Latent Actions from Factorized Transition Effects under Agent Ambiguity
Abstract: Latent Action Models (LAMs) learn action-like proxies from observation transitions. However, in multi-object or distractor-rich scenes, these visual effects mix agent motion with distractors, camera dynamics, and background changes, making the underlying action source ambiguous without supervision. Structuring this mixture as reusable transition effects provides an intermediate representation from which action-like latents can be more robustly formed. We introduce Observed Transition Factorization (OTF), which decomposes each transition into a sparse set of observed transition primitives. Using these primitives as the transition interface, we propose OTF-LAM, which abstracts motion primitives into action-like latents within the standard inverse-forward dynamics framework, and OTF-LAM-Dino, a decoder-free variant that predicts future states in a frozen DINOv2 representation space. Empirically, OTF primitives transfer zeroshot across controlled carrier and morphology shifts, showing reusability. Furthermore, downstream policy learning results match or outperform baselines under complex transition ambiguity.
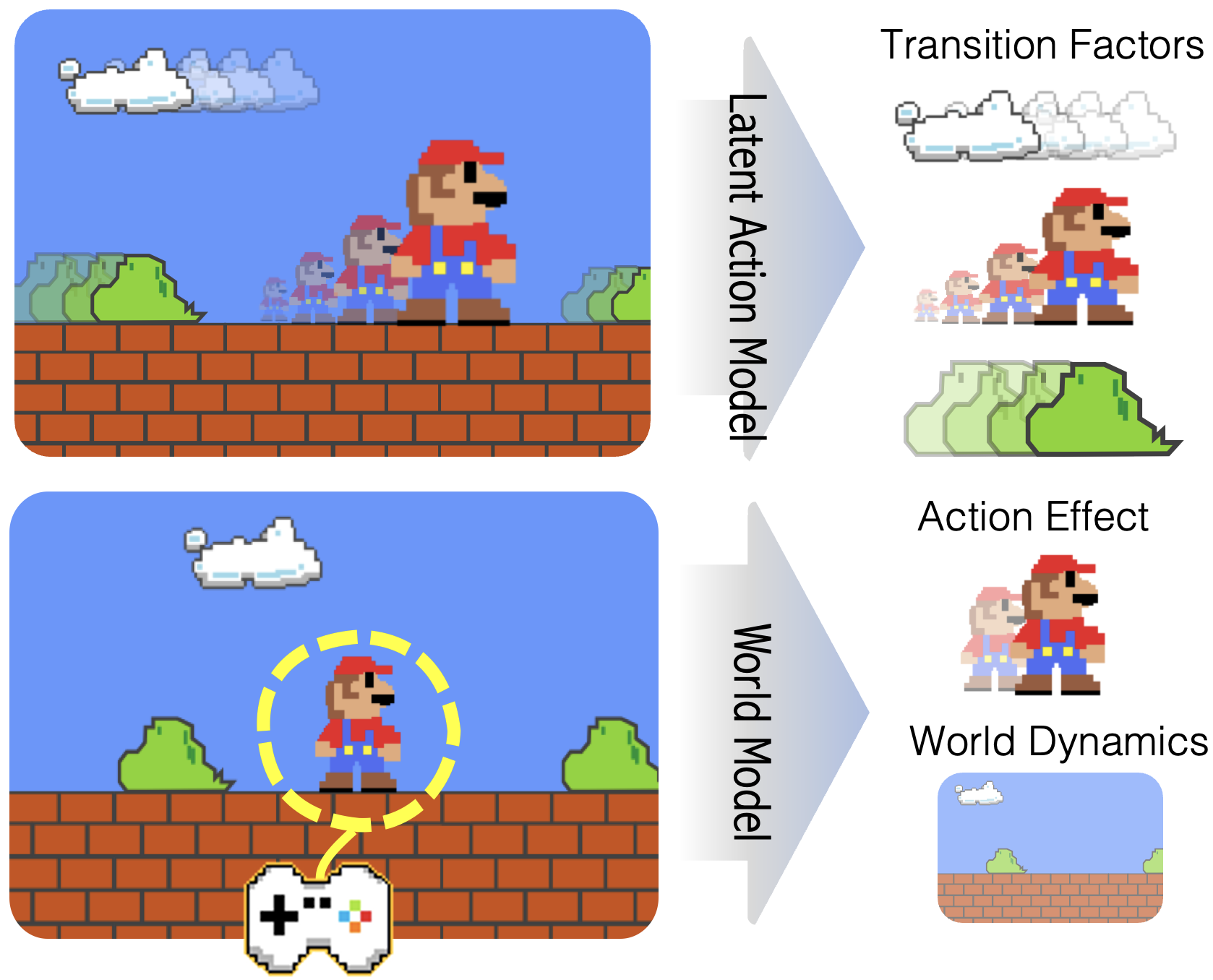




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Latent Actions from Factorized Transition Effects under Agent Ambiguity”
What is this paper about?
This paper is about teaching computers to understand “actions” in videos without being told what the actions are. Instead of using labeled buttons or joystick commands, the model only sees two frames of a video (before and after) and tries to figure out what changed and why. The authors argue that, in busy scenes with moving backgrounds or other objects (called distractors), it’s hard to tell which changes were caused by the main character. Their solution is to first break the visible change into simple, reusable pieces of motion, then combine those pieces to form an “action-like” code the computer can use for prediction and control.
What questions does it ask?
- Can we learn a library of basic, reusable “visual change pieces” (like Lego bricks of motion) directly from videos?
- Can these pieces help us build better “action-like” codes when there are distractors and camera motion?
- Do these motion pieces work on new characters or new looks without retraining (zero-shot transfer)?
- Will policies (controllers) trained on these action-like codes perform as well as or better than existing methods?
How does it work? (Methods in simple terms)
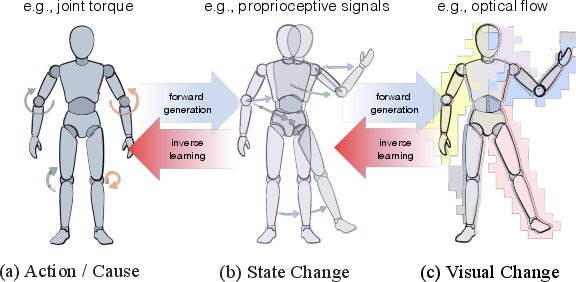
Think of an action as a 3-step chain:
- A real action happens (like pressing “right”).
- It changes the physical state (the character moves).
- We see a visual effect in the pixels (edges shift right, legs swing, background drifts).
Because the model only sees pixels, it’s safest to first learn level 3: the visual effects. Then we work upward to build action-like codes.
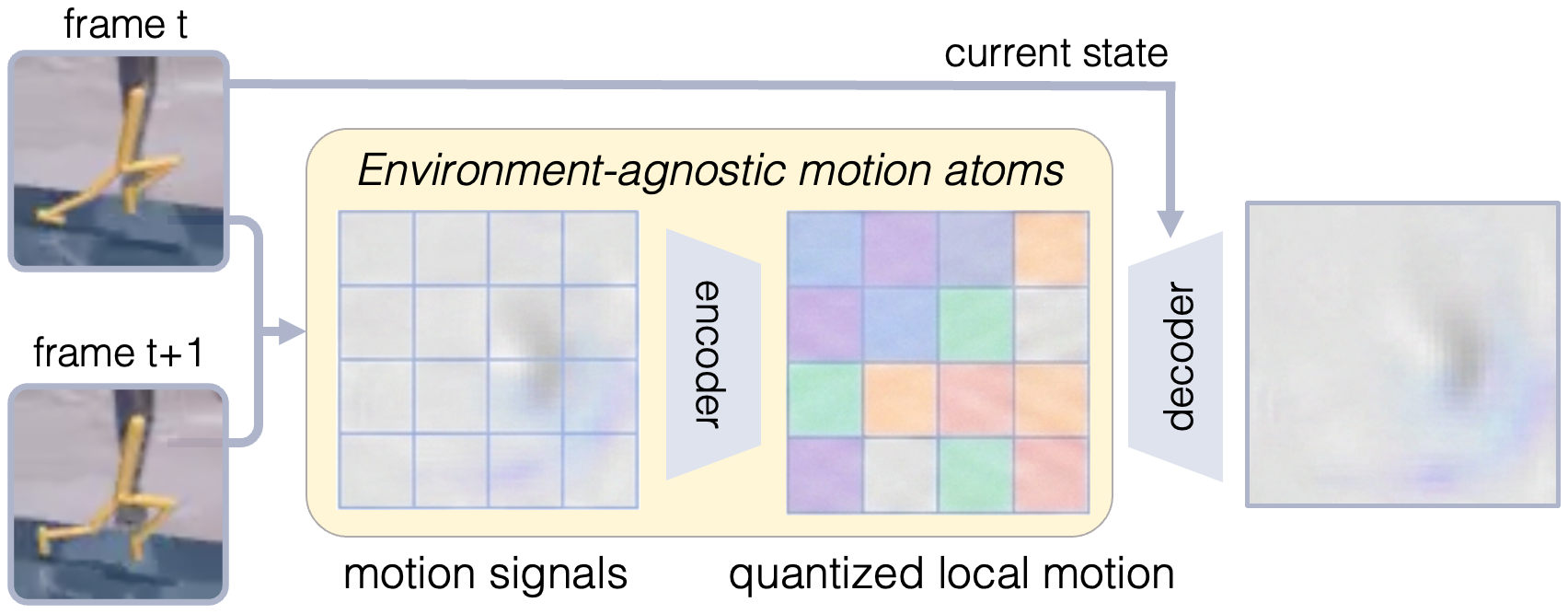
Step 1: Build a vocabulary of visual changes (OTF)
- The method, called Observed Transition Factorization (OTF), looks at the difference between two frames and turns it into a grid of small patches (like tiling the image).
- For each patch, it picks the best “motion sticker” from a learned dictionary (called a codebook). Each sticker describes a local effect like “something moved slightly to the right here” or “an edge appeared here.”
- The result is a sparse list of which stickers were used, where they were placed, and how strong they were. This is the scene’s visual change written in a shared, reusable vocabulary.
- Analogy: You watch a short clip and describe the change not in words like “Mario jumps,” but in tiny motion stickers placed over the image: “this edge shifted up,” “this patch rotated a bit,” “background slid left.”
Why this helps:
- Stickers capture visual effects, not object identity. “Shift-right” looks similar whether it’s Mario or Kirby.
- Because the stickers are local and reusable, they can transfer to new scenes and characters.
Step 2: Turn motion pieces into action-like codes (OTF-LAM)
- Now we want one compact code that summarizes the important motion effects for prediction.
- The model looks at the selected motion stickers and the current frame, scores which stickers matter (a “relevance gate”), and blends the important ones into a short “action-like” vector.
- This vector is then used with the current frame to predict the next frame (or the change to get there).
- Analogy: From many small motion stickers, pick and mix the ones that best explain the change caused by the main character, producing a short summary of “what action-like thing just happened.”
Step 3: A decoder-free variant that predicts in feature space (OTF-LAM-Dino)
- Predicting future pixels can force the model to care about texture, lighting, or background distractions.
- The paper also tries predicting the future in a frozen feature space from DINOv2 (a powerful vision encoder). Think of it as predicting in a language of visual features that already ignores many pixel-level distractions.
- This variant often performs even better, because it focuses on meaningful state changes instead of tiny pixel details.
Learning a policy: mapping to real actions
- Pixel changes alone can’t tell you exactly which control (like which key) was pressed.
- So, after learning the action-like space, the authors use a small set of videos that do have action labels (a few dozen trajectories) to learn a simple translator from the action-like code (plus the current frame) to the true control commands.
- This small supervised step resolves the final ambiguity.
What did they find, and why is it important?
Main results:
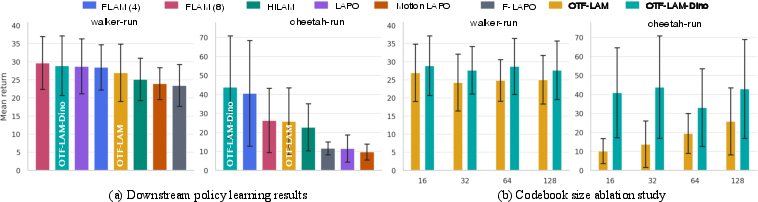
- The motion stickers (OTF primitives) transfer zero-shot:
- From one robot body to another (e.g., learned on walker, applied to cheetah).
- From one set of digits to new digits in Moving MNIST (learned on digits 0–4, works on 5–9).
- Policies trained with OTF-LAM match or beat strong baselines when scenes are messy with distractors.
- The decoder-free version (OTF-LAM-Dino), which predicts future features instead of pixels, often works best. It seems to ignore unhelpful pixel details and focus on core motion.
Why this matters:
- It shows that focusing on reusable visual effects (the “what changed” in the image) is a powerful middle step before trying to infer actions.
- This approach is more robust to distractions, camera motion, and different characters or bodies.
- It reduces how much action-labeled data is needed: most of the learning is from unlabeled videos, then a small labeled set finishes the mapping.
What’s the impact?
- For learning from “in-the-wild” videos (like YouTube), where we don’t have button logs or labels, this method offers a practical path: learn reusable motion pieces first, then build action-like codes, and finally do a tiny amount of supervision.
- It could make video-based robotics and game-playing systems more general, handling new environments or characters without starting over.
- Future steps include testing on even richer, more chaotic worlds (like platformers with scrolling cameras and many moving objects) and refining how big the motion vocabulary should be.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, concrete list of what remains missing, uncertain, or unexplored in the paper, to guide future research:
- Identifiability guarantees: No theoretical analysis of when (and under what assumptions) OTF’s factorized primitives or the aggregated latent action are identifiable or unique, especially under mixed exogenous and endogenous motion.
- Controllability attribution: The method learns action-like latents without explicitly separating controllable from exogenous transition factors; it remains unclear whether (and how reliably) the gating mechanism can isolate controllable effects without supervision.
- Multi-step dynamics: Training and evaluation focus on single-step prediction; the stability and usefulness of OTF/OTF-LAM(-Dino) for multi-step rollouts, long-horizon planning, compounding error, and model-based RL are not assessed.
- Generalization scope: Empirical validation is limited to DCS (cheetah-run, walker-run) and Moving MNIST; transfer to richer, dynamic, in-the-wild video domains (e.g., scrolling cameras, heavy egomotion, complex backgrounds, multiple distractors, multi-agent interactions) remains untested.
- Camera and egomotion handling: The approach does not explicitly model egomotion or camera changes; robustness to large view shifts, parallax, zoom, and rolling background motion is not evaluated.
- Robustness to visual nuisances: Sensitivity to occlusions, motion blur, lighting changes, shadows, compression artifacts, or sensor noise in the motion signal is not quantified.
- Motion input design: Only gradient/Sobel differences are considered; comparisons to learned or flow-based motion (e.g., RAFT), event-based inputs, or multi-stride fusion are missing, as is a study of when each motion representation is preferable.
- Patch size and stride: The locality–context trade-off is acknowledged but not systematically studied across patch sizes, overlaps, strides, or multi-scale setups; guidelines for choosing these are absent.
- Codebook size and structure: Effects of vocabulary size K are only partially probed; interactions with task complexity, data scale, and representation space (pixels vs DINO) are not characterized; product-quantization, hierarchical, or multi-scale codebooks are unexplored.
- Hard vs soft quantization: Top-1 nearest-neighbor assignment is used; the impact of soft/k-nearest assignments, entropy regularization, or sparse coding on transferability and reconstruction quality is not examined.
- Spatial compositionality: Only non-overlapping patches are used; the benefits of overlapping patches, deformable grids, or attention-based dynamic receptive fields for capturing non-local/global effects are not explored.
- Temporal consistency of primitives: Whether code assignments and factors remain stable over time for the same underlying effect is not analyzed (e.g., tracking consistency, temporal smoothness regularizers).
- Factor sparsity and selection: The method assumes sparse activation but does not study explicit sparsity constraints, thresholds, or selection strategies; how sparsity impacts transfer and downstream control is unclear.
- Action supervision dependence: A small supervised mapping (32 trajectories) is required to decode latents to real actions; the sample efficiency curve, robustness to reduced labels, and alternatives to supervision (e.g., weak/implicit signals) are not studied.
- Action decoding design: The action decoder conditions on the pixel frame, which may re-entangle appearance; ablations on conditioning choices and their effect on generalization are not provided.
- Cross-embodiment transfer limits: Transfer is shown across walker→cheetah and digit carriers, but not across drastically different control interfaces, actuation delays, or contact-rich manipulation; failure modes and limits of embodiment transfer are unspecified.
- Evaluation breadth and rigor: Only two DCS tasks and 3 seeds are reported; statistical significance, task diversity (e.g., discrete vs continuous control, sparse rewards), and ablations controlling for model capacity/compute are limited.
- DINO dependence: OTF-LAM-Dino uses a frozen DINOv2; sensitivity to the choice/version of the frozen encoder, domain shifts where DINO features degrade, or alternative JEPA-style backbones is not investigated.
- Decoder-free vs pixel-space trade-offs: Why and when representation-space prediction outperforms pixel prediction (beyond heuristic explanation) is not deeply analyzed; hybrid or learned target spaces are untested.
- Adaptation of the vocabulary: The codebook is trained once and frozen; mechanisms for continual or online adaptation to novel transition effects, non-stationary environments, or catastrophic mismatch are not addressed.
- Interpretability and diagnostics: There is no quantitative assessment of whether codes align with semantically meaningful motion categories (e.g., rightward limb swing vs background drift) or tools for diagnosing misattributions.
- Computational efficiency: Memory/time costs of patchwise VQ across frames, scalability to higher resolutions and higher frame-rates, and latency for control are not reported.
- Failure-case analysis: The paper lacks qualitative/quantitative analyses of when OTF fails (e.g., dense global motion, very small/fast objects, textureless regions), and how such failures propagate to control.
- Comparison to object-centric alternatives: While object-centric assumptions are discussed, systematic empirical comparison under varied distractor densities and object counts (including mixed moving/static objects) is missing.
- Multi-agent and interaction dynamics: Scenarios with multiple controllable entities, collisions, contact dynamics, or tool-use where factor interactions are nonlinear remain unexplored.
- Large-scale pretraining: Effects of scaling unlabeled pretraining data, diversity, and curricula on the universality and reusability of primitives are not studied.
- Safety and adversarial robustness: Sensitivity to adversarial perturbations or worst-case distractor patterns that could corrupt learned latents is not considered.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can leverage OTF-LAM and OTF-LAM-Dino with today’s tooling and moderate engineering effort.
- Latent-action policy learning from video with minimal labels (Robotics, Software)
- Use OTF as a reusable transition interface to learn policies from unlabeled videos, then fit a small action decoder with tens of labeled trajectories to map latent actions to real controls.
- Tools/workflow: pretrain OTF on raw videos from the target setup; freeze OTF; train action abstraction + forward model; collect a small labeled calibration set (e.g., ~32 trajectories); fit action decoder; deploy policy.
- Assumptions/dependencies: access to domain-relevant videos; a small supervised action dataset per embodiment; camera viewpoints roughly consistent with deployment; GPU for VQ and DINO processing.
- Robust control in distractor-rich environments (Robotics, Manufacturing)
- Improve policy learning where background/camera/distractor dynamics confound action inference by gating and aggregating factorized observed effects rather than relying on monolithic latents.
- Tools/workflow: drop-in replacement for LAMs within existing IDM/FDM pipelines; visualize factor gates to debug failure modes.
- Assumptions/dependencies: visual distractors are common; motion transforms (e.g., gradient/Sobel) accentuate transitions; latency/compute budget supports patchwise factorization.
- Cross-embodiment transfer for sim and bench-top robotics (Robotics)
- Reuse an OTF codebook trained on one morphology across similar tasks or new platforms; only retrain the action decoder with a small labeled set.
- Tools/workflow: build a shared motion-primitive library at the lab level; per-robot “calibration” via short action-labeled sessions.
- Assumptions/dependencies: target domain shares observable motion regularities; limited but nonzero supervision to resolve embodiment-specific action mappings.
- Video indexing and retrieval by motion primitives (Media, Sports, Security)
- Index footage by OTF code activations to search for recurring motion patterns (e.g., “rightward displacement,” “contact/deformation,” “rotation-like residuals”).
- Tools/workflow: batch-embed archives; store per-clip primitive histograms and occupancy maps; expose search over code sequences.
- Assumptions/dependencies: domain-specific pretraining of OTF for reliable primitives; searchable metadata infra.
- Anomaly and quality control monitoring via “transition signatures” (Manufacturing, Security)
- Learn normal distributions over OTF primitives for a process/scene; flag deviations (e.g., unusual machine motion or crowd behavior).
- Tools/workflow: fit unsupervised baseline on normal operation; online scoring of streaming video by primitive distributions.
- Assumptions/dependencies: relatively stationary normal patterns; sufficient training footage; alarm thresholds tuned to workload.
- Camera/subject disentanglement for tracking and stabilization (Mobile, Drones, Video Tools)
- Separate subject-induced transitions from background/camera motion for steadier tracking and digital stabilization.
- Tools/workflow: run OTF on-device to weight/gate subject-relevant factors before tracker updates.
- Assumptions/dependencies: compute-constrained inference (optimize patch size/K); reliable detection of subject-relevant codes without explicit segmentation.
- Imitation learning from internet videos with light supervision (Robotics, Education)
- Distill latent action spaces from unlabeled demonstrations (e.g., locomotion on DCS-like tasks) and map them to a robot with a small action-labeled set.
- Tools/workflow: OTF pretraining on domain-relevant YouTube datasets; per-robot action decoder; optional safety filters.
- Assumptions/dependencies: domain gap between internet and robot views manageable; safety review for real-world execution.
- Forecasting in a frozen representation space (OTF-LAM-Dino) for perception stacks (Software, CV)
- Replace pixel prediction with DINO-space prediction to reduce nuisance sensitivity in downstream tasks like tracking, segmentation, or anticipation.
- Tools/workflow: drop-in auto-regressive forecasting head over DINO features conditioned on z_act; evaluate gains in robustness to lighting/texture.
- Assumptions/dependencies: DINOv2 generalizes to the target domain; prediction horizon/stride tuned to task latency.
- Research diagnostics and dataset curation (Academia)
- Use code occupancy maps and gates to audit which visual effects drive predictions; identify spurious correlations; design stress tests for distractors.
- Tools/workflow: visualization of M_tk, α_{t,k}; ablate code subsets; compare monolithic vs factorized representations.
- Assumptions/dependencies: access to training internals; reproducible pipelines for controlled ablations.
Long-Term Applications
The following applications are promising but will benefit from further research, larger-scale pretraining, standardization, or systems integration.
- Embodiment-agnostic “motion vocabulary” foundation models (Robotics, Software)
- Pretrain OTF on internet-scale video to yield a universal transition codebook reused across robots and tasks; reduce per-robot supervision to minimal calibration.
- Potential products/workflows: hosted “motion tokenizer” API; robot SDK that ships with a foundation motion vocabulary; skill transfer via shared latent effect distributions.
- Assumptions/dependencies: large-scale, diverse pretraining; standard interfaces for action decoders; robust cross-domain generalization; safety certification.
- Cross-robot skill libraries and marketplaces (Robotics)
- Distribute skills as distributions/sequences over observed-transition primitives rather than actuator commands; vendors supply small decoders per platform.
- Potential products/workflows: “skill packages” defined in OTF space; auto-calibration wizard to learn the action mapping.
- Assumptions/dependencies: ecosystem standards for OTF serialization; IP/licensing; governance for safe adaptation.
- Observation-only pretraining for autonomous driving behaviors (Automotive)
- Learn action-like latents from dashcam fleets without synchronized control logs; later map to vehicle-specific controls with limited supervised data.
- Potential products/workflows: fleet-scale OTF pretraining; fine-tune per region/vehicle; use z_act as mid-level plan prior.
- Assumptions/dependencies: multi-sensor fusion with LiDAR/RADAR/IMU; stringent safety/verification; domain shift across weather, regions.
- Healthcare movement analytics and rehab assessment (Healthcare)
- Build patient-specific movement primitive profiles; track recovery, detect compensatory patterns, or early signs of motor decline from ambient video.
- Potential products/workflows: clinician dashboard of primitive distributions over sessions; alerts on anomalous transition effects.
- Assumptions/dependencies: clinical validation and trials; privacy-by-design (on-device processing, de-identification); bias and fairness assessments.
- Urban surveillance and traffic flow analysis robust to camera drift (Public Sector, Smart Cities)
- Model normal scene dynamics at scale and detect anomalies independent of camera/background motion; support traffic analytics without identity tracking.
- Potential products/workflows: citywide OTF models per camera cluster; anomaly heatmaps; incident triage.
- Assumptions/dependencies: governance, auditing, and privacy compliance; compute at the edge; change management for camera upgrades.
- Motion-aware video codecs and generative editing (Media, Compression)
- Use learned, compositional transition primitives as a compact motion side-channel for predictive coding or as editable control “effect tokens” in generators.
- Potential products/workflows: codec plugins leveraging OTF codes; video editors exposing “motion primitive” layers for retiming or motion stylization.
- Assumptions/dependencies: standardization and hardware support; interoperability with existing codecs; IP around learned codebooks.
- AR/VR predictive rendering and foveated streaming (AR/VR, Edge)
- Predict near-future representation states to prefetch/render content, reducing latency and bandwidth sensitivity to pixel-level nuisance factors.
- Potential products/workflows: headset runtime predicting DINO-space deltas conditioned on z_act; bandwidth allocation guided by primitive saliency.
- Assumptions/dependencies: tight, low-latency inference; energy-efficient accelerators; seamless integration with graphics pipelines.
- Multi-agent interaction modeling without explicit segmentation (Robotics, Multi-Agent Systems)
- Extend factor gating to attribute overlapping observed effects to agents/parts for coordination and collision avoidance.
- Potential products/workflows: multi-robot planners that reason over shared OTF primitives; human-robot collaboration modules.
- Assumptions/dependencies: 3D/multi-view extensions; causal attribution under occlusion; stronger temporal credit assignment.
- Game AI from broadcast/Let’s-Play videos (Gaming)
- Learn action-like latents from character-agnostic observed effects; transfer across skins/characters; use small labeled datasets to connect to game controls.
- Potential products/workflows: Unity/Unreal plugins for OTF pretraining; “effect token” controllers for NPCs; analytics for e-sports.
- Assumptions/dependencies: access to large gameplay corpora; synchronization with game state for calibration; anti-cheat and fairness considerations.
- Hardware acceleration and edge deployment of factorized transition models (Semiconductors, Edge AI)
- Design kernels/ASIC blocks for patchwise quantization, code lookup, and gated aggregation to enable real-time OTF pipelines on devices.
- Potential products/workflows: NPU libraries for OTF ops; co-design with camera ISPs for on-sensor motion transforms.
- Assumptions/dependencies: vendor adoption; power/latency constraints; standardized operator sets.
Notes on feasibility and common dependencies
- Data: Unlabeled, domain-matched video is required; small action-labeled sets remain necessary to resolve inverse ambiguity between latent effects and true actions.
- Compute/latency: Patchwise VQ and DINO encoders add overhead; real-time uses may need model distillation, smaller patch sizes, or hardware acceleration.
- Generalization: OTF codebooks transfer across carriers/morphologies in controlled tests, but large domain shifts (e.g., new sensors, viewpoints, lighting) may require re-pretraining or adaptation.
- Safety and compliance: For safety-critical or privacy-sensitive deployments (healthcare, AV, surveillance), rigorous validation, on-device processing, and governance are essential.
- Integration: Best results arise when OTF is a reusable interface paired with domain-tuned action decoders and predictors; end-to-end policy learning pipelines should be adapted accordingly.
Glossary
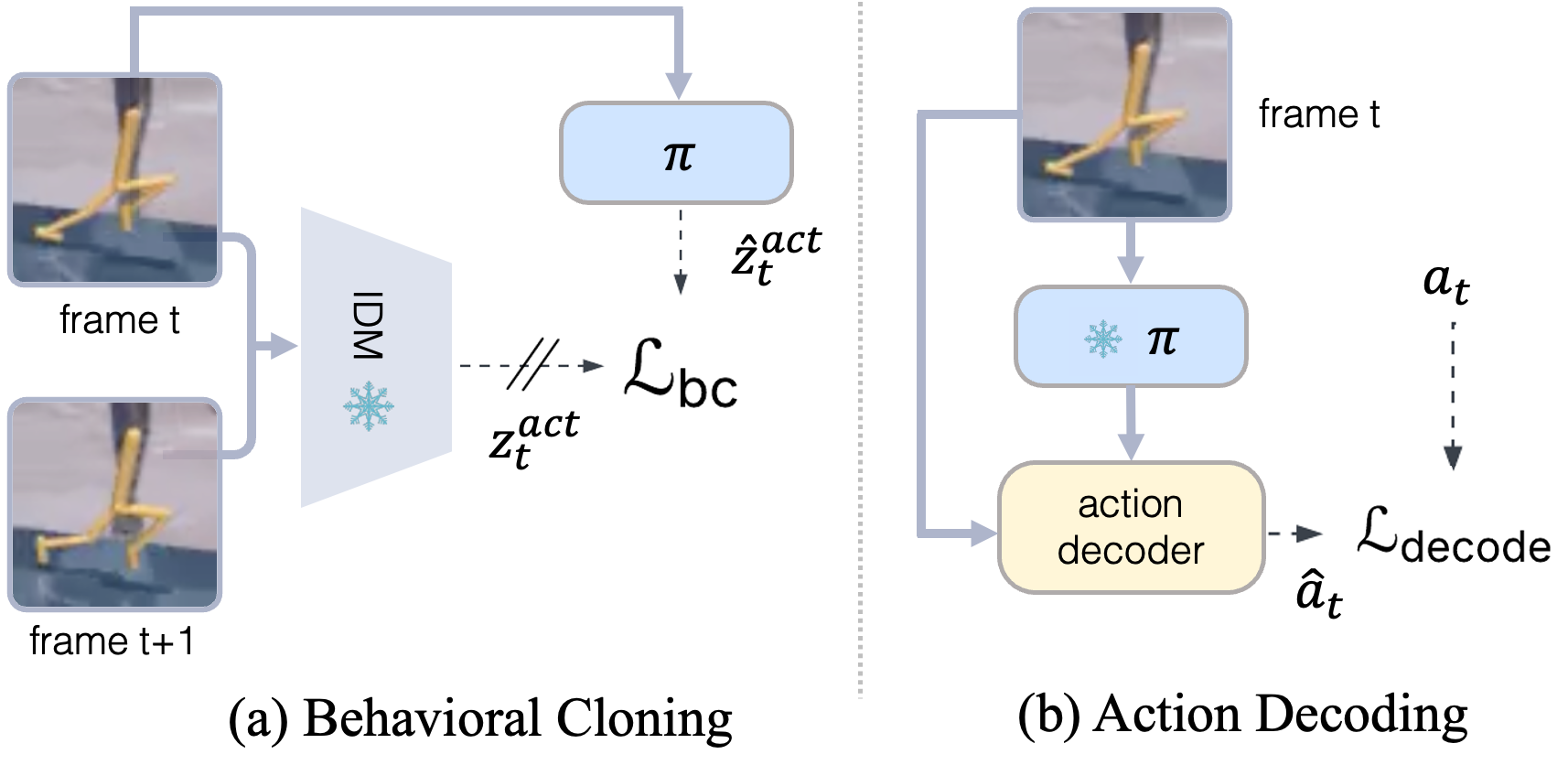
- Action decoder: A learned module that maps latent representations back to concrete environment actions. "An action decoder then maps these primitives to ground-truth actions , utilizing the pixel frame to associate motions with specific objects (right)."
- Behavioral cloning: Supervised policy learning by imitating expert actions from demonstrations. "via behavioral cloning (left)."
- Codebook: A discrete set of learned prototype vectors used to quantize local transition features. "a shared codebook of reusable observed-transition primitives"
- DINOv2: A self-supervised vision transformer used here as a frozen visual encoder/space for prediction. "a decoder-free variant that predicts future states in a frozen DINOv2 representation space."
- Distracting Control Suite (DCS): A benchmark for RL from pixels with challenging visual distractors. "We mainly evaluate our method on the Distracting Control Suite (DCS)~\citep{dcs}, where we focus on cheetah-run and walker-run environment"
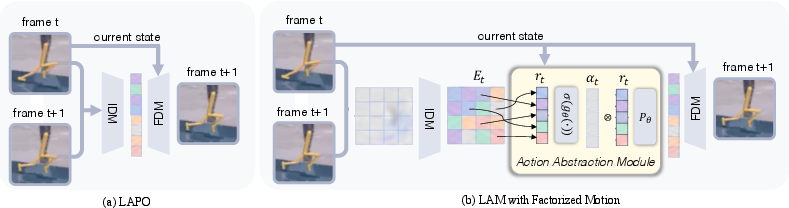
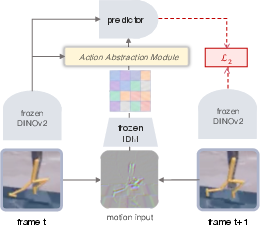
- Forward dynamics model (FDM): A model that predicts the next observation/state given the current state and an action (or latent action). "A standard monolithic latent action model with inverse dynamics model (IDM) and forward dynamics model (FDM)."
- Gate network: A module that scores and selects relevant factors to aggregate into a latent representation. "A gate network then assigns each factor a relevance weight"
- Inverse dynamics model (IDM): A model that infers the action (or latent action) that caused a transition between observations. "A standard monolithic latent action model with inverse dynamics model (IDM) and forward dynamics model (FDM)."
- inverse–forward dynamics framework: A two-part setup combining inverse dynamics for latent action inference and forward dynamics for prediction. "within the standard inverseâforward dynamics framework"
- JEPA: Joint-Embedding Predictive Architecture; a representation learning approach predicting future embeddings without pixel decoders. "We explore a decoder-free JEPA-style variant, OTF-LAM-Dino."
- Latent action: A compact representation inferred from observations that captures action-relevant transition information. "A typical LAM encodes an observation pair into a latent action and uses it to predict from ."
- Latent Action Models (LAMs): Models that learn action-like variables from observation-only transitions without action labels. "Latent Action Models (LAMs) learn action-like proxies from observation transitions."
- Morphology shift: A change in the agent’s body or embodiment across domains that challenges transfer. "less sensitive to the morphology shift,"
- Nearest-neighbor quantization: Assigning continuous features to the closest codebook vector during discretization. "top-1 nearest-neighbor quantization"
- Occupancy map: A spatial mask indicating where a particular code (primitive) is active in the transition. "we derive for each code an occupancy map "
- Observed Transition Factorization (OTF): A method that decomposes each visual transition into a sparse set of reusable observed-transition primitives. "We introduce Observed Transition Factorization (OTF), which decomposes each transition into a sparse set of observed-transition primitives."
- OTF-LAM: A latent action model that aggregates OTF primitives into state-aware action-like latents for prediction. "we propose OTF-LAM, which abstracts motion primitives into action-like latents"
- OTF-LAM-Dino: A decoder-free variant predicting future states in a frozen DINOv2 space using OTF primitives. "OTF-LAM-Dino uses frozen DINOv2 as an encoder and frozen OTF module as a motion primitive extractor."
- Optical flow: A pixel-level motion field between frames; used here as a constraint in a baseline method. "LAOF~\citep{laof} uses optical-flow constraints,"
- Orthogonality regularizer: A loss encouraging code vectors to be decorrelated or orthogonal to reduce redundancy. "and an orthogonality regularizer:"
- Patchwise vector quantization: Discretizing features on a per-patch basis to capture localized transition effects. "Patchwise vector quantization."
- Proprioceptive signals: Sensor measurements of an agent’s internal state (e.g., joint angles/velocities) not available in video-only settings. "do not provide frame-level action labels or proprioceptive signals,"
- Residual prediction: Predicting the change relative to the current frame instead of predicting the next frame directly. "we use residual prediction by default."
- Sobel transform: An edge-detection filter used to derive motion-centric inputs less tied to raw appearance. "grayscale frames with a Sobel transform"
- Vector quantization: Mapping continuous features to discrete code vectors to structure representations. "using vector quantization as the final latent action bottleneck can be too restrictive for complex in-the-wild videos."
- VQ-VAE: Vector-Quantized Variational Autoencoder; learns a discrete codebook and reconstructs inputs via quantized latents. "We instantiate the observed-transition factorizer as a VQ-VAE trained to reconstruct the motion observation rather than the future RGB frame."
- World models: Models that predict environment dynamics for planning and control. "World models~\cite{wm} for planning and control have been evaluated in settings where the actor and the action space are known,"
- Zero-shot transfer: Applying a learned component to new domains without additional training. "transfer zero-shot across controlled carrier and morphology shifts"
Collections
Sign up for free to add this paper to one or more collections.

