Latent Reasoning with Normalizing Flows
Abstract: LLMs often improve reasoning by generating explicit chain-of-thought (CoT), demonstrating the importance of intermediate computation. However, textual CoT forces this computation through a discrete, serial, and communication-oriented token stream: each reasoning step must be verbalized before the model can proceed, even when the underlying update is semantic, uncertain, or only partially formed. Latent reasoning offers a higher-bandwidth alternative by performing intermediate computation in compact continuous states before committing to text. Yet existing latent-reasoning methods often sacrifice key advantages that make CoT effective in autoregressive LLMs, including native left-to-right generation, probabilistic sampling, compatibility with KV-cache decoding, and tractable likelihood estimation. We propose NF-CoT, a latent reasoning framework that preserves these advantages by modeling continuous thoughts with normalizing flows. NF-CoT instantiates a TARFlow-style normalizing flow inside the LLM backbone, defining a tractable probability model over compact continuous thoughts distilled from explicit CoT. Continuous-thought positions are generated by an NF head, while text positions are generated by the standard LM head within the same causal stream. This design provides exact likelihoods for latent thoughts, enables probabilistic left-to-right decoding with the original KV cache, and supports direct policy-gradient optimization in the latent reasoning space. On code-generation benchmarks, NF-CoT improves pass rates over explicit-CoT and prior latent-reasoning baselines while substantially reducing intermediate-reasoning cost.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Latent Reasoning with Normalizing Flows” (for a 14-year-old)
Overview: What is this paper about?
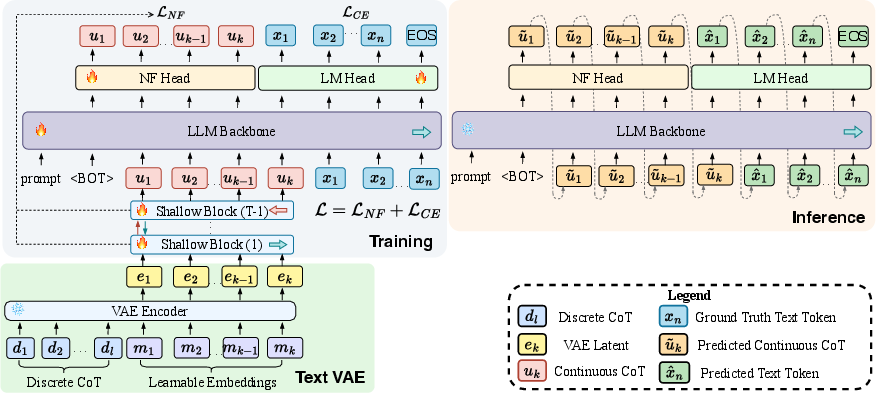
This paper is about teaching AI LLMs to “think” more efficiently. Usually, when these models solve a problem (like writing code), they do better if they show their steps in words—this is called chain-of-thought (CoT). But writing out every step as text is slow and long. The authors propose a new way for the model to think privately in short, continuous “thought tokens” (tiny vectors of numbers) before writing the final answer. Their method, called NF‑CoT (short for Normalizing-Flow Chain of Thought), keeps the good parts of traditional CoT (like step-by-step generation and sampling different reasoning paths) while making it faster and more compact.
What questions are they asking?
In simple terms, the paper asks:
- Can we let AI models do their “scratch work” in a fast, compact, non-text form without losing the benefits of step-by-step reasoning?
- Can we sample and score these hidden thoughts just like we do with words, so the model can pick better reasoning paths?
- Will this make problem-solving (especially code writing) both more accurate and more efficient?
- Can we further improve these hidden thoughts using trial-and-error learning (reinforcement learning) with real feedback (like passing unit tests)?
How did they study it? (Methods explained simply)
Think of three ways to show your work:
- Writing every step in sentences (explicit CoT): clear but long and slow.
- Whispering to yourself without any trace (hidden states): fast but impossible to inspect or score.
- Their idea: short “thought tokens” you can measure, sample, and reuse.
Here’s how NF‑CoT works, using everyday analogies:
- Continuous thoughts as sliders instead of sentences: Instead of writing “I’ll try a loop here,” the model adjusts a set of numerical “sliders” (continuous thought tokens) that represent its reasoning.
- Normalizing flows as a reversible recipe: A normalizing flow is like a reversible cooking process that turns plain ingredients (random noise) into a dish (a thought vector) and back. Because it’s reversible, you can compute exactly how likely a thought is and sample new ones easily.
- Left-to-right thinking like writing line by line: The model creates these thought tokens one-by-one in order—just like writing a paragraph—so it can keep using its usual “step-by-step” style.
- Shared backbone (one brain, two mouths): The same model “brain” handles both thought tokens and text. It has two “heads”: one predicts the next continuous thought; the other predicts the next text token (like words in the final answer). This means it can think and then write in one pass, reusing its memory so it doesn’t redo work.
- Training in two stages (practice then full sprint): First, they teach a small part to map from existing step-by-step text explanations into compact thought tokens (like learning good shorthand). Then they train the whole system end-to-end to make sure the private thoughts help produce better final answers.
- Inference (solving a new problem): The model first samples a short sequence of thought tokens, then uses them to write the final answer—all in one smooth, left-to-right process.
- Reinforcement learning (trial-and-error with rewards): For coding, they run the model’s code against tests. If it passes, that’s a reward. The model updates not only how it writes answers, but also how it chooses its hidden thought tokens, so it learns better reasoning paths over time.
What did they find, and why does it matter?
Here are the main results, with why they’re important:
- Better accuracy on coding tasks:
- explicit CoT (writing out every step in text),
- other “hidden thought” methods, and
- diffusion-based latent methods (which need many slow “denoising” steps).
- This means compact thinking can be both smarter and cleaner.
- Much more efficient reasoning:
- around 2× faster overall at test time,
- used about half the compute per sample,
- and trained several times faster.
- Faster and cheaper is great for real-world use.
- Keeps step-by-step benefits: Because NF‑CoT can score and sample thoughts left-to-right, it preserves the best parts of normal language modeling—sampling different reasoning routes and measuring how likely each one is.
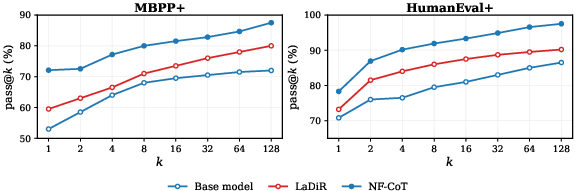
- Scales well with more samples (pass@k): When they generated multiple solutions for the same problem, the success rate kept rising steadily, showing NF‑CoT explores diverse, useful reasoning paths instead of getting stuck on one idea.
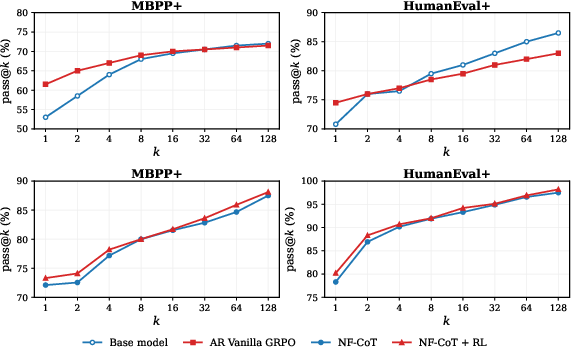
- Reinforcement learning adds gains without collapsing diversity: After training with execution rewards (unit tests), accuracy improved further—and, unlike some methods, it didn’t become narrow or repetitive. The model still explored varied solutions as it sampled more attempts.
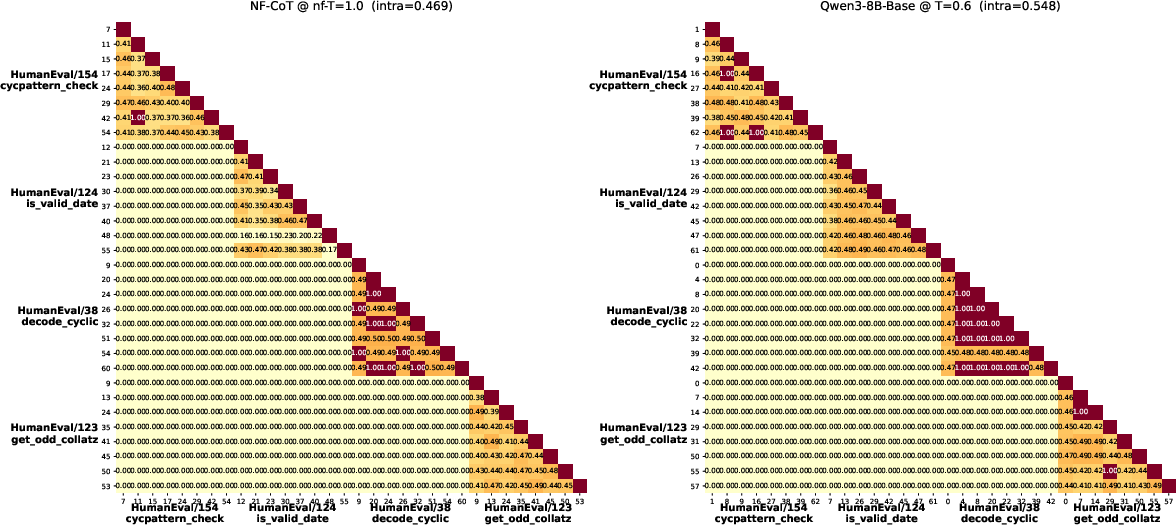
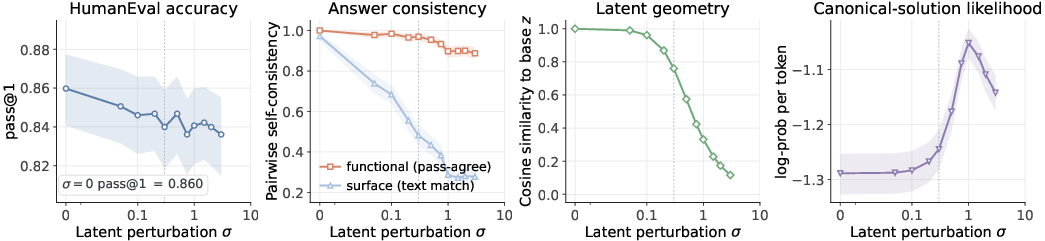
- Smooth and meaningful thought space: Small nudges to the thought tokens tended to change the style of the solution (how the code is written) more than its correctness. That suggests the hidden thoughts are stable and well-organized.
So what? Why this could matter
- Faster, cheaper reasoning: By thinking in short, continuous tokens instead of long text, models can solve complex tasks more quickly and with less compute—helpful for coding assistants, tutoring systems, or math solvers.
- Better training tools: Because NF‑CoT provides exact probabilities for thoughts, it supports both standard training and reinforcement learning directly in the “thinking space.” That opens up new ways to teach models to reason better using feedback.
- A practical middle ground: You keep the flexibility of step-by-step generation and sampling (like with text CoT), but in a compact, efficient, and measurable form.
- Limitations to keep in mind: These results focus on code. The hidden thoughts aren’t human-readable, so they’re great for performance but not for explaining the model’s reasoning to people. Also, the strongest feedback (unit tests) is specific to programming; extending this to other domains will need different kinds of rewards.
In short, NF‑CoT shows that models can “think privately” in a compact, continuous way—still step-by-step, still sample-able and scorable—and end up both more accurate and more efficient.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a single consolidated list of concrete gaps and open questions that remain unresolved and could guide future research:
- Coverage beyond code generation: Validate NF-CoT on math word problems, multi-step commonsense reasoning, scientific QA, and multimodal tasks to test domain generality and robustness.
- Multilingual and multi-language code: Assess performance on non-English prompts and other programming languages (e.g., Java, C++, Rust) to quantify transferability.
- Dependence on explicit CoT and frozen VAE: Evaluate end-to-end training without CoT traces, alternative encoders (contrastive, predictive, masked modeling), and joint training of the encoder with the flow and LLM to reduce supervision dependency and potential encoder–flow mismatch.
- Posterior mean vs stochastic targets: The method trains on the VAE posterior mean; test whether sampling from the posterior (and propagating uncertainty) or using ensembles improves latent modeling and downstream accuracy.
- Distribution shift in u-space: Measure and mitigate the gap between training (u derived from e via F with teacher forcing) and inference (u sampled autoregressively); explore scheduled sampling, latent noise curriculum, or consistency regularizers in latent space.
- Fixed latent budget K: Develop adaptive or learned halting mechanisms for continuous thoughts so the model uses more latent steps only when needed; study performance/latency trade-offs under variable K.
- Interleaving strategy: Compare “latent prefix then answer” vs interleaving multiple cycles of latent and text tokens; measure effects on reasoning quality, compute, and KV-cache reuse.
- Expressivity of the conditional density: The per-step diagonal Gaussian is unimodal; benchmark mixtures, normalizing-flow heads, or energy-based heads at each step to capture multimodal latent trajectories.
- Capacity of the shallow flow F: Quantify how many shallow blocks are necessary/sufficient; test deeper or alternative invertible transformations, and analyze the impact on likelihood, stability, and performance.
- Sensitivity to hyperparameters: Systematically vary K (slots), D (dimension), noise magnitude added to e, and loss weights (λflow, λtext) to map stability and accuracy regimes.
- Calibration and selection: Quantify correlation between latent likelihood and correctness (and with token likelihood); evaluate whether latent likelihood can replace or augment self-consistency ranking and voting strategies.
- RL at scale: Study stability and variance of latent-space policy gradients with longer training, larger datasets, and different advantage baselines; compare against actor–critic, PPO/DPPO, and off-policy corrections in latent space.
- Credit assignment in latent trajectories: Explore step-wise or segment-level rewards in u-space (e.g., via intermediate unit tests or heuristic signals) to improve sample efficiency and reduce RL variance.
- Verifier-free domains: Develop alternative reward signals (human preference models, weak verifiers, hindsight relabeling) for tasks without executable tests; measure quality/diversity trade-offs.
- Diversity controls: Disentangle temperature/top-p in latent vs token sampling; measure entropy of u, mutual information I(u;x), and de-duplication rates to better control and understand pass@k scaling.
- Robustness to noisy/incorrect CoT supervision: Stress-test training with mislabeled or low-quality textual rationales feeding the VAE; evaluate robustness tactics (noise-aware training, robust losses, data filtering).
- Safety and reliability: Audit generated code for security vulnerabilities, license violations, and unsafe patterns; extend to domains where errors are costly and evaluate guardrails for latent-space RL.
- Interpretability and faithfulness: Move beyond qualitative decoded CoTs to quantitative probes that test whether decoded rationales causally reflect internal latent trajectories (e.g., counterfactual editing, causal mediation tests).
- Effect on general LLM capability: Evaluate whether inserting NF heads degrades instruction following, factuality, or language modeling (e.g., MMLU, HELM); investigate catastrophic forgetting and mitigation strategies.
- Compute and memory profiling vs explicit CoT: Provide apples-to-apples comparisons against explicit-CoT self-consistency under equal wall-clock/token budgets, including memory/KV-cache overheads and batching effects.
- Portability across backbones and scales: Test NF-CoT with different base models (sizes, architectures, instruction-tuned vs base) to characterize scaling laws and backbone-specific interactions.
- Failure mode analysis: Characterize where NF-CoT underperforms (e.g., long-horizon dependencies, tricky algorithmic problems) and whether failures stem from latent modeling, decoder conditioning, or training dynamics.
- Theoretical underpinnings: Provide analysis of why AR flows maintain pass@k diversity (e.g., bounds linking per-step Gaussian entropy to trajectory diversity) and when unimodal steps suffice to model multimodal reasoning paths.
- KV-cache and streaming edge cases: Evaluate behavior in streaming/online settings, retrieval-augmented generation, and tool use, where cache reuse and interleaving may introduce latency or context-window constraints.
- Curriculum and initialization: Investigate alternatives to the frozen-backbone warm-up (e.g., better initialization, auxiliary alignment losses) to reduce training complexity without hurting stability.
- Data contamination and leakage: Audit benchmarks and pretraining/fine-tuning corpora to ensure fair evaluation, especially for code tasks with public repositories and frequent duplication.
These gaps indicate concrete directions—new benchmarks, architectural variants, training objectives, and diagnostics—that can test the robustness, generality, and practical deployment readiness of latent reasoning with normalizing flows.
Practical Applications
Immediate Applications
Below are specific, deployable use cases that leverage the paper’s findings on latent chain-of-thought (CoT) with autoregressive normalizing flows (NF-CoT), focusing on efficiency, sampling, and exact-likelihood training.
- Improved code assistants with lower latency and cost
- Sector: software
- What: Replace explicit CoT with continuous thoughts in coding copilots to cut intermediate tokens (≈6× compression reported) while improving pass@1 and pass@k. Reuse KV cache across latent and answer decoding in a single causal pass.
- Tools/workflows: “NF-CoT Copilot” plugin for IDEs; vLLM-serving integration that interleaves NF head (continuous thoughts) and LM head (tokens).
- Assumptions/dependencies: Availability of a VAE encoder distilled from explicit CoT traces; integration into an LLM backbone (e.g., Qwen3-8B-like); engineering support for NF head and shallow flow blocks.
- Execution-guided reinforcement learning (RL) for code generation
- Sector: software, MLOps
- What: Apply group-based RL (e.g., GRPO) using unit-test feedback directly to the latent policy (exact latent likelihood enables standard policy gradients). Empirically preserves pass@k diversity compared to token-space RL.
- Tools/workflows: “Latent-RL training loop” that samples (u, x), runs tests, computes group-normalized advantages, and updates both NF and LM heads.
- Assumptions/dependencies: Verifiable rewards (unit tests); frozen shallow blocks during RL as in the paper; compute budget for RL sampling.
- Budgeted, multi-sample candidate generation for retrieval and ranking
- Sector: software, platform infra
- What: Use pass@k scaling by sampling continuous thoughts to generate diverse, high-quality candidates for code synthesis, then rank by tests or heuristics.
- Tools/workflows: “Diversity manager” that controls K (latent slots) and sampling temperature; per-candidate latent likelihood for calibration and filtering.
- Assumptions/dependencies: Sampling budget; test or proxy scorers to rank outputs; careful sampling hyperparameters to balance quality/diversity.
- Training-time acceleration versus diffusion-based latent reasoning
- Sector: platform infra, energy/cost optimization
- What: Replace diffusion-style iterative denoising with left-to-right NF sampling to increase sample/token throughput (reported 2–6×) and reduce FLOPs.
- Tools/workflows: Migration playbook from diffusion-latent pipelines (e.g., LaDiR) to NF-CoT; throughput dashboards tracking FLOPs/sample.
- Assumptions/dependencies: Flow architecture and curriculum (Stage 1 frozen backbone + Stage 2 joint training); ops familiarity with flow likelihoods.
- Latent-space A/B testing and online optimization
- Sector: product analytics, MLOps
- What: Log latent likelihoods alongside outputs; use perturbation of u to explore solution modes without collapsing correctness; run small online experiments.
- Tools/workflows: “Latent experiment harness” to perturb u (Gaussian noise) and compare pass rates, structural diversity, and acceptance.
- Assumptions/dependencies: Safety guardrails for code execution; monitoring for correctness drift; storage and privacy policies for latent traces.
- KV-cache-preserving reason-and-answer decoding
- Sector: platform infra
- What: Maintain a single causal stream where continuous thoughts and tokens share the backbone and KV cache, improving throughput and memory.
- Tools/workflows: vLLM/tensorRT-LLM adaptors that support mixed continuous–discrete positions; caching policy tuned for thought-length K.
- Assumptions/dependencies: Backend serving stack must support custom heads and interleaved positions; regression testing for cache correctness.
- Data curation via exact latent likelihood for reasoning trajectories
- Sector: academia, dataset engineering
- What: Score continuous CoT targets by exact likelihood to filter noisy traces and to prioritize high-signal supervision.
- Tools/workflows: “Likelihood-based sampler” to upweight in-distribution latents; curriculum that increases K or noise as modeling improves.
- Assumptions/dependencies: Reliable CoT encoder posterior means; compute for likelihood scoring on large corpora.
- Rapid research prototyping for reasoning analysis
- Sector: academia
- What: Study smoothness and controllability of reasoning by perturbing u; probe how latent diversity maps to solution diversity without major accuracy loss.
- Tools/workflows: Notebooks for latent perturbation experiments; decoded latent CoT as qualitative probes.
- Assumptions/dependencies: Interpreting decoded CoTs only as probes (not faithful explanations), per the paper’s caveat.
- Cost-aware enterprise deployment of reasoning LLMs
- Sector: enterprise IT, finance (ops)
- What: Adopt NF-CoT to improve accuracy and reduce inference-time token budgets relative to explicit CoT, lowering serving costs at scale.
- Tools/workflows: TCO calculators incorporating FLOPs/sample; autoscaling policies keyed to latent budget K.
- Assumptions/dependencies: ROI depends on task mix with heavy reasoning; engineering resources to retrofit existing LLM stacks.
Long-Term Applications
These use cases require further research, broader validation beyond code, new reward designs, or productization work.
- General-purpose latent reasoning assistants beyond code
- Sector: healthcare, legal, finance, education
- What: Apply NF-CoT to math, scientific QA, medical or legal reasoning, and tutoring where explicit CoT is costly. Use latent sampling to generate multiple solution strategies and select via verifiers.
- Tools/products: “Latent Reasoning Tutor” that offers diverse solution paths; domain verifiers (symbolic math solvers, rubric-based graders).
- Assumptions/dependencies: Reliable domain-specific verifiers or reward surrogates (unit-test analogs); mitigation for domain bias inherited from CoT data; rigorous safety review in sensitive domains.
- RL with learned or weak verifiers
- Sector: robotics, operations research, finance
- What: Train latent policies using approximate or learned reward models where ground-truth verifiers are unavailable (planning, scheduling).
- Tools/workflows: Preference or heuristic reward models; hybrid human-in-the-loop feedback aggregated at group level for GRPO-style updates.
- Assumptions/dependencies: Reward misspecification risks; need for off-policy evaluation and safety constraints; sample efficiency research.
- Controllable and steerable reasoning via latent editing
- Sector: developer tools, education
- What: Expose user controls to nudge solution style (e.g., iterative vs. vectorized code) by editing or conditioning u, leveraging the observed smoothness.
- Tools/products: “Latent knob” UI for assistants; templates that set priors over u for different strategies.
- Assumptions/dependencies: Robust, user-understandable semantics of latent controls; safeguards to avoid degrading correctness.
- Adaptive latent budgets and variable-length thought allocation
- Sector: platform infra, model architecture
- What: Learn to allocate K adaptively per problem difficulty, trading latency for quality; dynamic halting of thought generation.
- Tools/workflows: Budget controllers that predict K from prompt states; early-stopping criteria for NF head.
- Assumptions/dependencies: Training signals that reward efficient reasoning; architectural changes to support variable-length flows.
- Safety, auditing, and governance using tractable latent likelihoods
- Sector: policy, governance, compliance
- What: Use exact likelihoods to monitor distributional drift in reasoning trajectories; define audits for “coverage” of reasoning modes.
- Tools/workflows: “Reasoning audit reports” with latent perplexity trends; conformance tests for safety constraints at the latent level.
- Assumptions/dependencies: Calibrated likelihoods across domains; accepted standards for latent-based auditing; privacy treatment of latent traces.
- Multi-agent systems with latent coordination channels
- Sector: autonomous systems, simulation, operations
- What: Agents communicate or coordinate using compact continuous thoughts, improving bandwidth and diversity over explicit textual protocols.
- Tools/workflows: Agent frameworks where u is shared or partially shared; latent-channel negotiation and credit assignment in RL.
- Assumptions/dependencies: Robustness to adversarial or noisy shared latents; interpretability and safety of cross-agent reasoning.
- Tool-augmented latent policies (actions + thoughts)
- Sector: software automation, data engineering
- What: Jointly optimize latent reasoning and tool invocation policies with policy gradients (exact likelihood enables principled updates).
- Tools/workflows: Differentiable tool-calling wrappers that condition LM head on u and tool results; execution feedback as rewards.
- Assumptions/dependencies: Stable training with mixed discrete actions and continuous thoughts; reward design for complex tool chains.
- Privacy-preserving storage of reasoning traces
- Sector: enterprise data governance
- What: Store compact continuous thoughts instead of verbose text CoT for logs/telemetry; optionally decode to text for audits.
- Tools/workflows: “Latent loggers” and selective decoding pipelines; access control to decoded traces.
- Assumptions/dependencies: Risk assessment that continuous latents may still carry sensitive information; policies for retention and decoding.
- Hardware–software co-design for flow-based reasoning
- Sector: semiconductor, inference platforms
- What: Accelerate NF heads and shallow flow blocks with kernels optimized for triangular Jacobians and affine coupling in Transformers.
- Tools/workflows: Runtime libraries supporting interleaved continuous–discrete positions; compiler passes that fuse NF operations.
- Assumptions/dependencies: Sufficient demand to justify kernel development; standardized NF-CoT APIs across backbones.
- Explainability bridges from latents to human-readable rationales
- Sector: education, regulated industries
- What: Train decoders or probes that translate u into faithful, minimal textual rationales, enabling oversight while keeping latent efficiency.
- Tools/workflows: Post-hoc probing models; alignment losses tying decoded rationales to trusted reasoning patterns.
- Assumptions/dependencies: Avoiding spurious plausibility; metrics and protocols to evaluate faithfulness; potential performance–transparency trade-offs.
Cross-cutting assumptions and dependencies
- Domain generalization: Current evidence is from code; extending to math/QA/other domains requires datasets with explicit CoT and/or reliable verifiers.
- Data pipeline: Requires pretraining a CoT encoder (VAE) and a two-stage curriculum (frozen-backbone warm-up, then joint training).
- Serving integration: Inference stacks must support interleaved continuous-thought positions and KV-cache reuse with separate NF/LM heads.
- Safety and governance: Latents are not inherently interpretable; decoded CoTs are qualitative probes and should not be treated as faithful explanations without validation.
- Compute budgets: While more efficient than diffusion-based latent reasoning, NF-CoT still adds heads/flows and training stages; ROI depends on task complexity and scale.
Glossary
- affine flows: A class of flow transformations that apply affine (linear plus bias) mappings, often designed to be invertible and computationally efficient. "Because they are causal affine flows, their Jacobian is triangular and their log-determinant is tractable, contributing to the likelihood in \cref{eq:e-likelihood-through-u}."
- autoregressive normalizing flow: A normalizing flow that generates variables sequentially, conditioning each step on previous ones, aligning with left-to-right (causal) sequence modeling. "We presented \methodname{}, a latent reasoning framework that gives continuous CoT the same modeling status as language tokens by running an autoregressive normalizing flow inside the LLM's causal stream."
- causal Gaussian density: A left-to-right Gaussian modeling approach where each variable’s distribution is conditioned on the prompt and past variables, enabling tractable sampling and likelihood. "we model continuous thought tokens with a causal Gaussian density:"
- causal stream: The unidirectional, left-to-right processing pathway in a Transformer where each position only attends to past positions. "processed in the same causal stream as answer tokens, in the spirit of interleaved continuous-discrete generation~\citep{shen2026starflow2}."
- chain-of-thought (CoT): A prompting strategy where models generate intermediate reasoning steps before the final answer to improve reasoning quality. "LLMs often improve reasoning by generating explicit chain-of-thought (CoT), demonstrating the importance of intermediate computation."
- continuous chain-of-thought (Continuous CoT): Replacing textual rationales with continuous latent codes that play the role of intermediate reasoning variables. "Continuous CoT replaces text rationales with continuous codes of length and dimension , which play the role of the intermediate variable in \cref{eq.cot}."
- cross-entropy: A standard loss function for training classifiers and LLMs that measures the difference between predicted and true distributions. "both runs reach nearly the same total loss and answer cross-entropy."
- diffusion models: Generative models that learn to reverse a noising process via iterative denoising steps to sample from complex distributions. "Others model stochastic continuous latents with diffusion models~\citep{ladir2025,ladirl2026}"
- exact likelihood: The ability to compute the true probability (density) of data under a model without approximation. "giving exact likelihood evaluation and direct sampling."
- execution rewards: Reinforcement learning signals derived from executing generated code (e.g., unit tests) to evaluate correctness. "we further apply GRPO to the supervised \methodname{} (Unified) using execution rewards on a random selected 20K-problem Python mixture for 150 training steps."
- GRPO: A policy-gradient reinforcement learning objective that uses group-normalized advantages to stabilize updates. "In our experiments, we use a GRPO-style objective over groups of sampled trajectories."
- identity initialization: Setting an invertible transformation to initially behave like the identity function to stabilize training. "and are trained from scratch with identity initialization ()."
- interleaved continuous-discrete generation: A generation scheme where continuous latent variables and discrete tokens are produced within the same causal sequence. "processed in the same causal stream as answer tokens, in the spirit of interleaved continuous-discrete generation~\citep{shen2026starflow2}."
- invertible transformation: A bijective mapping that allows moving between latent and data spaces and computing exact likelihoods via the change-of-variables formula. "The two spaces are connected through an invertible transformation "
- Jacobian: The matrix of partial derivatives of a transformation; in flows its determinant adjusts densities under change-of-variables. "their Jacobian is triangular and their log-determinant is tractable"
- Kullback–Leibler (KL) divergence: A measure of how one probability distribution differs from another, commonly used in VAEs as a regularizer. "+ \beta\,\mathrm{KL}!\left(q_\phi(e\mid d)\,|\,\mathcal{N}(0,I)\right)."
- KV-cache decoding: A decoding optimization that caches key/value attention states to avoid recomputation during autoregressive generation. "compatibility with KV-cache decoding, and tractable likelihood estimation."
- latent diffusion: Applying diffusion modeling in a learned latent space rather than directly in token or pixel space. "LaDiR~\citep{ladir2025} (replaces our flow with latent diffusion)."
- latent trajectory distribution: The probability distribution over sequences of latent reasoning states sampled during generation. "does not collapse the latent trajectory distribution."
- likelihood-based formulation: Modeling approach that explicitly defines and optimizes the (log-)likelihood of observed data under the model. "A likelihood-based formulation of continuous CoT that preserves the sampling, scoring, and decoding interface of explicit CoT;"
- log-determinant: The logarithm of the determinant of the Jacobian, appearing in the change-of-variables formula to compute exact likelihoods. "their log-determinant is tractable"
- normalizing flow (NF): An invertible neural transformation that maps a simple base distribution to a complex data distribution with tractable likelihoods. "Normalizing flows~\citep{dinh2014nice,dinh2016density} map data to a simple base variable through an invertible network."
- NF head: The model head that outputs parameters of the conditional density for continuous latent positions within the causal sequence. "At continuous-thought positions, an NF head maps the hidden state to the parameters and of the conditional density"
- pass@k: A metric for code generation that measures whether at least one of k sampled programs passes the tests. "Pass@ scaling on MBPP+ and HumanEval+."
- policy gradient: A reinforcement learning method that updates policy parameters in the direction of expected reward gradients. "and update the policy via the policy gradient"
- posterior mean: The mean of the posterior distribution produced by an encoder (e.g., in a VAE), used as a point estimate for latents. "use its posterior mean as the continuous CoT target ."
- reparameterized thought space: An alternative latent space obtained via an invertible map to make autoregressive modeling easier while preserving information. "the full likelihood of the original continuous CoT target can therefore be written through the reparameterized thought space:"
- reinforcement learning (RL): A learning paradigm where policies are optimized to maximize expected rewards from environment feedback. "we further refine \methodname{} with reinforcement learning."
- STARFlow: A scalable autoregressive flow architecture leveraging Transformers for high-dimensional structured latents. "Following STARFlow~\citep{gu2025starflow}, we model continuous thought tokens with a causal Gaussian density:"
- TarFlow: A Transformer-based autoregressive normalizing flow designed for scalability in high-dimensional latent modeling. "instantiates a TARFlow-style normalizing flow inside the LLM backbone,"
- triangular Jacobian: A Jacobian matrix with nonzero entries only on and below (or above) the diagonal, enabling efficient determinant computation. "their Jacobian is triangular and their log-determinant is tractable"
- Variational Autoencoder (VAE): A generative model that learns a latent variable space by maximizing an evidence lower bound with a reconstruction term and KL regularization. "Another approach is to first learn a continuous code space with a VAE: an encoder maps together with learnable queries to "
- vLLM: A high-throughput inference engine for LLMs that accelerates decoding via optimized memory and execution. "HumanEval inference efficiency with vLLM answer decoding."
Collections
Sign up for free to add this paper to one or more collections.

