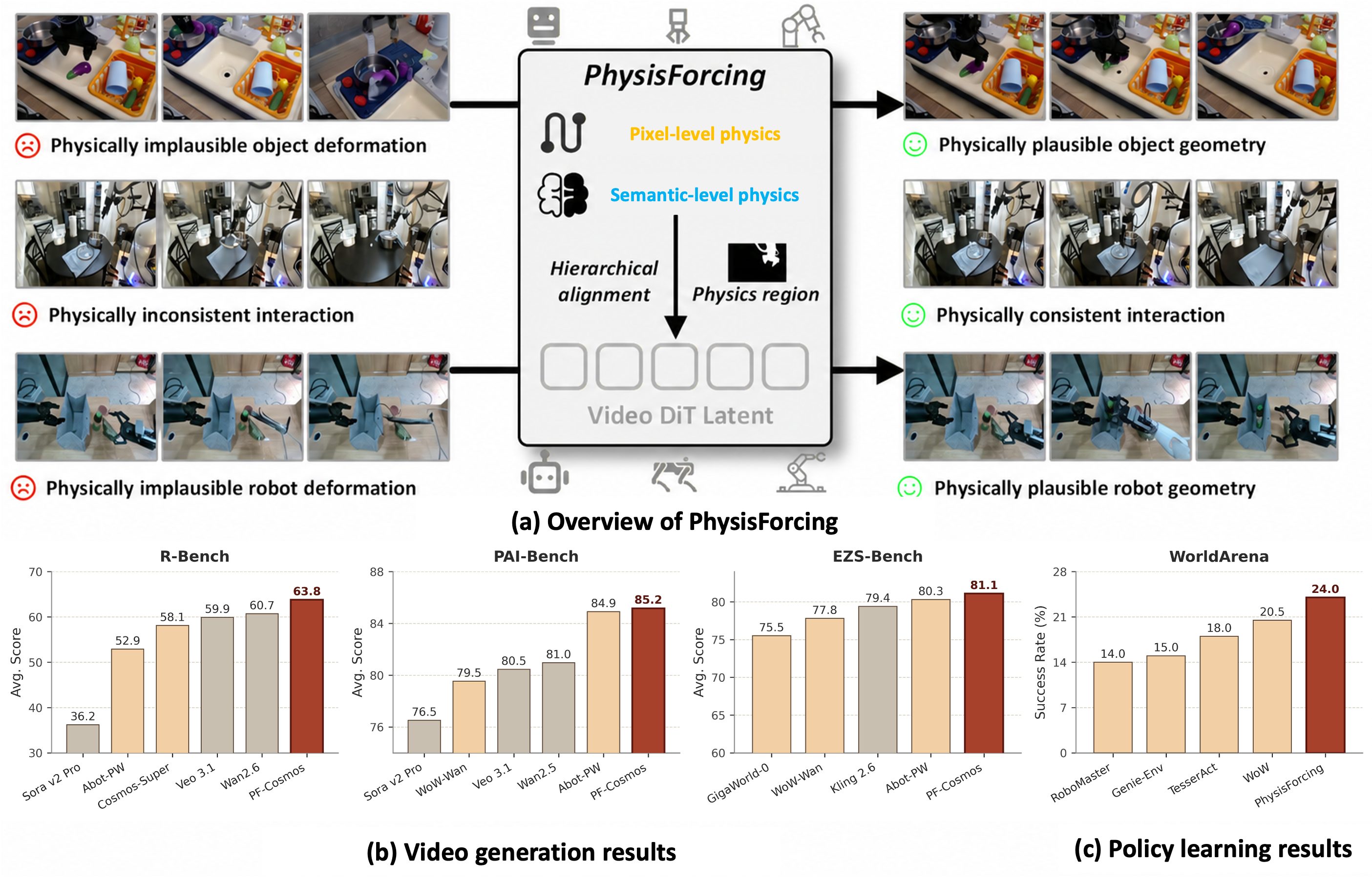
- The paper presents a hierarchical framework that integrates pixel-level and semantic-level physics alignment to boost simulation fidelity for robotic manipulation.
- It leverages diffusion-based video generation with targeted supervision that improves state transitions and reduces physically implausible behaviors.
- Experimental results demonstrate significant performance gains across multiple benchmarks, enhancing policy learning in robotic tasks.
Robotic manipulation in simulation increasingly leverages video generation models as world simulators, but even strong models—whether general-domain or robot-specific—commonly generate physically implausible dynamics (e.g., discontinuous trajectories, invalid contact, drifting objects), severely limiting their utility in action modeling or policy learning. The PhysisForcing framework addresses these failure modes by proposing region-focused hierarchical supervision, explicitly targeting both pixel-level motion and semantic-level relational coherence in physically informative regions of robot-object interaction.
Methodological Framework
PhysisForcing augments training for diffusion-based video generation backbones by identifying and focusing on physics-critical regions—including manipulators, objects, and contact areas. The method applies two complementary losses:
- Pixel-level trajectory alignment: Per-point tracking (e.g., via CoTracker3) aligns DiT features with reference spatio-temporal trajectories, enforcing local continuity and contact dynamics.
- Semantic-level relational alignment: The pairwise token similarity matrix of DiT features is aligned with that from a frozen video understanding encoder (e.g., V-JEPA2), transferring object-interaction-centric relational structure.
This hierarchical physics alignment is imposed at an optimal intermediate depth in the backbone transformer, regularizing the representation most conducive to both motion and semantic structure. Supervision is restricted to physics-informative regions using depth-weighted foreground masks, mitigating the dilution effects of static background pixels.
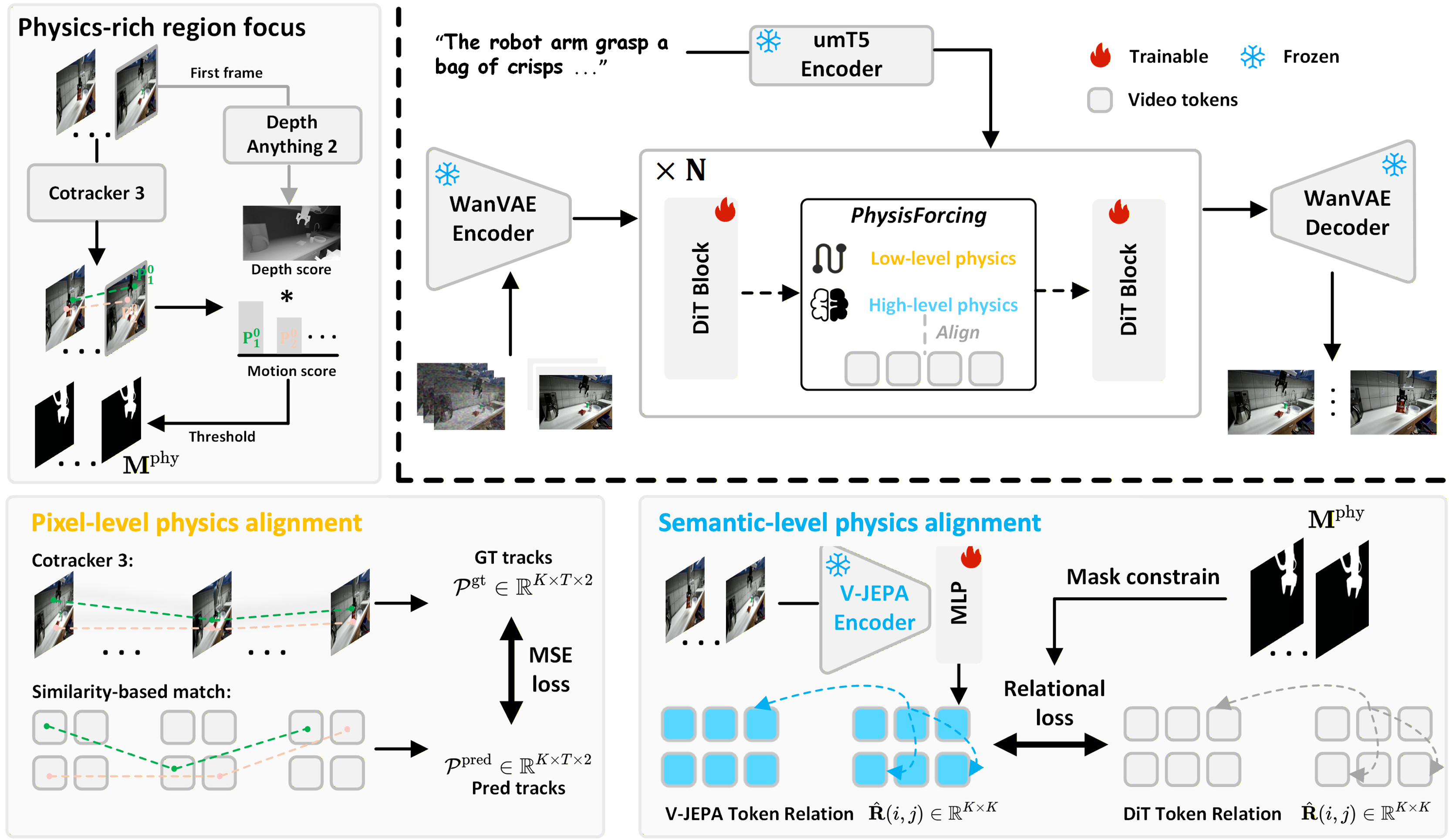
Figure 1: The architectural overview highlights the hierarchical physics alignment at both pixel and semantic levels, applied on interaction-critical spatial regions.
Experimental Evaluation and Numerical Results
PhysisForcing was evaluated across three established embodied video generation benchmarks:
Qualitative comparisons demonstrate that physically implausible failure modes (e.g., object drift, broken contact, deformation) are reduced in PF-trained models, which generate continuous grasping and maintain correct state transitions compared to commercial and robotics-specific competitors.

Figure 3: Qualitative analysis shows PF-Cosmos producing more physically plausible robot-object interactions relative to other state-of-the-art models.
Downstream Utility for Policy Learning
PhysisForcing-trained world models yield tangible improvements for action-centric evaluation:
- Fast-WAM backbone: Plugging PF-Wan into Fast-WAM raises average success rate from 68.2% to 72.8%, most notably on contact-heavy tasks (e.g., placing and pressing operations). This affirms that physically-aligned video models provide stronger representational support for downstream robotic policies.
- WorldArena closed-loop planning: PF-Wan elevates closed-loop success from 16.0% to 24.0%, surpassing all evaluated world-model planners including WoW and TesserAct.
Ablation Studies
Component and region-focused ablations reveal additive gains from the pixel-level and semantic-level losses. Both are individually beneficial, but their combination is optimal. Restricting supervision to physics-informative regions further increases task-focused scores (+1.5 over uniform application), verifying that targeted alignment is crucial. Selection of the alignment layer is empirically validated: intermediate depths maximize physics alignment efficacy, as shallow blocks lack relational structure while deep blocks are over-specialized.
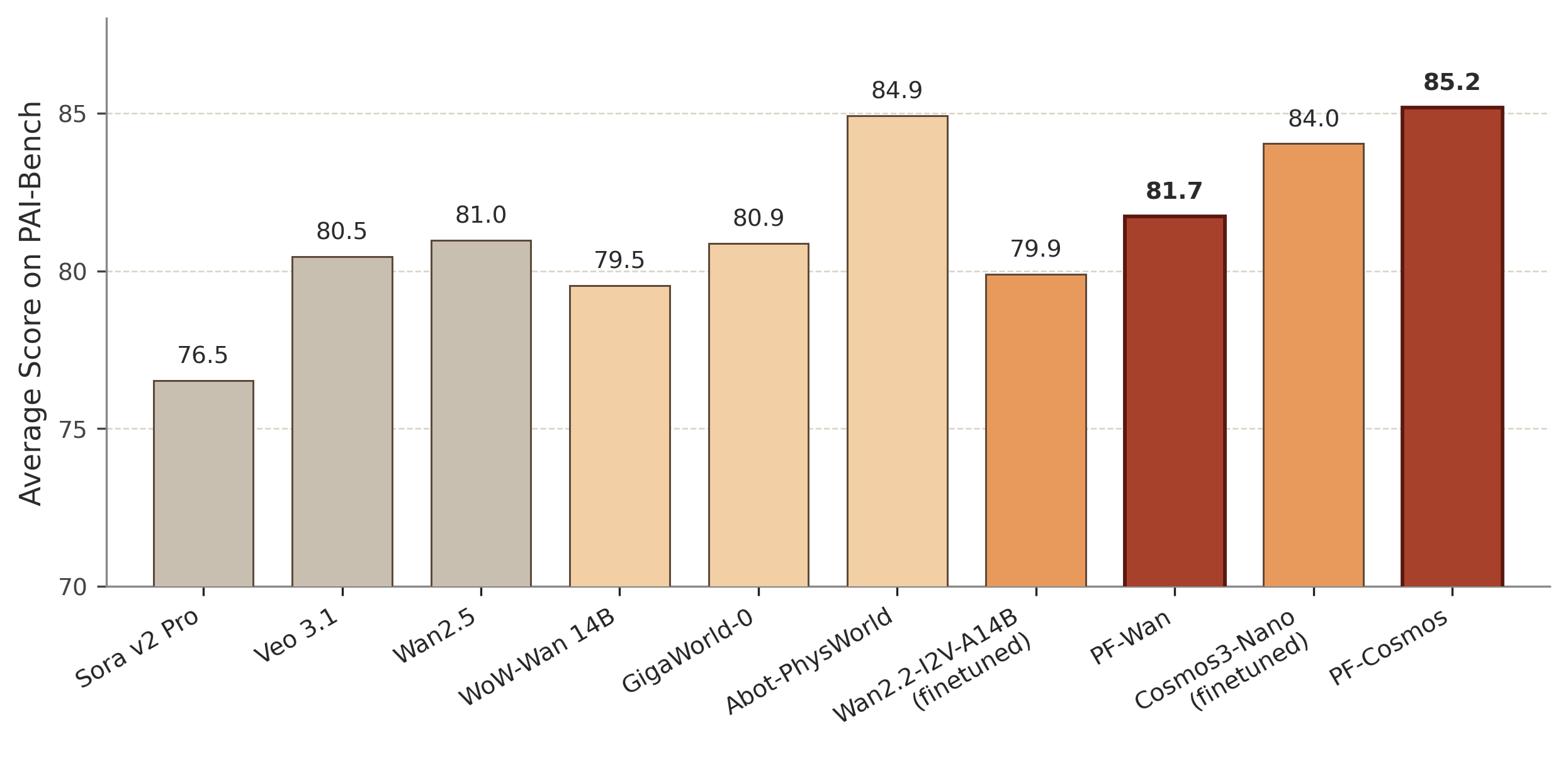
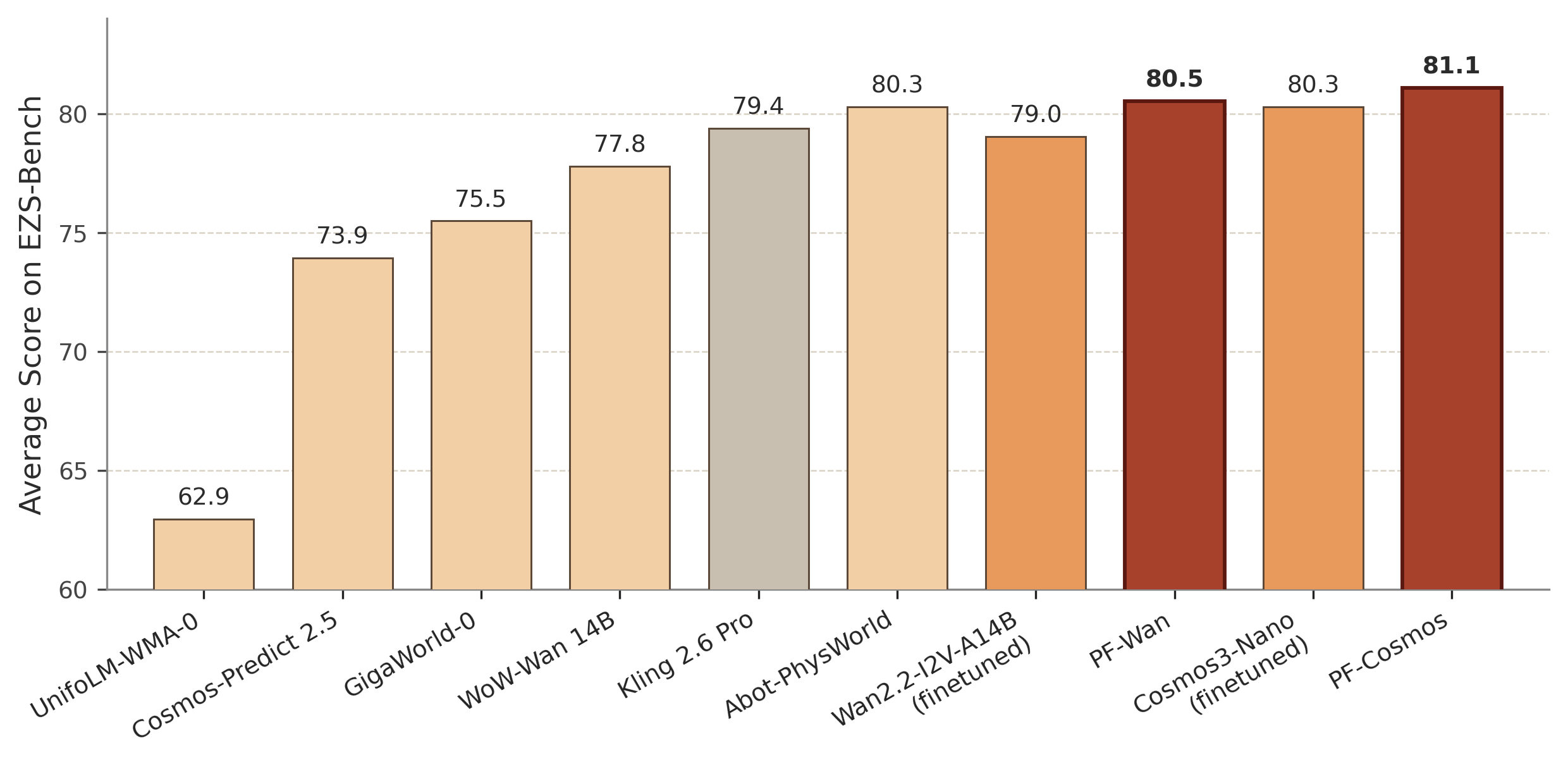
Figure 4: PF-Cosmos attains the best overall score on the PAI-Bench robot domain, confirming superior physical and semantic fidelity.
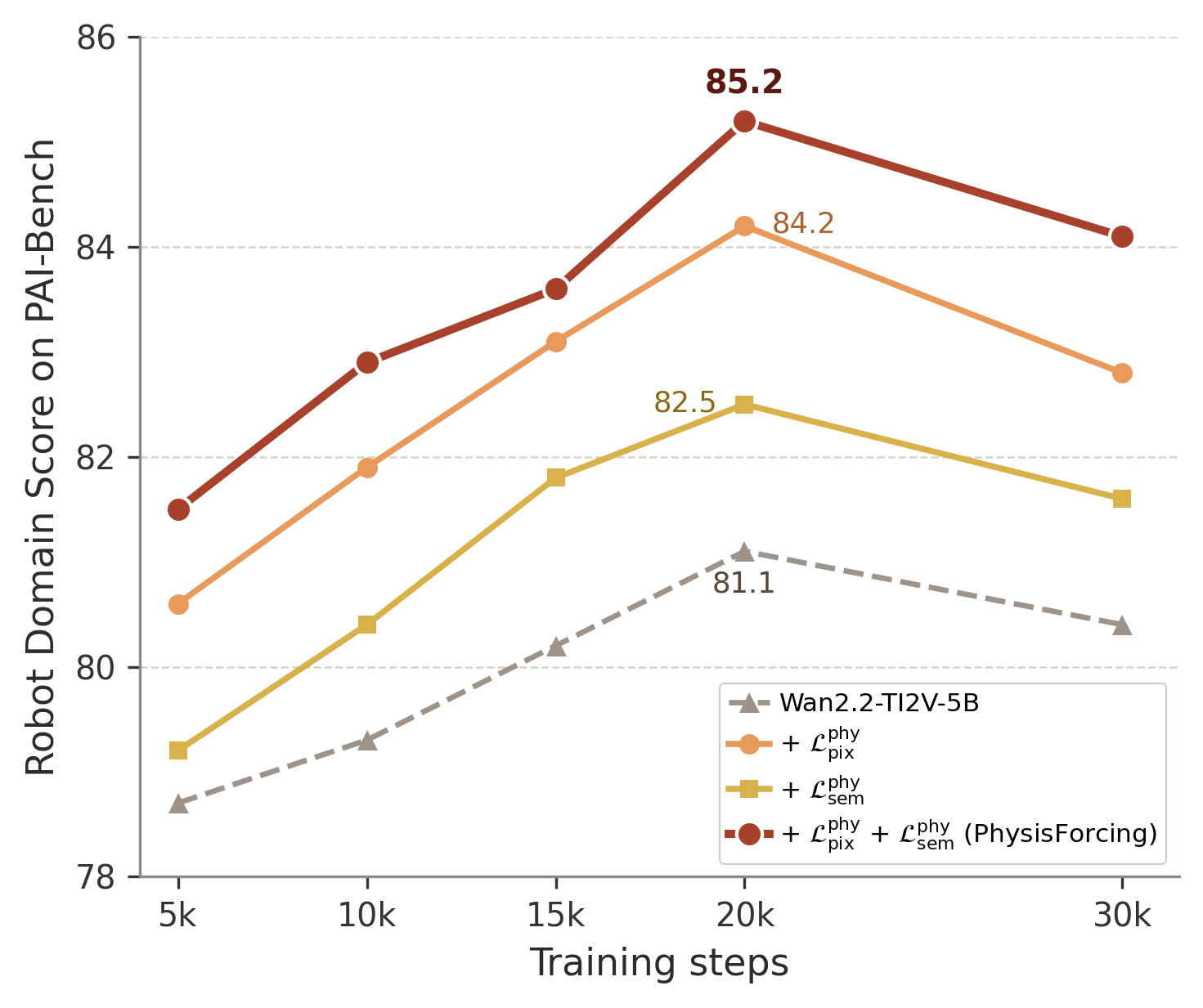
Figure 5: Training curve and ablation results demonstrate that the two physics alignment objectives are complementary, and region-focused supervision further improves performance.
Implications and Future Directions
The practical implication is clear: hierarchical, region-focused supervision yields video simulators with greater physical fidelity, producing data more suitable for world action modeling and downstream policy learning. PF-trained models not only generate visually realistic videos but also encode state transitions essential for embodied intelligence. Theoretically, this suggests that simulation fidelity for robotic learning is not solely a function of visual realism but requires explicit modeling of relational and causal physical structure.
Limitations include the dependency on the underlying backbone's representational capacity; as video foundation models improve in world knowledge and temporal reasoning, PhysisForcing's alignment objectives are expected to scale and compound with advancements.
Future directions involve extending hierarchical alignment to even finer-grained dynamics, integrating additional modalities (e.g., force, tactile), and scaling to long-horizon and multi-agent scenarios. The modularity of the approach facilitates adaptation across backbone families and training regimes.
Conclusion
PhysisForcing defines a region-focused, hierarchical framework for physics alignment in robotic video generation. Across rigorous benchmarks and policy-learning tasks, it consistently improves both physical plausibility and downstream utility over base models and strong baselines. The approach demonstrates that physically congruent generative simulators are foundational for robust embodied AI, offering scalable methods for improving fidelity in action-conditioned world modeling and robotic manipulation.