Fixed-Point Reasoners: Stable and Adaptive Deep Looped Transformers
Abstract: Looped architectures provide an inductive bias toward learning step-by-step procedures for tasks that require compositional reasoning. The number of effective layers reached by looping determines the quality of the solution these models find. Like deep architectures, looped architectures are prone to a signal propagation problem induced by depth as the halting decision is postponed. In this paper, we address this signal propagation issue using pre-norm layers and residual scaling. Building on these architectural modifications, we propose FPRM, a Transformer-based Fixed-Point Reasoning Model that uses fixed-point convergence as an end-to-end halting mechanism in a looped architecture. We show that fixed-point halting allows FPRM to adapt its compute to task difficulty. FPRM is effective on common reasoning benchmarks, namely Sudoku, Maze, state-tracking, and ARC-AGI.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a new way for AI models to “think in steps” and decide, on their own, when to stop thinking. The authors build a Transformer-based model called FPRM (Fixed-Point Reasoning Model). Instead of running a fixed number of layers, FPRM loops the same layer over and over on the same input, like re-reading and refining a draft. It stops automatically when its internal thoughts settle down and stop changing much. This helps the model spend more time on hard problems and less time on easy ones.
What questions did the researchers ask?
They focused on two simple, practical questions:
- How can a model flexibly use more or fewer steps depending on how hard a problem is?
- How can it decide when to stop those steps without needing a separate “stop now” module?
They also asked a technical question: how can we make these many repeated steps stable and trainable so the model doesn’t “blow up” or get stuck?
How did they approach it?
To answer these questions, the authors design a looping Transformer and add a smart, automatic stopping rule based on a fixed-point, plus stability tricks so the model trains well.
Looped Transformers: repeating a step until you’re done
A normal Transformer has a fixed stack of layers. Here, the same layer is reused many times: the model computes , meaning “take my current internal state , update it with the function , and repeat.” This gives the model flexibility to use more steps for tougher inputs.
Think of it like solving a puzzle: you try a move, look at the board, try another move, and keep going until the board stops changing in a meaningful way.
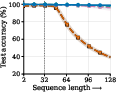
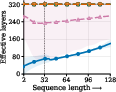
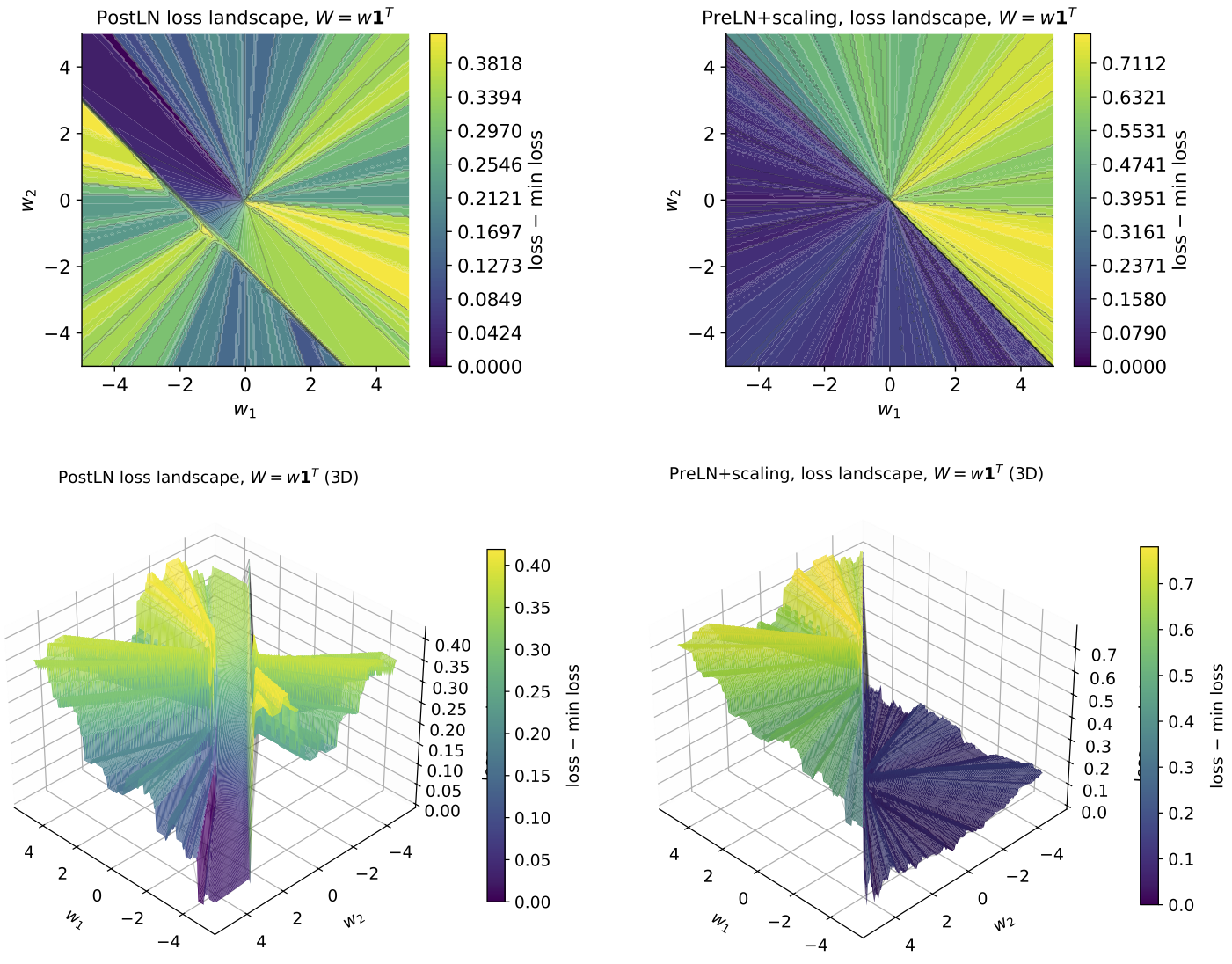
Keeping the signals healthy: pre-norm plus “residual scaling”
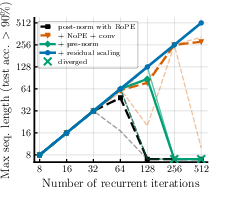
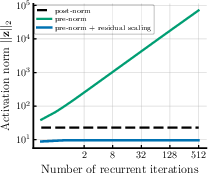
Deep or repeated models can run into “signal propagation” problems: signals can get too big (explode), too small (vanish), or fail to use later steps well. A common fix is “normalization,” which keeps numbers in a comfortable range. Many looped models use post-norm (normalize after a step) because it keeps values bounded, but it can make learning harder in deep settings.
The authors switch to pre-norm (normalize before each step), which usually trains better in deep models. But pre-norm alone can let values grow too much in a loop. So they add “residual scaling,” which is like turning two dials:
- A layer-level dial that balances “keep some of the old state” versus “add new changes.”
- A loop-level dial that blends the fresh state with the original input each time.
By choosing these dials well (and letting the model learn them), the updates stay bounded and stable while still allowing information to flow through many steps. The paper backs this up with math that shows the looped states won’t blow up and can converge.
Stopping automatically with fixed-points
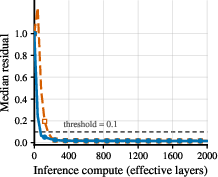
A fixed-point is a steady state: when the model’s next step is almost identical to the current state, it means it has “settled.” FPRM uses this idea to halt: it keeps looping until the change between steps is tiny. That way, the model naturally spends more computation on hard cases (which need more steps to settle) and less on easy ones.
This is different from methods that rely on:
- Chain-of-Thought (writing out many tokens and stopping at a special token), which needs special training data and scripting; or
- ACT (Adaptive Computation Time), which adds a separate module to decide when to stop and can be hard to train.
FPRM’s halting is built-in and end-to-end.
Avoiding oscillations: damping (taking smaller steps if needed)
Sometimes repeated updates can bounce around a good answer without landing on it (like overshooting back and forth). The authors add “damping,” which means mixing a bit less of the newest change into the state when progress stalls—like taking smaller steps if you’re wobbling. They use a simple rule: if improvement pauses for a while, shrink the step-size and keep going. They prove this kind of damping can stop the wobble and keep the same final answers.
Training the model
Training fixed-point models can be tricky. The authors use a practical approach that approximates the exact gradient (how much to change the model during learning) by looking at only a limited number of loop steps. This keeps training efficient and works well because the loop tends to be contracting (each step gets you closer to a solution).
What did they find, and why does it matter?
Here are the key takeaways the authors report:
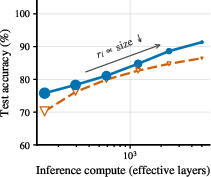
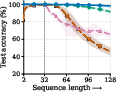
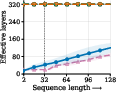
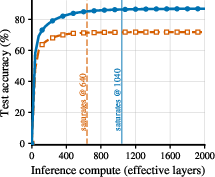
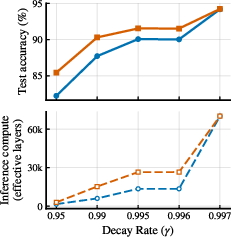
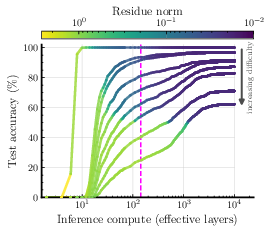
- The model adapts its compute to task difficulty. It loops more on hard inputs and halts earlier on easy ones—without extra modules.
- It performs strongly on popular reasoning benchmarks like Sudoku-Extreme, Maze-Hard, state-tracking tasks ( and ), and ARC-AGI-1, using only about 7 million parameters.
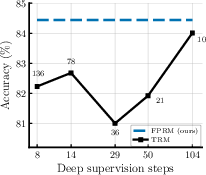
- It outperforms prior compact reasoning models (like TRM and HRM) on several tasks, even though those models use a hand-crafted hierarchy (fast and slow loops). FPRM achieves this without any hierarchy, thanks to better signal handling and fixed-point halting.
- Switching from post-norm to pre-norm in a looped Transformer, plus residual scaling, improves stability and the ability to use many effective steps.
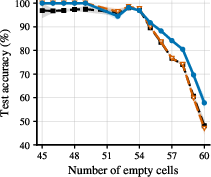
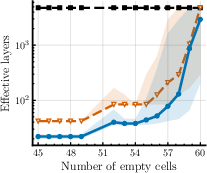
- The model correctly detects when extra steps won’t improve accuracy (it finds “plateaus”) and stops, saving computation.
This matters because it shows a clear, simple path to build small, efficient reasoning models that can think longer when needed, without complicated halting gadgets or special training recipes.
What could this change going forward?
- More reliable adaptive compute: FPRM shows that “stop when settled” is a clean, end-to-end way for models to control their own thinking time.
- Simpler designs: Getting rid of extra halting modules and hierarchies can make models easier to build, tune, and understand.
- Better small models: Strong results with ~7M parameters suggest you don’t always need huge models for reasoning-heavy tasks if you use compute wisely.
- Safer deep looping: The pre-norm + residual scaling recipe could help other looped or deep models avoid training breakdowns and make better use of many steps.
In short, this paper presents a stable, adaptive, and simple method for “thinking in loops.” By halting at a fixed-point and carefully controlling how information flows each step, FPRM solves puzzles and reasoning tasks efficiently—and knows when to stop.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and open questions that remain unresolved and could guide follow-up research:
- Theoretical assumptions vs. real Transformer layers: The boundedness and Lipschitz assumptions (e.g., sub-layer outputs bounded by a constant and global Lipschitz constants) are not established for attention/MLP layers with standard parameterizations. Derive realistic bounds for Transformer sublayers (including softmax attention) or specify regularization (e.g., spectral normalization) that provably enforces the assumptions.
- Effect of sequence length on boundedness: Analyze how the constants in the boundedness and Lipschitz assumptions scale with sequence length, width, and number of heads. Determine whether c_f or λ_f grows with context length and if so, how to mitigate.
- Coupling of residual scaling parameters: The specific coupling of β1 and β2 to α1 and α2 ensures boundedness but may constrain expressivity. Empirically ablate and theoretically study alternative parameterizations (e.g., untied per-layer scaling, gating, or input-conditional scaling) and their stability/expressivity trade-offs.
- Local vs. global convergence: Convergence is guaranteed only under local contractivity. Provide diagnostics or certification methods that verify (or enforce) contractivity at runtime per input, and characterize the prevalence of non-contractive regions.
- Existence and uniqueness of fixed points: Formalize conditions guaranteeing existence and uniqueness of fixed points for the learned operator across inputs. Identify architectures or regularizers that enlarge attraction basins and reduce spurious fixed points.
- Oscillation handling beyond damping: The adaptive damping heuristic (patience-based decay of η) lacks convergence guarantees. Compare against principled acceleration/stabilization methods (e.g., Anderson/Broyden with safeguards, Chebyshev damping) and analyze their effects on both convergence speed and solution quality.
- Halting criterion vs. correctness: The residual-based halting (‖z − f(z)‖ ≤ τ) is not calibrated to task loss; small residuals can correspond to wrong answers. Measure correlation between residual and correctness, derive bounds relating residual to task error, and design calibrated stopping criteria.
- Norm choice for residual: Justify the choice of the ℓ∞ residual (and normalization by ‖f(z)‖); systematically evaluate alternative norms (token-wise, layer-wise, ℓ2, per-head) for better predictiveness of correctness and compute allocation.
- Failure modes when no fixed point exists or is slow to reach: Identify inputs for which the iteration does not converge or converges too slowly. Provide robust fallback policies (e.g., max-steps, confidence checks, alternative solvers) and compute upper bounds on time-to-halt.
- Multi-attractor dynamics and initialization: Quantify sensitivity to initial states and characterize spurious attractors. Evaluate multi-start strategies, learned initializations, or curriculum methods to bias toward correct attractors and larger basins.
- Expressivity vs. contraction trade-off: The paper notes excessive contraction hurts expressivity, but does not quantify this trade-off. Develop metrics and training schedules for α1/α2 that preserve expressivity while ensuring trainability, and analyze their evolution over training.
- Truncated BPTT/Neumann gradient accuracy: The gradient derivation is incomplete and lacks empirical analysis. Complete the theoretical error bounds for truncated backprop (as a function of k and λ_f) and measure the bias/variance–performance trade-off across tasks.
- Memory and throughput cost: Provide systematic measurements of training/inference memory, latency, and throughput vs. baselines (TRM/HRM, DEQ with Broyden/Anderson, ACT-based models) under matched accuracy and compute budgets.
- Scalability beyond 7M parameters: Evaluate whether stability and adaptivity persist at larger scales (e.g., 100M–1B+), including sensitivity of α/β schedules, convergence behavior, and compute-efficiency.
- Domain generality beyond puzzles: Test FPRM on natural language, code, and tool-use reasoning tasks (e.g., GSM8K, MATH, MBPP, Toolformer-style tasks) to assess whether fixed-point halting and pre-norm with residual scaling transfer beyond grid/puzzle domains.
- Per-token or block-wise adaptivity: Current halting is global for the sequence. Investigate token-wise or segment-wise halting and its stability, along with scheduling and routing mechanisms that keep fixed-point benefits without sacrificing fine-grained adaptivity.
- Interaction with hierarchical looping: Although FPRM avoids hierarchy, it remains unclear whether combining fixed-point halting with hierarchical loops (fast/slow) could further improve efficiency or accuracy. Provide controlled comparisons and hybrids.
- Alternative fixed-point solvers in the looped regime: Benchmark Anderson/Broyden or learned quasi-Newton steps inside the loop against damping-only, measuring convergence speed, numerical stability, and impact on training.
- Sensitivity to halting hyperparameters: Characterize sensitivity to τ (tolerance), ε (normalizer), patience P, decay γ, and initialization of η and α2. Provide principled selection rules or learned controllers to tune these automatically per task/input.
- Robustness to noise and distribution shift: Test stability and adaptivity under noisy inputs, corrupted contexts, and out-of-distribution tasks (including longer sequences than seen in training). Measure how halting behavior changes and how to regularize for robustness.
- Guaranteeing compute bounds: Derive theoretical or empirical bounds on the number of iterations required to reach τ (as a function of λ_f, α2, etc.) to ensure predictable latency and energy use in deployment.
- Tying vs. untying parameters across iterations: Assess whether partial untying (e.g., every k loops) or learned iteration-dependent adapters can boost expressivity without compromising convergence and stability.
- Mechanistic interpretability of attractors: Analyze whether fixed points encode solutions or intermediate invariants; map attractor geometry (basin volumes, linearized dynamics) and relate to algorithmic routines the model learns.
- Tasks requiring non-convergent dynamics: Identify problems where useful dynamics are cyclic or chaotic (e.g., search with backtracking). Determine whether damping suppresses beneficial oscillations and design mechanisms to allow productive cycles without sacrificing halting.
- Regularization to ensure bounded sublayer outputs: Propose and evaluate explicit regularizers (e.g., spectral norm, Jacobian penalties, attention clipping) that enforce the boundedness needed by Theorem 1 without hurting performance.
- Fair adaptivity comparisons to ACT: Provide standardized, budgeted compute–accuracy curves across difficulty bins with matched training settings to substantiate claims that ACT fails to adapt and FPRM succeeds.
- Calibration of compute-to-difficulty: Define and validate difficulty measures per benchmark; quantify how iterations scale with task difficulty and whether this relation remains stable across seeds, hyperparameters, and domains.
Practical Applications
Immediate Applications
Below are actionable, deployment-ready uses that leverage the paper’s core findings: fixed-point halting for adaptive compute, pre-norm with residual scaling for deep looped stability, and damping-based convergence control.
- Adaptive compute controller for reasoning services (Sector: Software/ML Infrastructure)
- What: Replace fixed-depth inference with fixed-point halting, letting each request run until the hidden state converges (or an SLA cap is hit), reducing cost on easy inputs and allocating more compute to hard ones.
- How: Integrate a looped Transformer with pre-norm + residual scaling and the FPOpt routine (patience-based damping; residual threshold τ) into an inference service; log residuals r_i for observability; calibrate τ and patience P.
- Tools/Workflows: PyTorch module with learnable α1, α2 scalars; serving policy that enforces max-iterations; dashboards for residual trends per request; integration with existing A/B and SLA monitors.
- Assumptions/Dependencies: Task must have well-behaved fixed-points in practice; inference stack must support dynamic iteration; tolerance τ and damping schedule require tuning.
- Energy- and cost-aware serving (Sector: Cloud/DevOps)
- What: Reduce average GPU time and energy by halting early on easy inputs; increase throughput without accuracy loss.
- How: Use fixed-point convergence as early stopping; auto-tune τ per routing tier.
- Tools/Workflows: Autoscaling policies conditioned on residual statistics; per-tenant τ/P settings; budget-aware iteration caps.
- Assumptions/Dependencies: Residuals correlate with solution quality on your workload; need guardrails for worst-case latency.
- Constraint-satisfaction helpers for operations (Sector: Manufacturing/Logistics/Supply Chain)
- What: Apply FPRM as a learned heuristic for scheduling, timetabling, or assignment (analogous to Sudoku/ARC constraints).
- How: Encode domain states as sequences; train on synthetic or historical instances; deploy convergence-based halting to adapt compute to instance difficulty.
- Tools/Workflows: OR pipeline wrapper where FPRM proposes feasible/near-feasible solutions; fallback to exact solvers for certification.
- Assumptions/Dependencies: Requires task-specific representation and training data; feasibility checks may need external validators.
- Pathfinding and planning under compute budgets (Sector: Robotics, Games)
- What: Use fixed-point halting for online planning (maze-like pathfinding), spending more compute when navigation is complex.
- How: Replace or augment existing planners with FPRM; enforce max-iteration per control cycle; use damping to avoid oscillations near ambiguous states.
- Tools/Workflows: ROS-compatible module; test bench that maps residual trajectories to safety margins.
- Assumptions/Dependencies: Real-time requirements impose strict iteration caps; safety requires fallback policies.
- Compliance rule evaluation and exception triage (Sector: Finance/RegTech)
- What: Iteratively apply learned rule-check subroutines until the decision stabilizes; allocate extra steps to borderline cases.
- How: Encode rule graphs or transaction sequences; deploy residual-threshold halting plus audit logs of convergence behavior.
- Tools/Workflows: Exception handling workflow where non-converged cases escalate to human review.
- Assumptions/Dependencies: Needs traceability; validation on historical false positives/negatives; regulatory model risk processes.
- On-device assistants for step-by-step tasks (Sector: Consumer/EdTech)
- What: Run small FPRMs on phones/tablets for arithmetic/logic puzzles or tutoring; spend more compute on hard questions within battery/latency limits.
- How: Compress 7M-parameter FPRMs; set adaptive τ and max-iteration per device class.
- Tools/Workflows: Mobile inference with dynamic looping; telemetry on residual vs. battery and latency.
- Assumptions/Dependencies: Memory/power constraints; model performance must meet UX targets without network reliance.
- Agent planning modules with latent reasoning (Sector: Software Agents/Automation)
- What: Replace verbose Chain-of-Thought tokens with latent iterative reasoning; avoid token costs while retaining adaptive compute.
- How: Embed FPRM as an internal “planner” stage in agent pipelines; signal halting via residual rather than stop-tokens.
- Tools/Workflows: Agent step orchestrator calls FPRM until convergence or budget; compare to CoT token usage.
- Assumptions/Dependencies: Requires integration glue between language and latent modules; evaluation for hallucination/control flow.
- Runaway-loop and deadlock prevention (Sector: Security/SRE)
- What: Use convergence and damping to bound runtime and prevent pathological looping in production reasoning services.
- How: Enforce residual-based halting, patience-based damping, and hard iteration caps; alert on non-convergence rates.
- Tools/Workflows: SRE policies for abnormal oscillation patterns; automatic τ increases or fallbacks under incident response.
- Assumptions/Dependencies: Properly tuned τ/P; clear escalation paths for non-converged requests.
- Research and teaching kits for algorithmic reasoning (Sector: Academia/EdTech)
- What: Study adaptive compute and fixed-point attractors without hierarchical loops; reproduce results on Sudoku, Maze, ARC-AGI, and state tracking.
- How: Use the provided code; run ablations on α1/α2 initialization, residual scaling, and pre-vs-post norm.
- Tools/Workflows: Curriculum datasets; mechanistic analysis of basins of attraction; classroom modules on fixed-point training and truncated BPTT.
- Assumptions/Dependencies: Compute resources for iterative training; datasets reflecting target algorithms.
- Library extensions for looped Transformers (Sector: ML Tooling)
- What: Package pre-norm + residual scaling layers, iteration-wise input mixing, and FPOpt into open-source libraries.
- How: Add “LoopedTransformerPreNormScaled” and “FixedPointHalting” components; test harnesses for convergence and numerical stability.
- Tools/Workflows: PyTorch/Hugging Face integrations; unit tests for coupling of α/β as per boundedness theorem.
- Assumptions/Dependencies: Community adoption; rigorous documentation and examples.
Long-Term Applications
These opportunities require further research, scaling, or ecosystem development (e.g., stronger guarantees, larger models, hardware/compiler support).
- Scaled fixed-point reasoners for language tasks (Sector: Software/AI Platforms)
- What: Combine fixed-point halting with LLMs to control test-time compute without reliance on stop-tokens or long CoT.
- How: Hybrid architectures with token-level or segment-level looped modules; explore attractor diversity (multiple initial guesses).
- Dependencies: Training stability at scale; compiler/runtime support for dynamic looping; evaluation of safety and latency.
- Safety-critical planning and control (Sector: Autonomous Systems/Robotics)
- What: Real-time planners that adapt compute with provable halting and stability margins.
- How: Couple fixed-point residuals to certified safety monitors; derive worst-case iteration bounds.
- Dependencies: Formal guarantees; integration with redundancy/fallback controllers; certification pathways.
- Scientific and engineering solvers (Sector: Energy/Utilities/Manufacturing/R&D)
- What: Learn iterative operators for domain constraints (e.g., power flow, circuit checks, combinatorial design), halting on convergence.
- How: Train FPRMs as surrogate iterative solvers or proposal generators; use fixed-point residuals as physics-constraint proxies.
- Dependencies: High-fidelity data; verifiable constraints; hybrid workflows with physics solvers for certification.
- Grid optimization and dispatch (Sector: Energy)
- What: Adaptive compute for contingency analysis or re-dispatch under varying difficulty.
- How: Integrate FPRM into decision-support pipelines; restrict compute during normal ops, expand during emergencies.
- Dependencies: Regulatory acceptance; robust handling of corner cases; demonstrable reliability.
- Clinical decision support and triage (Sector: Healthcare)
- What: Allocate more compute to ambiguous cases; halt early on clear-cut ones; reduce clinician cognitive load.
- How: Encode patient trajectories/state as sequences; enforce conservative iteration caps and human-in-the-loop escalation.
- Dependencies: Extensive validation, fairness audits, and regulatory approval; traceability and calibration.
- Formal verification and program synthesis (Sector: Software/Verification)
- What: Iterative latent reasoning for invariant inference or synthesis tasks; adapt compute to proof difficulty.
- How: Integrate with constraint solvers and interpreters; use residuals as convergence toward invariants.
- Dependencies: Soundness guarantees; counterexample-guided refinement; benchmark suites.
- Dynamic, per-token halting and compute routing (Sector: AI Systems)
- What: Extend fixed-point halting to token-wise adaptive depth (mixture-of-recursions) to minimize latency on easy spans.
- How: Learn halting at finer granularity; route tokens to fewer iterations or specialized sub-modules.
- Dependencies: New training objectives; efficient scheduling; stability under asynchronous halting.
- Hardware and compiler co-design for adaptive loops (Sector: Semiconductors/Systems)
- What: Accelerators and runtimes that efficiently schedule variable-depth loops and detect convergence on-chip.
- How: ISA/runtime primitives for residual checks, early exit, and state reuse across loops.
- Dependencies: Vendor support; compiler toolchains; cost-performance validation.
- Governance and standards for adaptive compute (Sector: Policy/Regulation)
- What: Define reporting and controls for variable compute usage (energy, fairness, latency).
- How: Standardize logging of residuals, halting thresholds, and iteration counts for audits.
- Dependencies: Stakeholder consensus; alignment with model risk management and green AI initiatives.
- Interpretability of attractors and failure modes (Sector: Academia/Safety)
- What: Map basins of attraction; diagnose oscillations and non-convergence; relate to errors.
- How: Tools to visualize latent trajectories; interventions on damping and initialization.
- Dependencies: Shared benchmarks and evaluation protocols; collaboration across labs.
Cross-cutting assumptions and dependencies (common to many applications)
- Task fit: Benefits are largest for problems with compositional/iterative structure where fixed points exist or can be induced during training.
- Stability conditions: Practical convergence relies on appropriate initialization (e.g., small α2), residual scaling, and damping schedules; settings are task-dependent.
- Halting calibration: Tolerance τ, patience P, and max-iteration caps must be tuned to balance accuracy, latency, and reliability.
- Verification: Safety-critical uses require external validation, feasibility checks, and fallback mechanisms.
- Tooling: Dynamic-loop support in serving stacks and observability for residuals/iterations are essential for production readiness.
Glossary
- Adaptive Computation Time (ACT): A mechanism that learns when to stop computation by predicting halting decisions, enabling variable computation per input but introducing optimization challenges. Example: "The latter is associated with separate Adaptive Computation Time (ACT) networks"
- Anderson acceleration: A technique to speed up fixed-point iterations by extrapolating from previous iterates using linear combinations. Example: "which they solve with Anderson acceleration."
- Attractor Models: Models that frame iterative computation as finding attractors (roots) and use accelerated solvers to reach them. Example: "Attractor Models \citep{feinashley2026solveloopattractormodels} frame the iterations of TRM as a root-finding problem similar to DEQ, which they solve with Anderson acceleration."
- Broyden's method: A quasi-Newton algorithm for solving nonlinear fixed-point or root-finding problems without computing exact Jacobians. Example: "via a quasi-Newton approach such as Broyden's method"
- Chain-of-Thought (CoT): A strategy where a model generates intermediate reasoning steps in text to scale compute and guide halting via special tokens. Example: "The standard way to achieve both is through a Chain-of-Thought (CoT) mechanism"
- Contraction mapping: A function with Lipschitz constant less than one, guaranteeing a unique fixed-point and convergence of iterates. Example: "is a contraction and the iteration $\bmz_{i+1} = f_\theta(\bmz_i;\bmx)$ converges to a unique fixed-point"
- Deep Equilibrium Models (DEQ): Models that define outputs as the fixed-points of an implicit layer, typically solved with root-finding rather than explicit unrolling. Example: "This view is most extensively developed in Deep Equilibrium Models"
- Diffusion Models: Generative models that learn to denoise or estimate the score (gradient of log-density) and simulate data via diffusion (often as SDEs). Example: "Diffusion Models \citep {ho2020denoising, song2020score}"
- Damping: Mixing the current iterate with the update to suppress oscillations and stabilize fixed-point convergence. Example: "Damping stabilizes oscillatory fixed-point dynamics"
- Energy-Based Models (EBMs): Models that assign low energy to desired configurations and generate samples by descending or sampling in the energy landscape. Example: "Energy-Based Models (EBMs) \citep{lecun2006tutorial}"
- Fixed-point halting: An adaptive stopping rule that halts when successive iterates are sufficiently close, indicating convergence to a fixed-point. Example: "fixed-point halting allows FPRM to adapt its compute to the difficulty of the task."
- Implicit function theorem: A theorem enabling gradients through implicitly defined solutions (e.g., fixed-points) via the inverse of a Jacobian-related operator. Example: "Following the implicit function theorem we can write"
- Inductive bias: Architectural or algorithmic preferences that make learning certain patterns or solutions more likely. Example: "Looped architectures provide an inductive bias toward learning step-by-step procedures"
- Iteration-wise input mixing: Re-injecting the original input between iterations to stabilize and guide the recurrent computation. Example: "Iteration-wise input mixing."
- Jacobian: The matrix of partial derivatives of a vector-valued function, used to analyze local dynamics and convergence properties. Example: "oscillation around the fixed-point can happen when the Jacobian satisfies certain conditions."
- Jacobian-free backpropagation: An approximate implicit differentiation technique that avoids forming or inverting Jacobians directly. Example: "closely related to Jacobian-free backpropagation, where the full implicit linear solve is replaced by cheaper approximate gradients"
- Layer-wise residual scaling: Scaling both the residual stream and sub-layer outputs within each layer to keep activations bounded during looping. Example: "Layer-wise residual scaling."
- Lipschitz constant: A bound on how much a function can change with respect to its input; central for establishing contraction and stability. Example: "Let be the Lipschitz constant of the -layer model"
- Looped Transformer: A Transformer whose layers are applied repeatedly with shared parameters, effectively deepening computation at test time. Example: "Our fixed-point Looped Transformer uses pre-norm and residual scaling for improved signal propagation."
- MCMC methods: Markov chain Monte Carlo techniques for sampling from complex distributions, often used in EBMs. Example: "sampling with MCMC methods"
- Neumann series: A series expansion used to express the inverse of (I − J) under contractivity, enabling implicit gradient computation. Example: "The Neumann series $(\matI-\matJ)^{-1} = \sum_{j\geq 0}\matJ^{\,j}$ converges"
- Post-norm: A Transformer variant applying layer normalization after the residual addition, which bounds activations but can hinder signal propagation. Example: "post-norm bounds activation magnitudes"
- Pre-norm: A Transformer variant applying layer normalization before each sub-layer, improving gradient flow but risking unbounded activations in deep loops. Example: "pre-norm improves signal propagation"
- Quasi-Newton methods: Root-finding or optimization methods that approximate second-order information without full Hessians/Jacobians. Example: "via a quasi-Newton approach"
- Residual scaling: Introducing learned multipliers on residual and sub-layer paths to stabilize deep or repeated application of layers. Example: "by using pre-norm layers and residual scaling."
- Residual stream: The main pathway in residual networks that carries forward the previous representation to be added to sub-layer outputs. Example: "the residual stream and sub-layer output $f^\ell_{\theta^\ell}(\bmz^{\ell-1})$ are weighted by tied scalars"
- SDE: Stochastic differential equation; a continuous-time dynamical system with noise, used in diffusion model sampling. Example: "integrate an SDE over a fixed time interval"
- Signal propagation: The movement and preservation of information and gradients through many layers or iterations, whose degradation can hinder training. Example: "address the signal propagation issue"
- Truncated back-propagation through time (BPTT): Computing gradients through a limited number of unrolled steps to approximate implicit gradients efficiently. Example: "trained using truncated back-propagation through time (BPTT)"
- Weight tying: Sharing parameters across iterations or layers to enforce consistency and reduce parameter count. Example: "weight-tied looped models can naturally implement an implicit fixed-point computation"
Collections
Sign up for free to add this paper to one or more collections.