- The paper introduces PoLAR, which factorizes latent actions into radial extent and directional mode to enhance robot policy generalization.
- It employs radial ordering and hyperbolic geometry to align transition extents with temporal offsets, improving action informativeness and robustness.
- Experimental results demonstrate PoLAR's superior performance in simulated and real-world robot manipulation tasks relative to baseline methods.
PoLAR: Factorizing Extent and Mode in Latent Actions for Robot Policy Learning
Motivation and Background
Latent action pretraining aims to extract compact codes representing transitions between states, supporting both policy learning and world modeling in robotics. Traditional methods encode transitions as unstructured latent vectors, entangling transition extent (how much changes) and transition mode (what changes). This entanglement impairs policy generalization, particularly across varying horizons, since similar transition modes executed at different extents are not explicitly related within the latent space.
PoLAR (Polar Latent Actions with Radial structure) proposes a geometric factorization: utilizing radius in latent space to encode transition extent and direction to encode mode. By leveraging temporal offset between observation pairs as a weak proxy for transition extent, PoLAR imposes a radial ordering such that larger temporal gaps correspond to latent actions with larger radii. This separation facilitates more robust and interpretable policy learning. The model further instantiates this structure within a hyperbolic geometry, exploiting the exponential angular capacity at larger radii to support a greater diversity of transition modes.
Methodology
Radially Structured Latent Actions
PoLAR follows the canonical latent action pipeline: an inverse dynamics model (IDM) encodes visual changes from pairs of observations, subsequently quantized for discrete latents if needed. The forward dynamics model (FDM) reconstructs future states from the current observation and latent action. PoLAR augments this pipeline with two critical innovations:
- Radial losses: Imposed as Lord (ordering transitions by anchor-relative distance) and Lrad (ensuring radius increases proportionally with temporal offset), these losses work in tandem: Lord anchors transition extent locally, while Lrad orders extents globally.
- Hyperbolic geometry: Latent actions are lifted from the tangent space to the Poincaré ball. The radius and direction are computed hyperbolically, providing increased angular capacity for encoding diverse transition modes at larger extents.
For discrete latent actions, PoLAR uses a factorized codebook with R radii and D direction codes. Each latent action is quantized into one shared radial index and C direction indices per latent slot, enforcing a sharp factorization between extent and mode.
Experimental Evaluation
Task Suite and Simulation
PoLAR is evaluated across simulated and real-world tabletop manipulation tasks including RoboMimic, MimicGen, SimplerEnv-WidowX, and real robot executions.
Figure 1: Evaluation tasks for PoLAR, spanning multiple simulated and real-world manipulation domains.
PoLAR consistently outperforms flat and Euclidean baselines in simulated policy learning. For continuous latent action-conditioned diffusion policies, PoLAR boosts success rates over both radial-agnostic and purely Euclidean models.
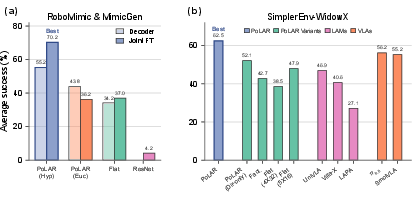
Figure 2: PoLAR delivers superior performance in simulation, with marked gains versus both baselines and pretrained VLAs.
Real-World Robot Manipulation
Real robot experiments show PoLAR with VLA achieves the highest success across all evaluated tasks. Gains are not limited to early-stage subtasks but persist across compound manipulations, evidencing practical robustness.
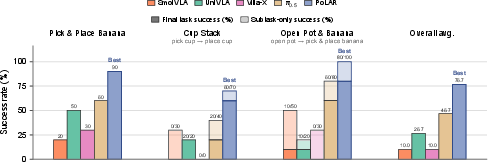
Figure 3: PoLAR with VLA achieves highest real-world success rates across multiple manipulation tasks.
Role of Radial Structure
Temporal offset strongly correlates with physical state change; PoLAR converts this weak supervision into a radial latent structure. As temporal offset increases, PoLAR radii exhibit ongoing progression, contrasting with flat baselines that capture little radial variation.
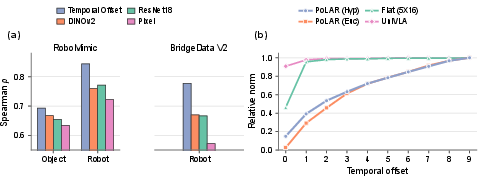
Figure 4: Temporal offset reliably proxies for transition extent, and PoLAR radii increase accordingly; flat baselines lack such radial organization.
Qualitative Decoder Analysis
Fixing direction tokens and sweeping radius produces progressively larger visual transitions, confirming that PoLAR's radial token explicitly modulates transition extent.

Figure 5: Radius token controls transition extent; increasing radial token yields larger decoded transitions with fixed mode.
Policy Learning Advantages
- Action informativeness: PoLAR latent actions contain the most mutual information and explain highest action variance relative to ground-truth actions, outperforming both factorized and unstructured baselines.
- Error robustness: When token prediction errors occur, PoLAR's factorization ensures mispredicted tokens remain proximate in latent space, translating to smaller decoded action errors.
- Multi-horizon efficiency: PoLAR benefits markedly from multi-horizon latent policy training, with cross-horizon action targets inducing less conflicting gradients due to shared directional structure and variable radius.
Geometry Choice: Hyperbolic vs Euclidean
Both hyperbolic and Euclidean variants of PoLAR learn radii reflecting temporal offset, but hyperbolic geometry provides exponentially increasing angular capacity at larger radii. This supports greater diversity among transition modes without sacrificing action-predictive information. Hyperbolic PoLAR demonstrates higher action informativeness and yields better downstream policy performance.
Failure Modes and Robustness
Representative rollouts highlight PoLAR's successes in complex, real-world manipulations. Failure analyses reveal PoLAR errors tend to cluster in grasp failures or incomplete sequential actions. Baseline method failures are broader, including incorrect object selection and more frequent task incompletions.

Figure 6: Representative successful real-world rollouts for PoLAR.

Figure 7: Observed PoLAR failures typically involve grasping or incomplete sequential actions.

Figure 8: Baseline failures span broader error modes, including incorrect object selection and failure in sequential manipulation tasks.
Additional radius-sweep visualizations further reinforce the decoupling of extent and mode, with radial manipulation yielding controlled, larger transitions.

Figure 9: Additional radius sweep examples showing larger visual transitions for increasing radii, mode preserved.
Implications and Future Directions
The explicit factorization of transition extent and mode within latent actions, instantiated via hyperbolic geometry, addresses a principal shortcoming in prior latent action models. Practically, this facilitates policy transfer across varying horizons and tasks, yielding more robust downstream policies in both simulation and reality. Theoretically, PoLAR demonstrates that geometric inductive biases in latent spaces improve action informativeness, robustness, and policy generalization.
Future work should extend PoLAR to multi-view and wrist-camera scenarios, as well as integrate stronger temporal supervision for cyclic or non-progressive behaviors. The separation of mode and extent offers promising avenues for compositional latent action design (cf. (2604.03340)), algebraic consistency (Tang et al., 11 May 2026), and rotational representation (Li et al., 13 May 2026). As geometric latent action modeling matures, integrating PoLAR structure with large-scale VLAs, world models, and embodied RL settings could structurally enhance robot skill acquisition and cross-embodiment transferability.
Conclusion
PoLAR introduces and validates a geometric latent action factorization for robot policy learning, separating transition extent and mode via radial-direction encoding and temporal supervision. Empirical results in both simulation and real robotic platforms underline PoLAR's superiority in success rates, action informativeness, and robustness. This work demonstrates that latent action space geometry is a salient lever for improving downstream control, with implications for broader adoption in embodied AI and vision-language-action modeling (2606.21139).