs way more nudges, that matters. SWE-Together captures that.
- Practical value: Teams choosing a coding assistant care about accuracy, reliability, and how much attention the human has to give. This benchmark reflects that real-world balance.
Limits of the study and what’s next
- The user simulator can’t interrupt mid-message, can’t edit files itself, and uses text only (no visuals).
- It works best for well-defined tasks with clear outcomes (like producing a patch); it’s less suited to open-ended brainstorming or vague requests.
- Future improvements could add richer interactions (like mid-turn interruptions), visual context, and broader task types.
Takeaway
SWE-Together is a new benchmark that tests coding AIs in realistic, multi-turn conversations rebuilt from real user sessions. It scores not just “Did it work?” but also “How much help did it need?” The results show clear differences between top models and confirm a common-sense idea: stronger coding AIs need less correction to reach good solutions. This kind of evaluation should help researchers and developers build and choose coding assistants that work well in the way people actually use them.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper, phrased concretely so future researchers can act on it.
- Representativeness and selection bias: quantify how the 109 retained tasks (0.97% yield) differ from the 11,260 raw sessions by language, domain, repo size, task type (bug fix vs feature vs refactor), and difficulty; report distributions and bias analyses.
- Language and framework coverage: report task mix across programming languages, frameworks, and ecosystems; add tasks beyond likely Python-heavy repos to test cross-language generalization.
- External-state tasks: develop mocked or sandbox-proxied variants to include tasks involving deployment, credentials, PR workflows, services, or APIs currently excluded by the viability screen.
- Dataset leakage risk: assess pretraining/exposure of evaluated models to the included repos, commits, or conversations; add time-based splits or contamination checks to quantify influence on scores.
- Generality across agent harnesses: replicate results with at least one additional agent framework/tooling stack to test whether rankings and metrics are harness-dependent.
- Reproducibility of LLM-driven components: measure run-to-run and day-to-day variance for both the user simulator and the rubric judge, including seed sensitivity and model-version drift; publish variance estimates and recommended procedures for stable scoring.
- Human-grounded validation of the rubric judge: conduct human expert studies to assess agreement with the agentic rubric judge at both goal and aggregate levels; report inter-annotator agreement and judge–human correlation.
- Threshold and weighting sensitivity: perform sensitivity analyses for the success threshold (τ = 0.85) and goal weights in the rubric; show how model rankings change under plausible thresholds/weightings.
- Separation of “process” vs “code” goals: the rubric currently mixes process requirements (e.g., explanations, hygiene) with behavioral correctness; provide separate sub-scores and investigate how process goals affect comparability and ceiling effects (e.g., reference patches failing).
- Deterministic verifier reliability: quantify false positives/negatives of executable checks versus human judgment across tasks; add systematic ablations (verifier-only vs rubric-only vs combined).
- Stability of Intent Coverage: validate how intents are decomposed (LLM vs rules vs human), check inter-rater reliability of intent sets, and report Intent Coverage variance across runs and tasks (not just across models).
- Validity of the User Correction tagger: benchmark the multi-label tagger against human annotations for precision/recall and robustness to phrasing; test whether simulator wording or cohort-specific styles systematically change tagger outputs.
- Weighting scheme for User Correction: the 1.0 (correction) vs 0.2 (nudge) weights are heuristic; explore alternative weights and show whether main findings (e.g., negative correlation with capability) persist.
- Causality of “stronger model needs less steering”: run controlled interventions (e.g., fixed scripted feedback vs adaptive simulator) to test whether lower User Correction causes better outcomes or merely correlates with them.
- Simulator action limitations: extend the action space beyond text (e.g., mid-turn interruptions, code edits, or running additional checks) and evaluate how richer interventions affect realism and comparability.
- Handling early/novel solutions: analyze how the simulator behaves when an agent solves tasks via paths not present in the original session; quantify any mis-timed or unnecessary interventions and their impact on scores.
- Realism beyond indistinguishability: the Turing-style test (46%, CI overlaps 50%) is small-scale; expand to more annotators, tasks, and criteria (usefulness, timing, specificity) to evaluate not only style realism but also functional adequacy of feedback.
- Coverage of ambiguous/open-ended work: design evaluation protocols for exploratory tasks (e.g., design proposals, trade-off analyses) that lack deterministic outcomes, possibly via structured rubrics or human-in-the-loop scoring.
- Efficiency comparability: normalize or control for serving location, rate limits, and backend latencies to ensure fair wall-clock comparisons; report model-side compute (e.g., tokens/sec) for more apples-to-apples efficiency metrics.
- Long-term maintainability of sandboxes: test task reproducibility over time (e.g., after dependency or OS updates) and provide hermetic containers or Nix/Guix configs to mitigate bit-rot.
- Task difficulty calibration: introduce difficulty labels/predictors (e.g., number of files touched, test coverage needed, dependency setup complexity) and analyze performance stratified by difficulty.
- Pass@k beyond k=2: evaluate with higher replicate counts to estimate pass@k curves and stability measures; justify k=2 as sufficient or provide guidance on minimal k for reliable comparisons.
- Cross-benchmark alignment: correlate SWE-Together scores with SWE-Bench/Terminal-Bench/CodeAssistBench on overlapping capabilities to understand what is new, redundant, or complementary.
- Gaming and robustness: probe whether agents can optimize to the judge (e.g., verbose justifications for process goals) without improving code quality; introduce adversarial trials to test judge robustness.
- Public release completeness: document simulator and judge prompts, seeds, and LLM versions; provide scripts to re-generate rubrics and replay interactions to enable external reproducibility audits.
- Scaling task construction: study why most sessions fail viability screening and propose methods (e.g., better repo-state recovery or automated test synthesis) to increase conversion yield without sacrificing verifiability.
Practical Applications
Immediate Applications
Below are applications that can be deployed with today’s tools and infrastructure, leveraging SWE-Together’s benchmark, user simulator, and evaluation protocol.
- Bold: Vendor evaluation and procurement benchmarking for coding assistants
- Sectors: software, finance IT, healthcare IT, energy IT, robotics software
- What: Use SWE-Together-style multi-turn sessions to compare AI coding assistants by both correctness and “user burden” (User Correction), not just pass@1.
- Tools/products/workflows: Benchmark-as-a-Service portal; standardized scorecards combining MeanJudge, SSR, pass@1, and User Correction; RFP checklists requiring multi-turn performance disclosure.
- Assumptions/dependencies: Access to reproducible environments; legal approval to evaluate vendor models on in-house or open tasks; consistent scoring via frozen rubrics.
- Bold: CI gating with interactive-agent regression suites
- Sectors: software, DevOps across all industries
- What: Convert internal user–agent chat logs into replayable, sandboxed tasks and run them in CI to catch regressions in agent quality (e.g., after model/version changes).
- Tools/products/workflows: Interactive Agent Regression Suite (IARS); nightly CI jobs that track pass@1 and User Correction deltas; alerts when “interaction cost” rises.
- Assumptions/dependencies: Logged sessions with consent; sandboxable repo states and pinned dependencies; modest GPU/LLM budget for replay.
- Bold: UX and workflow design for AI pair programming
- Sectors: software, education (coding bootcamps), internal developer platforms
- What: Use User Correction and Intent Coverage to quantify how interface changes (prompts, tool affordances, “clarify” buttons) reduce user steering needs.
- Tools/products/workflows: User Effort Dashboard; A/B tests that target lower User Correction without harming correctness.
- Assumptions/dependencies: Stable prompts/tooling per variant; enough traffic to detect changes; simulator reproducibility.
- Bold: Safety and reliability audits for regulated environments
- Sectors: healthcare IT, finance, energy, automotive/robotics software
- What: Document agent reliability with multi-turn metrics and show that simulators do not omit requirements (Intent Coverage audits), supporting governance and internal audits.
- Tools/products/workflows: Audit dossiers including rubric goals, evidence artifacts, and simulator-fidelity reports; change-control gates for agent updates.
- Assumptions/dependencies: Policy alignment on acceptable thresholds; auditable logs; privacy-preserving sandboxes.
- Bold: OSS maintainer workflows for agent-submitted patches
- Sectors: open-source software ecosystems
- What: Maintain per-repo SWE-Together tasks to evaluate bot PRs and auto-merge only when multi-turn correctness is high and User Correction is low.
- Tools/products/workflows: Maintainer-run pre-merge checks; badges showing a repo’s “agent readiness.”
- Assumptions/dependencies: Public reproducible repos; CI integration; community consensus on thresholds.
- Bold: Data-centric iteration on agent tool stacks
- Sectors: software, ML platform teams
- What: Diagnose where agents fail in real tasks (e.g., insufficient tests, flaky setup) and improve tool stacks, harnesses, and prompts guided by rubric-level misses.
- Tools/products/workflows: Rubric Goal Heatmaps; failure taxonomies by tool action sequence; targeted harness improvements.
- Assumptions/dependencies: Accurate rubric decomposition; consistent agent harness logging.
- Bold: Teaching and assessment with realistic multi-turn tasks
- Sectors: education
- What: Use SWE-Together-style tasks in courses to assess students’ ability to collaborate with coding agents (specification refinement, error correction).
- Tools/products/workflows: “Interactive assignment packs” with pinned repos and simulator; grading rubrics aligned to task goals; analysis of student-agent interaction quality.
- Assumptions/dependencies: Institutional policy on AI use; curated task difficulty; compute/time budgets.
- Bold: Internal model selection and routing
- Sectors: software, large enterprises with multiple LLMs
- What: Choose or route between models based on cost–capability trade-offs (e.g., GPT-5.5 vs. Opus 4.8) using stable solve rate vs. tokens/minutes.
- Tools/products/workflows: Routing policies that consider SSR and User Correction; per-task model portfolios.
- Assumptions/dependencies: Access to multiple models; reliable cost telemetry; performance drift monitoring.
- Bold: Customer-support bot maintenance for developer tools
- Sectors: software tooling vendors, platform providers
- What: Replay real customer-agent sessions as benchmarked tasks to reduce corrective back-and-forth and improve first-pass resolution.
- Tools/products/workflows: Simulator-grounded support triage suite; intent-recall reports to ensure all user follow-ups are addressed.
- Assumptions/dependencies: Consent to reuse support logs; PII scrubbing; repository mirroring for reproducibility.
- Bold: Research baselines and reproducible evaluation for interactive coding
- Sectors: academia, industrial research
- What: Use the anchored simulator, frozen rubrics, and public tasks for comparable, multi-turn evaluations and ablations.
- Tools/products/workflows: Shared leaderboards that include interaction diagnostics; replication packages for new control policies or toolsets.
- Assumptions/dependencies: Community adoption; careful calibration of the rubric judge.
- Bold: Fine-grained KPI setting for AI-dev enablement programs
- Sectors: enterprise engineering leadership
- What: Set explicit targets not only on solve rate but also on allowed User Correction per task; track velocity and usability impacts.
- Tools/products/workflows: Quarterly KPI dashboards; agent rollout gates tied to “interaction cost budgets.”
- Assumptions/dependencies: Agreement on measurement window and thresholds; representative task mix.
- Bold: Data pipeline to transform internal chats into tasks
- Sectors: software across industries
- What: Operationalize the eligibility filtering → viability screening → sandbox construction pipeline to build an internal, evolving benchmark from real sessions.
- Tools/products/workflows: Anchored User Simulator SDK; Repo Sandbox Builder; Agentic Rubric Judge Toolkit; governance for data retention and privacy.
- Assumptions/dependencies: Access-controlled logs; reproducible base commits; secure artifact storage.
Long-Term Applications
These require additional research, scaling, or ecosystem development before broad deployment.
- Bold: Training agents to optimize for “interaction cost” (minimize User Correction)
- Sectors: software, model providers
- What: Use User Correction as an auxiliary reward/signal for RL/DPO to encourage proactive clarification and error avoidance.
- Tools/products/workflows: Multi-objective training pipelines balancing correctness, latency, and user-effort rewards.
- Assumptions/dependencies: Large-scale interactive datasets; stable, unbiased User Correction estimates; careful reward design to avoid gaming.
- Bold: Cross-domain interactive simulators grounded in real sessions
- Sectors: data science/analytics, IT operations, DevSecOps, robotics
- What: Extend anchored, trajectory-conditioned user simulation to analytics notebooks, infra automation, or robot programming.
- Tools/products/workflows: Domain-specific anchored simulators; mixed tool/action spaces beyond code editing.
- Assumptions/dependencies: Availability of session logs and reproducible environments; safe sandboxing for non-code domains.
- Bold: Certification standards for interactive code agents
- Sectors: policy/regulation, procurement across regulated industries
- What: Create standards that mandate multi-turn metrics (Intent Coverage, User Correction) and scenario coverage before deployment in safety- or compliance-critical stacks.
- Tools/products/workflows: Third-party certification labs; test suites with documented rubrics and evidence artifacts.
- Assumptions/dependencies: Industry consensus; regulatory buy-in; neutral test hosting.
- Bold: Autonomously adaptive simulators that can interrupt and edit
- Sectors: software, HCI research
- What: Evolve simulators to interrupt mid-turn, make code edits, and handle multimodal context (UI, logs), approximating real pair-programming.
- Tools/products/workflows: Interruptible agent harnesses; mixed-initiative control policies; UI state capture.
- Assumptions/dependencies: New harness capabilities; evaluation protocols that fairly attribute responsibility between agent and simulator.
- Bold: Richer rubrics that capture process-quality and human factors
- Sectors: software quality, education, policy
- What: Weight goals like diagnostics quality, test hygiene, and explanation clarity; link to developer satisfaction metrics.
- Tools/products/workflows: Process-aware rubric judges; validated human-in-the-loop calibration studies.
- Assumptions/dependencies: Agreement on process-quality definitions; scalable judging without bias leakage.
- Bold: Organization-wide “agent readiness” programs
- Sectors: enterprise engineering
- What: Use continuous SWE-Together-style telemetry to gate where and how AI agents can act (read-only vs. write access; auto-PR vs. human review).
- Tools/products/workflows: Policy engines mapping capability metrics to permission tiers; automatic rollback on degradation.
- Assumptions/dependencies: Robust identity, access control, and observability; risk appetite alignment.
- Bold: Interactive curricula and certification for developers collaborating with AI
- Sectors: education, professional upskilling
- What: Certify developers on effective agent collaboration strategies (iterative intent refinement, constraint setting), assessed via multi-turn tasks.
- Tools/products/workflows: Scenario banks; proctored simulator-based exams; feedback analytics for coaching.
- Assumptions/dependencies: Widely accepted skill frameworks; scalable exam delivery.
- Bold: Sector-tailored benchmarks (healthcare, finance, energy)
- Sectors: healthcare IT, finance, energy
- What: Curate domain-specific repo tasks (e.g., HIPAA-aware logging, Basel risk calculators, grid telemetry parsers) with anchored user feedback patterns.
- Tools/products/workflows: Domain rubrics encoding regulatory and safety constraints; red-team variants for edge cases.
- Assumptions/dependencies: Access to representative code and policies; domain SMEs; strict privacy controls.
- Bold: Marketplace of replayable interactive tasks
- Sectors: software ecosystem, OSS communities
- What: A shared repository where maintainers and teams publish sandboxed multi-turn tasks for benchmarking, training, and hiring.
- Tools/products/workflows: Task exchange with metadata (difficulty, tools, environment); reputation and versioning.
- Assumptions/dependencies: Licensing clarity; quality moderation; sustainable hosting.
- Bold: Causal evaluation of tooling and prompt strategies
- Sectors: research, platform teams
- What: Use anchored replay and fixed rubrics to isolate causal effects of changes (tools, prompts, memory) on interaction cost and correctness.
- Tools/products/workflows: Randomized task assignment; counterfactual replays; metascience dashboards.
- Assumptions/dependencies: Sufficient task diversity and sample sizes; robust statistical pipelines.
Glossary
- Agent-environment multi-turn: An evaluation setup where an agent iteratively interacts with tools and the codebase while pursuing a fixed user request. "Agent-environment multi-turn refers to episodes in which an agent iteratively inspects files, runs commands, edits code, and invokes tests while solving a fixed user request."
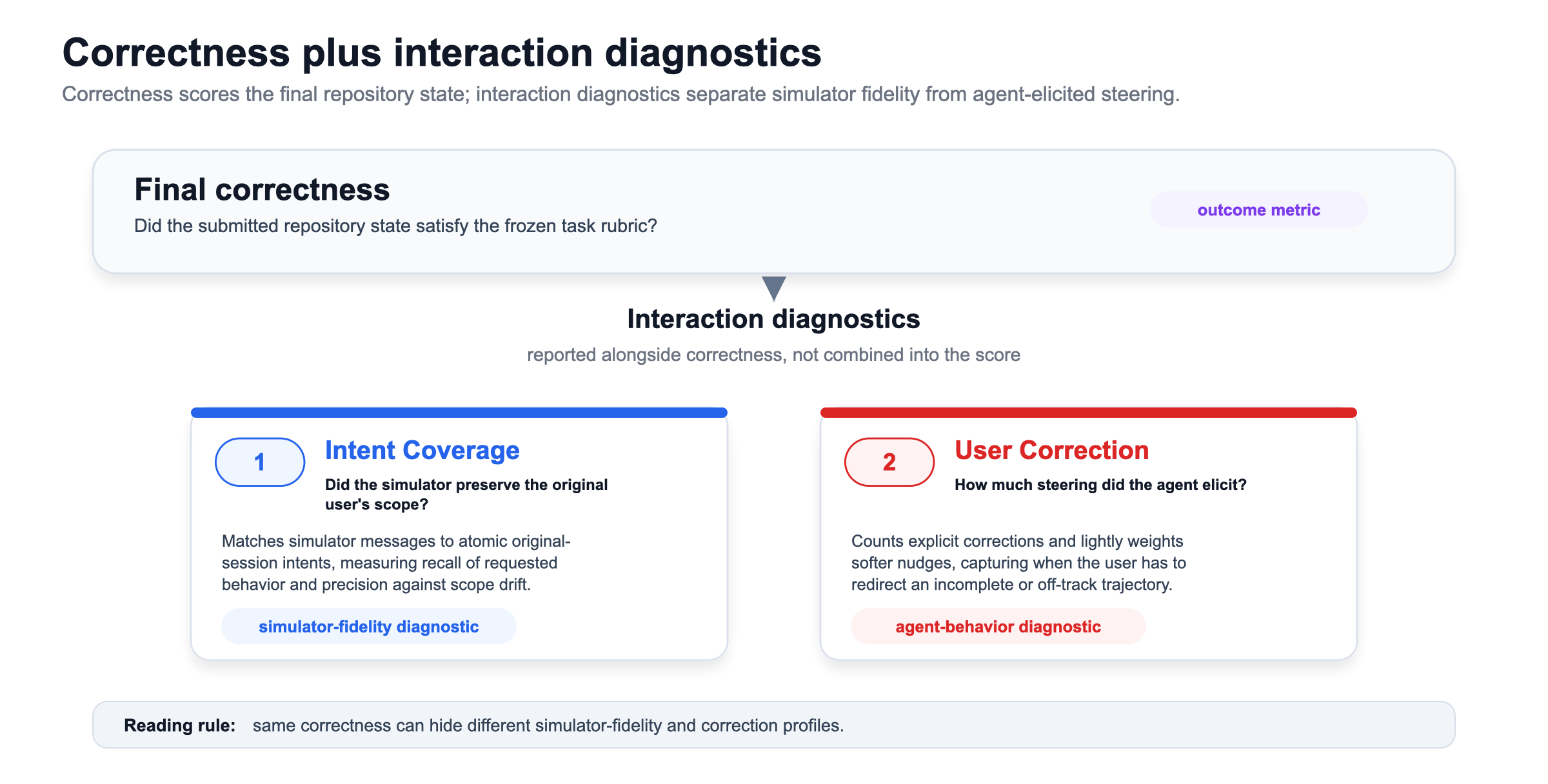
- Agentic rubric judge: An automated evaluator that applies a predefined rubric, using both code inspection and execution evidence, to score task completeness. "Correctness is assessed by an agentic rubric judge using repository inspection and executable evidence, while user-simulator behavior is characterized through User Correction and Intent Coverage."
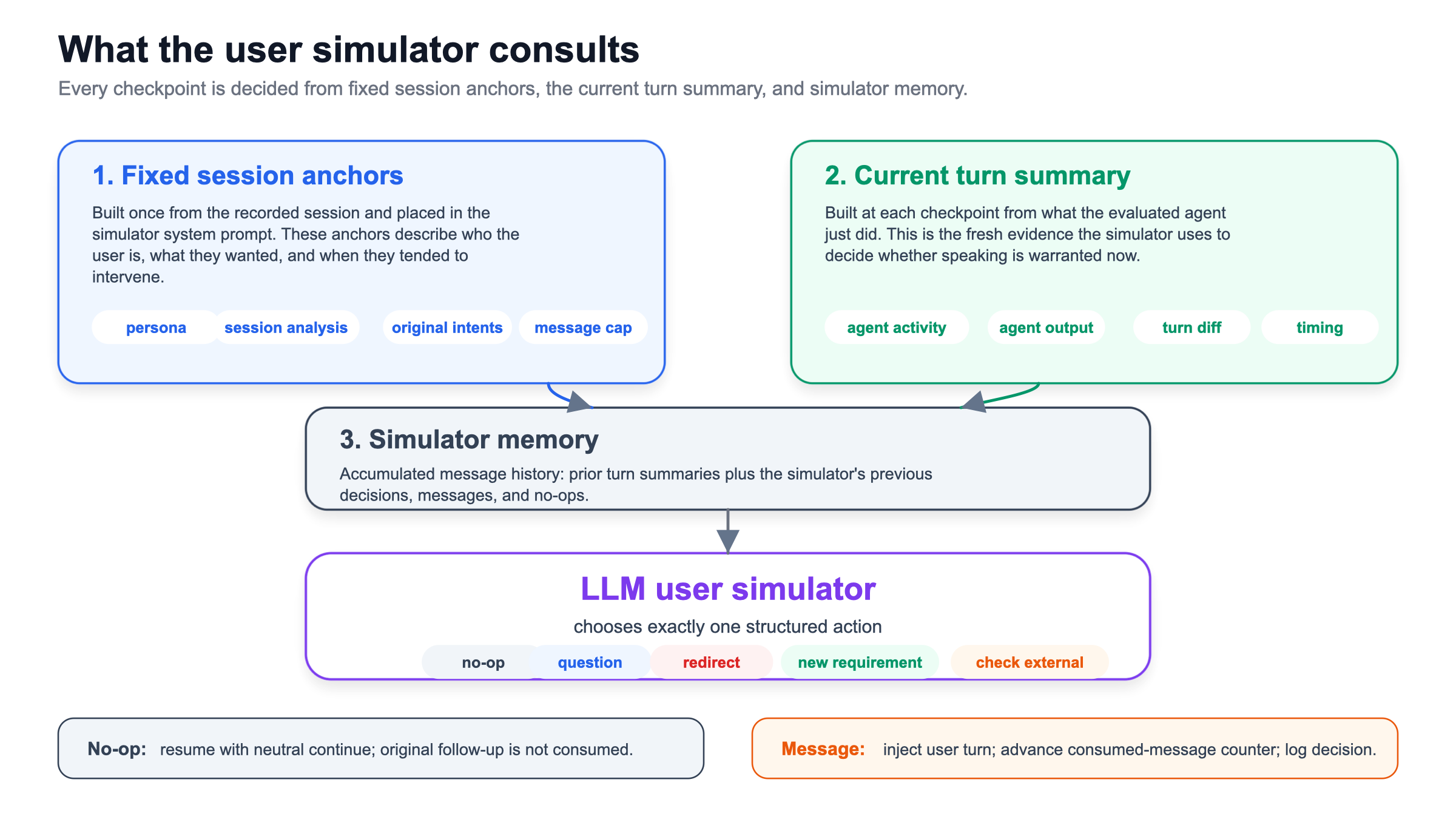
- Anchored, state-conditional LLM user simulator: A simulator grounded in the original session that adapts its timing to the agent’s live trajectory, intervening only when predefined conditions occur. "We develop an anchored, state-conditional LLM user simulator that preserves the original user's intent and intervention order while adapting feedback to each evaluated agent's evolving trajectory."
- Deterministic eligibility filtering: A rule-based initial screening that selects candidate sessions without using LLMs. "Step 1: Deterministic Eligibility Filtering"
- Deterministic verifier: A fixed, executable check that provides objective evidence (e.g., tests, commands) for scoring solutions. "Our evaluator therefore combines deterministic verifiers with an agentic rubric judge."
- Frozen rubric: A task-specific scoring rubric fixed before evaluation to ensure cross-agent comparability. "the task's frozen rubric from Section~\ref{sec:task_correctness}"
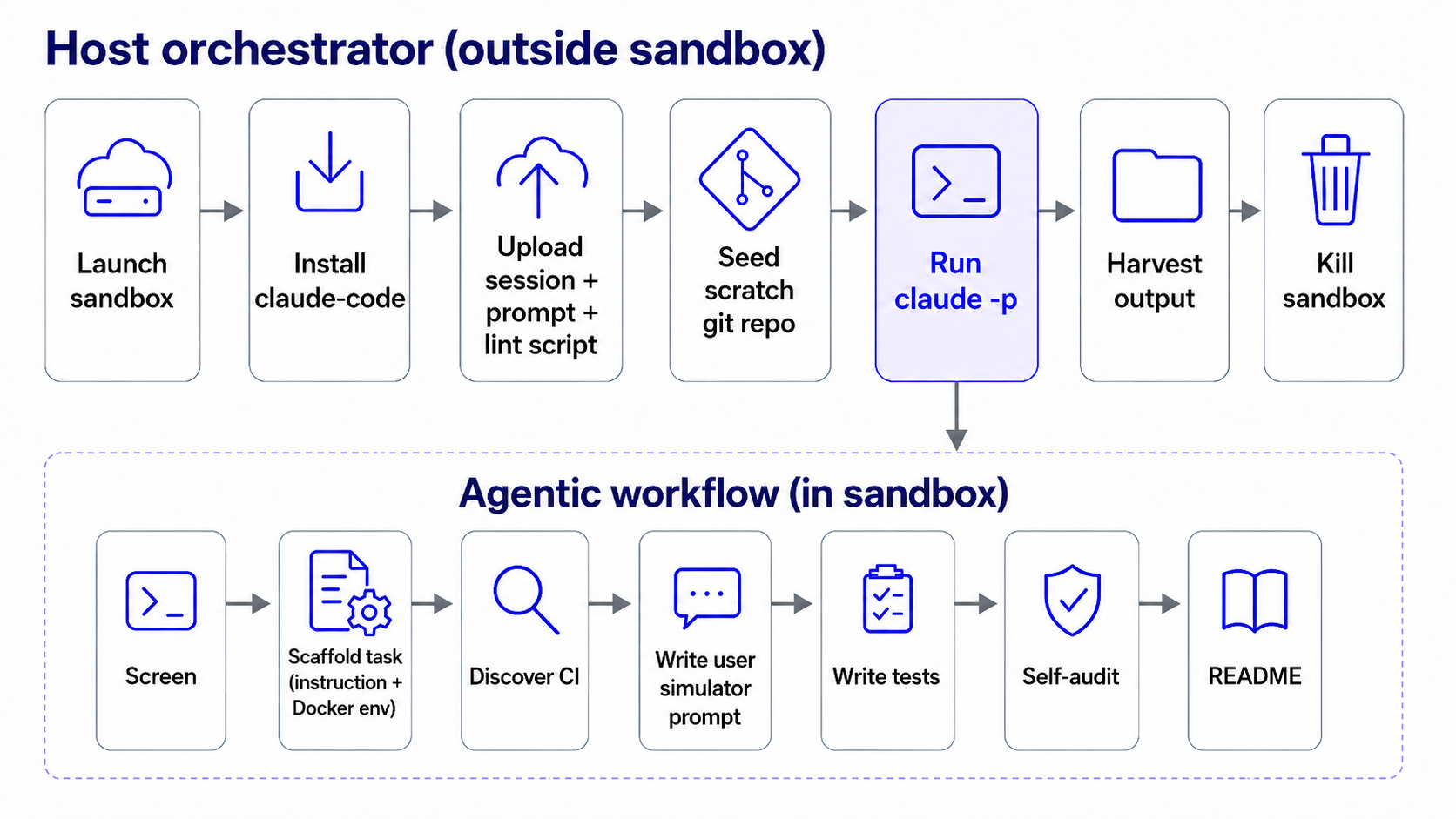
- Host orchestrator: A controller that creates isolated environments and coordinates task construction inside sandboxes. "For each candidate, a host orchestrator launches an isolated sandbox, provides the normalized session and prompt %{what's the authoring prompt?}, and harvests the generated task directory."
- Intent Coverage: A diagnostic measuring how faithfully the simulator re-expresses the original user’s intents and stays within scope. "Intent Coverage measures how faithfully the simulator preserves the original user intents of the original session."
- Interactive replay: Evaluation in which the user-facing instruction evolves across turns via feedback, corrections, and clarifications. "Interactive replay refers to episodes in which the user-facing instruction evolves through feedback,corrections, clarifications, or new requirements."
- LLM judge: A LLM used to assess whether a session can be turned into a reproducible, verifiable task. "an LLM judge determines whether the coding work can be reconstructed as a reproducible and verifiable task."
- Multi-label tagger: A classifier that can assign multiple communicative-function tags (e.g., correction, request, nudge) to a single message. "we apply a multi-label tagger to every simulator message."
- No-op: A simulator action that does nothing, allowing the agent to proceed without additional user input. "The default action is no-op, which keeps the simulator silent and lets the agent continue without consuming one of the original follow-up messages."
- pass@1: The marginal per-run success rate; the probability that one run solves the task under a thresholded judge score. "pass@1 is the marginal per-run success rate and estimates the probability that a single fresh run solves the task."
- Pinned commit: A fixed repository revision used to ensure reproducibility during task reconstruction and evaluation. "Inside the sandbox, a task-generation agent performs a stricter repository-grounded screen, clones the target repository at a pinned commit, identifies local setup and test commands, and writes the task artifacts."
- Pinned execution environment: A controlled, fixed software environment used to ensure consistent, reproducible execution of tasks. "The resulting package contains the original session record, the initial user instruction, a pinned execution environment, deterministic verifier artifacts, and a task-specific user-simulation prompt."
- Replay checkpoint: A point in the interaction where the simulator considers the live trajectory plus anchors and memory to decide whether to intervene. "Each replay checkpoint combines fixed session anchors, a summary of the evaluated agent's latest turn, and simulator memory from earlier checkpoints."
- Scope precision: The fraction of simulator messages that remain within the original user’s scope during replay. "scope precision $I_{\mathrm{precision}$, which measures how consistently its guidance remains within the original user's scope."
- Stable solve rate (SSR): A reliability metric that thresholds the average judge score across replicates for each task. "The stable solve rate (SSR) first averages the continuous judge scores within each task and then applies the threshold, measuring whether the model is reliable on average while tolerating an occasional weak or near-miss run."
- State-conditioned decision policy: A policy that triggers simulator interventions based on the agent’s current trajectory and predefined anchors. "At evaluation time, these anchors define a state-conditioned decision policy: the simulator speaks when the live trajectory warrants feedback and otherwise returns no-op."
- Tool-use distribution: A summary of which tools were used and how often in a session, used during screening. "The screener receives a compact session summary: repository metadata, message/tool/edit counts, a tool-use distribution, selected user messages, edited file paths, and truncated shell commands."
- Trajectory-conditioned: Dependent on the agent’s recent actions and state rather than fixed timing, to avoid mistimed or irrelevant interventions. "The simulator follows two principles: interventions are trajectory-conditioned rather than scheduled, and anchored to the original session rather than generic."
- Turing pass rate: The rate at which simulated trajectories are judged as real by human annotators in a forced-choice test. "We report the Turing pass rate, defined as the fraction of judgments in which the simulated trajectory is selected as real."
- User Correction: A metric counting corrective interventions (with full weight for corrections and lower weight for nudges) required to guide the agent. "We define ``User Correction'' to test the hypothesis that a stronger model requires less intervention to reach the same level of performance."
- Viability screening: A stage that checks if the recorded session’s deliverable can be reconstructed as a self-contained, locally executable task. "``Final tasks'' denotes sessions that passed eligibility filtering and viability screening, and were successfully converted into executable tasks for the evaluated 109-task suite."
- Weighted intent recall: The degree to which the simulator re-expresses all original user intents during replay, weighted by importance. "From this matching, we derive weighted intent recall $I_{\mathrm{recall}$, which measures how completely the simulator re-expresses the original requests, and scope precision $I_{\mathrm{precision}$, which measures how consistently its guidance remains within the original user's scope."
- Weighted task rubric: A rubric with goals weighted to allow partial credit, derived once per task and reused across agent submissions. "Phase~1 runs once per task to derive a weighted task rubric, and Phase~2 applies that same rubric to each candidate repository state."
Collections
Sign up for free to add this paper to one or more collections.