Masked Language Flow Models
Abstract: Masked Diffusion Models (MDMs) promise fast, parallel language generation, but their reverse transition factorises across token positions -- an approximation that breaks down in the few-step sampling regime where parallel generation ought to provide the greatest efficiency gains. Flow LLMs (FLMs) sidestep this limitation by learning a continuous flow that transports noise toward clean sequences represented in Euclidean space, inducing a flow map that can be distilled for single-step generation. However, this makes complex tasks requiring multi-step reasoning problematic for FLMs, as FLMs are forced to decode every token during generation. To address this, we introduce Masked Language Flow Models (MLFMs), which incorporate masking into FLMs using a continuous stochastic interpolant to bridge partially masked and clean sequences. This design enables conditional generation via continuous flows and allows pretrained MDMs to be converted into MLFMs through a simple, lightweight adaptation. Leveraging this flexibility, we propose a novel sampler that alternates continuous denoising with the discrete unmasking of confident tokens to better support multi-step reasoning. We evaluate our approach on GSM8K and MT-Bench and find, for the first time, that flow-based LLMs can be scaled to solve downstream reasoning and instruction-following tasks.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way for AI models to write text quickly and accurately. It combines two ideas:
- Masking (covering up some words and guessing them)
- Flow (smoothly moving from “noise” to a clear answer)
The authors call their method Masked Language Flow Models (MLFMs). The goal is to make models that can generate and reason about text in fewer steps, while still using helpful context and making smart, step-by-step choices.
What questions are the authors trying to answer?
They focus on three simple questions:
- How can we generate text in parallel (not one word at a time) without losing quality?
- How can we let the model use context flexibly and improve its guesses over multiple steps?
- Can “flow-based” models, which are fast, actually do tougher tasks like following instructions and solving math problems?
How did they do it?
To make this understandable, think of writing as solving a puzzle:
The big idea: Masked Language Flow Models
- Imagine a sentence with some words covered by “[MASK]” tokens.
- The model represents every word as a point in a number-space called an “embedding.” Think of embeddings like coordinates that capture meaning.
- For masked spots, the model follows a gentle path (a “Brownian bridge”) that starts at the mask’s embedding and ends at the true word’s embedding. Along the way, the model sees a “blurry” version of the word—this helps it guess smarter.
- Clean (unmasked) words stay fixed and act as context the model can trust.
Why this helps: It blends the strengths of two worlds:
- Masking lets the model condition on known context anywhere in the sentence.
- Flow gives smooth, joint updates across all positions, not just one-by-one.
Training by adapting an existing model
- Instead of training everything from scratch, they start with a strong masked diffusion model (MDM) that already knows how to guess masked words.
- They keep its core frozen and add small “adapters” (lightweight tuning parts) so the model learns to handle the continuous, flowing version of the task.
- This reduces training cost and speeds things up.
A new way to sample (generate) answers
When generating, the model uses two clever tricks:
- Context-corrupted guidance (CCFG): The model compares its direction when context is clean vs when the context is “blurred.” This shows how much the real context helps, and nudges the model in the better direction.
- Online Token Promotion (OTP): If the model becomes very confident (say 95% sure) about a masked word, it immediately “locks in” that word as clean context. This turns reliable guesses into helpful clues for the rest of the sentence, sooner rather than later.
Together, these make generation both guided and adaptive: the model learns step by step, and uses new confident words to improve the rest.
What did they find?
They tested MLFMs on two benchmarks:
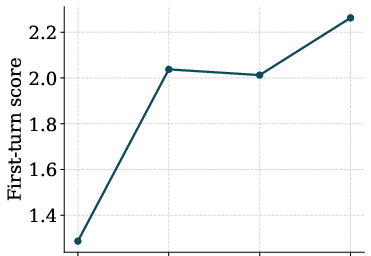
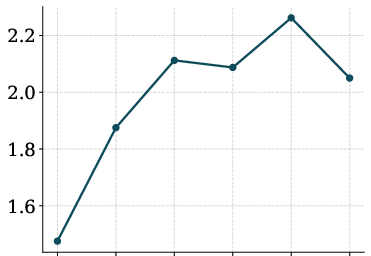
- MT-Bench: A test of instruction-following (answering diverse questions in natural language). MLFMs scored 2.27 (higher is better), beating both a similar diffusion model (1.60) and a similar autoregressive model (1.57).
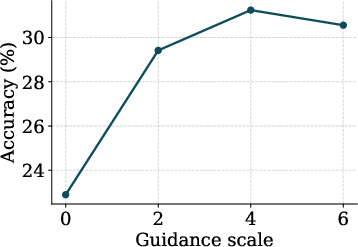
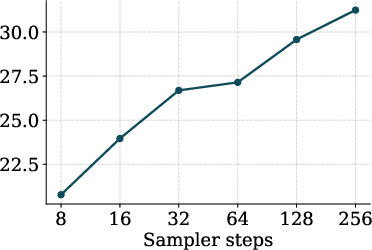
- GSM8K: A math word-problem dataset. MLFMs got 31.24% accuracy, which is below strong baselines (around 58%). The authors suggest this may be because their fine-tuning focused broadly on many tasks, not heavily on GSM8K like the baselines.
Why these results matter:
- MT-Bench shows MLFMs can handle real instruction-following and produce coherent, multi-step answers.
- GSM8K shows room to improve on math reasoning, likely with more task-specific training.
They also found their new sampling methods (CCFG and OTP) significantly improved performance versus simpler sampling.
Why does this research matter?
- Faster generation: Flow-based methods can cut down the steps needed. That means quicker responses and lower cost.
- Better use of context: Masking plus flow lets models condition on any part of the text and update everything together. This is great for multi-step reasoning.
- Practical progress: The paper shows, for the first time, that flow-based LLMs can be scaled and used on real downstream tasks like instruction-following. This opens the door to more efficient, high-quality AI assistants.
- Future potential: With more targeted fine-tuning and distillation (making the flow even more direct), MLFMs could close the gap on math tasks and push performance further while staying efficient.
In short, MLFMs are a promising step toward fast, flexible, and capable LLMs that don’t have to write strictly one word at a time—and that can still think through problems in multiple steps.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, structured list of what remains missing, uncertain, or unexplored in the paper, framed to guide future research.
Theoretical foundations
- Formalize sampling correctness with Online Token Promotion (OTP) under realistic conditions. Proposition 4.2 assumes exact denoising; quantify error when the denoiser is approximate and when guidance is applied, and study how errors accumulate across steps and promotions.
- Establish conditions under which mask-endpoint equivalence (Proposition 3.1) holds in practice. The result assumes unmasked token identities are recoverable from embeddings; analyze failure modes when embeddings are not injective or are frozen and suboptimal.
- Provide a theoretical link between context-corrupted classifier-free guidance (CCFG) and standard classifier-free guidance (CFG). Characterize when corruption-based guidance approximates or differs from CFG and its impact on bias/variance of the learned flow.
Modeling choices and design
- Study sensitivity to the Brownian bridge noise scale σ and to time-sampling schedules. Quantify how σ and the NSR schedule influence training stability, calibration, and downstream performance; explore learning σ or making it position-dependent.
- Evaluate alternatives to the fixed mask embedding m and frozen embedding matrix E. Assess whether learning m and/or unfreezing E improves accuracy, calibration, and invertibility assumptions.
- Analyze the impact of clamping vθ=0 on unmasked positions. Determine whether freezing clean-context velocities introduces bias, and whether learned context drift (small nonzero velocity) might help.
- Investigate training-time consistency with inference-time OTP. Current training never sees intermediate, incrementally promoted clean states; evaluate training that simulates OTP (e.g., self-conditioning or staged promotion during training) to reduce train–test mismatch.
Adaptation and training protocol
- Compare adaptation to MLFMs against training from scratch and against unfreezing the backbone. Ablate LoRA rank/placement, freezing choices, and AdaLN conditioning; quantify the trade-offs in compute, speed of convergence, and final quality.
- Examine the effect of the auxiliary embedding loss and its weight. Provide ablations to determine whether this loss improves calibration or harms discrete prediction.
- Clarify and ablate the instruction-tuning data mixture. The SFT includes code and general instruction data; evaluate mixture composition and curriculum effects for math and instruction-following, and isolate their contributions to downstream gaps (e.g., GSM8K).
Sampling and guidance
- Develop adaptive promotion criteria. Replace a fixed ε with token- and time-dependent thresholds based on calibrated uncertainty (e.g., entropy, margin, or Bayesian uncertainty) and assess accuracy/speed trade-offs.
- Quantify the computational cost of CCFG and OTP. Measure wall-clock overhead of two model evaluations per step (clean vs corrupted context), and amortize costs with caching or shared computation; explore single-call approximations to CCFG.
- Compare CCFG against alternative guidance and conditioning schemes. Evaluate masked-dropout context, learned guidance models, or guidance trained explicitly during MLFM training; assess robustness to short/ambiguous prompts.
- Explore deterministic solvers and flow-map distillation with OTP. The paper proposes distillation as future work; evaluate 1–8-step distilled samplers with online promotion for speed/quality trade-offs.
Evaluation and benchmarks
- Expand beyond GSM8K and first-turn MT-Bench. Evaluate multi-turn MT-Bench, coding (e.g., HumanEval), reasoning-heavy instruction traces, and long-context tasks to support claims on multi-step reasoning and instruction following.
- Provide strong AR and MDM baselines with matched fine-tuning regimes. The GSM8K protocol differs from SMDM’s task-specific fine-tuning; evaluate MLFM under the same task-specific protocol or report matched mixtures to isolate method effects.
- Report speed and efficiency metrics. Provide wall-clock latency, throughput, and memory comparisons to AR and MDMs for various sequence lengths and step counts; quantify when MLFMs win on efficiency in practice.
- Measure calibration and error analysis tied to OTP. Assess token-level calibration, promotion error rates, and the types of mistakes induced by early commitment; analyze error propagation across steps.
Capabilities enabled by “any-position conditioning”
- Validate any-position conditional generation beyond prompts. Benchmark inpainting and fill-in-the-middle tasks (e.g., text infilling, constrained decoding), as well as editing with sparse masks to test the flexibility highlighted by the framework.
- Study structural dependence modeling. Directly compare dependency recovery across positions (e.g., mutual information, cloze-style multi-token prediction) against MDMs and AR models to confirm advantages of joint continuous flows.
Robustness and generalization
- Assess robustness to rare tokens and distribution shift. Evaluate on low-frequency vocab items, domain shift tasks, and long-tail prompts; examine failure cases where embedding geometry or masking hampers recovery.
- Examine long-context scaling. Current experiments cap at 1024 tokens; test stability and quality for longer contexts and larger L, and the impact on promotion and guidance dynamics.
Scaling and resource considerations
- Establish scaling behavior with parameters, data, and steps. Provide parameter/data/compute scaling laws for MLFMs and identify regimes where flows overtake AR/MDM in quality or efficiency.
- Compare training compute and resource utilization to AR/MDM paradigms. Quantify the cost/benefit of adapting from MDMs versus pretraining MLFMs, including data efficiency and convergence speed.
Safety, alignment, and reliability
- Evaluate safety and alignment properties under OTP and CCFG. Test for prompt injection, toxicity, and hallucination under early promotion; analyze whether committing early to confident but wrong tokens increases harmful outputs.
- Investigate interpretability of multi-step and promotion dynamics. Develop tools to monitor when/why tokens are promoted and how this affects downstream reasoning trajectories.
Practical Applications
Immediate Applications
Below are concrete use cases that can be deployed now, leveraging Masked Language Flow Models (MLFMs), the context-corrupted classifier-free guidance (CCFG) sampler, and Online Token Promotion (OTP). Each item notes the sector, likely tools/products/workflows, and key assumptions/dependencies.
Industry
- Low-latency, high-throughput chat and helpdesk assistants
- Sector: Software/SaaS, Customer Support, Enterprise IT
- What: Use CCFG+OTP to resolve high-confidence tokens early and condition later steps on clean context, reducing latency and improving coherence in multi-step instruction following.
- Tools/workflows: Mask-aware inference servers; guidance-scale w and promotion threshold ε tuning; streaming token APIs that surface promoted tokens immediately.
- Assumptions/dependencies: Availability of a pretrained MDM or MLFM checkpoint; careful calibration of w and ε; monitoring for occasional early mis-promotions.
- Structured output generation (JSON/SQL/API payloads) with early structure locking
- Sector: Software, Finance, Health IT, LegalTech
- What: Promote deterministic format tokens (e.g., braces, commas, schema keys) early so the model conditions on the final structure while filling semantic fields.
- Tools/workflows: JSON schema–aware decoders; validators integrated with OTP; “structure-first” decoding profiles per task.
- Assumptions/dependencies: Accurate schema constraints; robust validation; careful handling of partial outputs during promotion.
- Span infilling and document editing (masked rewrite)
- Sector: Productivity, Content Ops, Knowledge Management
- What: Treat preserved text as clean context and regenerate masked spans via continuous flows; enables “rewrite” features without disturbing surrounding content.
- Tools/workflows: Editor plugins (Docs, email, CMS) with mask selection; OTP to stabilize nearby boilerplate; user-adjustable ε for precision vs speed.
- Assumptions/dependencies: Tokenization that respects user-selected spans; UI for mask control; fallback to conservative settings in high-stakes edits.
- IDE code completion and refactoring
- Sector: Software Development
- What: Resolve syntax/boilerplate (brackets, imports, keywords) early; condition subsequent steps on clean, correct scaffolding to improve multi-line completions.
- Tools/workflows: Flow-guided IDE extensions; OTP thresholds tuned per language; tests/linters as post-checks.
- Assumptions/dependencies: Language-specific adapters; robust syntax validators; domain fine-tuning for target codebases.
- RAG systems that rely on “context influence meters”
- Sector: Search, Enterprise Knowledge Bases, Customer Support
- What: Use the difference between clean-context and context-corrupted velocities (CCFG delta) as a signal for how much the retrieved context actually steers generation; reweight or filter retrieved passages.
- Tools/workflows: Retriever rerankers using CCFG delta; dynamic guidance scaling (w) per turn; dashboards showing context influence per answer.
- Assumptions/dependencies: Stable CCFG implementation; robust retrieval; calibration so the delta reliably reflects context utility.
- Cost-efficient model adaptation pipelines
- Sector: ML Platforms, MLOps
- What: Convert existing MDMs to MLFMs using LoRA and AdaLN adapters; freeze backbones/embeddings to reduce compute and time-to-market.
- Tools/workflows: Automated adaptation jobs (LoRA rank/α search); model registry with MLFM variants; continuous evaluation harnesses.
- Assumptions/dependencies: Access to licensed MDM checkpoints; adapter-friendly architecture; reliable scheduling of mixed t and s during training.
- Confidence-aware streaming for user interfaces
- Sector: Productivity Apps, Messaging, Consumer AI
- What: Stream only promoted (high-confidence) tokens to users; reduce flicker and rollbacks while maintaining responsiveness.
- Tools/workflows: UI streaming channel tied to OTP events; ε tied to UX latency budgets; token-confidence telemetry.
- Assumptions/dependencies: Accurate token confidence estimates; UX guardrails for rare early mistakes.
- Data augmentation and imputation in text pipelines
- Sector: Data Engineering, Content Platforms, E-commerce
- What: Mask selected fields (titles, tags, keywords) and fill them with MLFM; control masking schedule to target dependencies (e.g., category→title).
- Tools/workflows: Batch infilling jobs; QA filters based on CCFG deltas; A/B tests on downstream metrics (CTR, engagement).
- Assumptions/dependencies: Clean training corpora; domain SFT; governance for synthetic data usage.
- Promotion-trace logging for auditability
- Sector: Regulated Industries (Finance, Healthcare), GovTech
- What: Record each OTP decision (time, token, confidence) to create a step-by-step reasoning trace for internal audit and post-hoc review.
- Tools/workflows: Promotion event logs; dashboards for per-output traces; integration with compliance review workflows.
- Assumptions/dependencies: Storage/PII policies; governance on trace retention; calibration to keep promotion errors below εL bounds.
Academia
- Evaluation of non-factorized dependencies and iterative reasoning
- Sector: Academic NLP/ML
- What: Use MLFM’s joint continuous trajectories and OTP to probe where independence assumptions break; create benchmarks stressing long-range dependencies.
- Tools/workflows: Mask schedules that vary dependency structure; ablations over CCFG and OTP; public datasets of promotion trajectories.
- Assumptions/dependencies: Reproducible training and sampler configs; standardized reporting on w, ε, step counts.
- Interpretability via confidence trajectories
- Sector: AI Research/Interpretability
- What: Analyze token-level posterior concentration over time; study when/why tokens cross promotion thresholds to understand reasoning dynamics.
- Tools/workflows: Time-series tooling for token posteriors; saliency overlays aligned with promotions; comparisons vs AR self-consistency.
- Assumptions/dependencies: Access to logits/probabilities per step; consistent t-schedules across runs.
Policy
- Safer defaults through guidance scaling and promotion thresholds
- Sector: Policy/Compliance, Safety Engineering
- What: Use high guidance scales (w) to emphasize clean context and tighter OTP thresholds (small ε) in safety-critical paths (e.g., data-protected text).
- Tools/workflows: Policy profiles per use case (creative vs conservative); guardrail configs for w and ε; automatic fallbacks.
- Assumptions/dependencies: Risk taxonomy per application; safety testing; measurable trade-offs between creativity and constraint adherence.
Daily Life
- Smarter email and document drafting
- Sector: Consumer Productivity
- What: Selectively mask and rewrite message parts; get low-latency, stable completions with early promotion of obvious fillers and format tokens.
- Tools/workflows: Mask-and-rewrite UI; streaming completions; “confidence-aware” accept/reject shortcuts.
- Assumptions/dependencies: Privacy-preserving deployment; user control over aggressiveness (ε) and formality.
- Math and study assistance with step stabilization
- Sector: Education
- What: OTP commits intermediate steps as soon as they’re reliable, providing clearer scaffolding in multi-step solutions and explanations.
- Tools/workflows: Tutors that show promotion checkpoints; teacher dashboards to track reasoning steps; adjustable guidance for rigor vs speed.
- Assumptions/dependencies: Domain SFT for curricula; guardrails to avoid misleading intermediate steps; correctness checks for final answers.
Long-Term Applications
These use cases require further research, scaling, or engineering (e.g., distillation to one-step maps, domain-grade safety, multimodal extensions).
Industry
- On-device assistants via few-/one-step flow-map distillation
- Sector: Mobile, IoT, Robotics
- What: Distill MLFM trajectories into compact maps for near-instant generation; OTP still applicable at inference time for stability.
- Tools/workflows: Distillation pipelines; quantization; scheduler-free sampling with promotion hooks.
- Assumptions/dependencies: Robust one-step distillation for language; memory/compute constraints on edge devices; energy profiling.
- Multimodal masked flow generation
- Sector: Vision-Language, AR/VR, Content Creation
- What: Extend masked flows to image tokens, audio, or video segments; jointly condition on clean modalities while denoising masked ones.
- Tools/workflows: Multimodal tokenizers; cross-modal bridge schedules; UI for span/segment masking across modalities.
- Assumptions/dependencies: Tokenizers and embeddings that align modalities; large-scale pretraining; safety evaluations for multimodal outputs.
- Enterprise compliance drafting (financial reports, clinical notes)
- Sector: Finance, Healthcare
- What: Treat canonical templates and validated data fields as clean context; generate only masked narrative sections with high w, strict ε.
- Tools/workflows: Integration with EHR/ERP; validators for figures/citations; approval workflows with promotion traces.
- Assumptions/dependencies: Regulatory approval; high factual accuracy; domain-specific SFT and retrieval pipelines.
- Agent planning with promotion-triggered tool use
- Sector: Automation, DevOps, DataOps
- What: Commit plan milestones (promotions) and use them to trigger external tools (search, calculators, tests) mid-trajectory.
- Tools/workflows: Orchestrators that subscribe to OTP events; tool APIs linked to milestone types; rollback strategies for mis-promotions.
- Assumptions/dependencies: Reliable detection of “tool-worthy” promotions; sandboxing and cost control; observability.
- Specialized hardware/software kernels for Brownian-bridge steps
- Sector: Semiconductors, Cloud Providers
- What: Accelerate DDPM-like updates and dual model calls (clean vs corrupted context) for CCFG; reduce inference cost at scale.
- Tools/workflows: CUDA/ROCm kernels; graph capture of two-branch velocity evaluation; kernel fusion with LoRA adapters.
- Assumptions/dependencies: Stable sampler designs; sufficient demand to justify optimization; compatibility with common accelerators.
Academia
- Theory of masked continuous flows in discrete spaces
- Sector: ML Theory
- What: Convergence and error analyses for OTP (beyond TV ≤ εL), guidance-induced biases, and dependency recovery under few-step regimes.
- Tools/workflows: Benchmarks probing dependency graphs; formal connections to self-conditioning, consistency models, and optimal transport.
- Assumptions/dependencies: Shared evaluation suites; open-weight models for comparative studies.
- New benchmarks for conditional flows and reasoning
- Sector: NLP Evaluation
- What: Datasets that vary mask schedules, conditioning strength, and dependency patterns to assess reasoning robustness and latency-quality trade-offs.
- Tools/workflows: Public leaderboards tracking metrics vs (w, ε, steps); multi-seed, multi-schedule reporting standards.
- Assumptions/dependencies: Community adoption; reproducible pipelines; judge-model stability (for open-ended tasks).
Policy
- Hallucination risk scoring via context-influence differentials
- Sector: Safety, Governance
- What: Use CCFG delta as a “context reliance” signal; flag responses produced with weak dependence on verified context in high-stakes settings.
- Tools/workflows: Risk scorers attached to inference; policy gates that demand higher w when delta is low; human-in-the-loop review.
- Assumptions/dependencies: Empirical validation that delta tracks factual grounding; thresholds tuned per domain.
- Standardization of promotion-trace auditing
- Sector: Regulation, Compliance
- What: Define standards for logging OTP decisions (timestamp, token, confidence, context) to support accountability and forensic analysis.
- Tools/workflows: Interoperable trace schemas; privacy-preserving redaction; third-party auditing services.
- Assumptions/dependencies: Policy consensus on required granularity; secure storage; user consent frameworks.
Daily Life
- Collaborative writing with stable “locked scaffolds”
- Sector: Productivity, Creative Tools
- What: Multiple users (or the system) can lock/pin parts of a draft (clean context), while masked sections are refined in a few steps with promotion-based stability.
- Tools/workflows: Real-time co-editing with mask/pin controls; promotion-aware diff views; conflict resolution when promotions collide.
- Assumptions/dependencies: UX for shared masks; latency constraints; consistency across devices.
- Personalized, curriculum-aware tutoring with calibrated scaffolding
- Sector: Education
- What: Adjust w and ε to control how quickly steps are solidified; align with learner proficiency (more scaffolding for beginners).
- Tools/workflows: Teacher dashboards to set promotion pace; alignment with standards; formative assessment integration.
- Assumptions/dependencies: Verified content pipelines; safety checks; adaptation to diverse curricula.
Notes on Feasibility and Dependencies
- Model availability and licensing: Many immediate applications presume access to pretrained MDMs (or MLFMs) and the right to adapt them via LoRA/AdaLN.
- Tuning sensitivity: Performance depends on noise scale σ, time schedule πt, masking schedule πs, guidance scale w, and promotion threshold ε; robust defaults and auto-tuners improve reliability.
- Calibration and safety: OTP introduces a controllable error bounded in total variation by εL; applications in regulated domains need stringent ε, domain SFT, validation layers, and human oversight.
- Compute and cost: While inference steps can be fewer than traditional diffusion-like methods, dual model calls in CCFG and Brownian-bridge updates still add overhead; distillation is a major enabler for on-device and cost-sensitive deployments.
- Token embedding assumptions: Endpoint equivalence and conditional generation rely on recoverable clean-token identities from embeddings; mismatches in tokenization/embeddings can degrade performance.
- Current capability profile: Evidence in the paper shows strong gains on instruction-following (MT-Bench) but not yet parity with top AR/MDM baselines on GSM8K math; domain-specific SFT and improved training scales are likely prerequisites for high-stakes domains.
Glossary
- AdaLN: Adaptive Layer Normalization used to condition a transformer on a continuous corruption time or other signals. "augment the normalisations in these blocks with AdaLN \citep{nie2025scalingmdm} to condition on the continuous corruption time "
- AdamW: An optimizer with decoupled weight decay that often improves generalization over Adam. "We use the AdamW optimiser \citep{loshchilov2017decoupled}"
- Autoregressive Models (ARMs): Models that generate sequences left-to-right by predicting each next token given all previous tokens. "Autoregressive Models (ARMs) have driven much of the recent progress in language modelling"
- Brownian bridge: A stochastic process that interpolates between two endpoints with variance that vanishes at the ends. "using a Brownian bridge as a stochastic interpolant connecting embedded partially masked sequences with embedded clean sequences."
- Classifier-free guidance: A sampling technique that steers generation by combining conditional and pseudo-unconditional model predictions. "a variant of classifier-free guidance \citep{ho2022classifier}"
- Consistency-style solver: A few-step or one-step sampling approach based on consistency models to approximate flow-based trajectories. "consistency-style solver \citep{song2023consistency, boffi2026build}"
- Context-corrupted classifier-free guidance (CCFG): A guidance variant that corrupts the context embeddings to isolate the contribution of clean context during sampling. "context-corrupted classifier-free guidance (CCFG)"
- Continuous-time Markov chain (CTMC): A stochastic process with state changes in continuous time; here used to model masking dynamics. "defining a continuous-time Markov chain (CTMC) \citep{del2017stochastic}"
- DDPM sampler: The denoising diffusion probabilistic model sampling procedure, here adapted to continuous token embeddings. "the standard DDPM sampler \citep{ho2020denoising} for conditional generation"
- Denoiser: A network that predicts the clean data distribution (or its statistics) from a corrupted input at a given time. "we parametrise the denoiser "
- Dirac measure: A probability distribution concentrated entirely at a single point. "to the Dirac measure on fully masked sequences."
- Euclidean space: A continuous vector space used to embed discrete token sequences for flow-based modeling. "represented in Euclidean space"
- Exponential moving average (EMA): A smoothed average of parameters over training steps to stabilize evaluation and sampling. "we also maintain an exponential moving average (EMA) of the adapter weights with decay 0.999"
- Factorised posterior: A posterior distribution that decomposes across token positions, enabling parallel predictions. "the factorised posterior over clean tokens"
- Flow LLMs (FLMs): Models that learn a continuous flow transporting noise to embeddings of token sequences. "Flow LLMs (FLMs) sidestep this limitation"
- Flow map: A direct mapping induced by a learned flow that can enable one-step or few-step generation. "inducing a flow map that can be distilled for single-step generation."
- Gaussian-based stochastic interpolant: A noise-to-data interpolation constructed using Gaussian noise to define a flow. "Gaussian--based stochastic interpolant:"
- GSM8K: A benchmark of grade-school math word problems used to evaluate reasoning. "evaluate the resulting model on GSM8K \citep{cobbe2021gsm8k} and MT-Bench"
- LangFlow: A specific approach/framework for Flow LLMs used as a basis in this work. "in particular LangFlow \citep{chen2026langflow}"
- LoRA: Low-Rank Adaptation; parameter-efficient adapters applied to linear layers for fine-tuning large models. "attach LoRA adapters \citep{hu2022lora}"
- Masked Diffusion Models (MDMs): Non-autoregressive models that iteratively unmask tokens via a learned denoising process. "Masked Diffusion Models (MDMs) promise fast, parallel language generation"
- MaskGIT cosine schedule: A masking-ratio schedule from MaskGIT used to select which tokens to mask during training. "MaskGIT cosine schedule \citep{chang2022maskgit}"
- MT-Bench: An instruction-following benchmark scored by an LLM judge across diverse categories. "MT-Bench \citep{zheng2023judging}"
- Noise-to-signal ratio (NSR): A parameterization of corruption level used to sample time in diffusion/flow training. "log noise-to-signal ratio (NSR) "
- ODE (ordinary differential equation): The differential equation governing the deterministic flow used for sampling. "we can generate approximate samples from by integrating the ODE:"
- Online token promotion (OTP): A sampling strategy that commits high-confidence tokens early as clean context to guide later steps. "We call this sampling strategy online token promotion (OTP)"
- Posterior mean embedding: The expected token embedding under the model’s posterior distribution at a given time. "posterior mean embedding ."
- SDE (stochastic differential equation): A differential equation with a noise term; used to describe stochastic denoising transitions. "simulating the SDE"
- Stochastic interpolant: A random-time interpolation between noisy and clean states used to define a flow. "the stochastic interpolant formed by the Brownian bridge"
- Supervised fine-tuning (SFT): Fine-tuning on prompt–response pairs to improve conditional generation. "supervised fine-tuning (SFT)"
- Velocity field: The vector field that specifies the instantaneous direction of the flow in continuous space. "velocity field for the flow:"
- Vicuna prompt template: A chat-style prompt format used to structure inputs for evaluation. "Vicuna prompt template~\citep{vicuna2023}"
Collections
Sign up for free to add this paper to one or more collections.

