- The paper introduces a fixed-point dynamics framework that employs iterative self-refinement to converge on correct solutions in discrete flow language models.
- It demonstrates high accuracy and efficiency, achieving near-perfect performance on tasks like Sudoku through stability-based self-verification.
- The FlowDPO method optimizes preference training by reshaping solution basins to favor correct outputs, bridging the gap between generation and verification.
Flow Reasoning Models: Iterative Self-Refinement and Stability-Based Verification in Discrete Flow Language Modeling
Overview and Motivation
"Flow Reasoning Models: Scaling Reasoning Through Iterative Self-Refinement" (2606.29150) introduces a highly technical approach to deploying discrete flow LLMs (FLMs) for structured reasoning tasks, specifically constraint satisfaction problems (e.g., Sudoku, Zebra puzzles). The paper dissects why naïvely trained FLMs—despite geometric modeling advantages—underperform in solving such tasks and proposes a training and test-time scaling paradigm that leverages the dynamic stability of correct solutions. The formal motivation is rooted in the observation that correct solutions correspond to dynamically stable fixed points under the model's denoising flow, while incorrect states exhibit instability and drift under re-noising. The authors formalize this into an architecture and inference protocol that exploits fixed-point stability for both generation and verification, and then further augments training by directly optimizing preference over these basins via FlowDPO.
Fixed-Point Dynamics and Self-Conditioned Iterative Generation
The core technical innovation is reframing discrete flow language modeling as reasoning through fixed-point dynamics. Generation becomes an iterative denoising process with self-conditioning, feeding each step the model's own previous logits, which contracts the state directly onto stable fixed points. In structured tasks, correct completions behave as attractors for the flow, while erroneous completions are fragile and unstable.
Self-conditioning is instantiated via an additional channel initialized to zero, which carries previous logits throughout each Euler step. At inference, the model iteratively refines a candidate solution until convergence is detected, substantially improving the efficiency and reliability of a single generation attempt.
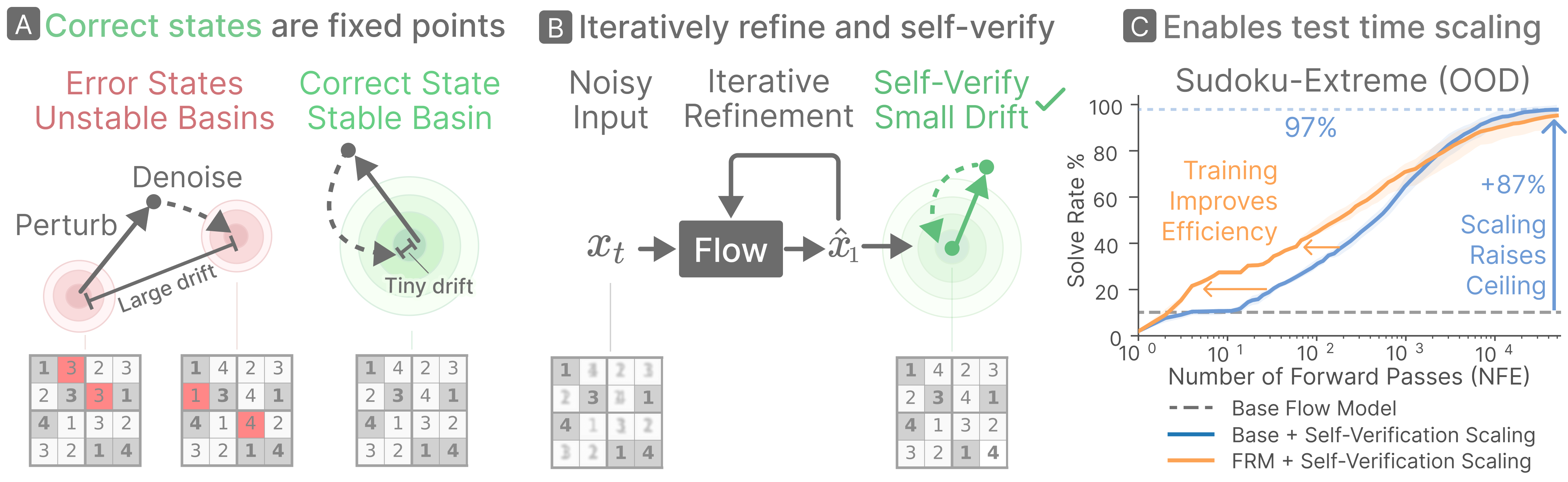
Figure 1: Stable fixed points and basins for correct versus incorrect solutions in discrete flow models, visualizing dynamical response to perturbation and iterative refinement with self-conditioning.
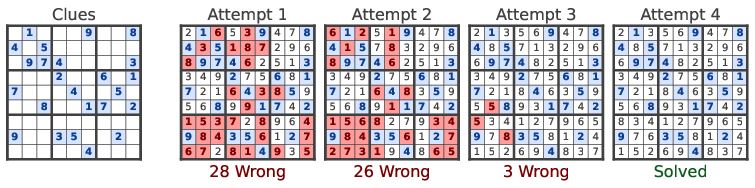
Figure 2: One Sudoku attempt is iteratively refined through self-conditioning, sharply reducing the wrong cells without restart or external verification.
Stability-Based Self-Verification and Test-Time Scaling
Beyond mere iterative generation, the model's fixed-point geometry provides an internal correctness signal: re-noising and resolving a candidate yields minimal drift for correct solutions but large discrepancy for erroneous ones. This divergence is quantifiable via renoise cross-entropy (renoise-CE), which serves as a label-free verifier. The model thus becomes its own verifier, enabling a test-time scaling regime where multiple candidates are proposed and only dynamically stable ones are selected.
This paradigm saturates structured reasoning tasks: for Sudoku, verification-based selection achieves 100% solve rate, efficiently generalizing even to unseen out-of-distribution puzzles (Sudoku-Extreme achieves 96.1%), independent of direct training on those distributions.
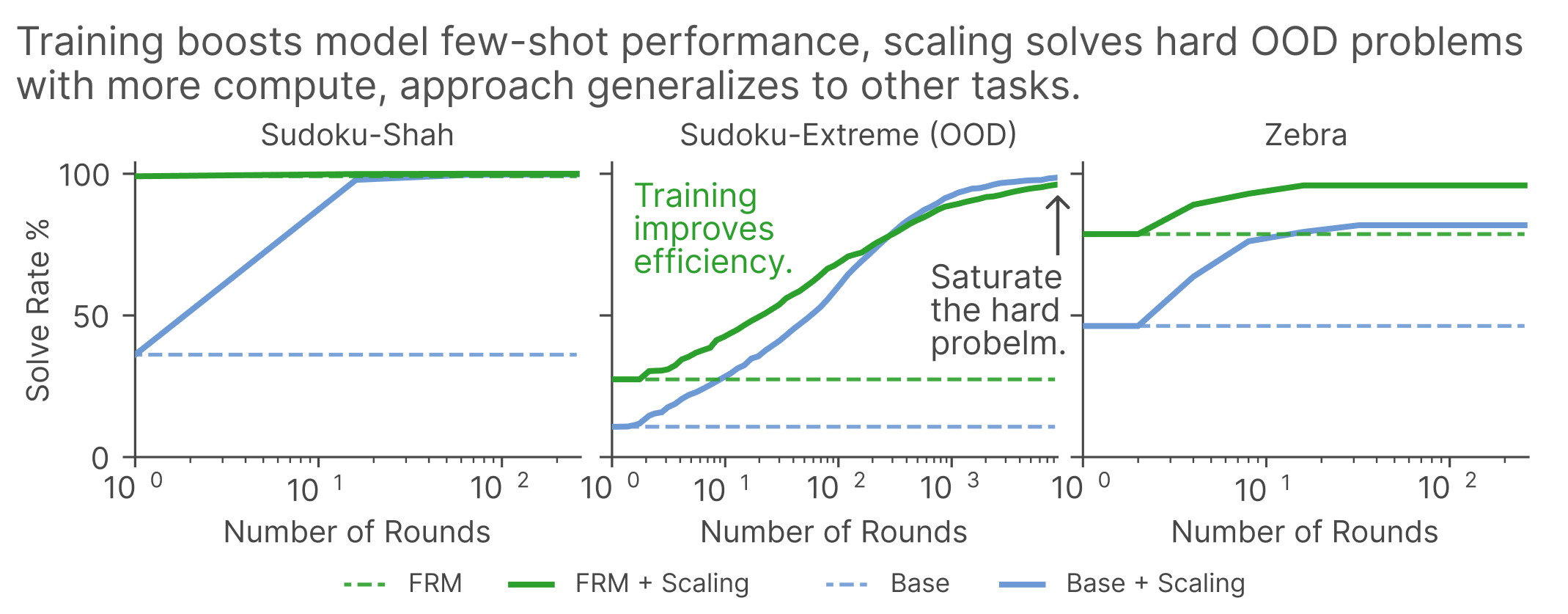
Figure 3: Test-time scaling with self-verification lifts solve rates across tasks, including hard out-of-distribution data—showing efficiency gains with the FRM architecture and verifier.
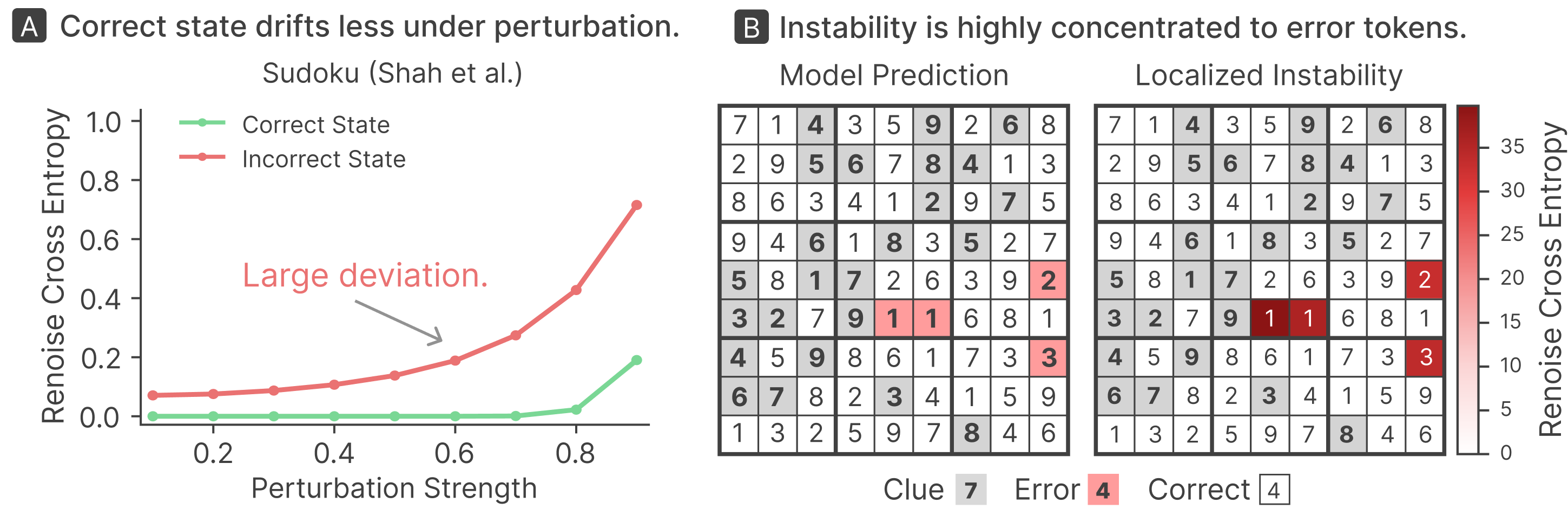
Figure 4: Re-noising probes reveal per-cell stability, sharply separating correct from incorrect areas in candidate grids.
Preference Optimization: FlowDPO and Basin Reshaping
Generation and verification are decoupled: models recognize stability with high accuracy but fail to generate correct solutions with comparable frequency (generation–verification gap). FlowDPO, the direct preference optimization over self-mined confident mistakes, is introduced to reshape the fixed-point landscape. By explicitly training the model to deepen the basin around correct solutions and suppress specific incorrect completions, FlowDPO substantially elevates single-shot solve rates (e.g., Sudoku pass@1 from 35.8% to 80.6% with EMA anchoring).
The preference loss is localized to decisive cells where incorrect completions deviate from gold. By mining the model's own high-confidence mistakes and updating specifically on those loci, FlowDPO avoids the dilution of gradient typical of whole-sequence contrast and outperforms both maximum likelihood and random preference pairing.
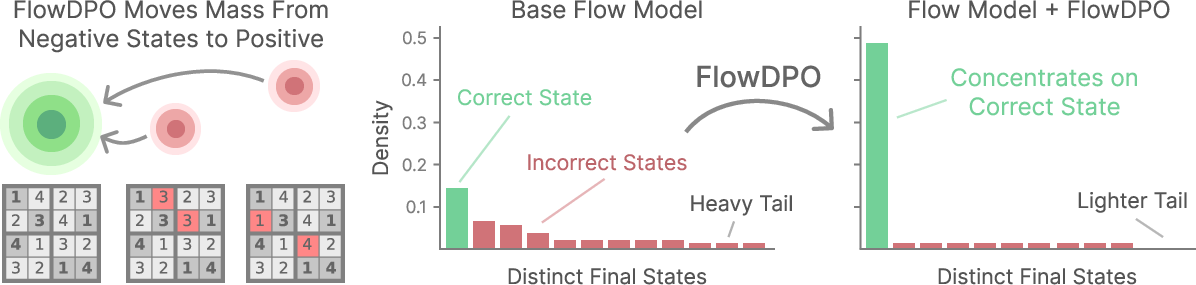
Figure 5: FlowDPO concentrates probability mass onto the correct solution, collapsing competing basins and numerically increasing the gold grid's share from 26% to 68%.
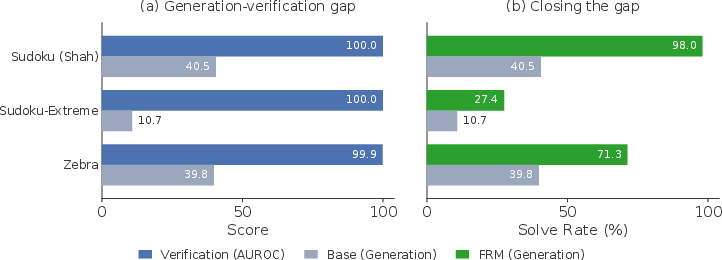
Figure 6: Rennoise-CE delivers near-perfect recognition of correct states (AUROC ≈ 1.0), while generation remains sparse—training with FlowDPO and self-conditioning closes the gap and boosts solve rates.

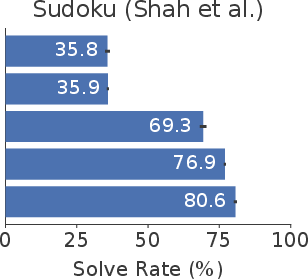
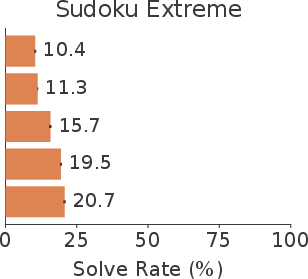
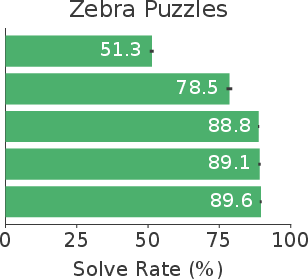
Figure 7: Ablation study: Single-shot solve rates climb additively as FlowDPO is progressively augmented with random pairs, wrong-cell support, mined hard negatives, and EMA anchoring.
Computational Efficiency and Scaling Implications
FRMs are computationally efficient: combined self-conditioning and stability-based verification reach 99.2% Sudoku accuracy in just 7 forward passes, an 8× reduction compared to the best masked-diffusion baselines, which require 57 forward passes for comparable accuracy. FlowDPO further shifts coverage curves upward and reduces necessary compute for target solve rates.
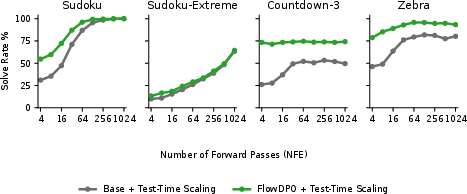
Figure 8: Compute budget required for solve rate: FlowDPO consistently improves efficiency, achieving high accuracy at lower NFE (number of forward passes).
Practical and Theoretical Implications
Practically, FRMs demonstrate robust, verifier-free solve rates for constraint satisfaction tasks, achieving generalization to unseen distributions without explicit retraining. The stability-verification protocol is label-free, offering test-time scaling and adaptive halting. Theoretically, the fixed-point perspective aligns with attractor models, equilibrium networks, and recurrent-depth architectures, offering a clean geometric interpretation of reasoning in discrete flow LMs. FlowDPO's cell-localized preference optimization suggests directions for future token-level and stepwise preference learning.
Critically, FRM's reliance on checkable, stable states means broader application to open-ended generation remains unproven, and scaling to larger domains is a nontrivial challenge. Nonetheless, the approach stands out for integrating proposal, verification, and preference training in a unified fixed-point geometry, differentiating itself from traditional vote-based or auxiliary-verifier solutions.
Future Research Directions
Key avenues include:
- Optimization stability for combined self-conditioning and FlowDPO, given observed seed variance.
- Extending fixed-point-based reasoning and verification beyond grid-structured constraint satisfaction toward larger-scale and more varied reasoning domains.
- Refining preference objectives, potentially introducing surrogate losses or further localizing preferences, and benchmarking against other diffusion-preference optimization schemes.
Conclusion
"Flow Reasoning Models" (2606.29150) establishes a principled framework for scaling structured reasoning in discrete flow LLMs via iterative self-refinement and stability-based verification. By leveraging the internal basin geometry and augmenting training through preference optimization (FlowDPO), FRMs achieve high accuracy, efficient compute usage, and robust generalization within checkable-task domains. The methodology provides a technical blueprint for non-autoregressive structured reasoning and advances the geometric understanding of dynamic stability in generative modeling.

